논문링크: Very Deep Convolutional Networks for Large-Scale Image Recognition

이번 논문은 AlexNet 뒤에 나온 VGG모델에 대한 논문입니다.
CNN 모델에서 깊이의 중요성을 이야기하는 논문으로, ImageNet Challenge 2014에서 2등을 한 모델입니다. 2등이었지만, 1등인 GoogLeNet보다 간단한 모델로 더 관심을 끌었다고 합니다. Abstract부터 논문의 순서대로 차근차근 정리해 보겠습니다.
Abstract
- 이 논문은 convolutional network의 깊이에 대한 연구이다.
- 작은 3 x 3 convolutional 필터를 사용하였고, 깊이는 16-19 weight 레이어를 사용한다.
- ImageNet Challenge 2014 제출의 기초가 되었고, 좋은 성능을 보여준다. 또한 다른 데이터 세트로 잘 일반화된다.
1. Introduction
- ConvNet의 간략한 설명: 컴퓨터 비전 영역에서 뛰어나며, ILSVRC 대회에서 사용 되어 중요한 역할을 했다. 첫 번째 layer의 window size와 stride를 작게하고, dense한 network를 사용하여 성능을 높였다.
- 이 논문에 대한 개요와 소개
- 이 논문에서는 모든 layer에 3 x 3 conv를 추가하여 깊이를 증가시켰다.
- Sect. 2: ConvNet configuration에 대해 설명
- Sect 3: 학습과 테스트에서의 세부 사항과 결과 설명
- Sect 4: the ILSVRC classification 작업 설명
- Sect 5: 결과
- Appendix에서 localization, generalization, the list of major paper revisions 설명
2. ConvNet Configurations
: 11개 layer를 가진 model A부터 19개 layer를 가진 model E까지인 VGGNet의 형태를 설명한다.
2.1. Architecture
: VGGNet의 기본적인 형태 설명를 설명한다.
- input size = 224 x 224이며, 전처리는 RGB 평균값을 빼는 작업만 실행했다.
- 기본적으로 3 x 3 필터 사용하였고, 1 x 1 필터를 중간에 넣은 configuration(model C)도 있다. (table 1 확인)
- 1 x 1 필터는 비선형성의 영향을 보고자 넣음
- stride = 1, padding = 1 (after conv)
- max pooling = 2 x 2, stride = 2
- 3개의 FC layer 사용
- 1, 2번째: 4096 channels
- 3번째: 1000 channels (class 개수)
- 마지막은 softmax 함수 사용
- 모든 hidden 레이어에는 ReLU를 사용했다.
- LRN(Local Response Normalization)은 메모리와 계산 시간만 증가시킬 뿐 성능 향상에는 도움이 되지 않았다.
2.2. Configurations
: table 1, 2를 소개한다.
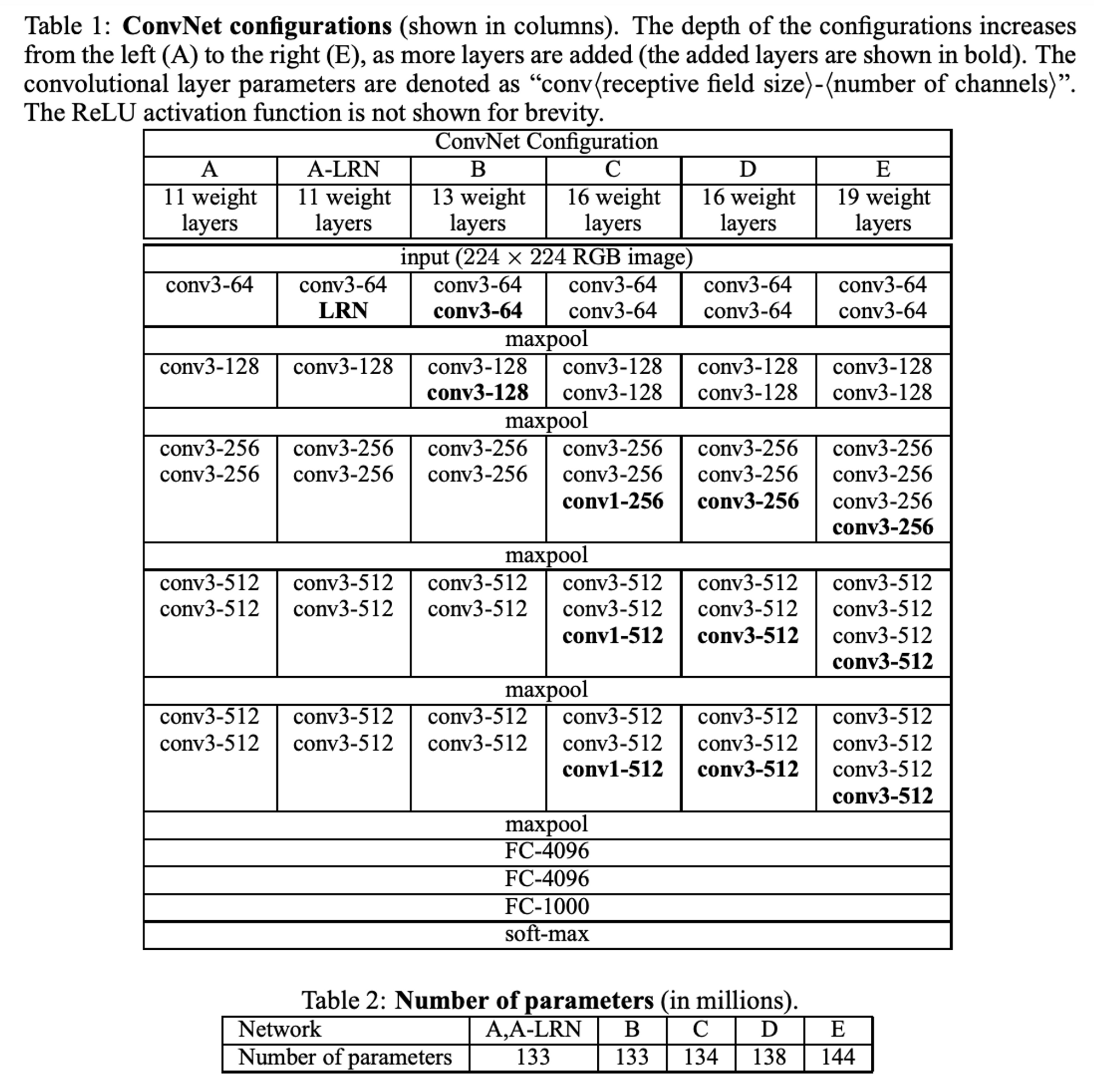
- A부터 E까지 점차 레이어의 수를 늘렸다. (11개 → 19개)
- 64부터 max pooling을 거쳐 512까지 늘어난다.
- A-LRN: 모델 A에 정규화 레이어를 하나 더 추가한 모델
- B, D, E: convolution layer를 더 추가한 모델들
- C: 모델 D와 깊이는 동일하지만, 3 x 3이 아닌, 1 x 1필터의 conv layer를 추가한 모델로, 비선형성만 증가시켰을 때의 결과를 보고자 했다.
- 깊이가 깊음에도 불구하고, 더 큰 conv 레이어와 수용 영역을 가진 네트워크에 비해 파라미터 수가 많지 않다.(Sermanet et al., 2014)
2.3. Discussion
- 7 x 7 필터를 1번 사용하는 것과 3 x 3 필터를 3번 사용하는 것은 동일한 수용 영역을 가지면서 네트워크를 더 깊게 만든다.
- 결정 함수의 비선형성이 증가한다.
- 학습 파라미터 수가 감소한다: 7 x 7 필터 1개에 대한 학습 파라미터 수는 49개, 3 x 3 필터 3개에 대한 학습 파라미터 수는 27(3 x 3 x 3)개이다.
- 이전 연구들과 비교
- Ciresan: 작은 필터를 사용하였지만 VGG보다 덜 깊다.
- GoogLeNet:L: 깊은 네트워크를 사용했지만 너무 복잡하다. 또한 피처맵의 spatial resolution이 계산량의 감소를 위해 첫번째 레이어에서 너무 크게 감소한다.
3. Classification Framework
: training, testing에서 세부사항을 설명한다.
3.1 Training
- 기본 내용
- 기본적으로 AlexNet과 비슷하지만, 추가적으로 mulit-scale 방식을 사용하였다. (아래에서 설명)
- 미니배치 경사하강법을 사용하여 다항 로지스틱 회귀를 최적화한다.
- 기본 하이퍼 파라미터
- batch size = 256
- momentum = 0.9
- weight decay: (L2 regularization)
- learning rate: 로 초기 설정을 한 후, validation set 정확도가 향상되지 않을 때까지 10배씩 감소시켰다.
- 370K iterations (74epochs)에서 학습 중단
- AlexNet과 비교하여 파라미터 수가 많고 네트워크가 더 깊음에도 불구하고, 다음의 두 가지 이유로 적은 epoch가 필요했다고 추측한다.
- implicit regularization imposed by greater depth and smaller conv filter sizes
- pre-initialization of certain layers
- 얕은 아키텍처(모델 A)부터 훈련 시작 (random init)
- 이후 학습된 첫 4개의 conv layers와 마지막 3개 FC layers의 가중치를 이용하여 깊은 아키텍처를 학습시켰다.(미리 가중치가 설정되기 때문에 수렴하기까지 적은 epoch이 필요했던 것)
- 가중치 초기화 값은 평균이 0이고, 분산이 0.01인 정규 분포에서 무작위 추출하여 진행했다.
- (논문 제출 후 Glorot&Bengio (2010)의 무작위 초기화 절차를 이용하여 사전 훈련 없이 가중치를 초기화하는 것이 가능하다는 것을 알아냈다.)
- 224 x 224의 사이즈를 얻기 위해, SGD 반복당 이미지 한 장 crop하였다. (아래에서 설명)
- 데이터 증강: random horizontal flipping, RGB color shift
- Training image size
S: 방향 상관없이 rescale된 training image에서 가장 작은 면을 칭함
예) 256 x 256의 input size에서 224 x 224 size로 무작위 crop하여 크기를 조정한다.
- single-scale
- S = 256, S = 384 두 고정된 scales에서 모델 평가 진행함
- 처음 S = 256으로 학습한 후, S = 384에서 훈련 속도를 높이기 위해 S = 256으로 사전학습된 가중치로 초기화하여 진행 (이 때, lr = )
- multi-scale
- 범위에서 무작위로 S를 샘플링하여 rescale된다. (논문에서는 = 256, = 512 사용)
- 속도 상의 이유로, S = 384로 고정된 사전 학습 모델의 레이어를 미세 조정하여 다중 스케일 모델을 훈련 시킴
- jittering?
multi-scale 방식을 말할 때 jittering이라는 표현을 쓰는데, 쉽게 생각해서 노이즈를 일부러 넣는 방법이라고 이해하면 될 것 같다.
3.2 Testing
Q: 사전에 정의된 가장 작은 이미지 면을 칭함 (테스트 스케일), 반드시 훈련 스케일인 S와 동일하지 않아도 된다.
- Q의 크기로 rescale 된다.
- 첫 FC layer → (7 x 7) Conv layer로, 마지막 2개 FC layer → (1 x 1) Conv layer로 변환하여 평가를 진행했고, 이 때 채널은 class 개수로 맞춰 출력하도록 설정했다.
- ⇒ 학습 이미지 사이즈와 같지 않아도 된다.
(1 x 1) Conv layer로 만들면, 결국 flatten 하는 순서만 바뀌고 동일한 구조로 만들어진다.
224 보다 큰 이미지가 들어올 경우 feature map이 (1 x 1)보다 클 수 있다. 그래서 마지막에 global average pooling을 사용하여 (1 x 1 x 1000)으로 만들게 된다.
(sum-pooling이라고 논문에는 나와있으나, 검색해본 결과 average pooling을 지칭하는 것으로 보인다.) - 마지막 class score map은 sum-pooled(GAP, global average pooling)한다.
- ⇒ 학습 이미지 사이즈와 같지 않아도 된다.
- horizontal flipping을 하여 augmentation 적용하며, 마지막 soft-max 는 원본 이미지와 flipped 이미지의 평균으로 하여 최종 score를 얻는다.
3.3 Implementation Details
C++ 기반의 Caffe를 사용했다.
기성 4-GPU 시스템에서 3.75배의 속도가 향상 되었고, 4개의 NVIDIA Titan Black GPU가 장착된 시스템에서 single net을 학습하는데에 2-3주가 소요되었다.
4. Classification Experiments
Datasets
- ILSVRC-2012 dataset 사용했다. 여기에는 1000개의 클래스가 존재한다.
- train set: 1.3M개, validation set: 50K개, test set: 100K개 (validation set을 test set으로 간주하여 사용)
- 평가 방식: top-1 error(multi-class classification error), top-5 error(ground-truth 범주가 상위 5개 예측 범주를 벗어나는 이미지의 비율)
4.1 Single Scale Evaluation
- test image size
- 고정된 S의 경우: Q = S
- S ∈ []의 경우: Q = 0.5()
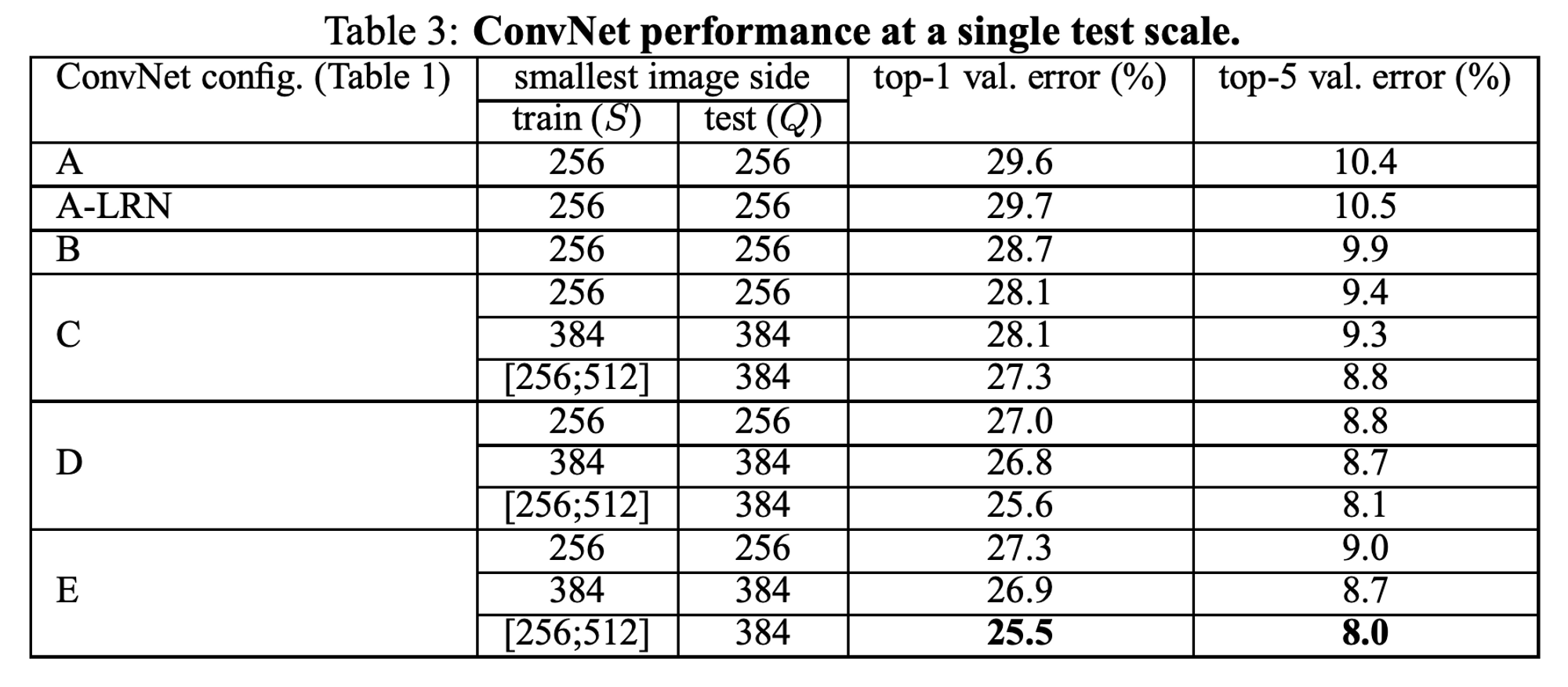
- A-LPN을 봤을 때, 정규화 레이어가 없는 모델 A와 비교해서 성능 향상이 없다.
그러므로 B-E 모델에서도 정규화를 사용하지 않는다. - ConvNet 깊이가 깊어질 수록 오류가 감소한다.
- 동일한 깊이일 때: 네트워크 전체에 3 x 3 conv 레이어를 사용하는 게 1 x 1 conv 레이어를 포함하는 것보다 낫다. (D와 C 비교)
⇒ 추가적인 비선형성이 도움이 되지만(C-B 비교), conv filter를 사용하여 spatial context를 잡아내는 것이 중요하다는 것 의미(D-C 비교) - 19 layers에서 포화되었지만, 더 큰 dataset에서는 더 깊은 네트워크가 도움이 될 것이라고 판단한다.
- 모델 B에서 한 쌍의 3 x 3 conv 레이어를 단일 5 x 5 레이어로 대체했을 때 top-1 error가 7% 더 높았다.
⇒ 작은 필터의 깊은 네트워크가 큰 필터의 얕은 네트워크보다 성능이 우수하다. - 테스트에서 단일 스케일을 사용하더라도, 고정된 S로 train하는 것보다, S ∈ []로 train하는 것이 더 낫다.
4.2 Multi Scale Evaluation
- single scale로 평가한 후, 테스트 시 jittering의 영향을 평가한다. error는 rescale된 여러 버전에서 수행한 다음 결과를 평균하여 나타냈다.
- train과 test scale이 큰 차이가 성능 저하를 초래한다는 점을 고려하여, 고정 S로 훈련된 모델은 Q = {S - 32, S, S + 32}로 세 가지 test 이미지 크기로 평가하였다.
- S ∈ []로 훈련된 모델은 Q = { , 0.5( ), }로 평가하였다.
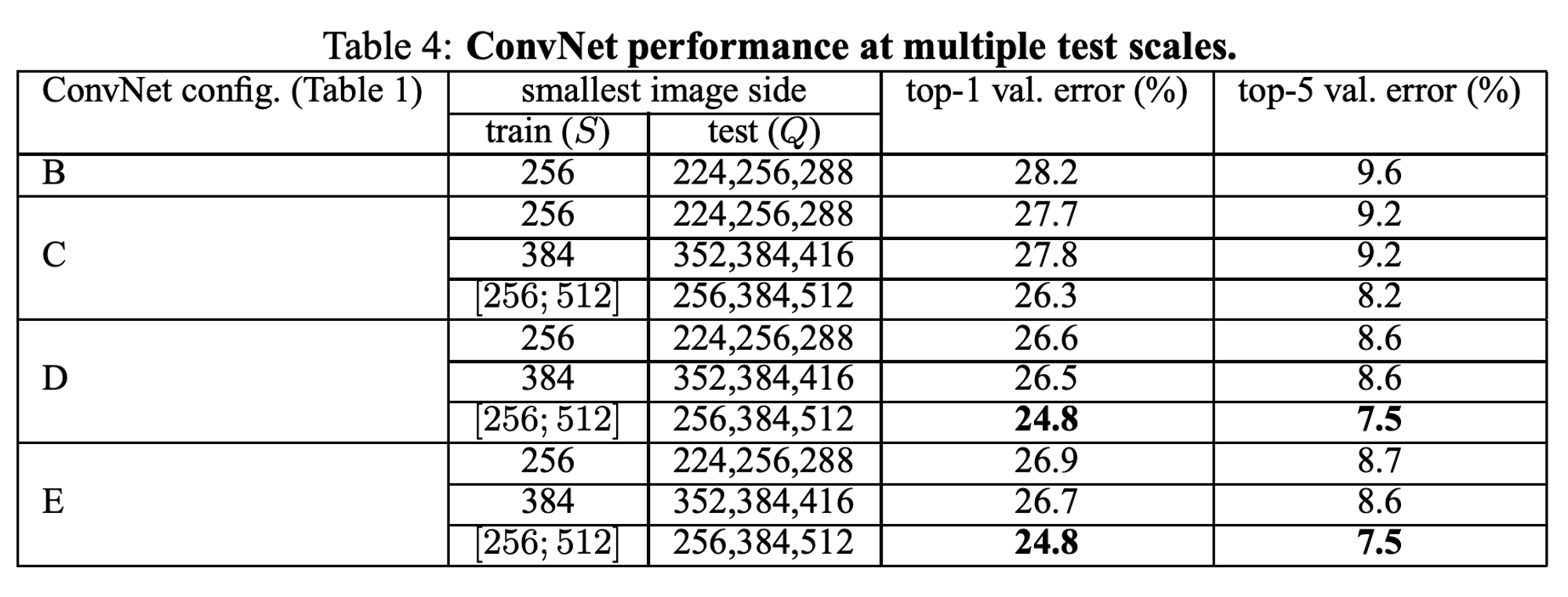
- scale jittering이 더 나은 성능을 보인다.
- D, E가 가장 우수한 성능을 보인다.
- validation set에서 가장 우수한 성능: 24.8% / 7.5%, test set에서 가장 우수한 성능: 7.3% (top-5 error)
4.3 Multi-Crop Evaluation
- multi crop evaluation과 dense ConvNet evalution을 비교 + 두 평가 기법 상호 보완하여 평가 진행했다.
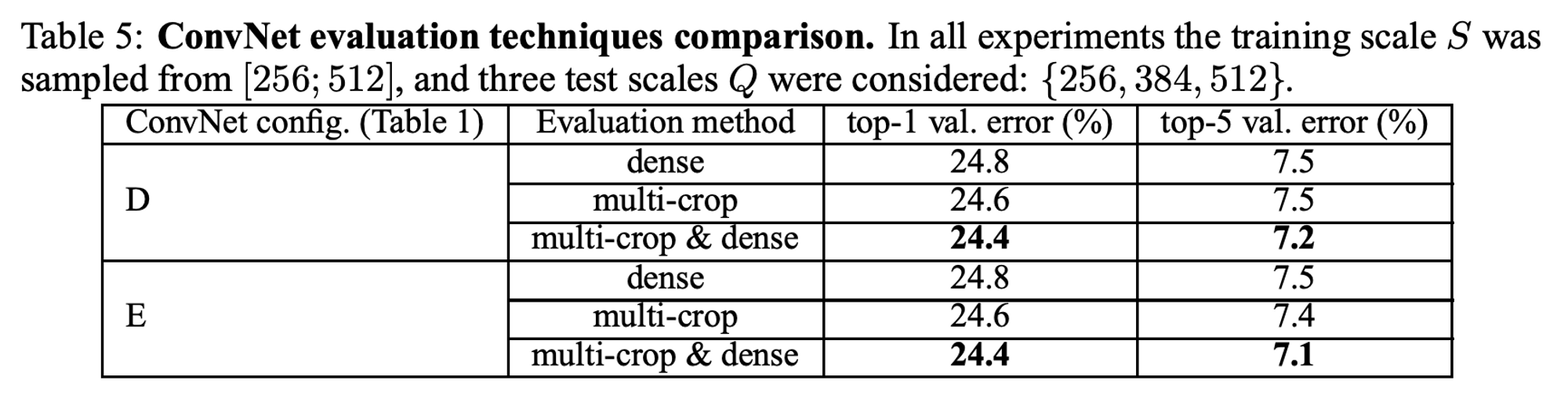
- multiple crops는 dense evaluation보다 약간 좋은 성능을 보이며, 두 방식을 결합한 것이 가장 뛰어난 성능을 보인다.
4.4 ConvNet Fusion
- soft-max class posteriors를 평균하여 여러 모델의 결과를 결합했다.

- ILSVRC 제출 때 single scale network와 multi-scale model D만 훈련했다.
7개의 네트워크의 앙상블 결과는 7.3% test error를 보였다. - 제출 후, dense evaluation을 사용하여 test error를 7.0%으로 줄였고, dense, multi-crop evaluation을 결합하여 6.8%까지로 test error를 줄였다. (D와 E만 앙상블하여 결과를 냄)
4.5 Comparison with the State of the Art
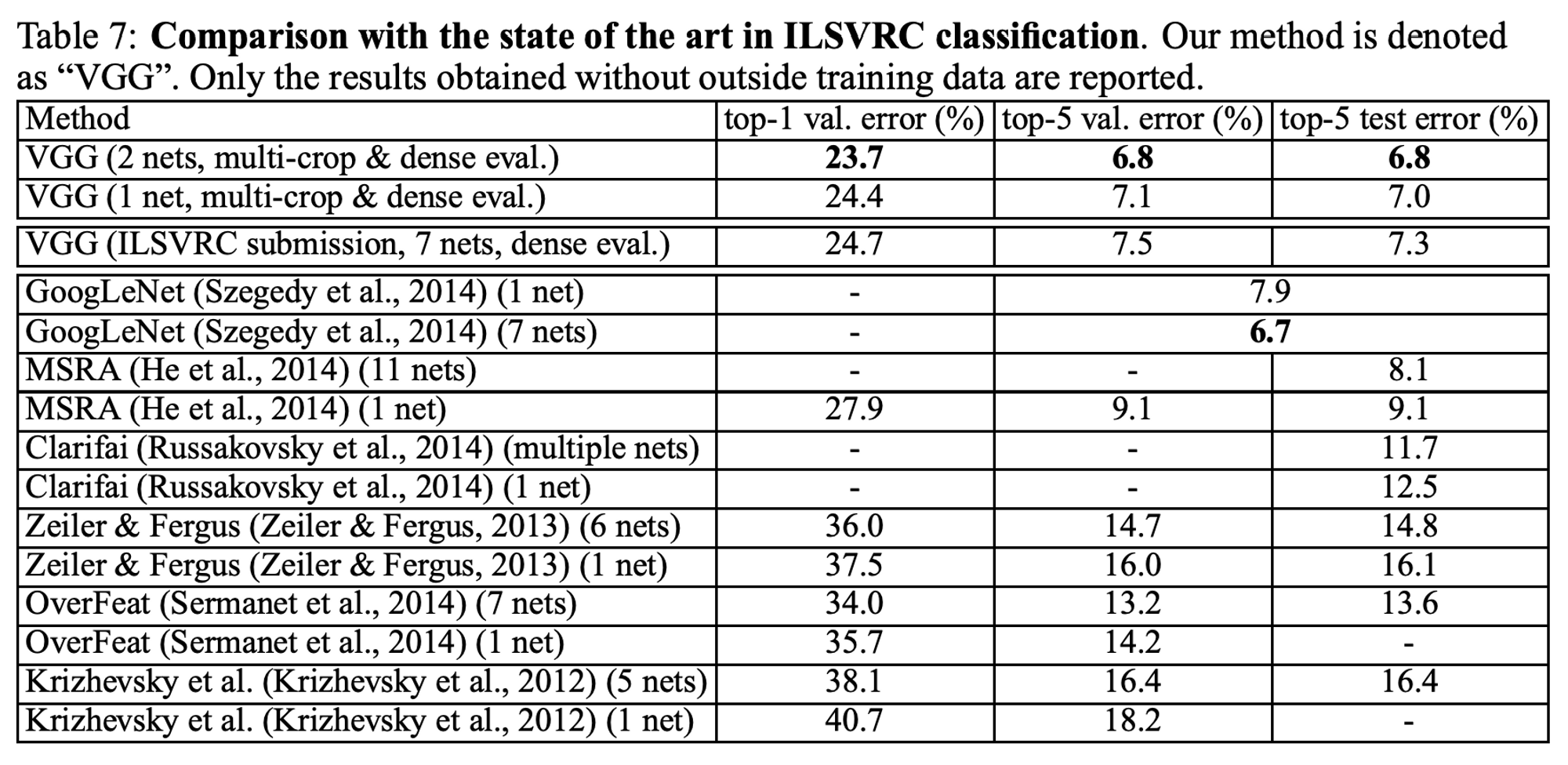
- ILSVRC 제출에서 사용한 것보다 적은 모델(2개 사용)을 결합하여 더 좋은 결과를 얻을 수 있다.
(1등한 GoogLeNet보다 성능이 좋다. 구글 단일 net일 때보다 VGG가 위에서 적은 것처럼 0.9% 더 낮은 에러를 보였다.)
5. Conclusion
- 깊이가 깊을 수록 성능이 좋다.
- Appendix를 보면, 더 넓은 영역에서의 작업과 다른 데이터셋에서도 VGGNet이 효가적임을 알 수 있다.
VGG 논문에서는 깊이의 중요성뿐만 아니라, 데이터 rescale 방법과 동일 조건 하에서 여러 모델들을 비교하는 부분을 학습할 수 있었습니다. 차근차근 비교하고, 여러가지를 결합하는 방식을 보며 재미를 느꼈습니다. :)
혹시 해석과 내용 중 틀린 점이 있다면 댓글로 알려주세요!
읽어주셔서 감사합니다. 😊
