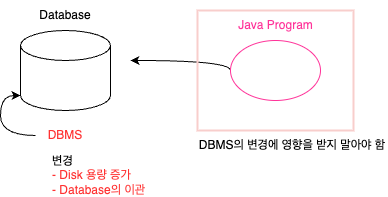
Database
: 데이터의 집합
: 관련성이 있는 / 대용량의 / 체계적으로 모아놓은 데이터의 집합체
: 이걸 사용하려면 여러개의 program(DBMS)이 있어야 함
DBMS(Database Management System)
: Database의 운영과 관리를 담당하는 software
| DBMS | vendor | |
|---|---|---|
| Oracle | Oracle | 유료 |
| MySQL | Oracle | 유료/무료 |
| MariaDB | MariaDB | 무료 |
| DB2 | IBM | 유료(main frame에서 사용) |
| SQL Server | MicroSoft | 유료 |
| Postgre SQL | PostgreSQL | 무료 |
- 운영/관리 측면
DBA - 개발 측면
DBMS의 특징
① 무결성(Integrity)
: 잘못된 데이터가 들어오면 안 됨
: 제약사항(constraints)을 이용해서 관리
② 독립성
③ 보안
④ 데이터 중복 최소화
⑤ 안정성
DBMS의 유형
⓪ file system
: 느리고, 불편하고, 보안성 없음
① 계층형 DBMS
폴더구조
② Network DBMS
: DBMS를 만들기가 너무 힘듦
③ IBM EF.codd (Relation)
: 데이터를 표(table)로 저장해서 DBMS 구현
: Relational DBMS(관계형 DBMS)
④ 객체지향의 시대(우리나라 기준 1990년대 중반부터 ~)
: 객체지향 DBMS 등장 -> R DB로 인해 망함
⑤ 객체-관계형 Database
: Oracle
RDB(Relational DBMS)
<-> 요즘에는 비정형 데이터 사용이 많아짐 (NoSQL DBMS : 대표적으로 Mongo DB ... )
MySQL
데이터가 저장되는 요소 : Table
MySQL 설치
https://dev.mysql.com/downloads/mysql/
1. community Server(메인)
2. workbench(GUI Tool)
3.
- CLI(Community Line Interpreter)
->Dos창(불편)
-> 그래서 일반적으로 GUI형태의 Tool을 이용 (DBeaver-유료, DataGrip-유료)
-> MySQL에서 workbench 무료 제공
포트번호 3306
-----------------------------------Window version
설정 - 정보 - 고급 시스템 정보 - 환경변수
mysql -u root -p
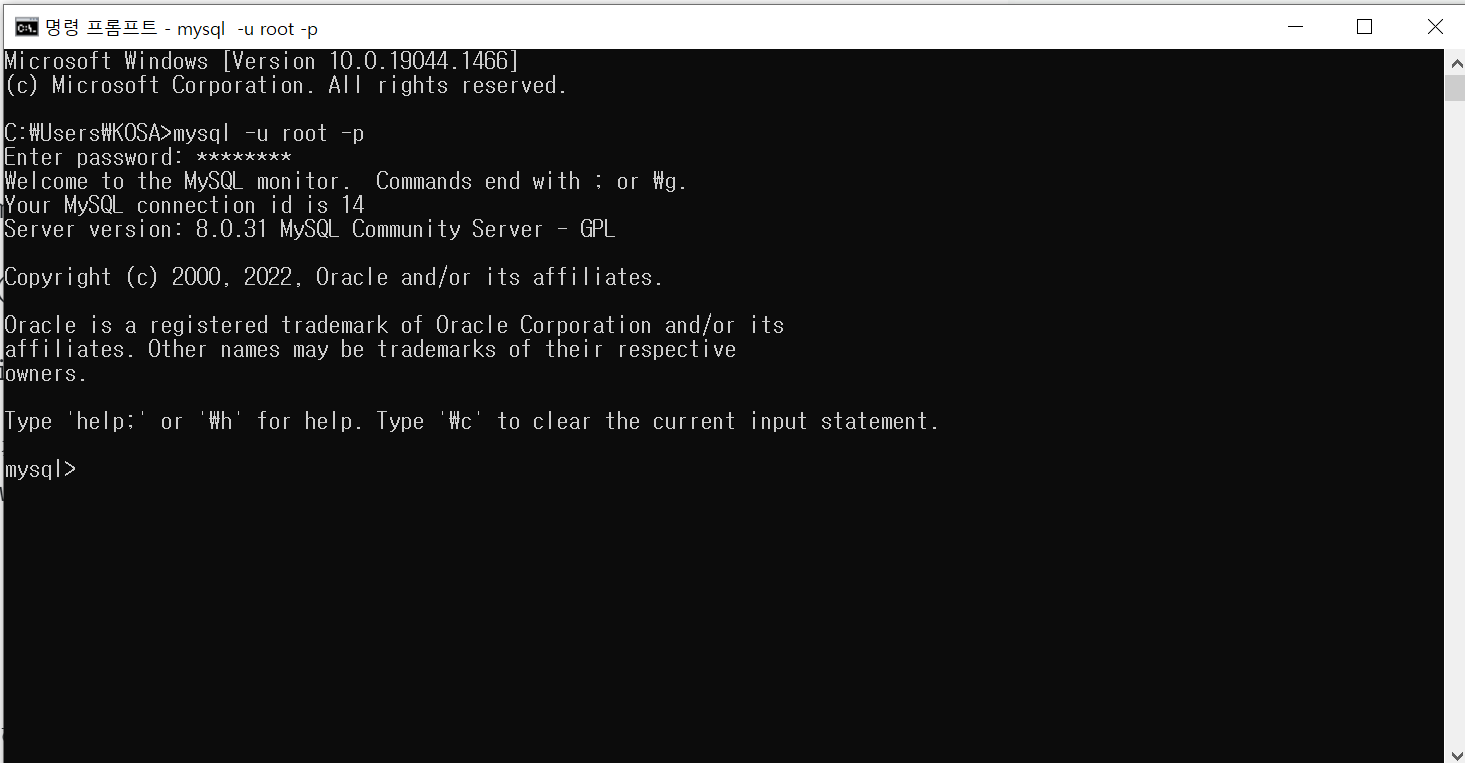
DOS창에서 사용하는 필터 : working Directory
Terminology(용어)
① Table : Data를 저장한느 표형태의 자료구조
② Database
: Table이 저장되는 고유의 Repository(저장소)
: DBMS안에 여러개 존재할 수 있고 이름이 붙어있음
③ DBMS : Database를 관리하기 위한 software들
④ column(열), colunm명, row(행) : Table과 연관됨
당연히 Data Type이 존재함
⑤
⑥
Key
: 특정 Column 지정
: row를 유일하게 식별할 수 있는 column
=> 여러개의 colunm으로 key를 구성할 수 있음(복합키)
모든 Table에는 Primary key가 있음
Foreign Key(외래키)
무결성 위배 - Foreing Key가 지칭하는 값이 다른 테이블에 없음
Database 생성
(MySQL에서는 schema와 Database가 동일 용어)
1. Table생성
memberTBL
| 열의미 | 컬럼명 | Data Type | 길이(여부) |
|---|---|---|---|
| 아이디 | memberID | 문자(CHAR) | 8글자 |
| 이름 | memberName | 문자(CHAR) | 4글자 |
| 주소 | memberAddr | 문자(CHAR) | 20글자 |
- 문자열
CHAR(20)
최대 20글자의 문자열을 의미
20칸 짜리 공간이 생김
VARCHAR(20)
내가 집어놓은 문자열에 따라 공간이 생김
=> 공간을 효율적으로 사용할 수 있으니 더 좋은 거 아닌가요?
연산은 char가 훨씬 빠름
Tool을 이용한 Data지정
SQL(Structed Query Language)
: 구조적 질의 언어
: 표준(표준이긴 하지만 DBMS에 따라서 그 내용이 상이)
SELECT 컬럼명들 FROM table 이름
(조건이 없어서 모든 데이터 대상)
SELECT memberName, memberAddr
FROM shopdb.memberTBL;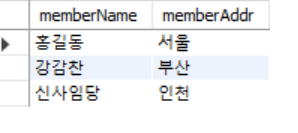
조건절 where
SELECT memberName, memberAddr
FROM memberTBL
WHERE memberAddr = '서울';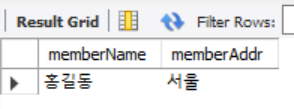
Index
: 속도를 높이기 위해 사용(아차하면 오히려 성능이 저하됨)
: 데이터가 많지 않을 때는 index가 큰 의미가 없음 BUT 데이터가 많아질 수록 수행속도 차이가 굉장히 큼
- 기본적으로 Column에 설정
Primary Key를 설정하면 해당 column은 index가 자동으로 설정
clustered Index로 설정(자동설정)
이거 말고 따로 특정 colume에 Index를 설정하는 것도 가능
Index를 사용하면 내부 자료구조가 생성됨
=> 많으면 많을수록 성능 저하
SELECT first_name, last_name, hire date
FROM employees.employees
LIMIT 500;
limit은 표준이 아님
create
테이블 생성
CREATE TABLE indexTBL (
first_name VARCHAR(14),
last_name VARCHAR(16),
hire_date DATE
);insert
INSERT INTO indexTBL
SELECT first_name, last_name, hire_date
FROM employees.employees
LIMIT 500;조회
SELECT *
FROM indexTBL;where 조건절
SELECT first_name, last_name, hire_date
FROM indexTBL
WHERE first_name = "Mary";index 생성
CREATE INDEX idx_indexTBL_firstname
ON indexTBL(first_name);