Summary
Introduction
Azure Conversational Language Understanding(CLU)은 사용자의 대화 데이터를 분석하여 의도(Intent)와 엔티티(Entity)를 식별하는 AI 서비스입니다. 이 문서에서는 CLU를 설정, 학습, 배포하는 방법을 정리했습니다.
Code, Conept & Explanation
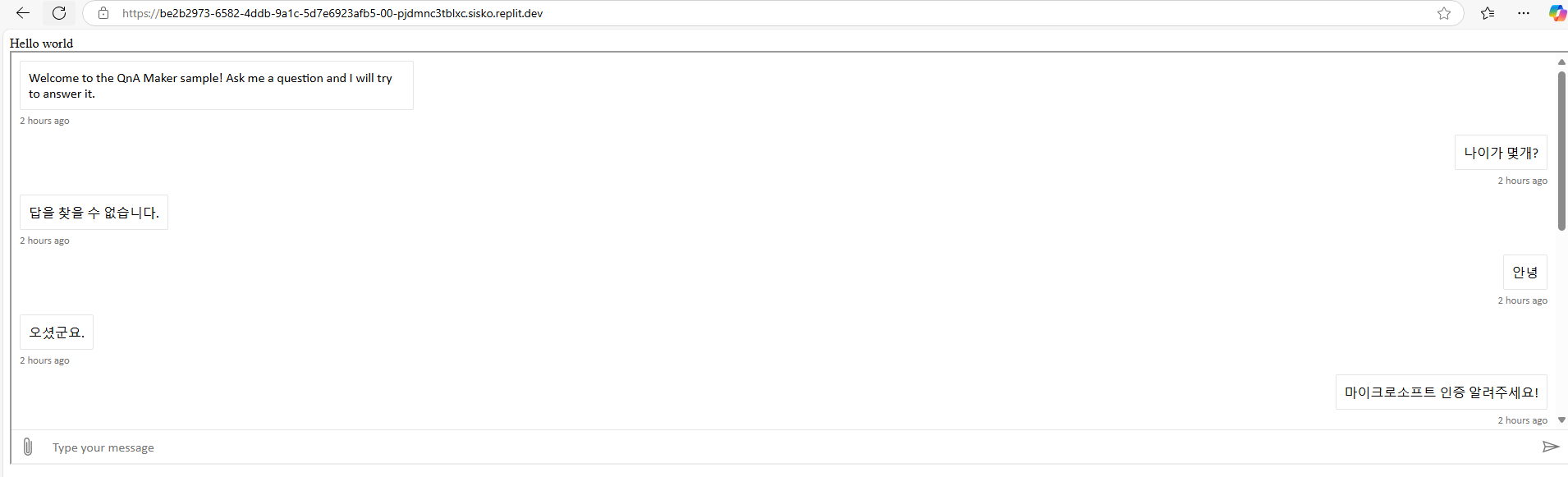
특정 분야에 맞춰서 특화된 답변을 하는 챗봇
여행사 등 특정 서비스에서 활용 기대
리플릿에서 구현
HTML 통해 생성
1. 리소스 생성 및 설정
1.1 리소스 그룹 생성
1. Azure Portal에서 리소스 그룹을 생성합니다.
- 리소스 그룹 이름을 지정합니다.
- 지역을 선택합니다 (CLU 작업은 Australia East에서 가능합니다).
1.2 AI 서비스 리소스 생성
- Marketplace에서 AI Services를 검색합니다.
- OpenAI 로고가 포함된 최신 버전을 선택합니다.
- 리소스 이름, 지역, Pricing Tier (Standard S0)를 설정한 뒤 리소스를 생성합니다.
1.3 Language Studio로 이동
- 생성된 리소스를 통해 Language Studio에 접속합니다.
- Custom Conversational Language Understanding을 선택하여 설정을 시작합니다.
2. CLU 프로젝트 생성 및 학습
2.1 프로젝트 생성
- Language Studio에서 Create new project를 선택합니다.
- 프로젝트 이름을 입력하고 데이터 언어를 설정합니다.
2.2 데이터 업로드
- JSON 또는 텍스트 데이터를 업로드합니다.
- GitHub 예제: EmailAppDemo.json
- 데이터 레이블링(Schema Definition, Data Labeling) 단계를 완료하거나 이미 준비된 데이터를 사용할 수 있습니다.
2.3 학습 실행
- 모델 학습을 위해 다음 설정을 진행합니다:
- 학습 모델 이름 지정.
- Standard Training(무료) 또는 Advanced Training(다국어 지원) 선택.
- 데이터 세트를 학습/테스트 용도로 분리.
- 학습을 완료하고 모델 성능(Micro F1, Precision, Recall)을 확인합니다.
3. CLU 모델 배포 및 테스트
3.1 모델 배포
- 학습된 모델을 배포합니다:
- 배포 이름을 지정합니다.
- 배포할 지역을 선택합니다.
- 배포 상태를 확인합니다.
3.2 모델 테스트
- 배포된 모델을 API 호출로 테스트합니다.
- 사용자의 입력 문장에서 의도와 엔티티를 분석합니다.
4. 오류 해결 방법
4.1 Cannot find published project 오류
- 오류 원인: 지정된 프로젝트 이름 또는 배포 이름이 일치하지 않음.
- 해결 방법:
- Language Studio에서 프로젝트 이름과 배포 이름을 확인합니다.
- API 호출 코드에서 올바른 이름을 설정합니다.
4.2 Input documents cannot be a string
- 오류 원인: API가 문자열 대신 JSON 배열을 요구.
- 해결 방법:
{
"documents": [
{ "id": "1", "text": "문서 내용" }
]
}5. Python API 호출 예제
from azure.ai.textanalytics import TextAnalyticsClient
from azure.core.credentials import AzureKeyCredential
# 설정
endpoint = "https://<your-endpoint>.cognitiveservices.azure.com/"
key = "<your-key>"
project_name = "ProjectName"
deployment_name = "DeploymentName"
# 클라이언트 생성
client = TextAnalyticsClient(endpoint=endpoint, credential=AzureKeyCredential(key))
# 데이터 준비
documents = [{"id": "1", "text": "Sample text for analysis."}]
# 요청
poller = client.begin_single_label_classify(
documents=documents,
project_name=project_name,
deployment_name=deployment_name
)
result = poller.result()
for doc in result:
if doc.classifications:
for classification in doc.classifications:
print(f"Category: {classification.category}, Confidence: {classification.confidence_score:.2f}")6. 모델 성능 평가
6.1 주요 지표
- Micro F1 Score: 전체 모델의 정확도.
- Precision: 올바른 예측 비율.
- Recall: 실제 인스턴스를 올바르게 예측한 비율.
6.2 성능 시각화
Language Studio에서 모델의 의도(Intent)와 엔티티(Entity)별 성능 지표를 확인할 수 있습니다.
Challenges & Solutions
Results
What I Learned & Insights
Conlusion
Azure Conversational Language Understanding은 대화 데이터를 분석하고 이해하는 데 강력한 도구입니다. 올바른 프로젝트와 배포 설정, 그리고 적절한 학습 데이터 준비를 통해 높은 정확도의 모델을 구현할 수 있습니다.

New life & History