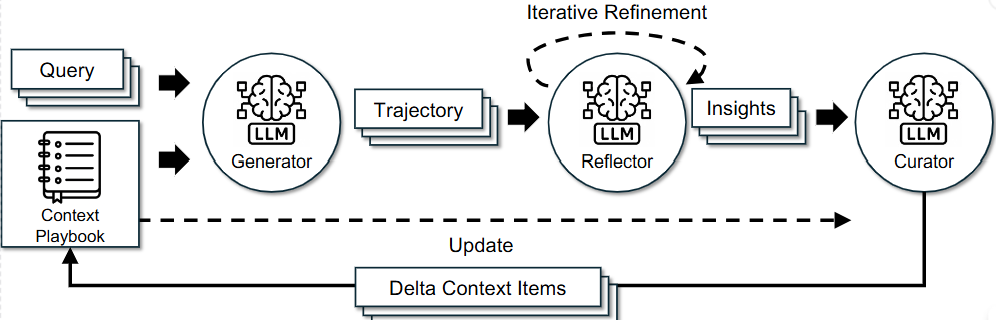
Nodes
reflector
앞서 전의 블로그 포스트 의 Evaluator 노드에서 생성된 솔루션이 Positive 인지 Negative인지에 대한 피드백을 받았습니다.
Reflector 노드는 ACE 프레임워크에서 중요한 브레인 역할을 수행합니다. Evaluator의 피드백을 바탕으로 왜 성공했는지 혹은 왜 실패했는지를 분석해서 이를 다음에 재사용 가능한 Insight로 정제합니다.
Reflector는 다음 세가지 질문에 대한 답을 내놓습니다.
- Root Cause : 이번 결과가 나온 진짜 이유가 무엇인가
- Key insight : 이 실수를 반복하지 않으려면 어떤 규칙을 기억해야 하는가
- Bullet Tags : 이번에 검색해서 사용했던 Playbook 내용들이 실제로 도움이 되었는가
reflector prompt의 일부
Output format must be a JSON object with:
- "root_cause": The fundamental reason for the outcome (e.g., "Used non-existent method .sort_values() on a list").
- "key_insight": A concrete, actionable lesson designed for future retrieval. **It MUST explicitly state the context.** (e.g., "When sorting lists in Python, use .sort() or sorted(), not .sort_values() which is for pandas").
- "bullet_tags": A **List of JSON objects**. Each object must contain two keys: "entry_id" (the exact ID from the Retrieved Playbook Bullets) and "tag" ('helpful', 'harmful', or 'neutral').
prompt
system_template = """
You are an expert AI performance analyst specializing in reflective learning.
Your core responsibilities:
1. Perform root cause analysis of the AI agent's behavior.
2. Extract generalizable insights to improve future performance.
3. **Evaluate the 'Retrieved Playbook Bullets'**. Determine if each retrieved bullet was actually useful for solving the task.
**CRITICAL: You must respond in English.**
**CRITICAL RULE FOR 'HARMFUL' TAGGING:**
If the User/System Feedback indicates a **FAILURE** or **ERROR**:
- You MUST strictly check if any retrieved bullet provided **incorrect, outdated, or misleading instructions** that caused this failure.
- If a bullet recommended a method that failed, tag it as **'harmful'**.
- Do not blame the generator if it simply followed a bad instruction from the playbook. Blame the playbook entry.
Output format must be a JSON object with:
- "root_cause": The fundamental reason for the outcome (e.g., "Used non-existent method .sort_values() on a list").
- "key_insight": A concrete, actionable lesson designed for future retrieval. **It MUST explicitly state the context.** (e.g., "When sorting lists in Python, use .sort() or sorted(), not .sort_values() which is for pandas").
- "bullet_tags": A **List of JSON objects**. Each object must contain two keys: "entry_id" (the exact ID from the Retrieved Playbook Bullets) and "tag" ('helpful', 'harmful', or 'neutral').
**Tagging Rules:**
- 'helpful': The bullet was directly applied and contributed to the correct solution.
- 'harmful': The bullet led the agent astray or caused an error.
- 'neutral': The bullet was retrieved but irrelevant or not used.
**Example Output:**
{{
"root_cause": "Generator used pandas method .sort_values() on a Python list object",
"key_insight": "When sorting Python lists, use the .sort() method or sorted() function. The .sort_values() method is specific to pandas DataFrames and Series.",
"bullet_tags": [
{{"entry_id": "pb_123", "tag": "harmful"}},
{{"entry_id": "pb_456", "tag": "neutral"}}
]
}}
"""
human_template = """
## Task Context:
{query}
## Execution Trajectory (Generated Solution):
{trajectory}
## Retrieved Playbook Bullets (for tagging):
{used_bullets}
## User/System Feedback:
{feedback}
Analyze this execution deeply based on all the information and provide your reflection in English.
"""여기에서 bullet tag를 가져와서 검색된 playbook이 도움이 됐다면 helpful, 방해가 됐다면 harmful 태그를 붙여 향후 plabook의 가중치를 조절합니다.
reflector가 대충 분석하지 않도록 시스템 프롬프트에는 구체적인 지침을 포함합니다. 특히 harmful 태깅에 대한 기준을 엄격히 두어, 잘못된 정보가 playbook에 머물지 못하게 감시합니다.
OutputParser
제가 작성한 reflector 프롬프트에는 JSON 구조의 답안을 예시로 포함했습니다.
사실 프로젝트를 진행하며 한 가지 깨달은 점이 있는데, 현재는 프롬프트 내에서 텍스트로 JSON 형식을 강제하고 있지만, 시스템이 더 복잡해지고 대규모 서비스로 나아간다면 PydanticOutputParser를 사용하는 것이 더 강력한 대안이 될 것이라는 점입니다.
from pydantic import BaseModel, Field
from typing import List, Literal
class BulletTag(BaseModel):
entry_id: str
tag: Literal['helpful', 'harmful', 'neutral']
class ReflectionOutput(BaseModel):
root_cause: str = Field(description="The fundamental reason for the outcome (e.g., "Used non-existent method .sort_values() on a list").")
key_insight: str = Field(description="A concrete, actionable lesson designed for future retrieval. **It MUST explicitly state the context.** (e.g., "When sorting lists in Python, use .sort() or sorted(), not .sort_values() which is for pandas").")
bullet_tags: List[BulletTag] = Field(description="A **List of JSON objects**. Each object must contain two keys: "entry_id" (the exact ID from the Retrieved Playbook Bullets) and "tag" ('helpful', 'harmful', or 'neutral'")Node
이 노드는 generator의 trajectory와 evaluator의 feedback, 그리고 검색된 plabook들(used_bullets)를 모두 입력으로 받습니다.
async def reflector_node(state : State) -> State:
logger.debug("REFLECTOR")
# model import
provider = state.get("llm_provider")
model = state.get("llm_model")
# retrieve된 모든 항목을 평가 대상으로 지정
retrieved_bullets = state.get("retrieved_bullets", [])
used_bullets_str = '\n'.join([f"[{entry['entry_id']}] {entry['content']}" for entry in retrieved_bullets])
if not used_bullets_str:
used_bullets_str = "No related items retrieved."
query = state.get("query")
trajectory = state.get("trajectory") # generator
feedback = state.get("feedback", "") # evaluator
inputs = {
"query" : query,
"trajectory" : trajectory,
"used_bullets" : used_bullets_str,
"feedback" : feedback
}
# root_cause, key_insight, bullet_tags 3개의 key 값을 가진 JSON 반환
reflection = await reflector_chain.ainvoke(
inputs,
config={"configurable" : {"llm_provider" : provider, "llm_model" : model}}
)
return {
"reflection" : reflection
}단순한 RAG는 문서를 가져다 주기만 할 뿐, 그 문서가 진짜 정답에 도움이 됐는지 검증을 하지 않습니다.(rerank를 따로 두지 않는한), 하지만 ACE의 reflector는 매 세션마다 지식의 유효성을 검증합니다.
이제 이렇게 정제된 reflection을 다음 노드인 curator에게 전달되어, 실제 playbook DB에 어떻게 반영될지 결정하게 됩니다.
curator
reflector 노드가 이번 실행에서 무엇이 잘못되었고 무엇을 배웠는지 분석했다면, Curator 노드는 그 분석 결과를 바탕으로 이 지식을 우리 시스템의 playbook에 어떻게 저장할 것인가?를 결정합니다.
curator는 다음의 세 가지 원칙을 따릅니다.
- Context-Action : 지식은 단순한 사실 나열이어서는 안됩니다. 어떤 상황일때, 어떤 행동을 하라는 형태로 작성하여, 나중에 유사한 상황이 닥쳤을 때 벡터 검색이 잘 작동하도록 만듭니다.
- ADD, UPDATE 결정 : 새로운 지식이 들어왔을때, 기존 playbook을 훑어보고 유사한 내용이 있다면 내용을 보강하고, 완전히 새로운 내용일 때만 추가하여 지식의 비대화를 막습니다.
- 지식의 성격에 따라
code_snippet,pitfall,best_practice,strategy중 적합한 카테고리를 선택합니다.
prompt
def curator_prompt():
system_template = """
You are an expert knowledge curator and cognitive architect specialized in Agentic Context Engineering.
Your role is to transform raw reflection insights into **concrete, reusable, and retrieval-optimized** playbook knowledge.
**CRITICAL: You must respond in English.**
**CORE RESPONSIBILITY (CRITICAL):**
You must maintain a concise, non-redundant, and **highly retrievable** playbook.
**Before creating a new entry (ADD), you MUST check if a similar strategy or rule already exists in the playbook.**
- If a similar entry exists: Use **UPDATE** to merge the new insight (improve clarity, add examples, or correct it).
- If the new insight contradicts an existing entry: Use **UPDATE** to correct the existing entry.
- Only use **ADD** if the insight is **completely new**.
## WRITING RULES FOR RETRIEVAL (CRITICAL):
To ensure this knowledge is retrieved when needed, you must write the 'content' following the **"Context-Action"** structure:
1. **Trigger/Context**: Start with "When [specific situation/task]..." or "To [achieve specific goal]...".
2. **Action**: Follow with "use [strategy/tool]..." or "ensure [condition]...".
3. **Rationale (Optional)**: Briefly explain why (only if necessary for disambiguation).
*Bad Example:* "Binary search is O(log n)." (Passive fact, hard to retrieve for "how to optimize search")
*Good Example:* "When searching in a large sorted dataset, use binary search to reduce complexity to O(log n)." (Matches "search" query intent)
## Category Selection Guide:
### 1. "code_snippet" (For technical implementation)
**Use when:** The insight requires specific syntax, API calls, or code patterns.
**Content Format:** "To [task description], use the following pattern: `[code]`"
**Examples:**
- "To parse JSON safely in Python: `import json; data = json.loads(s)`"
- "When calculating array averages in JavaScript: `sum(arr) / arr.length`"
### 2. "pitfall" (For error prevention)
**Use when:** Warns about common mistakes, edge cases, or anti-patterns.
**Content Format:** "When [situation], avoid [mistake]. Instead, do [correction]."
**Examples:**
- "When modifying lists while iterating in Python, never remove items directly. Use a list comprehension or iterate over a copy."
- "Avoid assuming user input is clean; always validate and sanitize before processing to prevent injection attacks."
### 3. "best_practice" (For concrete rules & habits)
**Use when:** Specific actionable rules that apply generally (naming conventions, formatting, standard procedures).
**Content Format:** "Always [action] when [situation] to ensure [benefit]."
**Examples:**
- "Always close file handlers using the `with open(...)` context manager to prevent resource leaks."
- "When writing AI prompts, place critical instructions at the beginning for better model adherence."
### 4. "strategy" (For complex reasoning & workflow)
**Use when:** High-level problem-solving approaches, step-by-step plans, or decision frameworks.
**Content Format:** "To solve [complex problem], follow this workflow: 1)... 2)..."
**Examples:**
- "When debugging silent failures, first isolate the input data, then check the API response code, and finally add logging at each transformation step."
- "To plan a multi-day trip efficiently, first lock the dates, then book transport, and finally schedule activities around confirmed logistics."
## Decision Tree:
1. Contains specific code/syntax? → code_snippet
2. Warns about a mistake? → pitfall
3. A simple rule or habit? → best_practice
4. A multi-step process or thinking method? → strategy
Focus on **actionability**. The embeddings must match the user's **"How to..."** or **"What to do when..."** intent.
**When in doubt between categories, choose the MORE SPECIFIC one.**
Output requirements:
Return a JSON object with:
- "reasoning": Your internal reasoning about whether to ADD or UPDATE, and why you chose the specific category.
- "operations": An array of operation objects (ADD or UPDATE).
1. **For NEW insights (ADD):**
{{
"type": "ADD",
"category": "code_snippet" | "pitfall" | "best_practice" | "strategy",
"content": "... (clear, reusable instruction following Context-Action structure)"
}}
2. **For improving existing entries (UPDATE):**
{{
"type": "UPDATE",
"entry_id": "...",
"category": "code_snippet" | "pitfall" | "best_practice" | "strategy",
"content": "... (improved version with better clarity, examples, or corrections)"
}}
If no valuable or reusable insights are found, return an empty "operations" array.
"""
human_template = """
## Existing Playbook (Check for duplicates here first):
{playbook}
## New Reflection Insights:
{reflection}
Your task:
1. Scan the Existing Playbook for related entries.
2. Decide between ADD (new) or UPDATE (refine existing).
3. Write the 'content' using the **Context-Action** structure (e.g., "When X, do Y because Z").
4. Apply the category decision tree strictly.
5. Output only ADD or UPDATE operations in JSON format.
6. Respond in English.
"""curator 프롬프트에 핵심적인 부분은 지식을 정제하는 write rule입니다.
- bed example : 이진 탐색은 O(log n)이다.
- good example : 정렬된 대규모 데이터셋에서 검색 효율을 높여야할 때(context), 이진 탐색을 사용하여 시간 복잡도를 O(log n)으로 줄여라(action)
이렇게 작성된 지식은 나중에 사용자가 "대량의 데이터에서 빠르게 값을 찾고 싶어"라고 물었을때, retriever 노드에서 이걸 영어로 변환하고 search, fast, large dataset 같은 키워드로 결합되어 검색됩니다.
node
async def curator_node(state : State) -> State:
logger.debug("CURATOR")
# model import
provider = state.get("llm_provider")
model = state.get("llm_model")
playbook_str = '\n'.join(f"[{entry['entry_id']}] {entry['content']}" for entry in state['playbook']) or "EMPTY PLAYBOOK"
reflection = state.get("reflection")
inputs = {
"playbook" : playbook_str,
"reflection" : reflection
}
# reasoning, operations 2개의 key값을 가진 JSON 반환
new_insights = await curator_chain.ainvoke(
inputs,
config={"configurable" : {"llm_provider" : provider, "llm_model" : model}}
)
operations = new_insights.get("operations", [])
return {
"new_insights" : operations
}curator 노드가 존재하기 때문에 playbook으로 진화할 수 있습니다. 이제 curator가 operations를 들고, 실제로 DB와 벡터 스토어에 물리적인 변화를 일으키는 Update 노드로 가보겠습니다.
Delta Updates
Curator가 "이 내용을 추가하고, 저 내용은 수정해" 라고 명령을 내렸다면 Update 노드는 그 명령을 실제로 DB에 업데이트하고 벡터스토어에 인덱스를 재구성합니다.
이 과정은 논문에서 설명한 전체 컨텍스트를 새로 쓰는 대신, 변화된 부분(Delta)만 반영한다 는 원칙을 따릅니다.

node
async def update_playbook_node(state : State) -> State:
# halpful, harmful count 누적안됨, 무조건 helpful이 1로 시작 -> 해결필요 -> curator에서 retrieved된 결과를 playbook에 전달하지 않아서 생긴 이슈였음
logger.debug("PLAYBOOK DELTA UPDATE")
# DB
vector_store = get_vector_store_instance()
db = get_db_instance()
embedding_model = vector_store.get_embedding_model
updated_playbook = state['playbook'].copy()
max_playbook_size = state.get("max_playbook_size")
entries_to_save = set()
# reflector 노드에서 반환되는 값, 여기에서 helpful과 harmful을 누적
bullet_tags = state.get("reflection", {}).get("bullet_tags", [])
for tag_info in bullet_tags:
target_id = str(tag_info.get("entry_id", '')).strip()
target_tag = tag_info.get("tag", "").lower()
for entry in updated_playbook:
current_id = str(entry['entry_id']).strip()
if current_id == target_id:
old_helpful = entry['helpful_count']
if target_tag == 'helpful':
entry['helpful_count'] += 1
if state.get("verbose", False):
highlight_print(f"✅ Helpful Count UP! [{current_id[:8]}] {old_helpful}->{entry['helpful_count']}", 'green')
elif target_tag == 'harmful':
entry['harmful_count'] += 1
if state.get("verbose", False):
highlight_print(f"❌ Harmful Count UP! [{current_id[:8]}]", 'red')
entry['last_used_at'] = datetime.now()
entries_to_save.add(entry['entry_id'])
break
# delta operation
docs_to_add_to_vector_store = []
ids_to_delete_from_vector_store = []
# curator 노드의 operations 부분에서 각각 type, category, content로 나눠짐
for op in state.get("new_insights", []):
op_type = op.get("type").upper()
if op_type == "ADD":
new_id = str(uuid.uuid4())
content = op['content']
# 중복 제거
if is_duplicate_entry(content, vector_store, embedding_model):
logger.debug(f"Duplicate found for content : {content}. Skipping ADD")
continue
# expected values : strategy, code_snippet, pitfall, best_practice
category = op.get("category", "uncategorized")
entry = PlaybookEntry(
entry_id=new_id,
category=category,
content=content,
helpful_count=1, # curator에서 ADD로 판단하므로 결과가 helpful 하다고 판단(가정)
harmful_count=0,
created_at=datetime.now(),
updated_at=datetime.now()
)
# DB 저장용
docs_to_add_to_vector_store.append(entry)
db.add_entry(entry)
updated_playbook.append(entry)
elif op_type == "UPDATE":
entry_id_to_update = op.get("entry_id")
new_content = op.get("content")
if not entry_id_to_update or not new_content:
continue
for entry in updated_playbook:
if entry['entry_id'] == entry_id_to_update:
# id가 같지만 오래된(update가 필요한) 플레이북 삭제
if entry['entry_id'] in entries_to_save:
entries_to_save.remove(entry['entry_id'])
ids_to_delete_from_vector_store.append(entry['entry_id'])
entry['content'] = new_content
entry['updated_at'] = datetime.now()
db.add_entry(entry)
docs_to_add_to_vector_store.append(entry)
break
# 루프가 끝난 후, 카운트만 변경되고(UPDATE 안됨) 아직 저장되지 않은 항목들 일괄 저장
if entries_to_save:
for entry in updated_playbook:
if entry['entry_id'] in entries_to_save:
db.add_entry(entry)
ids_to_delete_from_vector_store.append(entry['entry_id'])
docs_to_add_to_vector_store.append(entry)
# prune
all_entries_in_db = db.get_all_entries()
max_playbook_size = state.get("max_playbook_size")
_, ids_to_prune = prune_playbook(all_entries_in_db, int(max_playbook_size))
if ids_to_prune:
if state.get("verbose", False):
logger.debug(f"Pruning {len(ids_to_prune)} entries...")
ids_to_delete_from_vector_store.extend(ids_to_prune)
for entry_id in ids_to_prune:
db.delete_entry(entry_id)
if ids_to_delete_from_vector_store:
vector_store.delete_by_entry_ids(list(set(ids_to_delete_from_vector_store)))
if docs_to_add_to_vector_store:
docs = []
for entry in docs_to_add_to_vector_store:
doc = Document(
page_content=entry['content'],
metadata = {
"entry_id" : entry['entry_id'],
"category" : entry['category'],
"helpful_count" : entry['helpful_count'],
"harmful_count" : entry['harmful_count'],
"created_at" : entry['created_at'],
"updated_at" : entry['updated_at']
}
)
docs.append(doc)
vector_store.to_disk(docs)
return {"playbook" : updated_playbook}논문에서는 기존의 방식들이 컨텍스트가 커질수록 LLM이 이를 한꺼번에 다시 쓰게 유도하는데, 이 과정에서 중요한 세부 정보가 유실되는 Context Collapse 현상을 지적합니다. 이 시스템은 Update 노드를 통해 다음을 보장합니다.
- 보존성 : 검증된 과거의 지식은 건드리지 않고 그대로 유지합니다.
- 정교함 : 수정이 피요한 부분만 업데이트합니다.
- 성능 : 수백~수천개의 지식중 몇 개만 수정하므로, 전체를 재작성하는 것보다 훨씬 빠릅니다.
Utils
Update 노드가 저장하기 전, 중복을 막고 품질을 필터링하는 두 가지 핵심 유틸이 있습니다.
- 중복 지식 방지
def is_duplicate_entry(
content : str,
vector_store : VectorStore,
embedding_model : Optional[HuggingFaceEmbeddings] = None,
threshold : Optional[float] = None
) -> bool:
if threshold is None:
threshold = float(env.get_playbook_config['DEDUP_THRESHOLD'])
if embedding_model is None:
embedding_model = VectorStore.get_embedding_model
if vector_store.get_doc_count() == 0:
return False
retriever = vector_store.from_disk()
query_embedding = embedding_model.embed_query(content)
similar_docs = retriever.similarity_search_by_vector(
embedding=query_embedding,
k=1,
score_threshold=threshold
)
return bool(similar_docs)에이전트가 질문을 많이 받다 보면, 이미 알고 있는 지식을 또 새로운 지식으로 판단(ADD) 할 떄가 있습니다. 만약 똑같은 내용이 playbook에 수십개 쌓인다면 검색 효율은 떨어지고 정작 필요한 다른 정보를 담을 공간이 부족해질 것입니다.
이 로직 덕분에 "파이썬 리스트 정렬법"과 "Python List를 정렬하는 방법"이 서로 다른 문장이더라도, 시스템은 같은 지식으로 인식하여 중복 추가를 방지합니다.
중복성을 체크하는 threshold는 config에서 확인할 수 있습니다.
[PLAYBOOK]
# Maximum number of entries allowed in the playbook.
# When exceeded, the pruning process (removing low-utility/old entries) is triggered.
MAX_PLAYBOOK_SIZE = 200
# Semantic similarity threshold (0.0 ~ 1.0) for detecting duplicates.
# If a new insight's similarity to an existing one exceeds this value, it triggers an UPDATE instead of ADD.
DEDUP_THRESHOLD = 0.85
# Minimum cosine similarity score required to retrieve an entry.
# Entries with similarity below this value will be filtered out to prevent noise.
RETRIEVAL_THRESHOLD = 0.42
# The number of top relevant playbook entries to retrieve and provide to the Generator.
RETRIEVAL_TOP_K = 8- 가지치기
논문의 매커니즘인 grow-and-refine을 구현한 함수입니다. playbook 공간은 무한하지 않으며, 잘못된 지식은 에이전트를 망칠 수 있습니다. 이 함수는 두 단계의 심사를 거쳐 살아남은 지식만 골라냅니다.
def prune_playbook(playbook : PlaybookEntry, max_size : int) -> tuple[list[PlaybookEntry], list[str]]:
"""
Prunes the playbook based on two criteria:
1. Quality: Remove entries where harmful_count > helpful_count (Poisoned knowledge)
2. Capacity: If size > max_size, remove entries with lowest value (LRU & Low Utility)
"""
ids_to_prune = set()
kept_entries = []
clean_entries = []
for entry in playbook:
h_count = entry.get("helpful_count", 0)
harm_count = entry.get("harmful_count", 0)
if harm_count > h_count:
ids_to_prune.add(entry['entry_id'])
else:
clean_entries.append(entry)
current_size = len(clean_entries)
if current_size > max_size:
excess_count = current_size - max_size
clean_entries.sort(
key=lambda x : (
x.get("helpful_count", 0),
x.get("last_used_at") or datetime.min,
)
)
entries_to_remove = clean_entries[:excess_count]
kept_entries = clean_entries[excess_count:]
for entry in entries_to_remove:
ids_to_prune.add(entry['entry_id'])
else:
kept_entries = clean_entries
return kept_entries, list(ids_to_prune)update 노드는 이 유틸리티들을 활용하여, 시간이 지날수록 더 가볍고, 더 강력하며, 더 정확한 playbook을 온성해 나갑니다.
Self-Evolving agent
이로써 Retriever → Generator → Evaluator → Reflector → Curator → Update 로 이어지는 에이전트 노드가 완성되었습니다.
이 구조 덕분에 ACES(Agentic Context Engineering for Services)는 아무것도 모르는 상태에서 시작해도 질문을 받고 실수를 교저하며 스스로 지식 playbook을 쌓아 올립니다.
참고
구현 중에 halpful 카운트가 누적되지 않던 이슈가 있었는데, 이는 curator가 이전에 검색된 지식의 ID 값을 langgraph의 state에 제대로 전달하지 않아 발생한 이슈였습니다. (지금은 해결됨)
