
12.1 새로운 값 계산하기
파일 열어보기
%matplotlib inline
import pandas as pd
df = pd.read_csv('drive/MyDrive/dataScience/data/broadcast.csv',index_col=0)
dfoutput
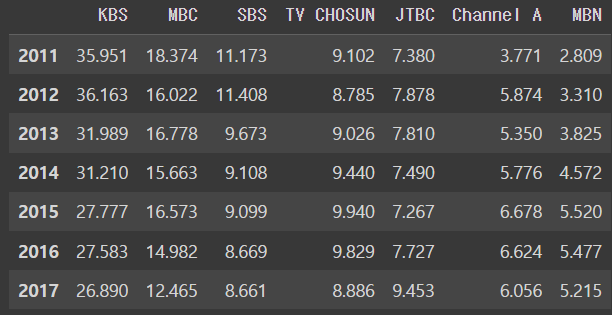
그래프화 시키면
df.plot()output
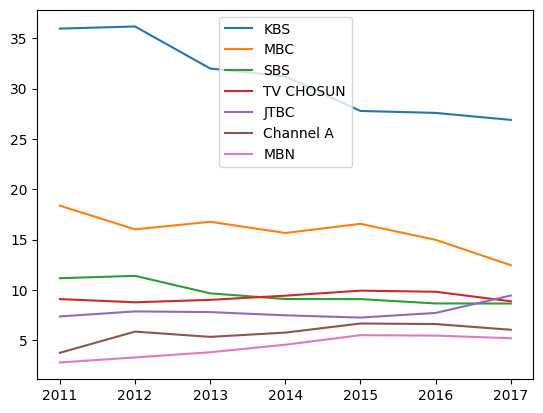
채널들의 총 시청률
df['KBS'] + df['MBC'] + df['SBS'] + df['TV CHOSUN'] + df['JTBC'] + df['Channel A'] + df['MBN']output
2011 88.560
2012 89.440
2013 84.451
2014 83.259
2015 82.854
2016 80.891
2017 77.626이걸 간단하게 적을 수도 있다
df.sum(axis = 'columns')output
2011 88.560
2012 89.440
2013 84.451
2014 83.259
2015 82.854
2016 80.891
2017 77.626column에 추가해보자!!
df['Total'] = df.sum(axis = 'columns')
dfoutput
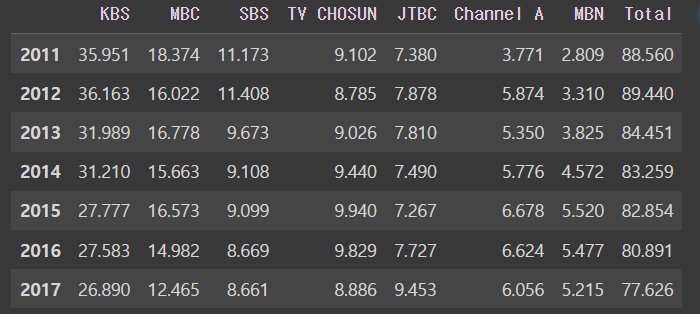
Total을 그래프화 시키자
df.plot(y='Total')output
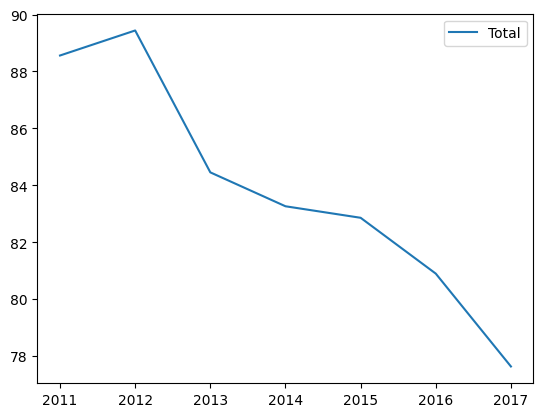
지상파와 종편을 나누어서 group1과 group2로 나눠보자
df['Group1'] = df.loc[:,'KBS':'SBS'].sum(axis = 'columns')
df['Group2'] = df.loc[:,'TV CHOSUN':'MBN'].sum(axis = 'columns')
dfoutput
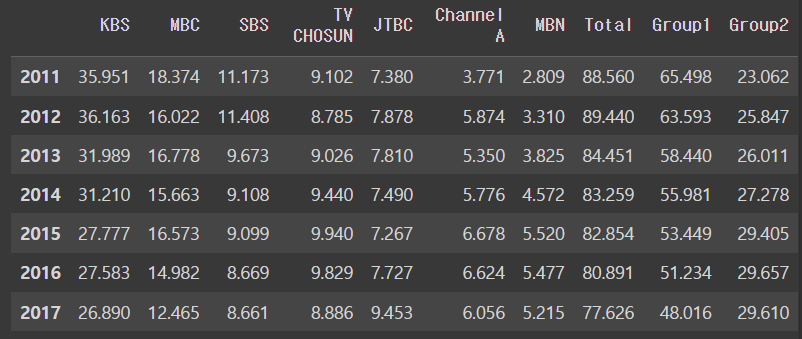
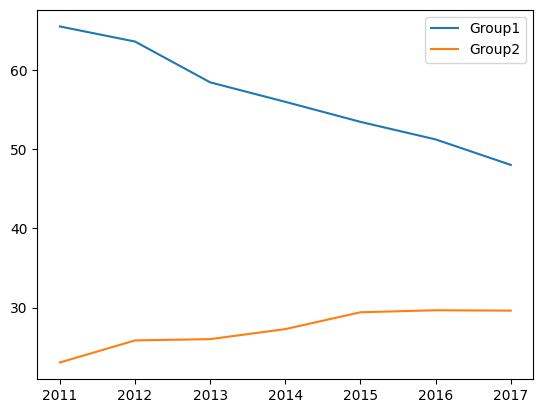
새로 추가된 열만 그래프화 시키자
df.plot(y=['Group1','Group2'])output
12.2 문자열 필터링
파일 불러오기
df = pd.read_csv('drive/MyDrive/dataScience/data/albums.csv', encoding = 'latin1')
df.head(20)output
장르가 뭐가 있는지 보고싶으면
df['Genre'].unique()output
array(['Rock', 'Rock, Pop', 'Funk / Soul', 'Rock, Blues', 'Jazz',
'Jazz, Rock, Blues, Folk, World, & Country', 'Funk / Soul, Pop',
'Blues', 'Pop', 'Rock, Folk, World, & Country',
'Folk, World, & Country', 'Classical, Stage & Screen', 'Reggae',
'Hip Hop', 'Jazz, Funk / Soul', 'Rock, Funk / Soul, Pop',
'Electronic, Rock',
'Jazz, Rock, Funk / Soul, Folk, World, & Country',
'Jazz, Rock, Funk / Soul, Pop, Folk, World, & Country',
'Funk / Soul, Stage & Screen',
'Electronic, Rock, Funk / Soul, Stage & Screen',
'Rock, Funk / Soul', 'Rock, Reggae', 'Jazz, Pop',
'Funk / Soul, Folk, World, & Country', 'Latin, Funk / Soul',
'Funk / Soul, Blues',
'Reggae,�Pop,�Folk, World, & Country,�Stage & Screen',
'Electronic,�Stage & Screen', 'Jazz, Rock, Funk / Soul, Blues',
'Jazz, Rock', 'Rock, Latin, Funk / Soul', 'Electronic, Rock, Pop',
'Hip Hop, Rock, Funk / Soul', 'Electronic, Pop',
'Rock, Blues, Pop', 'Electronic, Rock, Funk / Soul, Pop',
'Rock, Funk / Soul, Folk, World, & Country', 'Rock,�Blues',
'Rock, Pop, Folk, World, & Country', 'Rock, Latin',
'Rock, Stage & Screen', 'Rock, Blues, Folk, World, & Country',
'Electronic', 'Electronic, Funk / Soul, Pop',
'Pop, Folk, World, & Country', 'Electronic, Hip Hop, Pop',
'Blues, Folk, World, & Country',
'Electronic, Hip Hop, Funk / Soul, Pop',
'Rock, Funk / Soul, Blues, Pop, Folk, World, & Country',
'Jazz, Pop, Folk, World, & Country', 'Jazz, Rock, Pop',
'Hip Hop, Funk / Soul', 'Hip Hop, Rock',
'Electronic, Hip Hop, Funk / Soul',
'Funk / Soul,�Folk, World, & Country',
'Electronic, Hip Hop, Reggae, Pop', 'Electronic, Reggae',
'Electronic, Funk / Soul', 'Rock, Funk / Soul, Blues',
'Rock,�Pop', 'Electronic, Rock, Funk / Soul, Blues, Pop',
'Rock, Reggae, Latin'], dtype=object)장르가 Blues인 것만 찾고싶다면 아래처럼 해왔었당
df[df['Genre']=='Blues']output
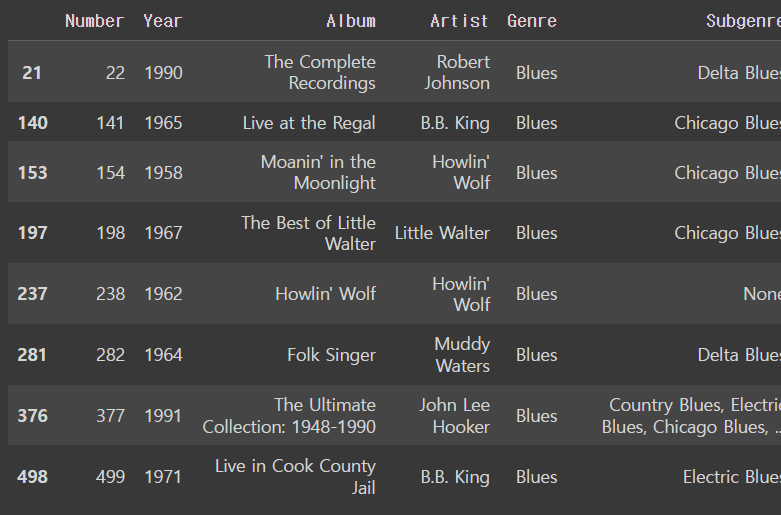
하지만 다르게 할 수도 있는데 str.contains()를 쓰는 것 !!
그리고 위의 코드는 장르가 딱 Blues인 애들만 나오기 때문에 여러 장르가 합쳐졌는데 그 안에 Blues가 있는 것들은 안나왔는데 이건 나온다
df[df['Genre'].str.contains('Blues')]output
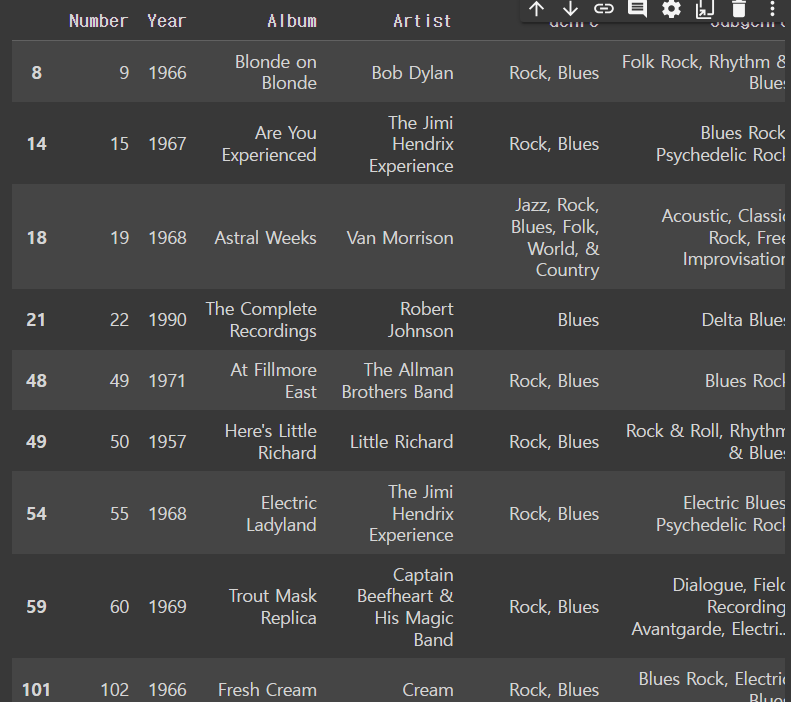
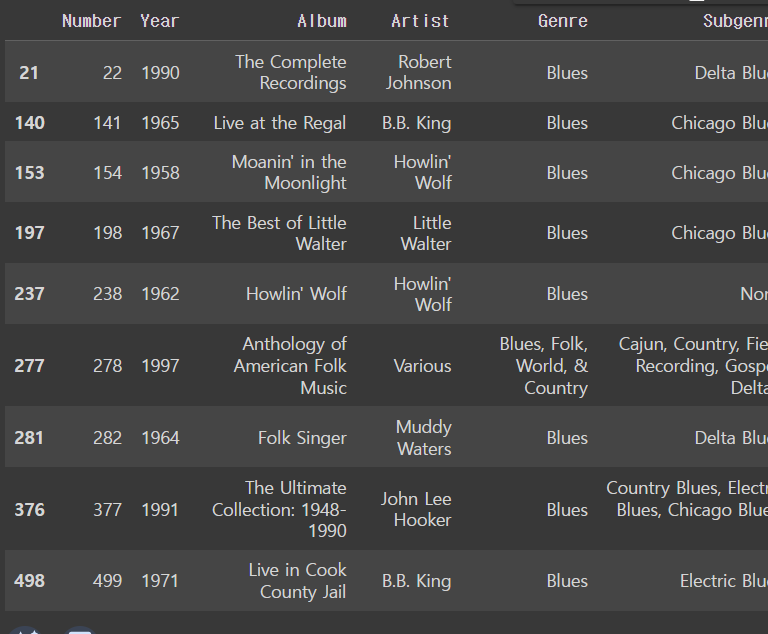
여러 장르가 합쳐진 것 중에 Blues가 있다 해도 맨 앞에 Blues가 없을 수 있는데 맨 앞에 나오는 것들만 필터링 하고자 하면 str.startswith()를 쓰면 된다 !
df[df['Genre'].str.startswith('Blues')]output
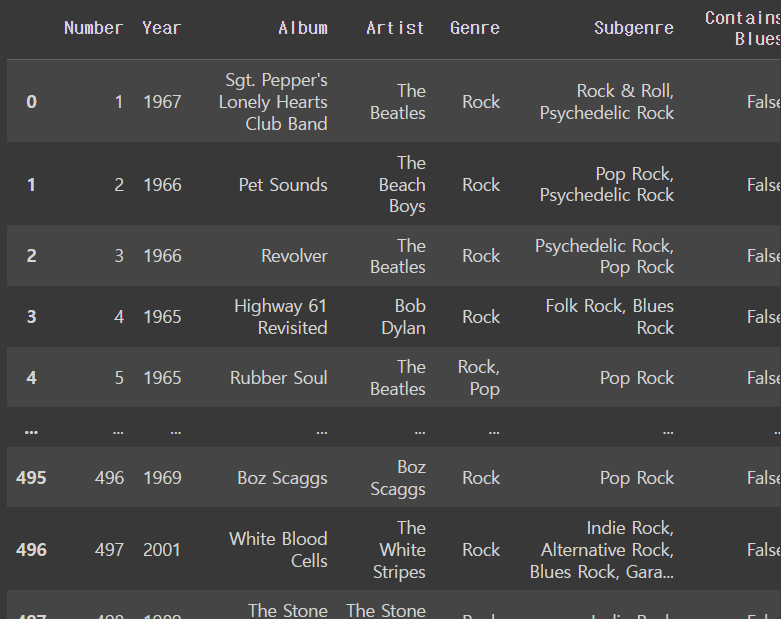
행을 하나 만들어서 blues를 포함하면 true, 안 하면 false로 만들 수도 있다
df['Contains Blues'] = df['Genre'].str.contains('Blues')
dfoutput
12.3 (실습) 박물관이 살아있다 I
한국에서 잘나가는 동양예술전문가 솔희는 최근 “박물관이 살아 있다” 프로젝트를 시작했습니다.
“박물관이 살아 있다” 프로젝트는 점점 떨어져가는 문화예술공간의 방문율을 높이기 위해 시작되었습니다.
김솔희씨는 먼저 예술의 흥행을 위해선 젊은이들의 참여가 시급하다고 판단하여, 대학교 박물관을 먼저 개선하기로 하였습니다.
대학 박물관을 개선하기 위해 다음과 같이 박물관을 분류하기로 하였습니다.
- 박물관은 대학/일반 박물관으로 나뉜다.
- 시설명에 '대학'이 포함되어 있으면 '대학', 그렇지 않으면 '일반'으로 나누어 '분류' column에 입력한다.
'분류' column을 만들어서 솔희를 도와주세요!
code
import pandas as pd
df = pd.read_csv('data/museum_1.csv')
is_university = df['시설명'].str.contains('대학교')
df.loc[is_university == True, '분류'] = '대학'
df.loc[is_university == False, '분류'] = '일반'
df12.4 문자열 분리
파일 불러오깅
df = pd.read_csv('drive/MyDrive/dataScience/data/parks.csv')
df.head()output
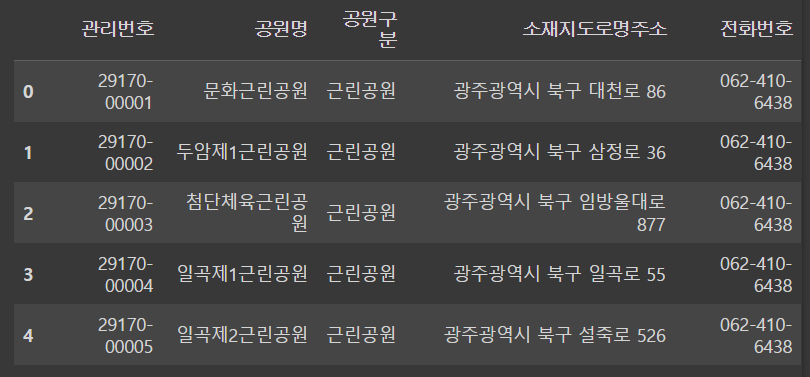
관할구역이 어딘지 알고싶다 !! 그러면 소재지도로명주소에서 앞에 시나 도를 떼어와서 알아야함. 여기서 쓸 수 있는 명령어는 str.split() !!
ㄴ 얘는 띄어쓰기를 기반으로 단어들을 나누어서 리스트처럼 만들어주는 역할을 한다
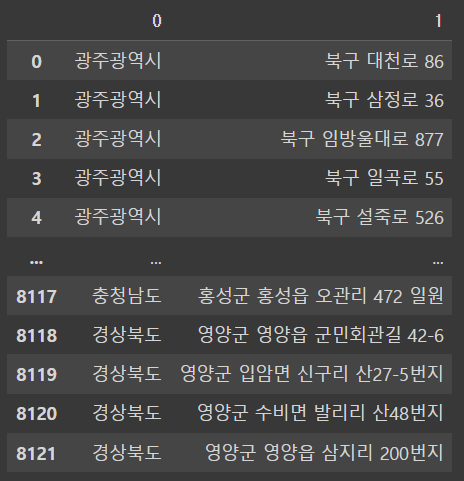
address = df['소재지도로명주소'].str.split(n=1, expand = True)
addressㄴ매개변수로 n을 넣어서 n=1이라고 한다하면 띄어쓰기 한 첫번째꺼와 나머지 형태로 추출해준다. 또, expand = True를 쓰면 분리된 결과를 여러열로 확장해서 DataFrame으로 반환한다 !
output
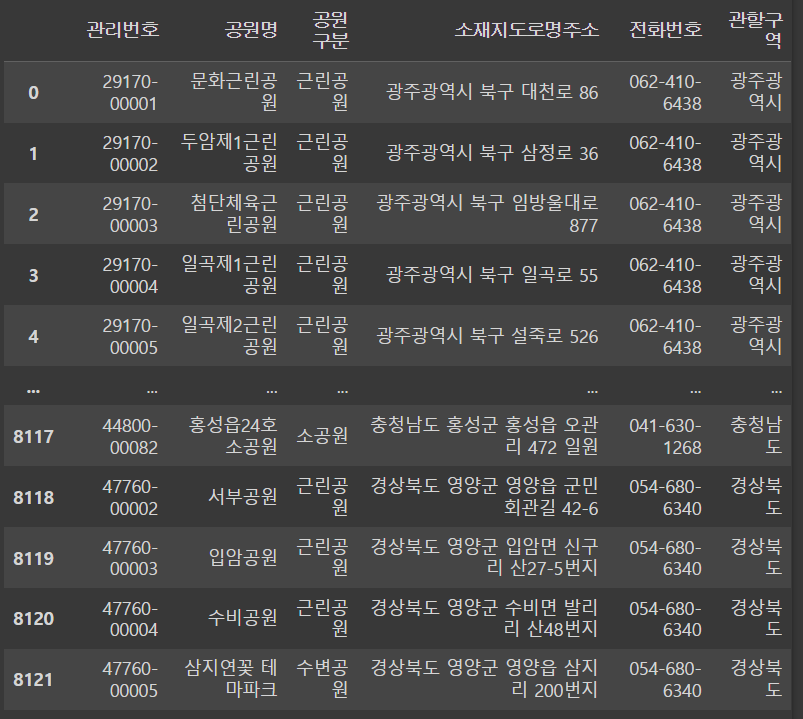
이제 그러면 관할구역이라는 column을 만들고 0번 값을 넣어주면 끝 !
df['관할구역'] = address[0]
dfoutput
12.5 박물관이 살아있다 II
솔희는 어느 지역에 박물관이 많은지 분석해보려고 합니다.
하지만 주어진 데이터에는 주소가 없네요.
그러던 도중, 전화번호 앞자리가 지역을 나타낸다는 것을 깨달았습니다.
솔희가 박물관의 위치를 파악할 수 있게 '운영기관전화번호' column의 맨 앞 3자리를 추출하고, '지역번호' column에 넣어주세요.
code
import pandas as pd
df = pd.read_csv('data/museum_2.csv')
num = df['운영기관전화번호'].str.split('-', n=1, expand = True)
df['지역번호'] = num[0]
df12.6 카테고리로 분류
파일 불러옵니다요
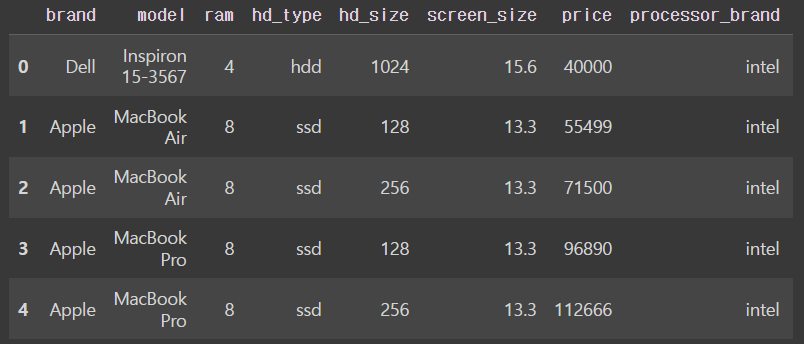
df = pd.read_csv('drive/MyDrive/dataScience/data/laptops.csv')
df.head()output
이번에 할 일은 브랜드가 어디 나라의 브랜드인지 바꿔주도록 할것임 !!
그러기 위해서 코드를 하나 작성해주자
brand_nation = {
'Dell':'U.S.',
'Apple':'U.S.',
'Acer':'Taiwan',
'HP':'U.S.',
'Lenovo':'China',
'Alienware':'U.S.',
'Microsoft':'U.S.',
'Asus':'Taiwan'
}이 다음에 map()이라는 함수를 쓸거임. 얘는 왼쪽 값을 오른쪽 값으로 바꿔주는 역할을 한당 ex) Dell => U.S.
df['brand'].map(brand_nation)output
0 U.S.
1 U.S.
2 U.S.
3 U.S.
4 U.S.
...
162 Taiwan
163 Taiwan
164 Taiwan
165 Taiwan
166 Taiwan
Name: brand, Length: 167, dtype: object이제 이걸 column으로 만들고 값을 넣어줄것임
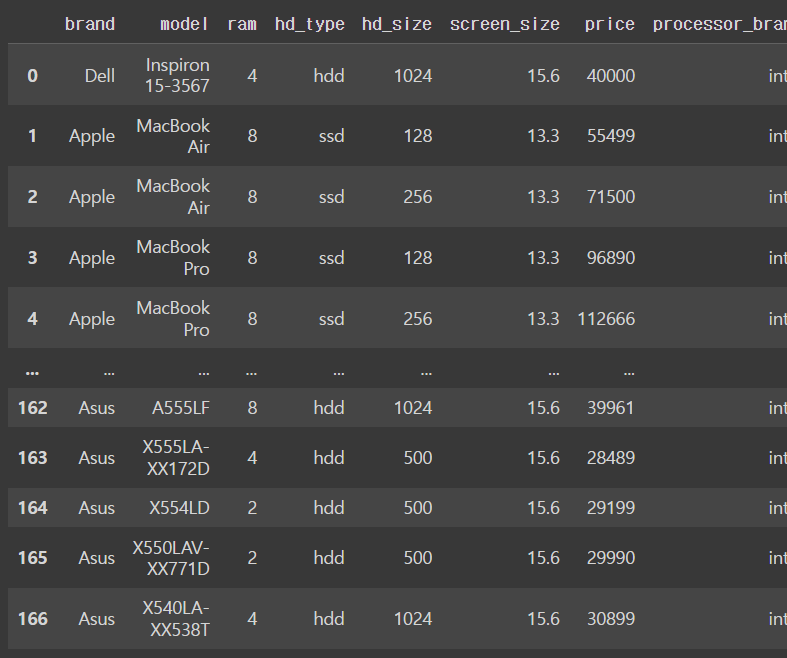
df['brand_nation'] = df['brand'].map(brand_nation)
dfoutput
12.7 (실습) 박물관이 살아 있다 III
솔희는 지역번호를 이용해서 지역 정보를 알아내고자 합니다.
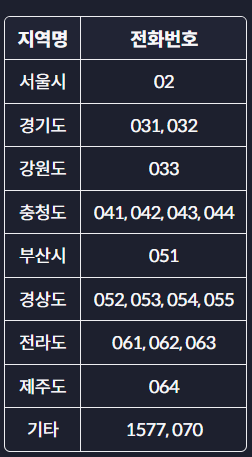
지역번호가 02이면 '서울시'이고, 지역번호가 064라면 '제주도'입니다.
'지역번호' column을 '지역명' 으로 변경하고, 아래 규칙에 따라 지역을 넣어주세요.
파이썬 사전(dictionary)을 만드는 과정이 번거로울 수 있지만, 실제 분석 상황을 가정한 과제입니다. 직접 작성해 보세요!
숫자로 이루어진 지역번호 column을 String type으로 바꿔주기 위해, read_csv() 메소드에 dtype={'지역번호': str} 옵션을 템플릿에 추가해 두었습니다. 참고하세요.
code
import pandas as pd
df = pd.read_csv("data/museum_3.csv", dtype={'지역번호': str})
name = {
'02': '서울시',
'031': '경기도',
'032': '경기도',
'033': '강원도',
'041': '충청도',
'042': '충청도',
'043': '충청도',
'044': '충청도',
'051': '부산시',
'052': '경상도',
'053': '경상도',
'054': '경상도',
'055': '경상도',
'061': '전라도',
'062': '전라도',
'063': '전라도',
'064': '제주도',
'1577': '기타',
'070': '기타'
}
new_name = {'지역번호':'지역명'}
df.rename(columns = new_name, inplace = True)
df['지역명'] = df['지역명'].map(name)
df이렇게 할 수도 있다 !! (rename을 나중에 씀)
해설코드
region = {
'02': '서울시',
'031': '경기도', '032': '경기도',
'033': '강원도',
'041': '충청도', '042': '충청도', '043': '충청도', '044': '충청도',
'051': '부산시',
'052': '경상도', '053': '경상도', '054': '경상도', '055': '경상도',
'061': '전라도', '062': '전라도', '063': '전라도',
'064': '제주도',
'1577': '기타', '070': '기타'
}
df["지역번호"] = df["지역번호"].map(region)
df.rename(columns={"지역번호": "지역명"}, inplace=True)
# 테스트 코드
df 12.8 groupby
이번에는 groupby라는 함수를 배워보았다 ! 이는 각 column에 몇개의 값이 있는지 비교하면서 볼 수 있는 함수
6강에서 했던 실습과 이어서 진행하였다
nation_groups = df.groupby('brand_nation')
type(nation_groups)output
pandas.core.groupby.generic.DataFrameGroupByㄴ 타입 역시 DataFrameGroupBy인 것을 볼 수 있다 ~
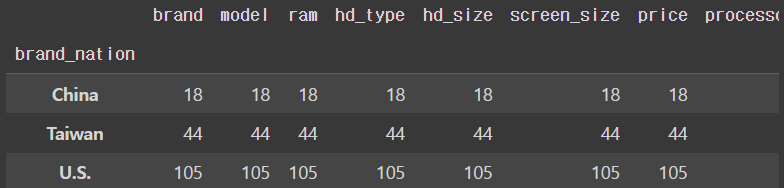
count()를 써서 나라 별로 개수를 세서 비교할 수 있음
nation_groups.count()output
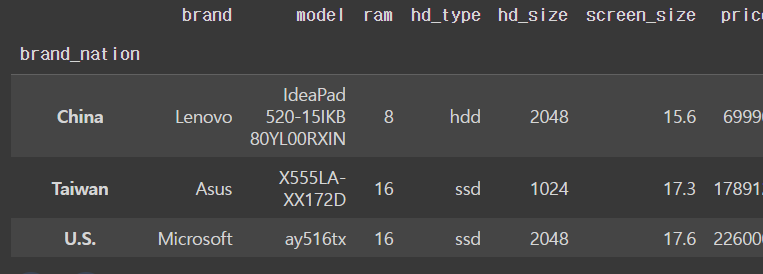
max()로 나라별 최댓값을 알아볼 수 있다
nation_groups.max()output
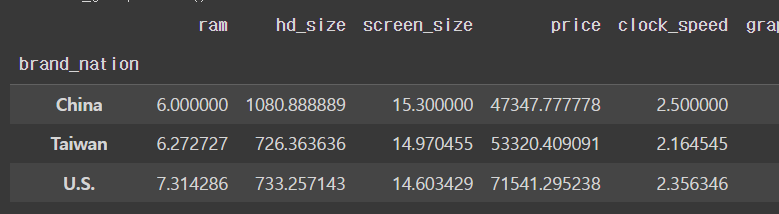
mean()으로 평균값 비교하기
nation_groups.mean()output
first()를 쓰면 첫번째 값들을 알아볼 수 있음
nation_groups.first()output
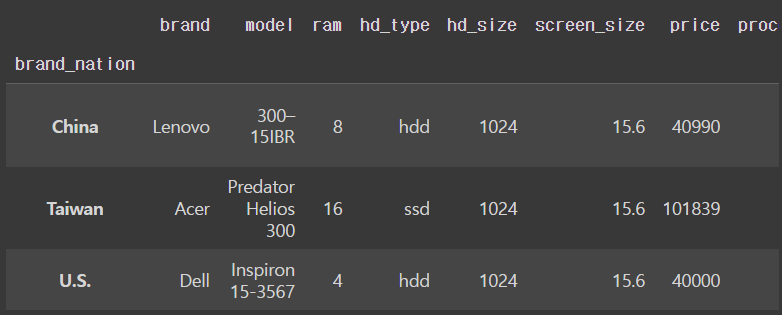
last()로 마지막 값 알아보기
nation_groups.last()output

groupby와 plot을 사용해서 각각 그래프를 그릴 수 있다
nation_groups.plot(kind = 'box', y = 'price')output
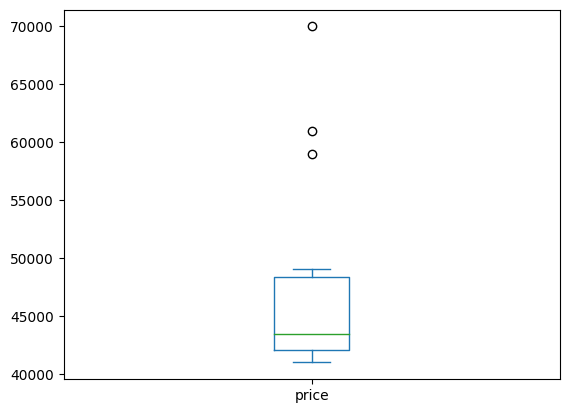
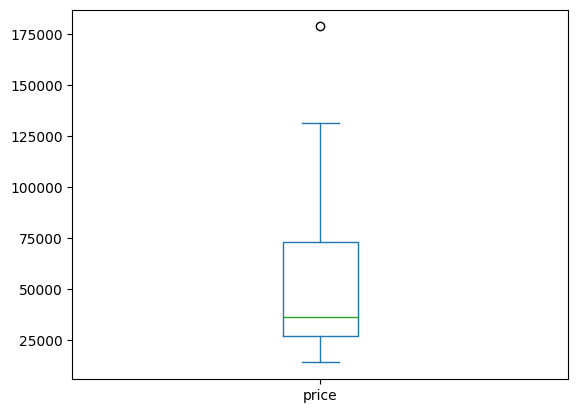
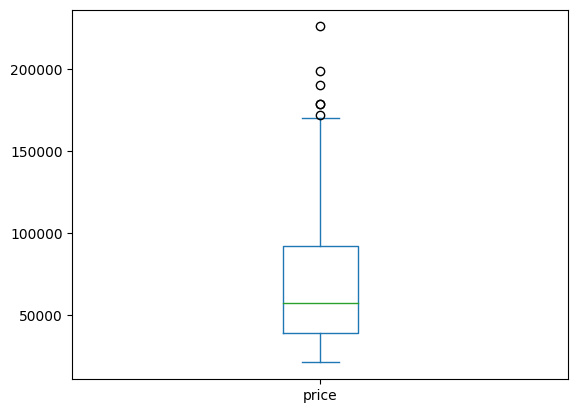
이번엔 히스토그램으로 그려보았다
nation_groups.plot(kind = 'hist', y = 'price')output
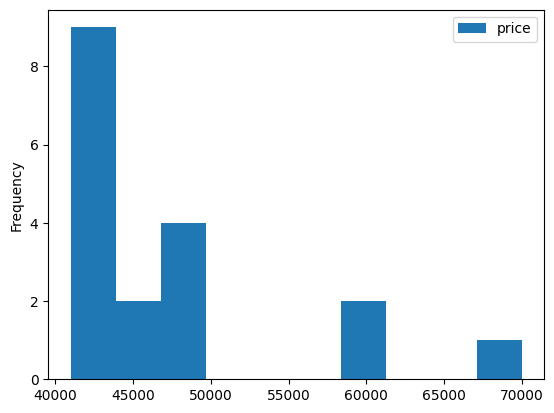
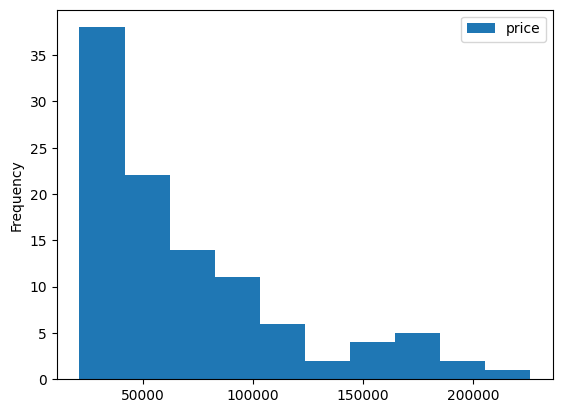
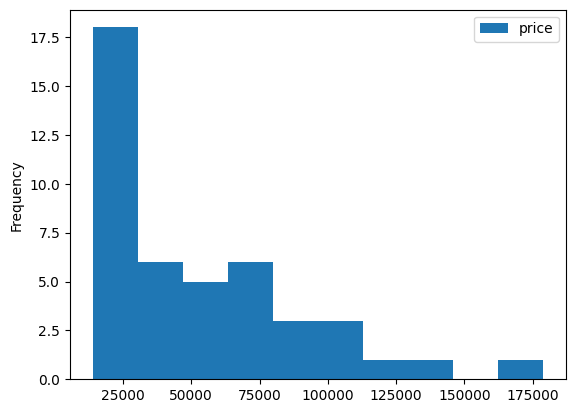
12.9 (실습) 직업 탐구하기 I
직업과 나이, 성별 등에 대한 데이터가 data/occupations.csv에 있습니다.
각 직업의 평균 나이가 궁금한데요.
groupby 문법을 사용해서 '평균 나이'가 어린 순으로 직업을 나열해 보세요.
code
import pandas as pd
df = pd.read_csv('data/occupations.csv')
group = df.groupby('occupation')
group.mean().sort_values(by = 'age')12.10 (실습) 직업 탐구하기 II
이번에는 여자 비율이 높은 직업과, 남자 비율이 높은 직업이 무엇인지 궁금한데요.
groupby 문법을 사용해서 '여성 비율'이 높은 순으로 직업을 나열해 보세요.
DataFrame이 아닌 Series로, 'gender'에 대한 값만 아래와 같이 출력되어야 합니다.
힌트 1
pythondf.groupby('column name')
DataFrame에 groupby 메소드를 사용하면, 특정 column 값을 기준으로 주어진 데이터를 group으로 묶을 수 있습니다.
힌트 2
groupby 오브젝트에 .mean() 메소드를 활용하면, 각 column에 대한 평균값을 알 수 있습니다.
하지만 숫자로 이루어진 column에 대해서만 계산됩니다.
.mean() 메소드로 성별 비율을 알기 위해서는 남자를 의미하는 'M'과 여자를 의미하는 'F'를 숫자로 바꾸어주면 됩니다.
힌트 3
groupby.mean(), groupby.max() 등의 결과도 DataFrame입니다. 따라서 일반적인 DataFrame의 인덱싱 기법을 모두 적용할 수 있습니다.
문제에서 주어진 조건과 같이, DataFrame에서 특정 Series만 추출해 보세요.
힌트 4
Series를 내림차순으로 정렬하고 싶으면, .sort_values() 메소드의 ascending 옵션을 이용하면 됩니다.
python.sort_values(ascending=False)
code
import pandas as pd
df = pd.read_csv('data/occupations.csv')
occupation_group = df.groupby('occupation')
# boolean 형식으로 만들어주기
df.loc[df['gender'] == 'M', 'gender'] = 0
df.loc[df['gender'] == 'F', 'gender'] = 1
occupation_group.mean()['gender'].sort_values(ascending=False)12.11 데이터 합치기
데이터 합칠 땐 merge를 써야함
합치는 4가지 방법
1. inner join
= 겹치는 부분만 합치겠다는 뜻
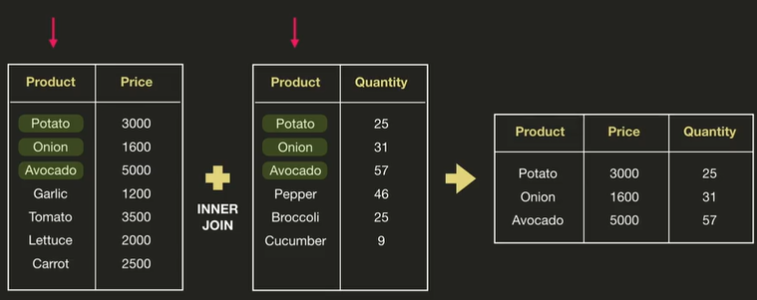
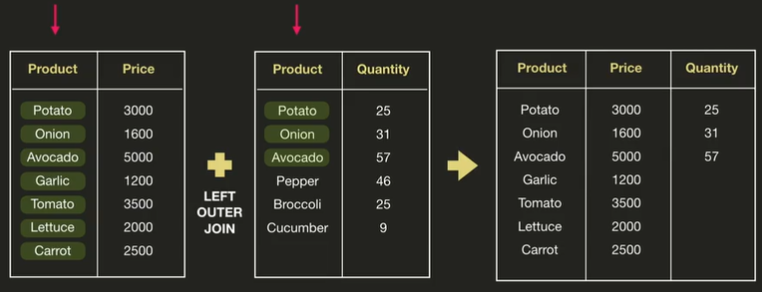
- left outer join
= 왼쪽 데이터프레임을 합친다는 뜻
-
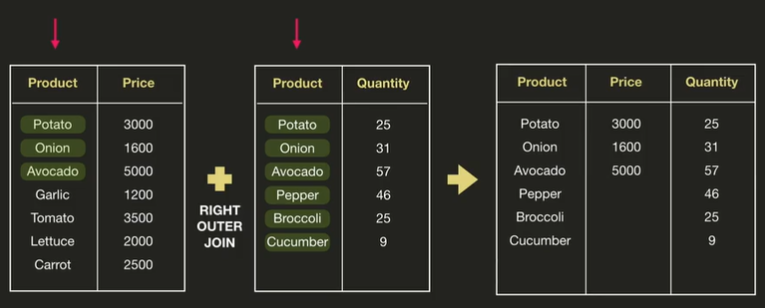
right outer join
= 오른쪽 데이터프레임에 존재하는 것만 합친다는 뜻
-
full outer join
= 양쪽에 있는 모든걸 합친다는 뜻

이제 코드로 봐보자 !!
파일을 불러와줌
import pandas as pd
price_df = pd.read_csv('drive/MyDrive/dataScience/data/vegetable_price.csv')
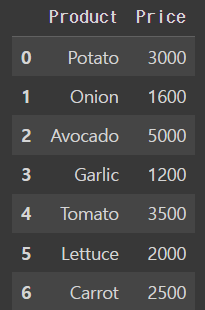
quantity_df = pd.read_csv('drive/MyDrive/dataScience/data/vegetable_quantity.csv')price_dfoutput
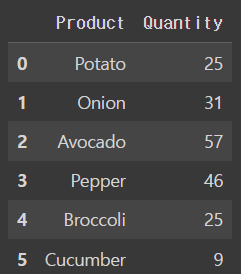
quantity_dfoutput
- inner join 하는 거
pd.merge(price_df, quantity_df, on='Product') #Product 열 기준으로 합치기 때문output
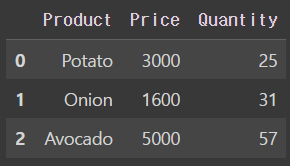
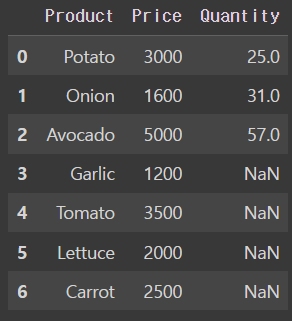
- left outer join
pd.merge(price_df, quantity_df, on='Product', how = 'left')output
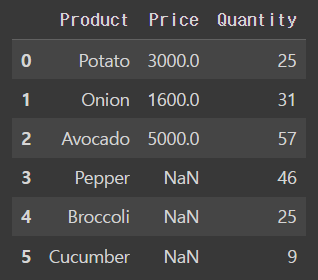
- right outer join
pd.merge(price_df, quantity_df, on='Product', how = 'right')output
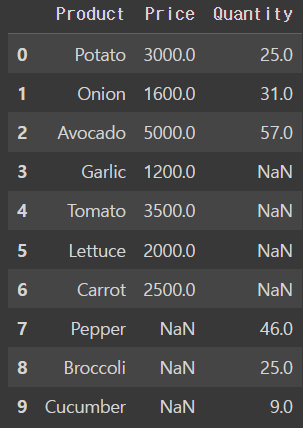
- full outer join
pd.merge(price_df, quantity_df, on='Product', how = 'outer')output
12.12 (실습) 박물관이 살아 있다 IV
파이썬 사전과 .map()을 사용해서 지역명을 알아낸 솔희는, 조금 더 편한 방법을 고민하고 있습니다.
고민하던 중, '지역번호와 지역명에 대한 데이터는 누군가 이미 만들어두지 않았을까'라는 생각을 하게 되는데요.
인터넷에서 지역번호와 지역명이 있는 데이터 region_number.csv를 구했습니다!
이 데이터를 먼저 살펴보고, .merge() 메소드를 활용해서 museum_3.csv에 '지역명' column을 추가해 보세요.
단, museum_3.csv의 박물관 순서가 유지되어야 합니다.
code
import pandas as pd
museum = pd.read_csv("data/museum_3.csv", dtype={'지역번호': str})
number = pd.read_csv("data/region_number.csv", dtype={'지역번호': str})
pd.merge(museum, number, on = '지역번호', how = 'left') # 박물관 순서가 유지되어야한다 했으므로 왼쪽 dataframe을 기준으로 해야함 = left outer join이 적절하다