arr = np.arange(0,12,1)
print(arr) #[ 0 1 2 3 4 5 6 7 8 9 10 11]
arr1 = arr.reshape(3,4) #3행 4열짜리 2차원배열로 바꿀 수 있음. 데이터 핸들링
print(arr1)
arr[-1]=100
print(arr)
print(arr1)
arr2 = arr.reshape(2,2,3)
arr = np.arange(0,12,1)
print(arr)
arr1 = arr.reshape(3,-1)
print(arr1)
arr = np.array([1,2,3,4,5])
print(arr) #1차원 ndarray
# arr + [3] 이면 shape이 맞지 않는데
# arr + [3,3,3,3,3]으로 바꿔서 shape을 맞춰서 연산을 수행시키려고 함 = broadcasting
# print(arr+3) #broadcasting
arr = np.arange(0,6,1).reshape(2,3)
print(arr + 3)
(2차원)행렬에 대해 사칙연산, 비교연산이 가능
행렬곱연산(Matrix Multiplication)->product
Pandas
데이터 처리(분석
: 데이터 처리(분석)을 하기 위해서는 우리가 사용하는 실제적인 module
: 기본적인 자료구조는 2개
1.Series : 1차원 ndarray를 기반으로 만든 자료구조
2.DataFrame : Series를 세로로 이어 붙여 만든 2차원 자료구조
- pandas를 설치해야 사용할 수 있음 !
conda install pandas
import numpy as np
import pandas as pd
s = pd.Series([-1, 5, 10, 99], dtype="float64")
print(s)
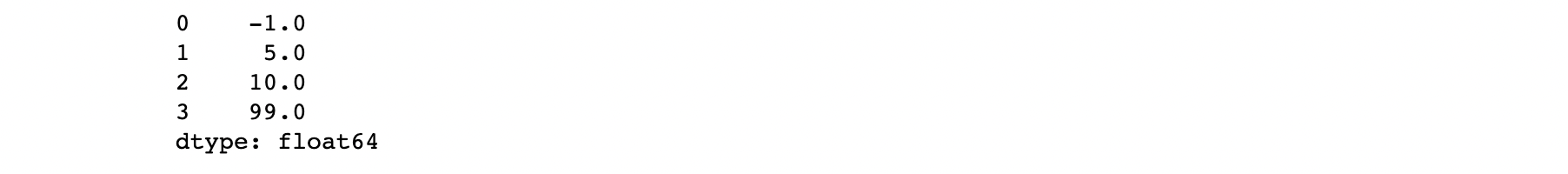
arr = s.values
print(arr) #[-1. 5. 10. 99.]
print(s.index) #RangeIndex(start=0, stop=4, step=1)s = pd.Series([1,5,-10,30],
dtype=np.float64,
index=['c', 'b', 'a', 'k'])
print(s)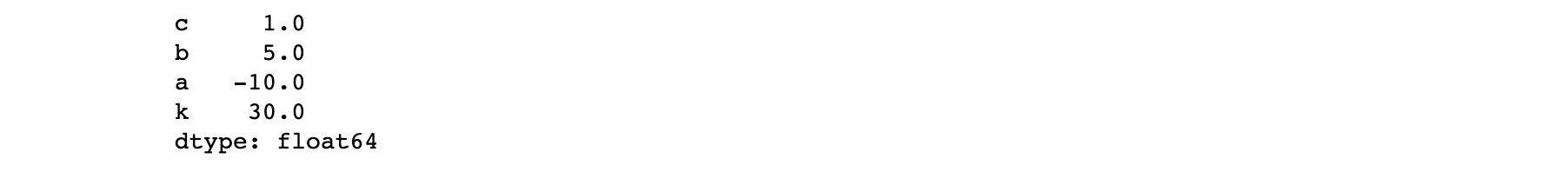
print(s[1]) #5.0
print(s['b']) #5.0
s = pd.Series([1, 5, -10, 30],
dtype=np.float64,
index=[0, 2, 100, 6]) #이 형태가 좋진 않음
print(s)
print(s[100])
s = pd.Series([1,5,-10,30],
dtype=np.float64,
index=['c', 'b', 'a', 'k'])
print(s)
# 혼동 금지
# print(s[0:3])
print(s['c':'k']) #지정 인덱스를 사용하면, c와 k를 모두 포함!
print(s[s%2==0]) #Boolean Indexing, Fancy Indexing 둘 다 사용가능.
print(s.shape)
Dictionary를 이용한 Series
: 이번에는 Series를 조금 다르게 만들어 보자
my_dict = {'서울':2000, '부산':3000, '인천':500}
print(type(my_dict)) #<class 'dict'>
s=pd.Series(my_dict)
print(s)
Series는 1차원 ndarray에 사용자 지정 index를 추가한 자료구조
: 일반적으로 Series를 직접 만들어 사용하는 경우는 많지 않음
: 대부분 DataFrame을 사용함(얘가 훨씬 편하고 기능도 많음)
: DataFrame은 Excel과 같음
import numpy as np
import pandas as pd
my_dict = {'names':['홍길동','신사임당', '강감찬'],
'year':[2020, 2021, 2022],
'point' : [3.0, 4.0, 2.2]}
# 키값이 컬럼명, []안에 있는 애들이 Data
# s = pd.Series(my_dict)
# print(s)
df = pd.DataFrame(my_dict)
display(df)
df = pd.read_csv('./data/movies.csv')
display(df.head())
print(df.shape) #9742,3
하이 반가워요😆💻