PYTHON
배우기가 쉬움
중괄호가 없음 -> 들여쓰기로 구분(안쪽으로 4칸)
Interactive하게 실행 가능
: 나눠서, 단계별로, 내가 원하는 부분까지만 실행 가능
: 데이터분석하기 좋음
Library가 많음
Python version
2.x
3.x
둘은 호환이 안 됨. 나는 3.x를 사용
Pycharm -유/무료 => Django web programming
Jupyter notebook (web기반의 개발툴)
-> local에 설정 or colab(클라우드)
-> Data분석 M.L/D.L
brew install anaconda
구글 드라이브에 새폴더 생성 - Colaboratory 설치

이게 하나의 cell. 코드를 작성
command + enter 로 실행

재생버튼 쪽 누르고 + b : 새로운 코드 생성
Python의 built-in data type
- Numeric(숫자)
- Sequence
- Text Sequence
- Mapping
- Set
- Bool
1. Numeric(숫자)
정수, 실수, 복소수, 진수(8진수, 16진수)
# 1. Numeric(숫자)
# 정수, 실수, 복소수, 진수(8진수, 16진수)
a = 123 # 정수
b = 3.14159 # 실수
print (type(a)) # class 'int'
print (type(b)) # class 'float'
result = 3/4 #java인 경우 0
print(result) # python은 0.75
2. Sequence bulit-in data type
Sequence는 3가지가 있음
list (Python의 가장 중요한 자료구조이자, data type)
객체를 순서대로 저장하는 집합형 자료구조
Java의 ArrayList와 상당히 유사함
Literal은 어떻게 되나요? => []
myList = list() # 요소가 없는 list객체를 만든다
myList = [1, 3.14, 100] # literal로 list를 표현하기
print(type(myList)) # <class 'list'>
# 중첩 리스트도 가능
myList = [1, 2, 3, [3.14, 5.25, 100], 4, 5]
print(myList)
print(myList[0]) # 1 => indexing이 가능
print(myList[-1]) # 5 => indexing에 -가 있으면 뒤에서부터 셈
print(myList[])
# list의 연산
a = [1,2,3]
b = [4,5,6]
c = a + b
print(c) # [1, 2, 3, 4, 5, 6]
# list의 연산
a = [1,2,3]
b = [4,5,6]
c = a * 3
print(c)
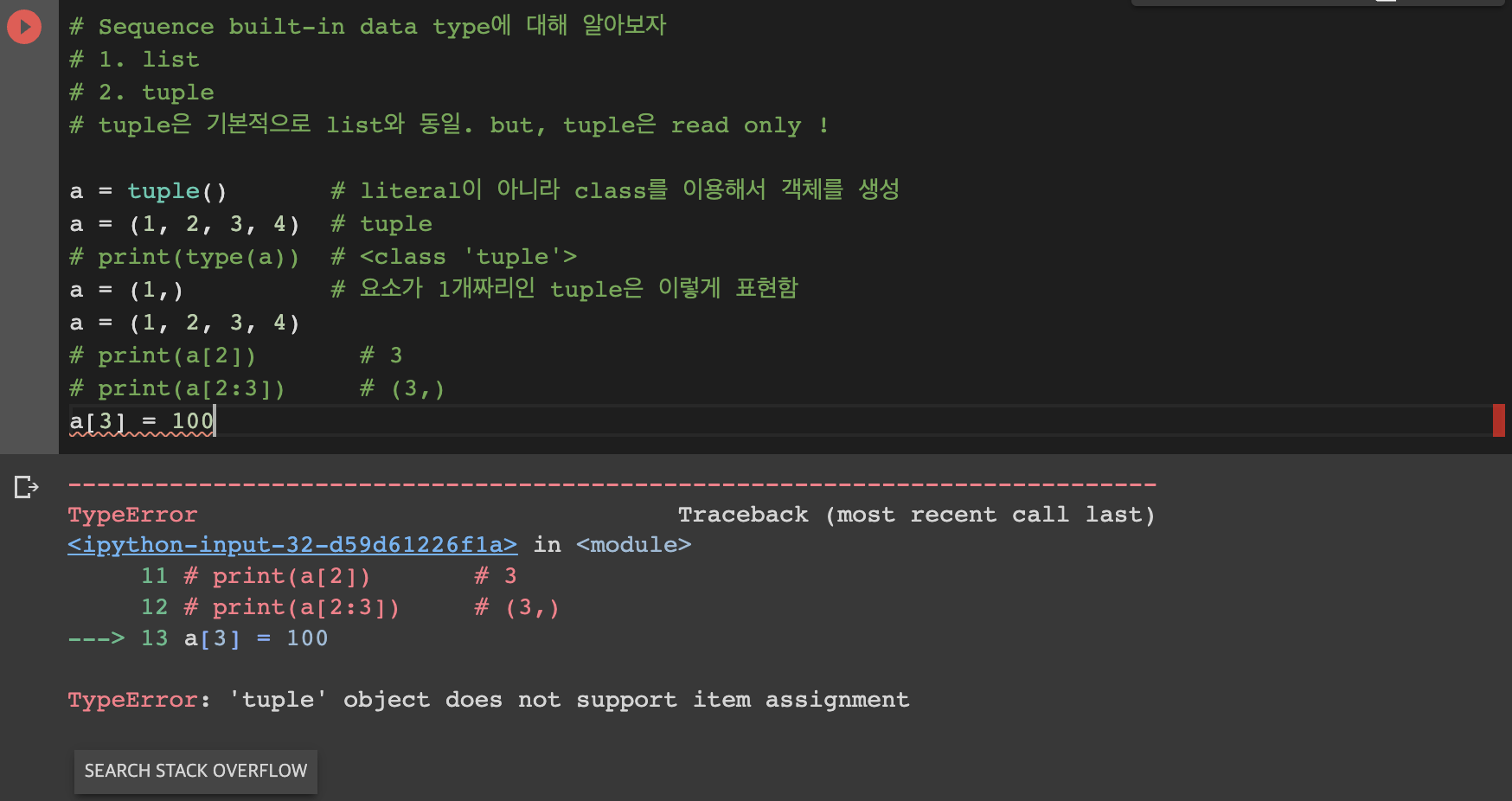
=> 튜플의 값은 바꿀 수 없음
3. Text Sequence
# 문자열 - 사용하는 클래스는 str
# literal은 '', "", 둘 다 사용 가능(dafault는 '')
# 문자개념이 없음. 모두 다 문자열임
a = '소리없는 아우성이란?'
print(type(a)) # <class 'str'>
# Text Sequence는 실제로 list임
# list의 성질을 그대로 이어 받음
a = '홍'
b = '은채'
print(a+b) # 홍은채
a = '소리없는 아우성이란?'
print(a[0]) # 소
print(a[0:3]) # 소리없
# 기억해야할 특이한 연산잗가 있음
print('소리' in a) # True (자바는 true, python은 True)
# 문자열은 str class의 객체임. 그러다보니, 굉장히 많은 method를 가지고 있음
print('{} 없는 {}'.format('소리', '아우성!'))
4. Mapping
4칸 들여써야함

Anaconda
가상환경 생성
conda create -n data_env python=3.8 openssl
가상환경으로 이동
conda activate data_env

기본 3개 module 설치
conda install numpy
conda install pandas
conda install metploalib
개발환경 module 1개 설치
conda install nb_conda
jupyter notebook --generate-config
jupyter notebook 실행
jupyter notebook
5.Set
# 5. Set
# 우리가 알고 있는 그 Set임
# 순서가 없음. 중복배제
# literal로 Set은 => {}
# [], {}(key와 value의 쌍으로 표현), ()
a = {1, 2, 3, 4, 1, 2, 3}
print(a) # {1, 2, 3, 4}
print(type(a)) #<class 'set'>
# for문
# for문은 2가지 형태로 사용됨
# 1. for ~ in range()
# 2. for ~ in list, dict
for test in range(10):
print(test)
# print() : 인자로 들어온 문자열을 출력하고 한줄을 띄움 !
for test in range(5):
print(test, end=', ')
a= ['홍','신','강']
for name in a:
print(name)
Numpy(Numerical Python)
: Numpy에 대해서 알아보자
: 여기서부터는 코드와 함께 이해해야함
: 데이터분석, 머신러닝, 딥러닝 이런 분야를 할 때, 가장 시간이 많이 걸리고 잘 해야 하는 것이
: 데이터 수집과 정제
: pandas(데이터 분석 module)와 matplotlib(시각화)의 base가 되는 기본 자료구조를 제공
: numpy는 딱 1개의 자료구조를 제공함
: n-d array
: 보다 적은 메모리를 필요로하고 훨씬 더 빠른 처리를 할 수 있음
: numpy는 외부 module이기 때문에 당연히 설치해야함
conda install numpy
import numpy as np
# python의 list
a = [1, 2, 3, 4, 5]
print(a) #[1, 2, 3, 4, 5]
b = np.array([1, 2, 3, 4, 5])
print(b) # [1 2 3 4 5]
print(type(b)) # <class 'numpy.ndarray'>
# 기억해야하는 특징 !
# list 안에는 아무거나 막 들어올 수 있음
c = [1, 3.14, '홍길동', True]
#ndarray는 반드시 같은 데이터 타입끼리만 들어올 수 있음
d = np.array([1, 2, 3.14, 4, 5])
print(d) # [1. 2. 3.14 4. 5. ]
print(d.dtype) # float64
# ndarray와 list의 가장 큰 차이점
# 차원을 표현할 수 있음
# 위에서 import했지만 코드의 안전성을 위해 한번 더 import했음
import numpy as np
myList = [[1, 2, 3], [4, 5, 6]] # 중첩리스트
print(myList)
arr = np.array(myList)
print(arr)
