Summary
Introduction
RAG (Retrieval-Augmented Generation)은 대규모 언어 모델(LLM)의 한계를 극복하기 위해 제안된 자연어 처리 기술입니다.
RAG는 LLM이 외부 데이터베이스를 활용하여 더욱 정확하고 맥락에 맞는 답변을 생성하도록 돕습니다.
Code, Conept & Explanation
RAG 모델의 핵심 아이디어
RAG는 검색(Retrieval)과 생성(Generation)을 결합하여 대규모 언어 모델의 성능을 강화하는 접근 방식입니다.
RAG는 언어 모델이 특정 질문이나 요청에 대해 외부 데이터베이스나 문서에서 관련 정보를 검색하고 이를 활용해 더 정밀하고 맥락에 맞는 응답을 생성하도록 설계되었습니다.
RAG 모델의 작동 원리
Retriever(검색기):
입력된 질문에 대해 관련 문서를 검색.
- 입력 문장(예: 질문)이 주어지면, 관련성이 높은 문서를 외부 데이터베이스(예: 위키피디아, 사전 구축한 문서 코퍼스 등)에서 검색합니다.
- 일반적으로 Dense Retrieval 모델(예: DPR, BM25)이 사용됩니다.
Generator(생성기):
검색된 문서를 바탕으로 최종 답변을 생성.
- 검색기로부터 검색된 문서들을 입력으로 받아, 질문에 대한 응답을 생성합니다.
- 주로 Seq2Seq 모델(예: BART, T5)이 사용됩니다.
RAG vs 미세 조정
- 미세 조정: 모델 자체를 특정 작업에 맞게 학습시키는 방식. 비용과 시간이 많이 소요됨.
- RAG: 기존 모델을 학습시키지 않고 외부 데이터를 연결하여 빠르고 효율적인 결과 생성.
RAG의 작동 방식
- 질문 또는 요청이 주어지면, 검색기가 데이터베이스에서 관련성이 높은 문서들(top-K)를 검색합니다.
- 검색된 문서들은 생성기의 입력으로 전달됩니다.
- 생성기는 검색된 문서를 참고하여 질문에 대한 응답을 생성합니다.
RAG 모델의 장점
- 외부 지식 활용: 모델이 학습된 데이터 외에도 최신 데이터나 특정 도메인의 지식을 활용할 수 있습니다.
- 효율성: 대규모 언어 모델을 단독으로 사용할 때보다 작은 크기의 모델로도 높은 성능을 낼 수 있습니다.
- 투명성: 검색된 문서와 생성된 응답을 제공하므로, 응답의 출처를 확인할 수 있습니다.
RAG 모델의 활용 사례
-
질문 답변 시스템 (Q&A)
예: 의료 지식, 법률 정보 등 특정 도메인에서 사용자 질문에 답변. -
문서 요약 및 생성
긴 문서를 기반으로 요약 생성. -
지식 기반 챗봇
최신 정보를 제공하거나 특정 도메인에 최적화된 대화 시스템 개발. -
제품 추천
사용자 피드백과 관련 문서를 검색하여 개인화된 제품 추천 제공.
RAG 모델의 단점
- 검색 정확도 의존: 검색기가 잘못된 문서를 선택하면, 생성기 역시 오류가 있는 응답을 생성할 가능성이 높습니다.
- 속도: 검색과 생성의 두 단계를 거치므로 처리 속도가 느릴 수 있습니다.
- 데이터베이스 구축: 관련성 높은 데이터베이스를 구축하고 유지하는 데 비용과 노력이 필요합니다.
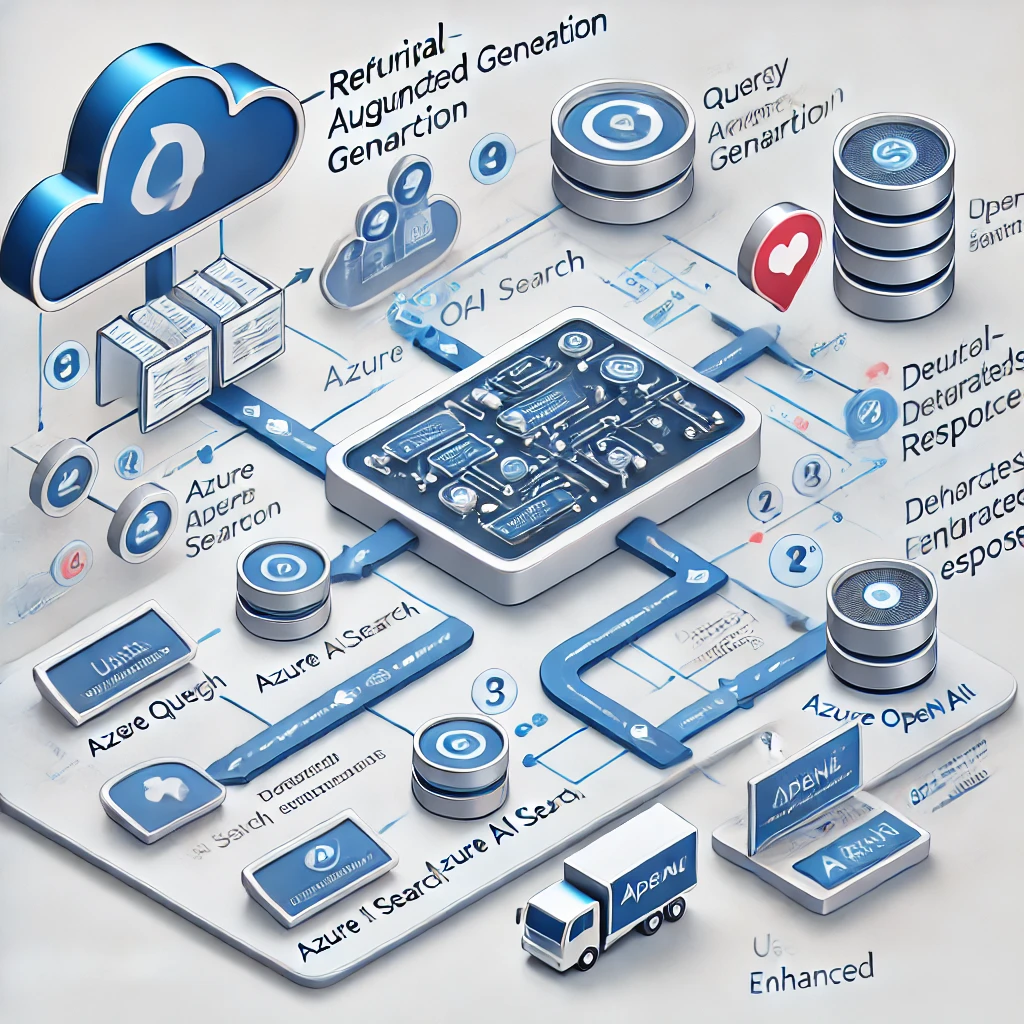
Azure OpenAI에서의 RAG 활용
Azure OpenAI Service를 통해 RAG를 쉽게 구현할 수 있습니다.
- 데이터 업로드: .txt, .pdf, .html 등 다양한 파일 형식 지원.
- AI Search 연결: 데이터를 인덱싱해 효율적으로 검색.
- API 활용: 외부 데이터와 함께 OpenAI API 호출 가능.
Azure OpenAI로 시작하는 방법
Azure OpenAI Studio 활용: 데이터 추가 및 설정.
Chat Playground: 사용자 지정 데이터를 참고해 응답 생성 실습.
API와 Visual Studio Code 연동: 코드 기반 응용 프로그램 개발.
Challenges & Solutions
Results
What I Learned & Insights
Conlusion
RAG는 기존 언어 모델의 한계를 보완하고, Azure OpenAI의 기능과 결합해 강력한 검색 및 생성 시스템을 제공합니다.
