<복습>
Linear Regression
: 분류값이 아닌 것?
: 종속변수가 연속적인 숫자값
Logistic Regression
(binary classification)
: 학습데이터의 상태(종속변수)가 다시 변해요
: 0~1 사이의 확률값 1개
ex) 타이타닉?
Multinomial classification
: 클래스별 확률값(0.6 0.3 0.1)
: 데이터가 비정형데이터 형태로 변함 - 이미지
ex) BMI
정형데이터를 대상으로 함
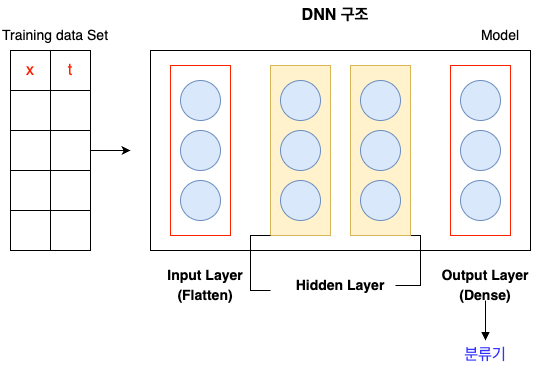
ANN(Articifial Neural Network) 인공신경망
: keras Model을 기본으로 생각하면 쉬움
: Layer를 추가로 input <-> output (사이에 hidden Layer추가) = DNN
DeepLearning
= DNN(Deep Neural Network)
: Image를 DNN을 이용해서 학습하면 좋을 것이라고 생각했지만, 문제가 있음
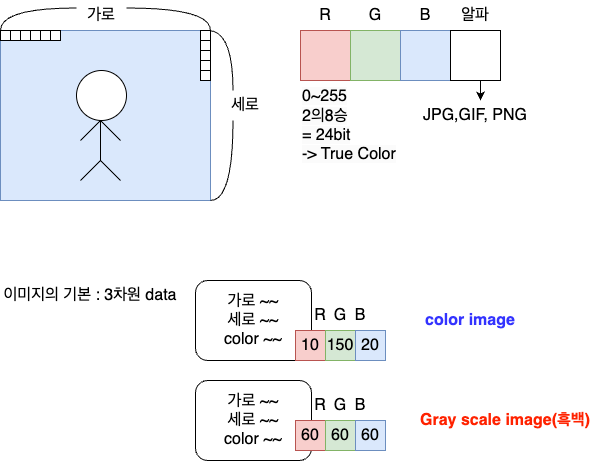
이미지입력 -> 기본적으로 3차원
DNN은 입력이 2차원
-> 해결
수행속도도 문제, 로컬에서 하면 라이브러리 충돌때문에 코랩에서 작업 !
Image파일에 대해 기억해야 하는 것
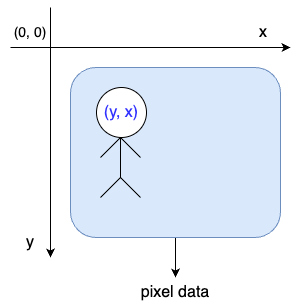
① 좌표계
일반적인 좌표계 - x축, y축
이미지는 image좌표계가 따로 있음
이미지의 기본 : 3차원 data(가로,세로,color)
CNN 실습
import numpy as np
from PIL import Image # 이미지 처리하기 편한 라이브러리
import matplotlib.pyplot as plt
color_img = Image.open('/content/drive/MyDrive/(KOSA)Python 실습/fruits.jpeg')# 우리가 필요한 건 ndarray
color_pixel = np.array(color_img)
# pixcel데이터를 이용해 그림을 그려보자
plt.imshow(color_pixel)
plt.show()
print('shape : {}'.format(color_pixel.shape))
# 위 그림을 흑백으로 바꾸기
# 각 pixcel의 RGB값을 평균내서 RGB칸에다 설정하면 흑백 처리됨
gray_pixel = color_pixel.copy()
for y in range(gray_pixel.shape[0]):
for x in range(gray_pixel.shape[1]):
gray_pixel[y,x] = np.mean(gray_pixel[y,x])
plt.imshow(gray_pixel)
plt.show()
print(gray_pixel.shape)
# 3차원 흑백이미지를 만들어봤음
# 흑백은 3차원으로 하는 것보다 2차원으로 표현하면 사이즈를 줄일 수 잇음
gray_2d_pixel = gray_pixel[:,:,0]
print(gray_2d_pixel.shape)
# 이미지를 2차원으로
plt.imshow(gray_2d_pixel, cmap='gray')
plt.show()
비정형 데이터의 가장 대표적인 image를 학습하려면 어떻게 해야하나요?
CNN(Convolutional Neural Network)
convnet(컨브넷)
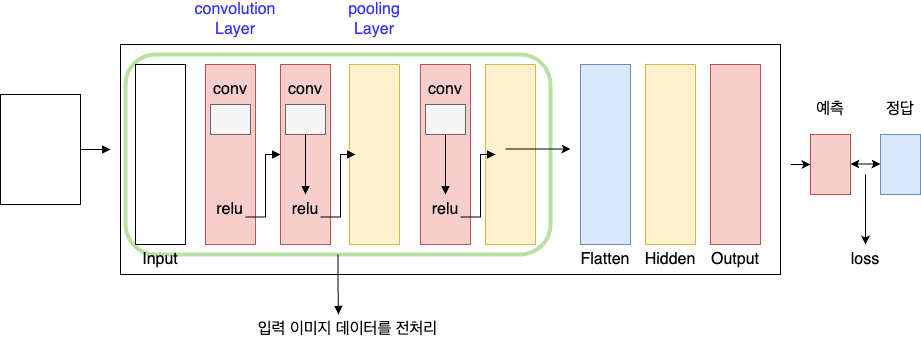
CNN(Convolutional Neural Network)
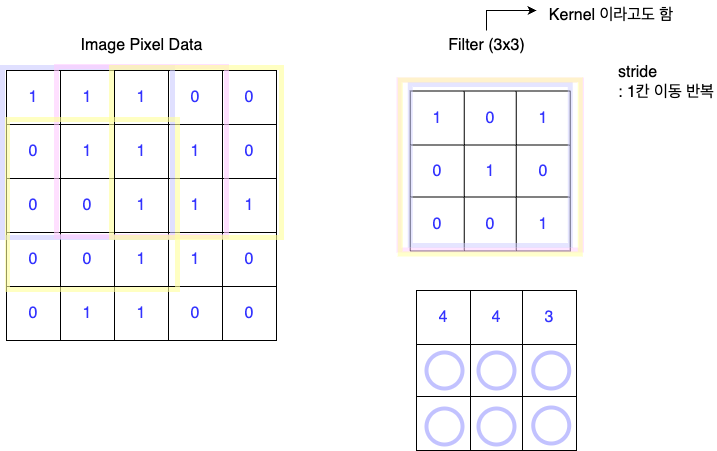
convolution연산 -> conv연산(합성곱 연산)
내가 가진 필터라는 정방형 커널을 이용해 각각의 위치에 맞게 곱하는 것을 합성곱이라고함
이동하는 간격을 stride라고 함
이미지의 크기를 키워주는 것을 padding
이를 이용하면 내가 가진 이미지의 크기가 변함. -> 왜 변화시키는가?
내가 가진 이미지의 특징을 이용해서 이미지를 변화시키는데,, 이 사이즈가 좀 줄어들지만 다양한 변화를 내는 것..이게 합성곱의 핵심
합성곱 연산을 수행하면 어떻게 되는지 code로 알아보자
합성곱연산(convolution)
: 이미지의 특징을 뽑아내서 학습에 좋은 이미지로 만드는 것
: Filter(kernel)에 따라 달라지고 여러개의 Filter를 사용함
: 이미지 1개가 특징만 추출한 이미지 여러개로 만들어짐 - 이미지의 사이즈가 줄어들고 너무 많은 양의 데이터가 생성됨
=> 이 문제를 해결하기 위해 Image size를 강제로 줄임 = pooling Layer가 하는 일
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.image as img# 도화지 준비
fig = plt.figure(figsize=(10,10)) # 가로세로 크기 inch단위
# 도화지를 두부분으로 나눔
ax1 = fig.add_subplot(1,2,1) # 1행 2열로 나눔
ax2 = fig.add_subplot(1,2,2)
ori_image = img.imread('/content/drive/MyDrive/(KOSA)Python 실습/girl-teddy.jpeg')
ax1.imshow(ori_image)
print(ori_image.shape)
# 입력이미지의 형태
# (1, 429, 640, 3) => (이미지 개수, height, width, color)
input_image = ori_image.reshape((1,) + ori_image.shape)
input_image = input_image.astype(np.float32)
print('Convolution input image.shape : {}'.format(input_image.shape))
# 입력이미지 channel 변경
# (1, 429, 640, 1) => (이미지 개수, height, width, color)
# slicing을 이용하여 첫번째 R(Red) 값만 이용
channel_1_input_image = input_image[:,:,:,0:1]
print('Channel 변경 input_image.shape : {}'.format(channel_1_input_image.shape))
# filter
# (3,3,1,1) => (filter height, filter width, filter channel, filter 개수)
weight = np.array([[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]]])
print('적용할 filter shape : {}'.format(weight.shape))
# 도화지 준비
fig = plt.figure(figsize=(10,10)) # 가로세로 크기는 inch단위
# 도화지를 위 아래 두 부분으로 나누기
ax1 = fig.add_subplot(1,2,1) # 행 1, 열 2, 순서 1번째
ax2 = fig.add_subplot(1,2,2) # 행 1, 열 2, 순서 2번째
# 이미지 불러오기
ori_image = img.imread('/content/drive/MyDrive/(KOSA)Python 실습/girl-teddy.jpeg')
t_img = conv2d[0,:,:,:]
ax1.imshow(ori_image)
ax2.imshow(t_img)
fig.tight_layout()
plt.show()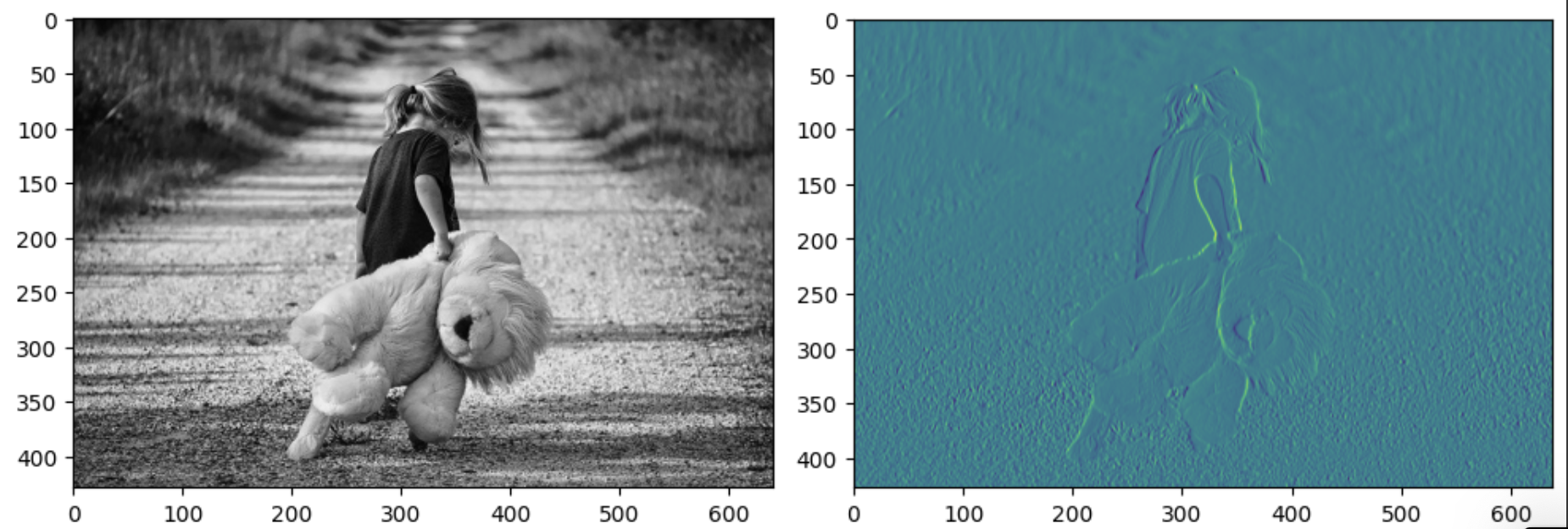
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.image as img
# 도화지
fig = plt.figure(figsize=(10,10)) # 가로세로 크기 inch단위
# 그림판 3장
ax1 = fig.add_subplot(1,3,1)
ax2 = fig.add_subplot(1,3,2)
ax3 = fig.add_subplot(1,3,3)
ori_image = img.imread('/content/drive/MyDrive/(KOSA)Python 실습/girl-teddy.jpeg')
# 첫번째 그림판에는 이미지 원본을 출력!
ax1.imshow(ori_image)
# 입력이미지의 형태
# (1, 429, 640, 3) => (이미지 개수, height, width, color)
input_image = ori_image.reshape((1,) + ori_image.shape)
input_image = input_image.astype(np.float32)
print('Convolution input image.shape : {}'.format(input_image.shape))
# 입력이미지 channel 변경
# (1, 429, 640, 1) => (이미지 개수, height, width, color)
# slicing을 이용하여 첫번째 R(Red) 값만 이용
channel_1_input_image = input_image[:,:,:,0:1]
print('Channel 변경 input_image.shape : {}'.format(channel_1_input_image.shape))
# filter
# (3,3,1,1) => (filter height, filter width, filter channel, filter 개수)
# weight = np.random.rand(3,3,1,1)
weight = np.array([[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]]])
print('적용할 filter shape : {}'.format(weight.shape))
# stride : 1 (가로1, 세로1)
# padding = 'VALID'
conv2d = tf.nn.conv2d(channel_1_input_image,
weight,
strides=[1,1,1,1],
padding='VALID').numpy()
t_img = conv2d[0,:,:,:]
# 2번째 그림판에 convolution한 이미지(특징을 뽑아낸) 출력
ax2.imshow(t_img)
## pooling 처리 ##
# ksize = pooling filter의 크기
pool = tf.nn.max_pool(conv2d,
ksize=[1,3,3,1],
strides=[1,3,3,1],
padding='VALID').numpy()
t_img = pool[0,:,:,:]
# 3번째 그림판에 pooling한 이미지(크기를 줄인) 출력
ax3.imshow(t_img)
fig.tight_layout()
plt.show()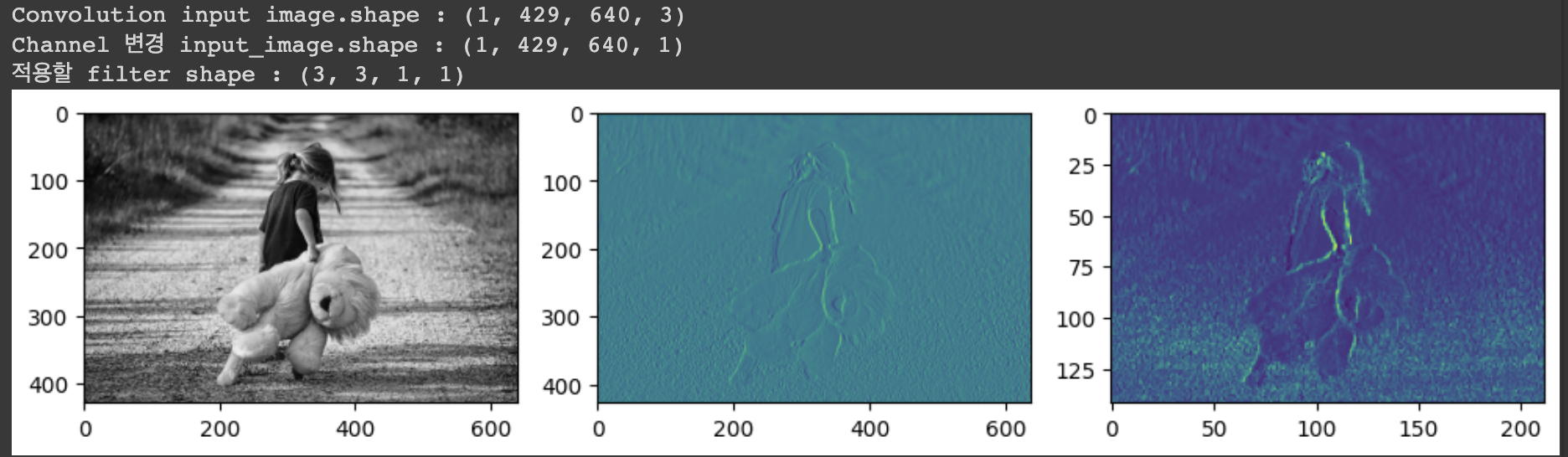
MNIST를 CNN으로 구현하기
- MNIST를 Multinomial Classification으로 구현 => 정확도
- MNIST를 DNN으로 구현 => 정확도
- MNIST를 CNN으로 구현 => 정확도
# 공통코드
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
# Raw Data Loading
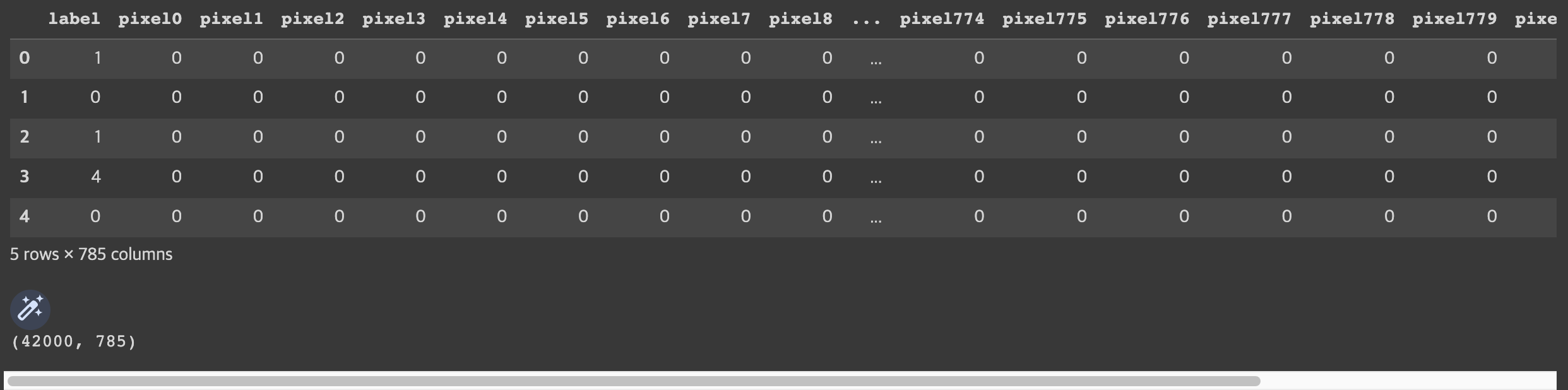
df = pd.read_csv('/content/drive/MyDrive/(KOSA)Python 실습/train.csv')
display(df.head(), df.shape)
# 공통코드
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
# Raw Data Loading
df = pd.read_csv('/content/drive/MyDrive/(KOSA)Python 실습/train.csv')
# display(df.head(), df.shape)
# 우리데이터는 샘플로 제공된 거라서 결측치/이상치가 없음
# 데이터를 나눠보자(train, test)
x_data_train, x_data_test, t_data_train, t_data_test = \
train_test_split(df.drop('label', axis=1, inplace=False),
df['label'],
test_size=0.3)
# 정규화 진행
scaler = MinMaxScaler()
scaler.fit(x_data_train)
x_data_train_norm = scaler.transform(x_data_train)
x_data_test_norm = scaler.transform(x_data_test)
# 첫번째 Model => Multinomial Classification(머신러닝)
model_1 = Sequential()
model_1.add(Flatten(input_shape=(784,)))
model_1.add(Dense(10, activation='softmax'))
model_1.compile(optimizer=Adam(learning_rate=1e-4),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_loss',
patience=3,
verbose=1,
mode='auto',
restore_best_weights=True)
model_1.fit(x_data_train_norm,
t_data_train,
epochs=2000,
validation_split=0.2,
verbose=1,
batch_size=100,
callbacks=[early_stopping])
# 첫번째 Model => Multinomial Classification(머신러닝)
# 평가는?
print(model_1.evaluate(x_data_test_norm, t_data_test))
# 두번째 Model => DNN(딥러닝)
model_2 = Sequential()
model_2.add(Flatten(input_shape=(784,)))
# hidden Layer가 포함되어야 함
model_2.add(Dense(64, activation='relu'))
model_2.add(Dense(128, activation='relu'))
model_2.add(Dense(32, activation='relu'))
model_2.compile(optimizer=Adam(learning_rate=1e-4),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_loss',
patience=3,
verbose=1,
mode='auto',
restore_best_weights=True)
model_2.fit(x_data_train_norm,
t_data_train,
epochs=2000,
validation_split=0.2,
verbose=1,
batch_size=100,
callbacks=[early_stopping])
# 두번째 Model => Multinomial Classification(머신러닝)
# 평가는? ====> 첫번째 모델 : 0.9226
# 두번째 모델 : 0.6171
print(model_2.evaluate(x_data_test_norm, t_data_test))
# 세번째 Model => CNN(딥러닝)
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dropout
model_3 = Sequential()
# Feature Extraction(Convoution 처리)
model_3.add(Conv2D(filters=32,
kernel_size=(3,3),
activation='relu',
input_shape=(28,28,1)))
model_3.add(MaxPooling2D(pool_size=(2,2)))
model_3.add(Conv2D(filters=64,
kernel_size=(3,3),
activation='relu'))
model_3.add(MaxPooling2D(pool_size=(2,2)))
model_3.add(Conv2D(filters=64,
kernel_size=(3,3),
activation='relu'))
model_3.add(Flatten())
# hidden Layer가 포함되어야 함
model_3.add(Dense(128, activation='relu'))
model_3.add(Dense(10, activation='softmax'))
model_3.compile(optimizer=Adam(learning_rate=1e-4),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_loss',
patience=3,
verbose=1,
mode='auto',
restore_best_weights=True)
model_3.fit(x_data_train_norm.reshape(-1,28,28,1),
t_data_train,
epochs=2000,
validation_split=0.2,
verbose=1,
batch_size=100,
callbacks=[early_stopping])
# 세번째 Model => CNN(딥러닝)
# 평가는? ====> 첫번째 모델 : 0.9226
# 두번째 모델 : 0.6171
# 세번째 모델 :
print (model_3.evaluate(x_data_test_norm.reshape(-1,28,28,1),
t_data_test))
CNN을 이용해서 Model을 학습하면 Image학습,예측에 좋은 결과를 얻을 수 있음
- 데이터는 어떤 형태로 입력해야 하나요?
- Model은 어떻게 만드나요? -> keras
- Model학습, 평가 -> keras
실사데이터를 이용해서 학습&예측하려면 어떻게 해야하나요?
