최근 전처리 때 특히나 자주 사용하게 되는 기능들이 있었어서 정리한다.
0. 데이터프레임 생성 - DataFrame
일단, 앞으로 작성할 기능들을 위해 데이터프레임을 하나 생성한다.
딕셔너리를 사용해 쉽게 생성 가능하다.
import pandas as pd
dictionary = {'이름': ["민지", "하니", "다니엘", "해린", "혜인"],
'생년': [2004, 2004, 2005, 2006, 2008],
'혈액형': ["A", "O", "AB", "B", "O"]}
df = pd.DataFrame(dictionary)
1. 고유값 확인 - unique
해당 컬럼의 고유값을 확인한다.
df["혈액형"].unique()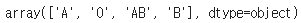
2. 컬럼 추가
데이터프레임에 컬럼을 추가할 때는 특별한 함수 없이 컬럼명과 컬럼값을 입력한다.
df["막내"] = ["X", "X", "X", "X", "O"]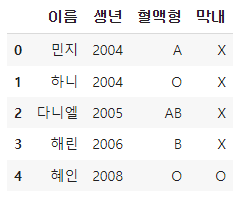
3. 행 또는 열 삭제 - drop
하나의 컬럼을 삭제하는 방법은 다음과 같다.
dropped_df = df.drop('막내', axis=1)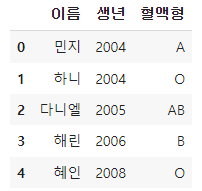
여러 개의 컬럼을 삭제하고 싶다면 리스트로 작성한다.
dropped_df = df.drop(['혈액형', '막내'], axis=1)
이때, inplace 파라미터를 True로 설정한다면, 기존 데이터프레임이 변경되며 None을 반환한다.
df.drop(['혈액형', '막내'], axis=1, inplace=True)디폴트 값은 False로, 따로 설정해 주지 않는다면 기존 데이터프레임은 바뀌지 않고, drop이 적용된 카피 데이터프레임을 반환한다.
4. 컬럼명 변경 - rename
컬럼명을 바꾸는 방법은 다음과 같다.
df.rename(columns={"이름":"name", "생년":"birth year"}, inplace=True)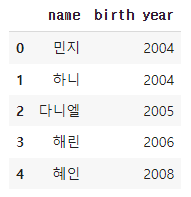
5. 데이터프레임에 함수 적용 - apply
데이터프레임의 행 또는 열에 함수를 적용한다.
2023년을 기준으로 'birth year' 컬럼을 통해 'birthyear_to_age'라는 함수로 세는나이를 계산해 'age'라는 컬럼을 새로 만들 것이다.
def birthyear_to_age(birth_year):
age = 2023 - birth_year + 1
return age
df['age']= df['birth year'].apply(birthyear_to_age)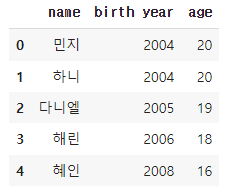
6. 결측치 확인 - isna
데이터프레임에 None 값 또는 numpy.NaN 값 같은 결측치가 있는지 확인한다.
axis를 0으로 설정하면 열을, 1로 설정하면 행을 기준으로 확인한다.
df.isna( ).any(axis=0)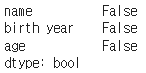
df.isna( ).any(axis=1)
다음과 같이 데이터프레임으로 결과를 보여 주는 방법도 있다. (결측치가 없어서 컬럼명만 보인다.)
df[df.isna( ).any(axis=1)]

이것저것 공부 중입니다