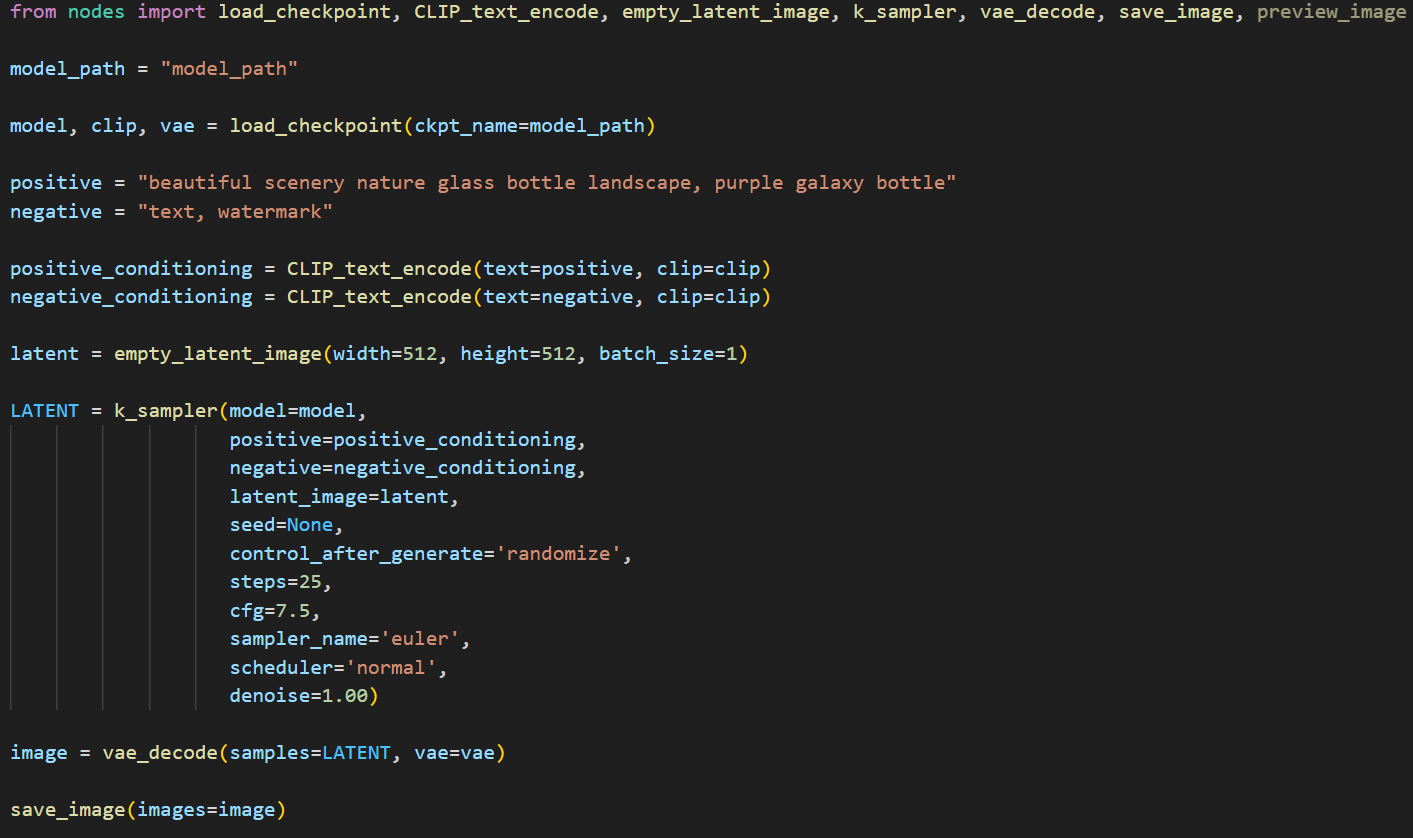
ComfyUI는 A1111과 비슷하게 Stable Diffusion 모델을 기반으로 한 비주얼 인터페이스입니다. ComfyUI를 실행하면 가장 먼저 보게되는 화면은 아마도
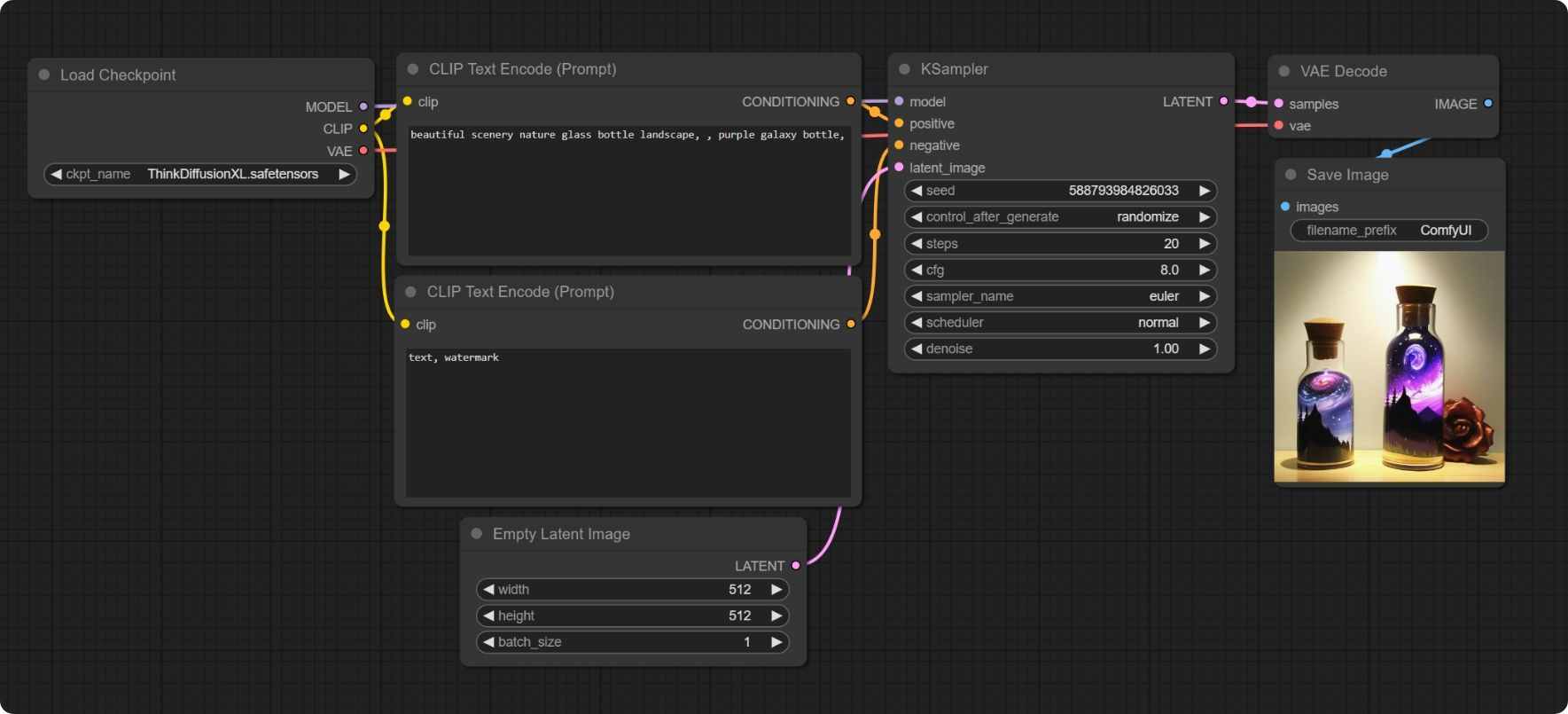
이런 화면일 것입니다. 여기에 있는 각 노드를 직접 구현해보았으며, 코드에 대한 설명을 진행하려고 합니다. 처음부터 끝까지 직접 구현한건 아니고 Diffusers을 많이 참고하였으며, Ksampler 에 해당하는 노드들은 diffusers의 파이프라인을 사용해 구현하였습니다.
자세한 코드는 ComfyUI-default-workflow-implementation 를 참고해주세요.
읽기 전에
프롬프트를 기반으로 모델을 읽어오고 이미지를 생성하는건 위에서 언급한 ComfyUI와 A1111뿐만 아니라 Diffusers로 손쉽게 구현이 가능합니다. 그럼에도 직접 구현을 한 이유는
- 모델의 구조와 동작 방식을 좀 더 자세히 이해하고 싶다.
- 삽질하고싶다.
이 두 가지 이유로 시작하게되었습니다.
노드의 순서는 왼쪽에서 오른쪽 순서대로 소스코드를 설명하겠습니다.
구현에 도움되는 유틸
코드에 종종 print 대신에 highlight_print 로 쓰여진 함수가 보일수 있습니다. 별건 아니고
def highlight_print(
target: str,
color: Optional[Literal['red', 'green', 'blue', 'yellow', 'magenta', 'cyan', 'white', 'none']] = None,
**kwargs
):
# Define ANSI color codes
RED = '\033[31m'
GREEN = '\033[32m'
YELLOW = '\033[33m'
BLUE = '\033[34m'
MAGENTA = '\033[35m'
CYAN = '\033[36m'
WHITE = '\033[37m'
RESET = '\033[0m'
print('-' * 80)
# Match the color and apply formatting
if color is None or color == 'none':
print(str(target), **kwargs)
elif color == 'red':
print(RED + str(target) + RESET, **kwargs)
elif color == 'green':
print(GREEN + str(target) + RESET, **kwargs)
elif color == 'blue':
print(BLUE + str(target) + RESET, **kwargs)
elif color == 'yellow':
print(YELLOW + str(target) + RESET, **kwargs)
elif color == 'magenta':
print(MAGENTA + str(target) + RESET, **kwargs)
elif color == 'cyan':
print(CYAN + str(target) + RESET, **kwargs)
elif color == 'white':
print(WHITE + str(target) + RESET, **kwargs)
else:
print(f"Unknown color '{color}', printing without color:")
print(str(target), **kwargs)
print('-' * 80)이렇게 구성되 있으며

Load Checkpoint
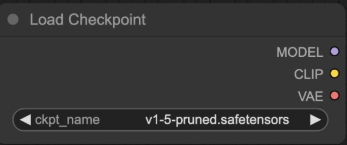
파일경로에 있는 모델 파일(.safetensors)을 받아서 MODEL CLIP VAE 를 리턴합니다.
제가 생각하는 Stable Diffusion의 종류는 크게
- Stable Diffusion 1.5 (sd15)
- Stable Diffusion 2.0 (sd20)
- Stable Diffusion xl (sdxl) (Pony diffusion도 여기에 해당)
- Stable Diffusion refiner
- Flux Diffusion
이렇게 여러 가지로 나뉘지만, 여기서는 간단하게 SD15와 SDXL만 구분하도록 하겠습니다. 각 모델마다 구조에 조금씩 차이가 있기 때문입니다.
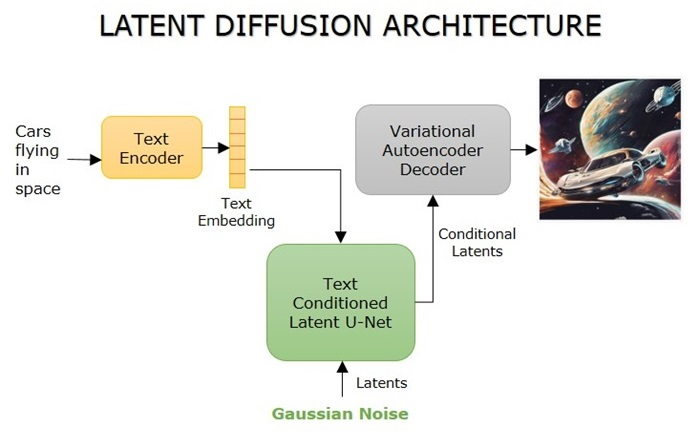
(https://www.tutorialspoint.com/stable-diffusion/stable-diffusion-architecture.htm)
SD15 모델은 크게 U-Net, Variational Autoencoder (VAE), 그리고 Text Encoder 세 가지 모델로 구성됩니다.
SDXL도 위 구조와 크게 다르진 않지만, 텍스트 인코더가 2개로 구성되어있으며 모델의 가중치와 관련된 정보를 저장하는 State dict의 key 이름이 조금 다릅니다.
모델의 종류에 따라 생성하는 방법도 다르기때문에 입력값으로 받는 모델이 sd15인지 sdxl인지 구분하는걸 먼저 구현합니다.
def load_checkpoint_file(ckpt, device : Literal['auto', 'gpu', 'cpu'] = 'auto'):
"""
Load a model file (either .safetensors or .ckpt).
"""
if device == 'auto' or device == 'gpu':
device = get_torch_device()
elif device == 'cpu':
device = get_cpu_device()
else:
device = get_torch_device()
ext = os.path.splitext(ckpt)[-1].lower()
if ext == '.safetensors':
sd = load_file(ckpt, device=device)
elif ext == '.ckpt':
model = torch.load(ckpt, map_location=device, weights_only=False)
if "state_dict" in model:
sd = model['state_dict']
else:
sd = model
else:
raise ValueError(f"{os.path.basename(ckpt)} is not a `safetensors` or `ckpt`")
return sddef get_model_keys(ckpt : os.PathLike, return_type : Literal['str', 'list'] = 'str',
save_as_file : bool = False ,
save_name : Optional[str] = None,
device : Literal['auto', 'gpu', 'cpu'] = 'cpu'):
sd = load_checkpoint_file(ckpt, device=device)
if return_type == 'str':
keys = '\n'.join(sorted(sd.keys()))
elif return_type == 'list':
keys = sorted(sd.keys())
if save_as_file:
if save_name is None:
prefix_name = os.path.basename(ckpt).split('.')[0]
save_name = f"{prefix_name}_keys.txt"
save_path = os.path.join(env.get_output_dir(), save_name)
with open(save_path, 'w', encoding='utf-8') as f:
f.write(keys)
highlight_print(f"Model keys are saved at : {save_path}", 'green')
return keys이 함수에서 모델을 넣어주면 가중치의 key 값들을 뽑아올 수 있습니다.
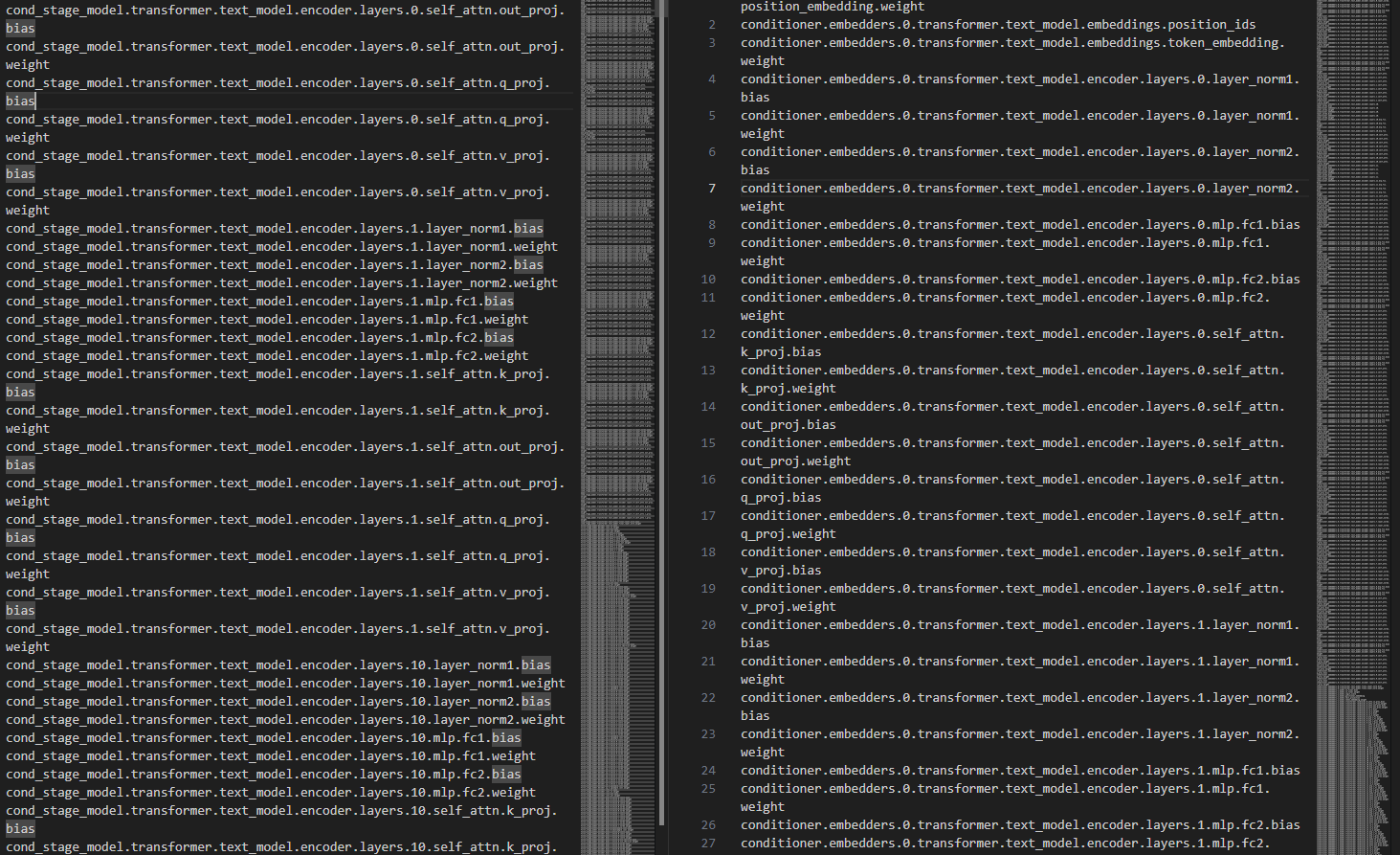
sd15 모델과 sdxl 모델의 key 값입니다. 여기서 모델별로 다른 키값을 사륜안으로 밝혀내거나 구글링으로 찾아보면
sd15 모델의 텍스트 인코더는 cond_stage_model 로 시작하고, sdxl 모델의 텍스트 인코더는 conditioner 로 시작하는걸 알 수 있습니다.
이제 모델이 sd15인지 sdxl인지 알아냈으니, 이걸 기반으로 하나의 모델에서 UNET,VAE,Encoder를 뽑아내는 코드를 작성합니다.
def auto_model_detection(ckpt) -> str:
"""
Is it a stable diffusion? or SDXL?\n
```python
model = "path/to/stable_diffusion_v1-5.ckpt"
model_type = auto_model_detection(model)
print(model_type) # 'sd15'
model = "path/to/sd_xl_base_1.safetensors"
model_type = auto_model_detection(model)
print(model_type) # 'sdxl'
```
"""
from module.model_state import get_model_keys
sd = get_model_keys(ckpt, return_type='list', save_as_file=False)
prefix_sd = [[part for part in item.split('.')[:1]] for item in sd]
def flatten(lst):
result = []
for item in lst:
result.extend(item)
return result
# Flatten a nested lits into a single list
preprocess_sd1 = flatten(prefix_sd)
# Remove duplicates from list
preprocess_sd2 = list(set(preprocess_sd1))
if 'cond_stage_model' in preprocess_sd2:
return 'sd15'
if 'conditioner' in preprocess_sd2:
return 'sdxl'
else:
raise ValueError("Cannot determine model type : No clear CLIP keys found in the state_dict.")def is_unet_tensor(key, model_type : Literal['sd15', 'sdxl']):
if model_type == 'sd15':
return key.startswith("model.diffusion_model.")
elif model_type == 'sdxl':
return key.startswith("model.diffusion_model.")
return False
def is_clip_tensor(key, model_type : Literal['sd15', 'sdxl']):
if model_type == 'sd15':
return key.startswith("cond_stage_model.transformer.")
elif model_type == 'sdxl':
return key.startswith("conditioner.embedders")
return False
def is_vae_tensor(key, model_type : Literal['sd15', 'sdxl']):
if model_type == 'sd15':
return key.startswith("first_stage_model.")
elif model_type == 'sdxl':
return key.startswith("first_stage_model.")
return Falsedef extract_model_components(ckpt) -> Tuple[Dict, Dict, Dict]:
"""
Extracts UNet, CLIP, VAE weights and model type(sd15 or sdxl) from a checkpoint as a dictionary\n
"""
unet_tensors = {}
clip_tensors = {}
vae_tensors = {}
model_type = auto_model_detection(ckpt)
tensors = load_checkpoint_file(ckpt, device='cpu')
for key, tensor in tensors.items():
if is_unet_tensor(key, model_type):
unet_tensors[key] = tensor
elif is_clip_tensor(key, model_type):
clip_tensors[key] = tensor
elif is_vae_tensor(key, model_type):
vae_tensors[key] = tensor
return unet_tensors, clip_tensors, vae_tensors, model_type
ckpt_model, ckpt_clip, ckpt_vae, model_type = extract_model_components(ckpt_name)이렇게 하면 unet dict, clip(encoder) dict, vae dict에 각각 모델의 가중치값이 담긴 값(state dict, sd)이 할당됩니다.
이제 껍데기만 있는 Unet, VAE, Encoder 모델을 만들어보도록 하겠습니다.
다행히도 sd15와 sdxl은 오픈소스이기때문에 찾아보면 모델구조를 만들 수 있습니다.
Huggingface 에서 껍데기 모델을 다운받는것도 하나의 방법이지만 저는 삽질하면서 모델의 동작방식을 이해하는것이 목적이라 직접 구현해서 코드에 집어넣었습니다.
최종적으로 diffusers 의 파이프라인을 통해 이미지를 생성할 예정이기때문에, Unet과 VAE는 diffusers에서, Encoder는 Transformers 라이브러리에서 제공하는 기본 모델을 사용합니다.
from diffusers import UNet2DConditionModel, AutoencoderKL
from transformers import CLIPTextModel, CLIPTextConfig
import torch
class UNet:
@staticmethod
def sdxl():
unet = UNet2DConditionModel(
sample_size=128,
act_fn="silu",
addition_embed_type="text_time",
addition_embed_type_num_heads=64,
addition_time_embed_dim=256,
attention_head_dim=[5,10,20],
attention_type="default",
block_out_channels=[320, 640, 1280],
center_input_sample=False,
class_embed_type=None,
class_embeddings_concat=False,
conv_in_kernel=3,
conv_out_kernel=3,
cross_attention_dim=2048,
cross_attention_norm=None,
down_block_types=["DownBlock2D","CrossAttnDownBlock2D","CrossAttnDownBlock2D"],
downsample_padding=1,
dropout=0.0,
dual_cross_attention=False,
encoder_hid_dim=None,
encoder_hid_dim_type=None,
flip_sin_to_cos=True,
freq_shift=0,
in_channels=4,
layers_per_block=2,
mid_block_only_cross_attention=None,
mid_block_scale_factor=1,
mid_block_type="UNetMidBlock2DCrossAttn",
norm_eps=1e-05,
norm_num_groups=32,
num_attention_heads=None,
num_class_embeds=None,
only_cross_attention=False,
out_channels=4,
projection_class_embeddings_input_dim=2816,
resnet_out_scale_factor=1.0,
resnet_skip_time_act=False,
resnet_time_scale_shift="default",
reverse_transformer_layers_per_block=None,
time_cond_proj_dim=None,
time_embedding_act_fn=None,
time_embedding_type="positional",
timestep_post_act=None,
transformer_layers_per_block=[1,2,10],
up_block_types=["CrossAttnUpBlock2D","CrossAttnUpBlock2D","UpBlock2D"],
upcast_attention=None,
use_linear_projection=True
)
return unet
@staticmethod
def sd15():
unet = UNet2DConditionModel(
act_fn="silu",
attention_head_dim=8,
block_out_channels=[320, 640, 1280, 1280],
center_input_sample=False,
cross_attention_dim=768,
down_block_types=["CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D"],
downsample_padding=1,
flip_sin_to_cos=True,
freq_shift=0,
in_channels=4,
layers_per_block=2,
mid_block_scale_factor=1,
norm_eps=1e-05,
norm_num_groups=32,
out_channels=4,
sample_size=64,
up_block_types=["UpBlock2D","CrossAttnUpBlock2D","CrossAttnUpBlock2D","CrossAttnUpBlock2D"]
)
return unet
class VAE:
@staticmethod
def sdxl():
"""
stabilityai/sdxl-vae
"""
vae = AutoencoderKL(
act_fn="silu",
block_out_channels=[128,256,512,512],
down_block_types=["DownEncoderBlock2D","DownEncoderBlock2D","DownEncoderBlock2D","DownEncoderBlock2D"
],
in_channels=3,
latent_channels=4,
layers_per_block=2,
norm_num_groups=32,
out_channels=3,
sample_size=1024,
scaling_factor=0.13025,
up_block_types=["UpDecoderBlock2D","UpDecoderBlock2D","UpDecoderBlock2D","UpDecoderBlock2D"
]
)
return vae
@staticmethod
def sd15():
vae = AutoencoderKL(
act_fn="silu",
block_out_channels=[128,256,512,512],
down_block_types=["DownEncoderBlock2D","DownEncoderBlock2D","DownEncoderBlock2D","DownEncoderBlock2D"],
in_channels=3,
latent_channels=4,
layers_per_block=2,
norm_num_groups=32,
out_channels=3,
sample_size=512,
up_block_types=["UpDecoderBlock2D","UpDecoderBlock2D","UpDecoderBlock2D","UpDecoderBlock2D"]
)
return vae
class TextEncoder:
@staticmethod
def sdxl_enc1():
config = CLIPTextConfig(
attention_dropout=0.0,
bos_token_id=0,
eos_token_id=2,
dropout=0.0,
hidden_act="quick_gelu",
hidden_size=768,
initializer_factor=1.0,
initializer_range=0.02,
intermediate_size=3072,
layer_norm_eps=1e-05,
max_position_embeddings=77,
num_attention_heads=12,
num_hidden_layers=12,
pad_token_id=1,
projection_dim=768,
torch_dtype = torch.float16,
vocab_size=49408
)
enc1 = CLIPTextModel(config=config)
return enc1
@staticmethod
def sdxl_enc2_config():
config = CLIPTextConfig(
attention_dropout=0.0,
bos_token_id=0,
dropout = 0.0,
eos_token_id= 2,
hidden_act="gelu",
hidden_size=1280,
initializer_factor=1.0,
initializer_range=0.02,
intermediate_size=5120,
layer_norm_eps=1e-05,
max_position_embeddings=77,
num_attention_heads=20,
num_hidden_layers=32,
pad_token_id=1,
projection_dim=1280,
torch_dtype=torch.float16,
vocab_size=49408
)
return config
@staticmethod
def sd15_enc():
config = CLIPTextConfig(
attention_dropout=0.0,
bos_token_id=0,
dropout = 0.0,
eos_token_id=2,
hidden_act="quick_gelu",
hidden_size=768,
initializer_factor=1.0,
initializer_range=0.02,
intermediate_size=3072,
layer_norm_eps=1e-05,
max_position_embeddings=77,
num_attention_heads=12,
num_hidden_layers=12,
pad_token_id=1,
projection_dim=768,
torch_dtype=torch.float32,
vocab_size=49408
)
enc = CLIPTextModel(config=config)
return enc이제 껍데기만 있는 모델에 아까 담아주었던 알맹이가 들어있는 딕셔너리와 합쳐주면 모델 분리가 완성됩니다.

문제는 우리가 경로로 넣어주었던 원본모델과, diffusers 에서 인식하는 모델은 서로 다른 Key값을 갖고있다는 점입니다. 그래서 원본모델에서 가중치를 뽑아낸 sd 값을 diffusers의 껍데기 모델과 합치려면 sd를 지정된 포맷에 맞춰 변환해줘야합니다.
Unet, vae, encoder 변환
이 부분은 노가다이니 새로운 파이썬 파일 하나 만들어서 복붙하시면 될거같습니다.
import re
from transformers import CLIPTextConfig, CLIPTextModel, CLIPTextModelWithProjection
from diffusers.utils.import_utils import is_accelerate_available
from contextlib import nullcontext
if is_accelerate_available():
from accelerate import init_empty_weights
from accelerate.utils import set_module_tensor_to_device
def shave_segments(path, n_shave_prefix_segments=1):
"""
Removes segments. Positive values shave the first segments, negative shave the last segments.
"""
if n_shave_prefix_segments >= 0:
return ".".join(path.split(".")[n_shave_prefix_segments:])
else:
return ".".join(path.split(".")[:n_shave_prefix_segments])
def renew_vae_resnet_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside resnets to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
new_item = old_item
new_item = new_item.replace("nin_shortcut", "conv_shortcut")
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
mapping.append({"old": old_item, "new": new_item})
return mapping
def conv_attn_to_linear(checkpoint):
keys = list(checkpoint.keys())
attn_keys = ["query.weight", "key.weight", "value.weight"]
for key in keys:
if ".".join(key.split(".")[-2:]) in attn_keys:
if checkpoint[key].ndim > 2:
checkpoint[key] = checkpoint[key][:, :, 0, 0]
elif "proj_attn.weight" in key:
if checkpoint[key].ndim > 2:
checkpoint[key] = checkpoint[key][:, :, 0]
def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside resnets to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
new_item = old_item.replace("in_layers.0", "norm1")
new_item = new_item.replace("in_layers.2", "conv1")
new_item = new_item.replace("out_layers.0", "norm2")
new_item = new_item.replace("out_layers.3", "conv2")
new_item = new_item.replace("emb_layers.1", "time_emb_proj")
new_item = new_item.replace("skip_connection", "conv_shortcut")
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
mapping.append({"old": old_item, "new": new_item})
return mapping
def assign_to_checkpoint(
paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None
):
"""
This does the final conversion step: take locally converted weights and apply a global renaming to them. It splits
attention layers, and takes into account additional replacements that may arise.
Assigns the weights to the new checkpoint.
"""
assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
# Splits the attention layers into three variables.
if attention_paths_to_split is not None:
for path, path_map in attention_paths_to_split.items():
old_tensor = old_checkpoint[path]
channels = old_tensor.shape[0] // 3
target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
query, key, value = old_tensor.split(channels // num_heads, dim=1)
checkpoint[path_map["query"]] = query.reshape(target_shape)
checkpoint[path_map["key"]] = key.reshape(target_shape)
checkpoint[path_map["value"]] = value.reshape(target_shape)
for path in paths:
new_path = path["new"]
# These have already been assigned
if attention_paths_to_split is not None and new_path in attention_paths_to_split:
continue
# Global renaming happens here
new_path = new_path.replace("middle_block.0", "mid_block.resnets.0")
new_path = new_path.replace("middle_block.1", "mid_block.attentions.0")
new_path = new_path.replace("middle_block.2", "mid_block.resnets.1")
if additional_replacements is not None:
for replacement in additional_replacements:
new_path = new_path.replace(replacement["old"], replacement["new"])
# proj_attn.weight has to be converted from conv 1D to linear
is_attn_weight = "proj_attn.weight" in new_path or ("attentions" in new_path and "to_" in new_path)
shape = old_checkpoint[path["old"]].shape
if is_attn_weight and len(shape) == 3:
checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0]
elif is_attn_weight and len(shape) == 4:
checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0, 0]
else:
checkpoint[new_path] = old_checkpoint[path["old"]]
def renew_attention_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside attentions to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
new_item = old_item
# new_item = new_item.replace('norm.weight', 'group_norm.weight')
# new_item = new_item.replace('norm.bias', 'group_norm.bias')
# new_item = new_item.replace('proj_out.weight', 'proj_attn.weight')
# new_item = new_item.replace('proj_out.bias', 'proj_attn.bias')
# new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
mapping.append({"old": old_item, "new": new_item})
return mapping
def renew_vae_attention_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside attentions to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
new_item = old_item
new_item = new_item.replace("norm.weight", "group_norm.weight")
new_item = new_item.replace("norm.bias", "group_norm.bias")
new_item = new_item.replace("q.weight", "to_q.weight")
new_item = new_item.replace("q.bias", "to_q.bias")
new_item = new_item.replace("k.weight", "to_k.weight")
new_item = new_item.replace("k.bias", "to_k.bias")
new_item = new_item.replace("v.weight", "to_v.weight")
new_item = new_item.replace("v.bias", "to_v.bias")
new_item = new_item.replace("proj_out.weight", "to_out.0.weight")
new_item = new_item.replace("proj_out.bias", "to_out.0.bias")
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
mapping.append({"old": old_item, "new": new_item})
return mapping
def convert_unet(checkpoint, config, path=None, extract_ema=False, controlnet=False, skip_extract_state_dict=False):
if skip_extract_state_dict:
unet_state_dict = checkpoint
else:
# extract state_dict for UNet
unet_state_dict = {}
keys = list(checkpoint.keys())
if controlnet:
unet_key = "control_model."
else:
unet_key = "model.diffusion_model."
for key in keys:
if key.startswith(unet_key):
unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(key)
new_checkpoint = {}
new_checkpoint["time_embedding.linear_1.weight"] = unet_state_dict["time_embed.0.weight"]
new_checkpoint["time_embedding.linear_1.bias"] = unet_state_dict["time_embed.0.bias"]
new_checkpoint["time_embedding.linear_2.weight"] = unet_state_dict["time_embed.2.weight"]
new_checkpoint["time_embedding.linear_2.bias"] = unet_state_dict["time_embed.2.bias"]
if config["class_embed_type"] is None:
# No parameters to port
...
elif config["class_embed_type"] == "timestep" or config["class_embed_type"] == "projection":
new_checkpoint["class_embedding.linear_1.weight"] = unet_state_dict["label_emb.0.0.weight"]
new_checkpoint["class_embedding.linear_1.bias"] = unet_state_dict["label_emb.0.0.bias"]
new_checkpoint["class_embedding.linear_2.weight"] = unet_state_dict["label_emb.0.2.weight"]
new_checkpoint["class_embedding.linear_2.bias"] = unet_state_dict["label_emb.0.2.bias"]
else:
raise NotImplementedError(f"Not implemented `class_embed_type`: {config['class_embed_type']}")
if config["addition_embed_type"] == "text_time":
new_checkpoint["add_embedding.linear_1.weight"] = unet_state_dict["label_emb.0.0.weight"]
new_checkpoint["add_embedding.linear_1.bias"] = unet_state_dict["label_emb.0.0.bias"]
new_checkpoint["add_embedding.linear_2.weight"] = unet_state_dict["label_emb.0.2.weight"]
new_checkpoint["add_embedding.linear_2.bias"] = unet_state_dict["label_emb.0.2.bias"]
# Relevant to StableDiffusionUpscalePipeline
if "num_class_embeds" in config:
if (config["num_class_embeds"] is not None) and ("label_emb.weight" in unet_state_dict):
new_checkpoint["class_embedding.weight"] = unet_state_dict["label_emb.weight"]
new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"]
new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"]
if not controlnet:
new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"]
new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"]
new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"]
new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"]
# Retrieves the keys for the input blocks only
num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer})
input_blocks = {
layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}" in key]
for layer_id in range(num_input_blocks)
}
# Retrieves the keys for the middle blocks only
num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer})
middle_blocks = {
layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
for layer_id in range(num_middle_blocks)
}
# Retrieves the keys for the output blocks only
num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer})
output_blocks = {
layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}" in key]
for layer_id in range(num_output_blocks)
}
for i in range(1, num_input_blocks):
block_id = (i - 1) // (config["layers_per_block"] + 1)
layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
resnets = [
key for key in input_blocks[i] if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
]
attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
if f"input_blocks.{i}.0.op.weight" in unet_state_dict:
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
f"input_blocks.{i}.0.op.weight"
)
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
f"input_blocks.{i}.0.op.bias"
)
paths = renew_resnet_paths(resnets)
meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
if len(attentions):
paths = renew_attention_paths(attentions)
meta_path = {"old": f"input_blocks.{i}.1", "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
resnet_0 = middle_blocks[0]
attentions = middle_blocks[1]
resnet_1 = middle_blocks[2]
resnet_0_paths = renew_resnet_paths(resnet_0)
assign_to_checkpoint(resnet_0_paths, new_checkpoint, unet_state_dict, config=config)
resnet_1_paths = renew_resnet_paths(resnet_1)
assign_to_checkpoint(resnet_1_paths, new_checkpoint, unet_state_dict, config=config)
attentions_paths = renew_attention_paths(attentions)
meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"}
assign_to_checkpoint(
attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
for i in range(num_output_blocks):
block_id = i // (config["layers_per_block"] + 1)
layer_in_block_id = i % (config["layers_per_block"] + 1)
output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
output_block_list = {}
for layer in output_block_layers:
layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
if layer_id in output_block_list:
output_block_list[layer_id].append(layer_name)
else:
output_block_list[layer_id] = [layer_name]
if len(output_block_list) > 1:
resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
resnet_0_paths = renew_resnet_paths(resnets)
paths = renew_resnet_paths(resnets)
meta_path = {"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
output_block_list = {k: sorted(v) for k, v in sorted(output_block_list.items())}
if ["conv.bias", "conv.weight"] in output_block_list.values():
index = list(output_block_list.values()).index(["conv.bias", "conv.weight"])
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
f"output_blocks.{i}.{index}.conv.weight"
]
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
f"output_blocks.{i}.{index}.conv.bias"
]
# Clear attentions as they have been attributed above.
if len(attentions) == 2:
attentions = []
if len(attentions):
paths = renew_attention_paths(attentions)
meta_path = {
"old": f"output_blocks.{i}.1",
"new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}",
}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
else:
resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
for path in resnet_0_paths:
old_path = ".".join(["output_blocks", str(i), path["old"]])
new_path = ".".join(["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]])
new_checkpoint[new_path] = unet_state_dict[old_path]
if controlnet:
# conditioning embedding
orig_index = 0
new_checkpoint["controlnet_cond_embedding.conv_in.weight"] = unet_state_dict.pop(
f"input_hint_block.{orig_index}.weight"
)
new_checkpoint["controlnet_cond_embedding.conv_in.bias"] = unet_state_dict.pop(
f"input_hint_block.{orig_index}.bias"
)
orig_index += 2
diffusers_index = 0
while diffusers_index < 6:
new_checkpoint[f"controlnet_cond_embedding.blocks.{diffusers_index}.weight"] = unet_state_dict.pop(
f"input_hint_block.{orig_index}.weight"
)
new_checkpoint[f"controlnet_cond_embedding.blocks.{diffusers_index}.bias"] = unet_state_dict.pop(
f"input_hint_block.{orig_index}.bias"
)
diffusers_index += 1
orig_index += 2
new_checkpoint["controlnet_cond_embedding.conv_out.weight"] = unet_state_dict.pop(
f"input_hint_block.{orig_index}.weight"
)
new_checkpoint["controlnet_cond_embedding.conv_out.bias"] = unet_state_dict.pop(
f"input_hint_block.{orig_index}.bias"
)
# down blocks
for i in range(num_input_blocks):
new_checkpoint[f"controlnet_down_blocks.{i}.weight"] = unet_state_dict.pop(f"zero_convs.{i}.0.weight")
new_checkpoint[f"controlnet_down_blocks.{i}.bias"] = unet_state_dict.pop(f"zero_convs.{i}.0.bias")
# mid block
new_checkpoint["controlnet_mid_block.weight"] = unet_state_dict.pop("middle_block_out.0.weight")
new_checkpoint["controlnet_mid_block.bias"] = unet_state_dict.pop("middle_block_out.0.bias")
return new_checkpoint
def convert_vae(checkpoint, config):
# extract state dict for VAE
vae_state_dict = {}
keys = list(checkpoint.keys())
vae_key = "first_stage_model." if any(k.startswith("first_stage_model.") for k in keys) else ""
for key in keys:
if key.startswith(vae_key):
vae_state_dict[key.replace(vae_key, "")] = checkpoint.get(key)
new_checkpoint = {}
new_checkpoint["encoder.conv_in.weight"] = vae_state_dict["encoder.conv_in.weight"]
new_checkpoint["encoder.conv_in.bias"] = vae_state_dict["encoder.conv_in.bias"]
new_checkpoint["encoder.conv_out.weight"] = vae_state_dict["encoder.conv_out.weight"]
new_checkpoint["encoder.conv_out.bias"] = vae_state_dict["encoder.conv_out.bias"]
new_checkpoint["encoder.conv_norm_out.weight"] = vae_state_dict["encoder.norm_out.weight"]
new_checkpoint["encoder.conv_norm_out.bias"] = vae_state_dict["encoder.norm_out.bias"]
new_checkpoint["decoder.conv_in.weight"] = vae_state_dict["decoder.conv_in.weight"]
new_checkpoint["decoder.conv_in.bias"] = vae_state_dict["decoder.conv_in.bias"]
new_checkpoint["decoder.conv_out.weight"] = vae_state_dict["decoder.conv_out.weight"]
new_checkpoint["decoder.conv_out.bias"] = vae_state_dict["decoder.conv_out.bias"]
new_checkpoint["decoder.conv_norm_out.weight"] = vae_state_dict["decoder.norm_out.weight"]
new_checkpoint["decoder.conv_norm_out.bias"] = vae_state_dict["decoder.norm_out.bias"]
new_checkpoint["quant_conv.weight"] = vae_state_dict["quant_conv.weight"]
new_checkpoint["quant_conv.bias"] = vae_state_dict["quant_conv.bias"]
new_checkpoint["post_quant_conv.weight"] = vae_state_dict["post_quant_conv.weight"]
new_checkpoint["post_quant_conv.bias"] = vae_state_dict["post_quant_conv.bias"]
# Retrieves the keys for the encoder down blocks only
num_down_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "encoder.down" in layer})
down_blocks = {
layer_id: [key for key in vae_state_dict if f"down.{layer_id}" in key] for layer_id in range(num_down_blocks)
}
# Retrieves the keys for the decoder up blocks only
num_up_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "decoder.up" in layer})
up_blocks = {
layer_id: [key for key in vae_state_dict if f"up.{layer_id}" in key] for layer_id in range(num_up_blocks)
}
for i in range(num_down_blocks):
resnets = [key for key in down_blocks[i] if f"down.{i}" in key and f"down.{i}.downsample" not in key]
if f"encoder.down.{i}.downsample.conv.weight" in vae_state_dict:
new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.weight"] = vae_state_dict.pop(
f"encoder.down.{i}.downsample.conv.weight"
)
new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.bias"] = vae_state_dict.pop(
f"encoder.down.{i}.downsample.conv.bias"
)
paths = renew_vae_resnet_paths(resnets)
meta_path = {"old": f"down.{i}.block", "new": f"down_blocks.{i}.resnets"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
mid_resnets = [key for key in vae_state_dict if "encoder.mid.block" in key]
num_mid_res_blocks = 2
for i in range(1, num_mid_res_blocks + 1):
resnets = [key for key in mid_resnets if f"encoder.mid.block_{i}" in key]
paths = renew_vae_resnet_paths(resnets)
meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
mid_attentions = [key for key in vae_state_dict if "encoder.mid.attn" in key]
paths = renew_vae_attention_paths(mid_attentions)
meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
conv_attn_to_linear(new_checkpoint)
for i in range(num_up_blocks):
block_id = num_up_blocks - 1 - i
resnets = [
key for key in up_blocks[block_id] if f"up.{block_id}" in key and f"up.{block_id}.upsample" not in key
]
if f"decoder.up.{block_id}.upsample.conv.weight" in vae_state_dict:
new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.weight"] = vae_state_dict[
f"decoder.up.{block_id}.upsample.conv.weight"
]
new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.bias"] = vae_state_dict[
f"decoder.up.{block_id}.upsample.conv.bias"
]
paths = renew_vae_resnet_paths(resnets)
meta_path = {"old": f"up.{block_id}.block", "new": f"up_blocks.{i}.resnets"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
mid_resnets = [key for key in vae_state_dict if "decoder.mid.block" in key]
num_mid_res_blocks = 2
for i in range(1, num_mid_res_blocks + 1):
resnets = [key for key in mid_resnets if f"decoder.mid.block_{i}" in key]
paths = renew_vae_resnet_paths(resnets)
meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
mid_attentions = [key for key in vae_state_dict if "decoder.mid.attn" in key]
paths = renew_vae_attention_paths(mid_attentions)
meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
conv_attn_to_linear(new_checkpoint)
return new_checkpoint
def convert_text_encoder(checkpoint, local_files_only=False, text_encoder=None):
if text_encoder is None:
config_name = "openai/clip-vit-large-patch14"
try:
config = CLIPTextConfig.from_pretrained(config_name, local_files_only=local_files_only)
except Exception:
raise ValueError(
f"With local_files_only set to {local_files_only}, you must first locally save the configuration in the following path: 'openai/clip-vit-large-patch14'."
)
ctx = init_empty_weights if is_accelerate_available() else nullcontext
with ctx():
text_model = CLIPTextModel(config)
else:
text_model = text_encoder
keys = list(checkpoint.keys())
text_model_dict = {}
remove_prefixes = ["cond_stage_model.transformer", "conditioner.embedders.0.transformer"]
for key in keys:
for prefix in remove_prefixes:
if key.startswith(prefix):
text_model_dict[key[len(prefix + ".") :]] = checkpoint[key]
if is_accelerate_available():
for param_name, param in text_model_dict.items():
set_module_tensor_to_device(text_model, param_name, "cpu", value=param)
else:
if not (hasattr(text_model, "embeddings") and hasattr(text_model.embeddings.position_ids)):
text_model_dict.pop("text_model.embeddings.position_ids", None)
text_model.load_state_dict(text_model_dict)
return text_model
textenc_conversion_lst = [
("positional_embedding", "text_model.embeddings.position_embedding.weight"),
("token_embedding.weight", "text_model.embeddings.token_embedding.weight"),
("ln_final.weight", "text_model.final_layer_norm.weight"),
("ln_final.bias", "text_model.final_layer_norm.bias"),
("text_projection", "text_projection.weight"),
]
textenc_conversion_map = {x[0]: x[1] for x in textenc_conversion_lst}
textenc_transformer_conversion_lst = [
# (stable-diffusion, HF Diffusers)
("resblocks.", "text_model.encoder.layers."),
("ln_1", "layer_norm1"),
("ln_2", "layer_norm2"),
(".c_fc.", ".fc1."),
(".c_proj.", ".fc2."),
(".attn", ".self_attn"),
("ln_final.", "transformer.text_model.final_layer_norm."),
("token_embedding.weight", "transformer.text_model.embeddings.token_embedding.weight"),
("positional_embedding", "transformer.text_model.embeddings.position_embedding.weight"),
]
protected = {re.escape(x[0]): x[1] for x in textenc_transformer_conversion_lst}
textenc_pattern = re.compile("|".join(protected.keys()))
def convert_text_encoder_2(
checkpoint,
config,
prefix="cond_stage_model.model.",
has_projection=False,
local_files_only=False,
**config_kwargs,
):
ctx = init_empty_weights if is_accelerate_available() else nullcontext
with ctx():
text_model = CLIPTextModelWithProjection(config) if has_projection else CLIPTextModel(config)
keys = list(checkpoint.keys())
keys_to_ignore = []
text_model_dict = {}
if prefix + "text_projection" in checkpoint:
d_model = int(checkpoint[prefix + "text_projection"].shape[0])
else:
d_model = 1024
text_model_dict["text_model.embeddings.position_ids"] = text_model.text_model.embeddings.get_buffer("position_ids")
for key in keys:
if key in keys_to_ignore:
continue
if key[len(prefix) :] in textenc_conversion_map:
if key.endswith("text_projection"):
value = checkpoint[key].T.contiguous()
else:
value = checkpoint[key]
text_model_dict[textenc_conversion_map[key[len(prefix) :]]] = value
if key.startswith(prefix + "transformer."):
new_key = key[len(prefix + "transformer.") :]
if new_key.endswith(".in_proj_weight"):
new_key = new_key[: -len(".in_proj_weight")]
new_key = textenc_pattern.sub(lambda m: protected[re.escape(m.group(0))], new_key)
text_model_dict[new_key + ".q_proj.weight"] = checkpoint[key][:d_model, :]
text_model_dict[new_key + ".k_proj.weight"] = checkpoint[key][d_model : d_model * 2, :]
text_model_dict[new_key + ".v_proj.weight"] = checkpoint[key][d_model * 2 :, :]
elif new_key.endswith(".in_proj_bias"):
new_key = new_key[: -len(".in_proj_bias")]
new_key = textenc_pattern.sub(lambda m: protected[re.escape(m.group(0))], new_key)
text_model_dict[new_key + ".q_proj.bias"] = checkpoint[key][:d_model]
text_model_dict[new_key + ".k_proj.bias"] = checkpoint[key][d_model : d_model * 2]
text_model_dict[new_key + ".v_proj.bias"] = checkpoint[key][d_model * 2 :]
else:
new_key = textenc_pattern.sub(lambda m: protected[re.escape(m.group(0))], new_key)
text_model_dict[new_key] = checkpoint[key]
if is_accelerate_available():
for param_name, param in text_model_dict.items():
set_module_tensor_to_device(text_model, param_name, "cpu", value=param)
else:
if not (hasattr(text_model, "embeddings") and hasattr(text_model.embeddings.position_ids)):
text_model_dict.pop("text_model.embeddings.position_ids", None)
text_model.load_state_dict(text_model_dict)
return text_model이 코드중 convert_unet convert_vae convert_text_encoder convert_text_encoder_2(sdxl는 텍스트 인코더가 2개) 가 diffusers 형식으로 모델을 변환하는 코드입니다.
convert_unet 을 보면 path를 지정하는 파라미터가 있는데 diffusers에서는 ""로 처리합니다. 저희도 빈 문자열을 넣어줍니다.
파라미터를 보면 checkpoint(state dict) 외에 config 값을 필수로 넣어야되는걸 볼 수 있는데
- checkpoint에 state dict 가중치값
- config 에 껍데기 모델의 config
를 넣어주면 됩니다.
마지막으로 파이토치에서 제공하는 .load_state_dict() 메서드 (껍데기 모델의 가중치를 외부에서 가져온 state_dict 값으로 업데이트)를 통해 원본모델에서 Unet, VAE, Encoder 모델을 뽑아낼 수 있습니다.
def convert_unet_from_ckpt_sd(unet : UNet2DConditionModel, ckpt_unet_sd : Dict):
path = ""
converted_unet_checkpoint = convert_unet(ckpt_unet_sd, unet.config, path)
unet.load_state_dict(converted_unet_checkpoint, strict=False)
return unet
def convert_vae_from_ckpt_sd(vae : AutoencoderKL, ckpt_vae_sd : Dict ):
converted_vae_checkpoint = convert_vae(ckpt_vae_sd, vae.config)
vae.load_state_dict(converted_vae_checkpoint, strict=False)
return vae
def convert_clip_from_ckpt_sd(clip_model : CLIPTextModel, ckpt_clip_sd : Dict, model_type : Literal['sd15', 'sdxl']):
converted_clip1_checkpoint = convert_text_encoder(ckpt_clip_sd, text_encoder=clip_model)
if model_type == 'sd15':
prefix = "cond_stage_model.model."
return converted_clip1_checkpoint
elif model_type == 'sdxl':
prefix = "conditioner.embedders.1.model."
config = TextEncoder.sdxl_enc2_config()
converted_clip2_checkpoint = convert_text_encoder_2(ckpt_clip_sd, config, prefix=prefix, has_projection=True, local_files_only = True)
return (converted_clip1_checkpoint, converted_clip2_checkpoint)최종 Load Checkpoint
MODEL_TYPE = ""
ENCODER = None
num_channels_latents = None
vae_scale_factor = None
device = get_torch_device()
dtype = torch.float16
# All Documentation comes from the ComfyUI Wiki.
# See https://comfyui-wiki.com/en for more details.
def load_checkpoint(ckpt_name : Union[os.PathLike, str]):
"""
The CheckpointLoaderSimple node is designed for loading model checkpoints without the need for specifying a configuration. It simplifies the process of checkpoint loading by requiring only the checkpoint name, making it more accessible for users who may not be familiar with the configuration details.
## Input types
ckpt_name : Specifies the name of the checkpoint to be loaded, determining which checkpoint file the node will attempt to load and affecting the node’s execution and the model that is loaded.
## Output types
model : Returns the loaded model, allowing it to be used for further processing or inference.
clip : Returns the CLIP model associated with the loaded checkpoint, if available.
vae : Returns the VAE model associated with the loaded checkpoint, if available.
"""
global MODEL_TYPE
global num_channels_latents
global vae_scale_factor
if not os.path.isabs(ckpt_name):
ckpt_dir = env.get_ckpt_dir()
ckpt_name = os.path.join(ckpt_dir, ckpt_name)
if not os.path.isfile(ckpt_name):
raise FileNotFoundError(f"Checkpoint file (.bin or .safetensors) not found : {ckpt_name}")
ckpt_model, ckpt_clip, ckpt_vae, model_type = extract_model_components(ckpt_name)
MODEL_TYPE = model_type
if model_type == 'sdxl':
original_unet = UNet.sdxl()
num_channels_latents = original_unet.config.in_channels
original_vae = VAE.sdxl()
vae_scale_factor = 2 ** (len(original_vae.config.block_out_channels) - 1)
original_encoder = TextEncoder.sdxl_enc1()
unet = convert_unet_from_ckpt_sd(original_unet, ckpt_model)
vae = convert_vae_from_ckpt_sd(original_vae, ckpt_vae)
enc1, enc2 = convert_clip_from_ckpt_sd(original_encoder, ckpt_clip, model_type)
clip = (enc1, enc2)
model = (unet, vae, clip)
return model, clip, vae
elif model_type == 'sd15':
original_unet = UNet.sd15()
num_channels_latents = original_unet.config.in_channels
original_vae = VAE.sd15()
original_encoder = TextEncoder.sd15_enc()
vae_scale_factor = 2 ** (len(original_vae.config.block_out_channels) - 1)
unet = convert_unet_from_ckpt_sd(original_unet, ckpt_model)
vae = convert_vae_from_ckpt_sd(original_vae, ckpt_vae)
clip = convert_clip_from_ckpt_sd(original_encoder, ckpt_clip, model_type)
model = (unet, vae, clip)
return model, clip, vae글로벌로 선언된 변수들과 값을 할당하는 num_channels_latents vae_scale_factor 는 추후에 잠재벡터()를 만들고 디코딩할때 사용됩니다.
데이터타입(dtype)의 경우 저는 H100을 살 형편이 안되기 때문에 적당한 GPU로 돌릴 수 있게끔 기본 float32에서 float16으로 선언해줍니다.
나머지 노드들은 다음 포스팅에서 설명하도록 하겠습니다.
