
11.1 EDA란?
EDA = 데이터셋을 다양한 관점에서 살펴보고 탐색하면서 인사이트를 찾는 것
- 각 row는 무엇을 의미하는가?
- 각 column은 무엇을 의미하는가?
- 각 column은 어떤 분포를 보이는가?
- 두 column은 어떤 연관성이 있는가?
ex) 성별에 따라 특히 더 관심있는 분야는 뭔지, 나이에 따라 성향이 어떻게 변하는지
EDA는 공식이 없다 !
= 그저 다양한 방법으로 데이터를 살펴보는 것 (ex 시각적인 방법, 통계적인 방법)
11.2 기본 정보 파악하기

파일을 불러온당
import pandas as pd
import seaborn as sns
df = pd.read_csv('drive/MyDrive/dataScience/data/young_survey.csv')
df.head()output
140~147번째 데이터들만 보고 싶다!!
basic_info = df.iloc[:,140:]
basic_info.head()output
수치형 데이터로 요약해보자
basic_info.describe()output
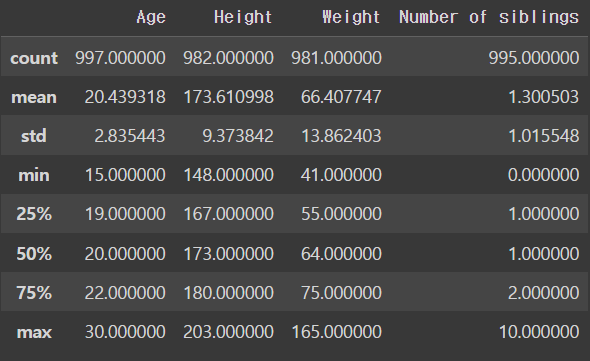
여기서 봐야될 점이 Gender, Handednes, Education이 describe()에선 나오지 않았단 것이다 !!
이유는 ? -> 값이 숫자가 아니기 때문
안나왔기 때문에 하나하나 알아보자면
(Gender)
basic_info['Gender'].value_counts()output
female 587
male 405
Name: Gender, dtype: int64(Handednes)
basic_info['Handedness'].value_counts()output
right 895
left 99
Name: Handedness, dtype: int64(Education)
basic_info['Education'].value_counts()output
high school 618
bachelor's degree 207
middle school 78
master's degree 78
elementary school 10
doctorate degree 5
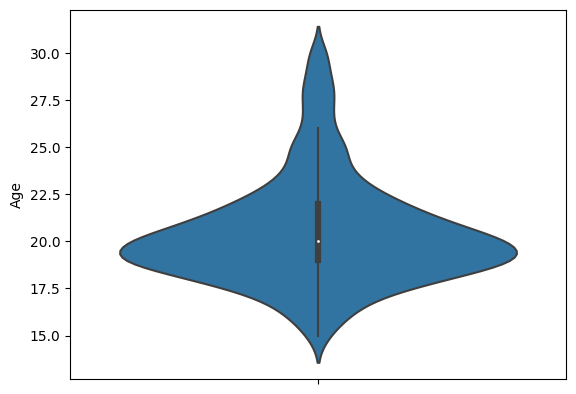
Name: Education, dtype: int64violin plot으로 나이의 분포를 알아보자
sns.violinplot(data = basic_info, y = 'Age')output
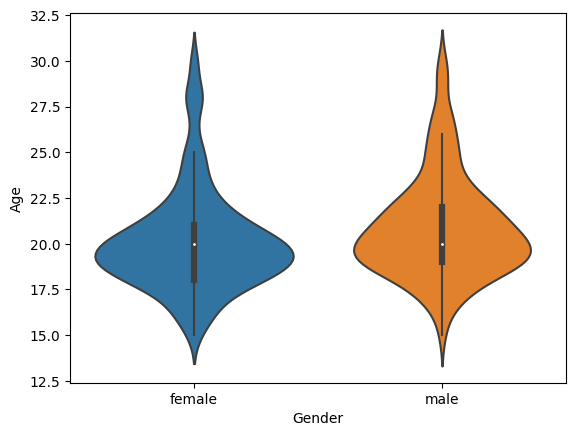
나이와 성별의 상관관계를 알아보자면
sns.violinplot(data = basic_info, x = 'Gender', y = 'Age')output
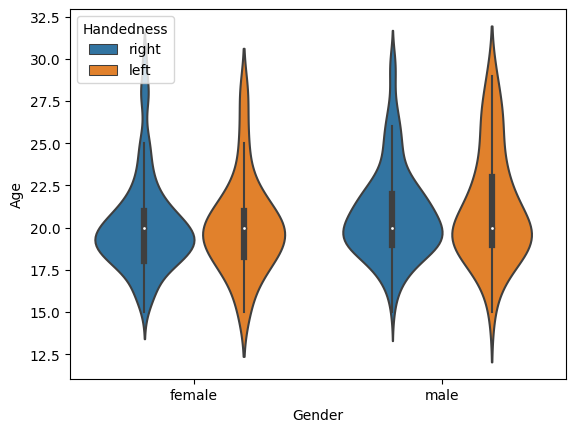
왼손잡이 오른손잡이와 상관관계까지 알아보자
sns.violinplot(data = basic_info, x = 'Gender', y = 'Age', hue = 'Handedness')output
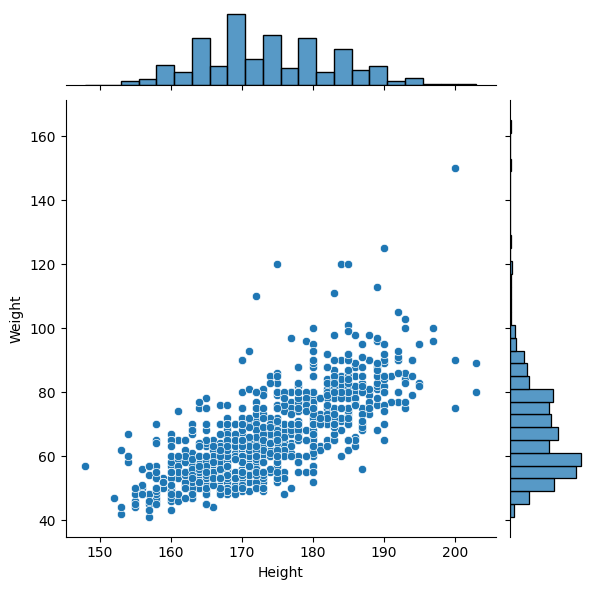
joint plot을 통해서 키와 몸무게 사이의 상관관계를 알아보자. joint plot은 산점도와 row와 column에 해당하는 데이터의 히스토그램까지 나온다
sns.jointplot(data = basic_info, x = 'Height', y = 'Weight')output
11.3 (실습) 요즘 인기 직업은 ?

code
import pandas as pd
df = pd.read_csv('drive/MyDrive/dataScience/data/occupations.csv', index_col = 0)
df.head(5)
women = df[df['gender']=='F'] # 성별이 여성인 데이터만 받기
women['occupation']
women['occupation'].value_counts().sort_values(ascending = False) # 각 직업이 얼마나 많이 있는지 확인 !output
student 60
other 36
administrator 36
librarian 29
educator 26
writer 19
artist 13
healthcare 11
marketing 10
programmer 6
homemaker 6
none 4
executive 3
scientist 3
salesman 3
engineer 2
lawyer 2
entertainment 2
retired 1
technician 1
Name: occupation, dtype: int64
code
men = df[df['gender'] == 'M']
men['occupation'].value_counts().sort_values(ascending=False)output
student 136
other 69
educator 69
engineer 65
programmer 60
administrator 43
executive 29
scientist 28
technician 26
writer 26
librarian 22
entertainment 16
marketing 16
artist 15
retired 13
lawyer 10
salesman 9
doctor 7
none 5
healthcare 5
homemaker 1
Name: occupation, dtype: int6411.4 상관 관계 분석
파일 불러오기
import pandas as pd
import seaborn as sns
df = pd.read_csv('drive/MyDrive/dataScience/data/young_survey.csv')
df.head(5)output
열이 너무 많아서 18번째까지만 보기로 함
music = df.iloc[:,:19]
music
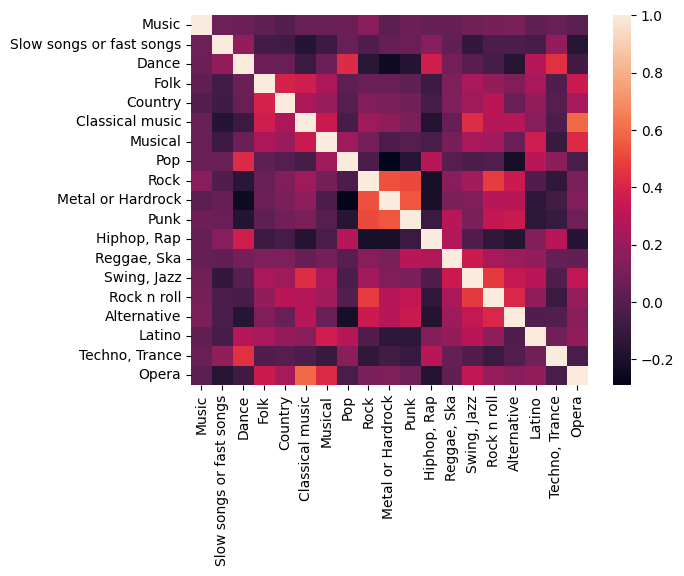
상관관계를 heatmap을 통해 알아보았땅
sns.heatmap(music.corr())output
그냥 숫자로만 판별하고자 한다면 df.corr()명령어를 쓰자
df.corr()output
나이만 알아보고 싶을 때는 뒤에 바로 괄호로 붙여주면 된다
df.corr()['Age']output
<ipython-input-8-440c5838b7f8>:1: FutureWarning: The default value of numeric_only in DataFrame.corr is deprecated. In a future version, it will default to False. Select only valid columns or specify the value of numeric_only to silence this warning.
df.corr()['Age']
Music -0.078058
Slow songs or fast songs 0.010998
Dance 0.031215
Folk 0.132414
Country 0.074586
...
Spending on healthy eating 0.015248
Age 1.000000
Height 0.122711
Weight 0.238893
Number of siblings 0.089174
Name: Age, Length: 139, dtype: float64내림차순으로 알아보자 !
df.corr()['Age'].sort_values(ascending = False)output
<ipython-input-9-bf891ef45536>:1: FutureWarning: The default value of numeric_only in DataFrame.corr is deprecated. In a future version, it will default to False. Select only valid columns or specify the value of numeric_only to silence this warning.
df.corr()['Age'].sort_values(ascending = False)
Age 1.000000
Weight 0.238893
Elections 0.212319
Prioritising workload 0.156256
Reliability 0.148141
...
Mood swings -0.111890
Getting up -0.119888
Questionnaires or polls -0.128187
Shopping centres -0.133800
Changing the past -0.146895
Name: Age, Length: 139, dtype: float6411.5 (실습) 브런치 카페 음악 셀렉션
대위는 신촌에서 대학생들을 대상으로 브런치 카페를 운영합니다.
손님들의 취향에 딱 맞는 음악을 틀고 싶은데요. 브런치 카페이기 때문에, 일찍 일어나는 사람들이 좋아할 만한 음악이 무엇인지 분석해 보려고 합니다.
주어진 데이터(다운로드)의 “Getting up”이라는 column을 보면 사람들이 아침에 일어나는 걸 얼마나 어려워하는지 알 수 있습니다. 5라고 대답한 사람들은 아침에 일어나는 걸 아주 어려워 하는 사람들이고, 1이라고 대답한 사람들은 아침에 쉽게 일어난다는 거죠.
이 데이터로 봤을 때, 아침에 일찍 일어나는 사람들이 가장 좋아할 만한 음악 장르는 무엇인가요?

code
import pandas as pd
df = pd.read_csv('data/young_survey.csv')
df.corr()
brunch_df = df.corr()['Getting up'] # 'Getting up' column에 대한 데이터 변수 선언
brunch_df[1:19].sort_values(ascending=True) # 음악 장르에 해당하는 column들 오름차순output
Opera -0.071819
Slow songs or fast songs -0.052613
Folk -0.049612
Punk -0.029189
Metal or Hardrock -0.026769
Country -0.025315
Latino -0.015060
Reggae, Ska -0.008434
Musical 0.011869
Classical music 0.014285
Swing, Jazz 0.019556
Techno, Trance 0.019863
Dance 0.027249
Alternative 0.027540
Rock n roll 0.028889
Hiphop, Rap 0.038980
Pop 0.079101
Rock 0.105245
Name: Getting up, dtype: float6411.6 (실습) 스타트업 아이템 탐색하기
경영학과 3학년이 된 영준이는 스타트업을 준비하고 있습니다.
사업 아이템을 고민하면서, 나름대로 가설을 몇 개 세워봤습니다.
- 악기를 다루는 사람들은 시 쓰기를 좋아하는 경향이 있을 것이다.
- 외모에 돈을 많이 투자하는 사람들은 브랜드 의류를 선호할 것이다.
- 메모를 자주 하는 사람들은 새로운 환경에 쉽게 적응할 것이다.
- 워커홀릭들은 건강한 음식을 먹으려는 경향이 있을 것이다.
이 내용을 사업 아이템으로 확장하기 전에, 데이터를 통해 가설을 검증해보려고 하는데요.
설문조사 데이터(다운로드)를 바탕으로, 가장 가능성이 낮은 가설을 골라보세요.
이 가설과 관련이 있는 column은 다음과 같습니다.
- Branded clothing: 나는 브랜드가 없는 옷보다 브랜드가 있는 옷을 선호한다.
- Healthy eating: 나는 건강하거나 품질이 좋은 음식에는 기쁘게 돈을 더 낼 수 있다.
- Musical instruments: 나는 악기 연주에 관심이 많다.
- New environment: 나는 새 환경에 잘 적응하는 편이다.
- Prioritising workload: 나는 일을 미루지 않고 즉시 해결해버리려고 한다.
- Spending on looks: 나는 내 외모에 돈을 많이 쓴다.
- Workaholism: 나는 여가 시간에 공부나 일을 자주 한다.
- Writing: 나는 시 쓰기에 관심이 많다.
- Writing notes: 나는 항상 메모를 한다.

code
#1
df.corr().loc['Musical instruments','Writing']output
0.3438162143904336#2
df.corr().loc['Spending on looks','Branded clothing']output
0.4183989446458902#3
df.corr().loc['Writing notes','New environment']output
-0.07939652994810617#4
df.corr().loc['Workaholism','Healthy eating']output
0.23864443283866715- 두 항목의 상관관계를 알아보고자 한다면
df.corr().loc['a','b']를 써주면 된다
11.7 클러스터 분석
클러스터 = 뭉쳐있는 무리
클러스터 분석 = 데이터들을 몇가지 부류로 나누는 것
df.head()output
관심 분야에 해당하는 열만 보기 위해
interests = df.loc[:,'History':'Pets']
interests.head()output
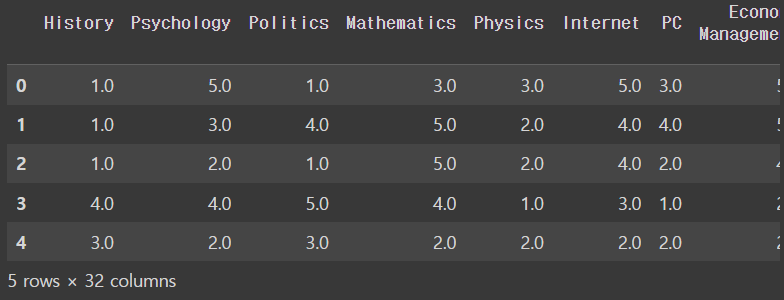
상관관계를 보고자 corr()씀
corr = interests.corr()
corroutput
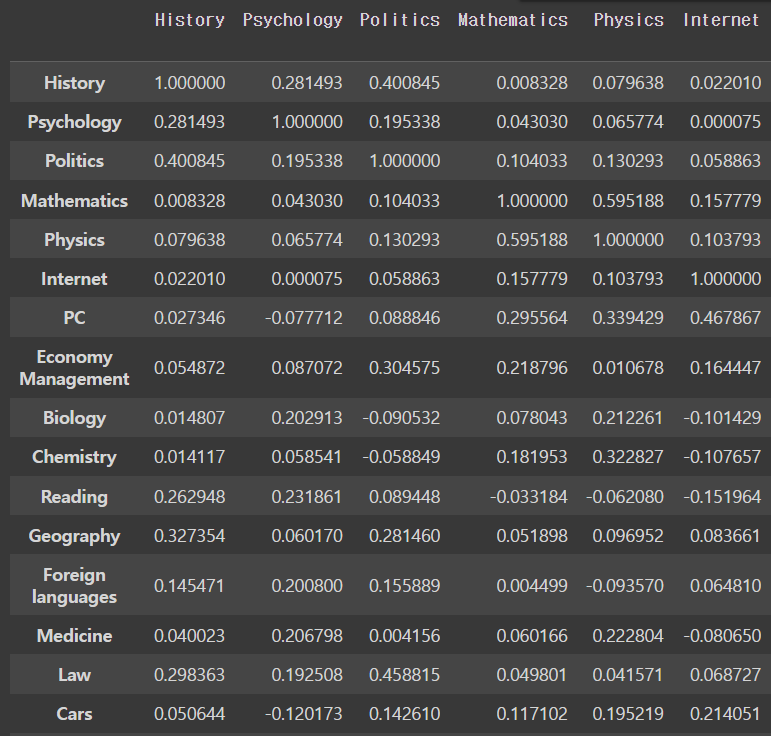
내림차순으로
corr['History'].sort_values(ascending = False)output
History 1.000000
Politics 0.400845
Geography 0.327354
Law 0.298363
Psychology 0.281493
Reading 0.262948
Religion 0.203840
Art exhibitions 0.200643
Theatre 0.185301
Writing 0.164617
Foreign languages 0.145471
Science and technology 0.135597
Musical instruments 0.107279
Countryside, outdoors 0.096609
Physics 0.079638
Active sport 0.064929
Adrenaline sports 0.061201
Economy Management 0.054872
Cars 0.050644
Medicine 0.040023
Gardening 0.033196
Dancing 0.032925
Pets 0.031920
PC 0.027346
Fun with friends 0.024960
Internet 0.022010
Biology 0.014807
Chemistry 0.014117
Mathematics 0.008328
Passive sport -0.013262
Shopping -0.061804
Celebrities -0.087338
Name: History, dtype: float64이번 강의에 처음 나온 clustermap !!
이거는 heatmap이랑 약간 비슷한데 행과 열에 연관성을 알려주는 사다리가 있음
sns.clustermap(corr)output
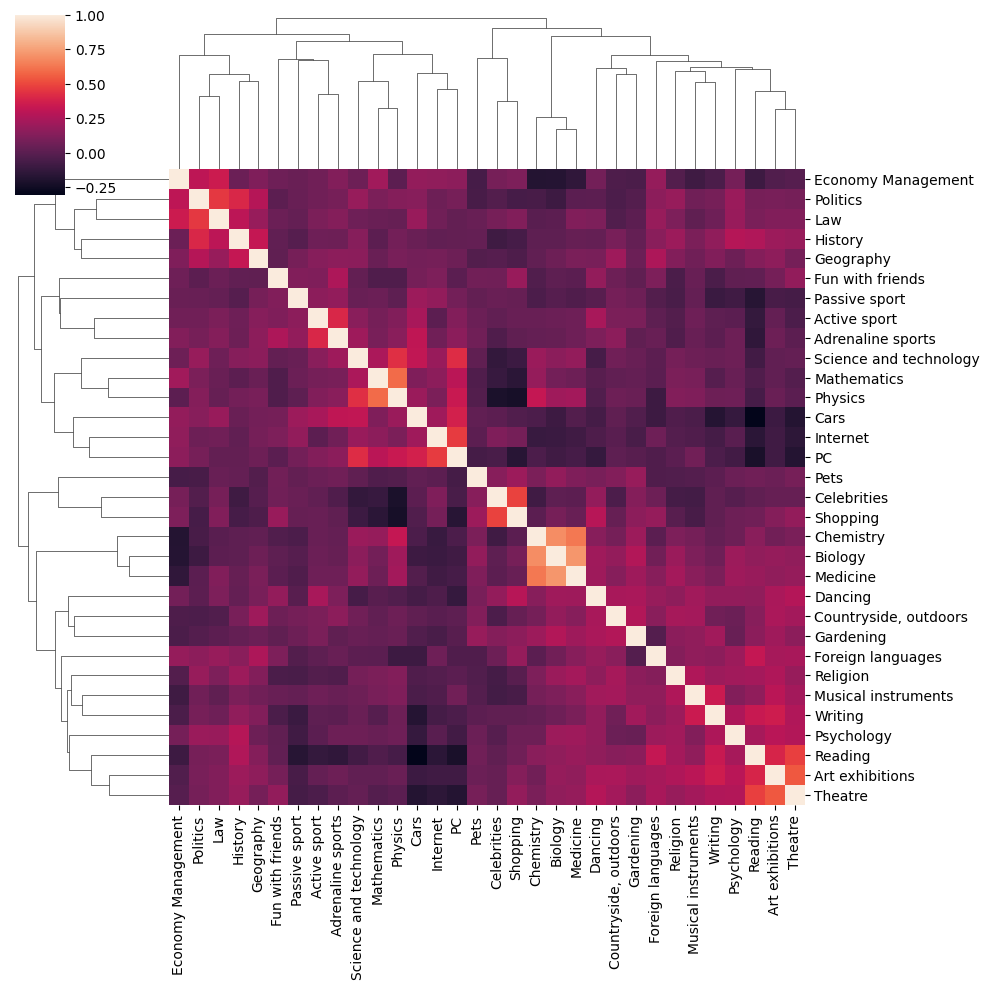
11.8 (실습) 영화 카페 운영하기
음악 선곡을 잘해서 대위의 브런치 카페는 대박이 났습니다. 그런데 브런치 카페이다 보니 저녁 시간대에는 가게가 텅텅 빌 수밖에 없죠.
고민 끝에, 저녁에는 가게를 영화 카페로 변신시켜 볼까 하는데요. 우선 수 많은 영화 DVD를 어떻게 배치해야 할지 고민입니다. 좀 연관된 장르끼리 묶어서 보관해야, 각 손님들의 취향을 잘 맞출 수 있을 것 같습니다.
이번에도 대박을 위해서 데이터의 도움을 최대한 빌리려고 합니다.
주어진 데이터셋에서 영화 장르에 대한 column은 'Horror'부터 'Action'까지 입니다. 영화 장르에 대해서 clustermap을 그려 보세요.
code
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/survey.csv')
genre = df.loc[:,'Horror':'Action']
corr = genre.corr()
sns.clustermap(corr)output
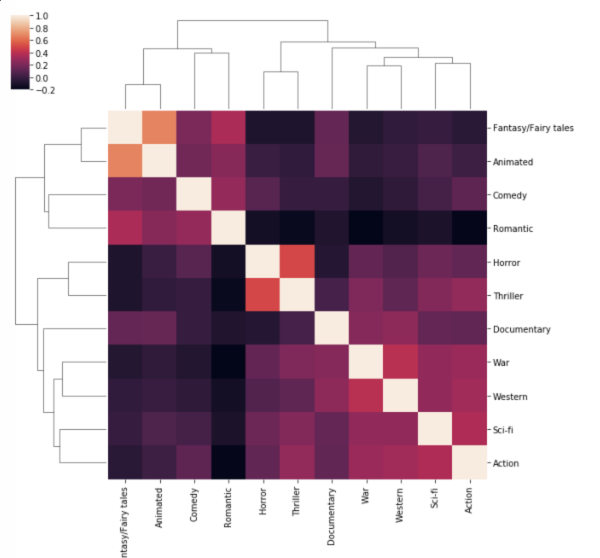
11.9 (실습) 영화 장르 분석하기
앞선 과제에서의 clustermap을 기반으로, 연관 있는 장르끼리 잘 묶인 것 같은 보기를 모두 고르세요.
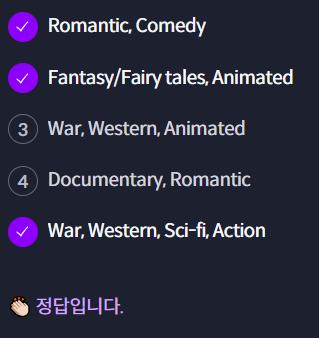
퀴즈 해설
그래프를 이용해서 보기를 하나씩 살펴봅시다.
1번: Romantic과 Comedy는 하나로 묶여 있습니다.
2번: Fantasy/Fairy tales와 Animated도 하나로 묶여 있습니다.
3번: War와 Western은 하나로 묶여 있지만, Animated는 따로 떨어져 있습니다.
4번: Documentary와 Romantic은 떨어져 있습니다. 둘 사이의 상관 관계가 비교적 낮다는 의미입니다.
5번: War과 Western은 하나로 묶여 있으며, Sci-fi와 Action도 하나로 묶여 있습니다. 그리고 이 두 그룹은 다시 더 큰 하나의 그룹으로 묶여 있습니다. 따라서 서로 연관 있는 장르라고 볼 수 있습니다.
11.10 타이타닉 EDA
RMS 타이타닉은 1912년에 빙산과 충돌해 침몰한 여객선입니다. 타이타닉호의 침몰은 무려 1514명 정도가 사망한 비운의 사건이죠. 영화 ‘타이타닉’으로 인해 이름이 가장 널리 알려진 여객선이기도 합니다.
우리에게 주어진 titanic.csv 파일(다운로드)에는 당시 탑승자들의 정보가 담겨 있습니다. 생존 여부, 성별, 나이, 지불한 요금, 좌석 등급 등의 정보가 있는데요.
- 생존 여부는
'Survived'column에 저장되어 있습니다. 0이 사망, 1이 생존을 의미합니다. - 좌석 등급은
'Pclass'column에 저장되어 있습니다. 1은 1등실, 2는 2등실, 3은 3등실을 의미합니다. - 지불한 요금은
'Fare'column에 저장되어 있습니다.
다양한 방면으로 EDA(탐색적 데이터 분석)를 한 후, 다음 보기 중 맞는 것을 모두 고르세요.

