Git
git을 매번 쓰지만 얘가 어떻게 동작하는지는 큰 관심이 없었고, 그냥 잘 쓰는 것에만 관심이 있었다. 이번 기회에 git이 어떻게 동작하는지를 알아보고자 한다.
여러가지 방법이 있겠지만, 오늘은 git에서 제공하는 공식문서를 쭉 읽어보려고 한다. git 공식문서
docker를 배울때도 공식문서가 도움이 많이 되었는데, git도 읽어봐야지 생각만 가지고 있다가 이번기회에 제대로 읽어보려고 한다.
공식문서 발췌
Git의 기초
Git은 파일을 Committed, Modified, Staged 이렇게 세 가지 상태로 관리한다.
- Committed란 데이터가 로컬 데이터베이스에 안전하게 저장됐다는 것을 의미한다.
- Modified는 수정한 파일을 아직 로컬 데이터베이스에 커밋하지 않은 것을 말한다.
- Staged란 현재 수정한 파일을 곧 커밋할 것이라고 표시한 상태를 의미한다.
Git 디렉토리는 Git이 프로젝트의 메타데이터와 객체 데이터베이스를 저장하는 곳을 말한다.
워킹 트리는 프로젝트의 특정 버전을 Checkout 한 것이다.
Staging Area는 Git 디렉토리에 있다. 단순한 파일이고 곧 커밋할 파일에 대한 정보를 저장한다.
Git으로 하는 일은 기본적으로 아래와 같다.
- 워킹 트리에서 파일을 수정한다.
- Staging Area에 파일을 Stage 해서 커밋할 스냅샷을 만든다. 모든 파일을 추가할 수도 있고 선택하여 추가할 수도 있다.
- Staging Area에 있는 파일들을 커밋해서 Git 디렉토리에 영구적인 스냅샷으로 저장한다.
Git의 내부 - 1
git init 명령을 실행하면 Git은 데이터를 저장하고 관리하는 .git 디렉토리를 만든다. 이 디렉토리를 복사하기만 해도 저장소가 백업 된다.
- git 디렉토리 구조
$ ls -F1
config -> config 파일에는 해당 프로젝트에만 적용되는 설정 옵션
description -> GitWeb 프로그램에서만 사용하기 때문에 이 파일은 신경쓰지 않아도 됨
HEAD
hooks/ -> 클라이언트 훅이나 서버 훅이 위치
info/ -> info 디렉토리는 .gitignore 파일처럼 무시할 파일의 패턴을 적어 두는 곳
objects/
refs/이제 남은 네 가지 항목은 모두 중요한 항목이다. HEAD 파일, index 파일, objects 디렉토리, refs 디렉토리가 남았다. 이 네 항목이 Git의 핵심이다.
- objects: 디렉토리는 모든 컨텐트를 저장하는 데이터베이스
- refs: 디렉토리에는 커밋 개체의 포인터를 저장 (브랜치, 태그, 리모트 등)
- HEAD: 현재 Checkout 한 브랜치를 가리키는 포인터
- index: Staging Area의 정보를 저장
Git의 내부 - 2
Git은 Content-addressable 파일시스템이다. 이게 무슨 말이냐 하면 Git의 핵심은 단순한 Key-Value(역주 - 예, 파일 이름과 파일 데이터) 데이터 저장소라는 것이다. 어떤 형식의 데이터라도 집어넣을 수 있고 해당 Key로 언제든지 데이터를 다시 가져올 수 있다.
Blob
파일을 생성 후 git hash-object으로 Git 데이터베이스에 새 데이터 개체를 직접 저장하면, Git은 SHA-1 해시를 계산하고 해당 데이터를 저장한다. 그 결과로 나온 해시 값은 파일 이름이 된다. 이렇게 해서 Git은 파일 이름을 SHA-1 해시 값으로 변환하고, 그 해시 값으로 파일을 찾는다. git hash-object 명령이 출력하는 것은 40자 길이의 체크섬 해시다. 해시의 처음 두 글자를 따서 디렉토리 이름에 사용하고 나머지 38글자를 파일 이름에 사용한다.
데이터를 수정 후 다시 git hash-object로 저장하면, 데이터베이스에는 데이터가 두 가지 버전으로 저장돼 있다. 앞선 파일과 내용이 완전히 똑같다면, Git은 새로 저장하지 않는다.
파일의 이름은 저장하지도 않고, 단지 파일 내용만 저장한다.
이런 종류의 개체를 Blob이라고 하고, 여기까지가 blob에 대한 설명이다.
Tree
파일의 이름은 Tree 개체에 저장한다. 파일 여러 개를 한꺼번에 저장할 수도 있다. Git은 유닉스 파일 시스템과 비슷한 방법으로 저장하지만 좀 더 단순하다. 모든 것을 Tree와 Blob 개체로 저장한다.
Tree는 유닉스의 디렉토리에 대응되고 Blob은 Inode나 일반 파일에 대응된다. Tree 개체는 파일이나 다른 디렉토리에 대한 포인터를 가지고 있고, Blob 개체는 파일의 내용을 가지고 있다.
그러니까, blob은 개별 파일에 대해 저장하고, tree는 디렉토리에 대해 저장한다.
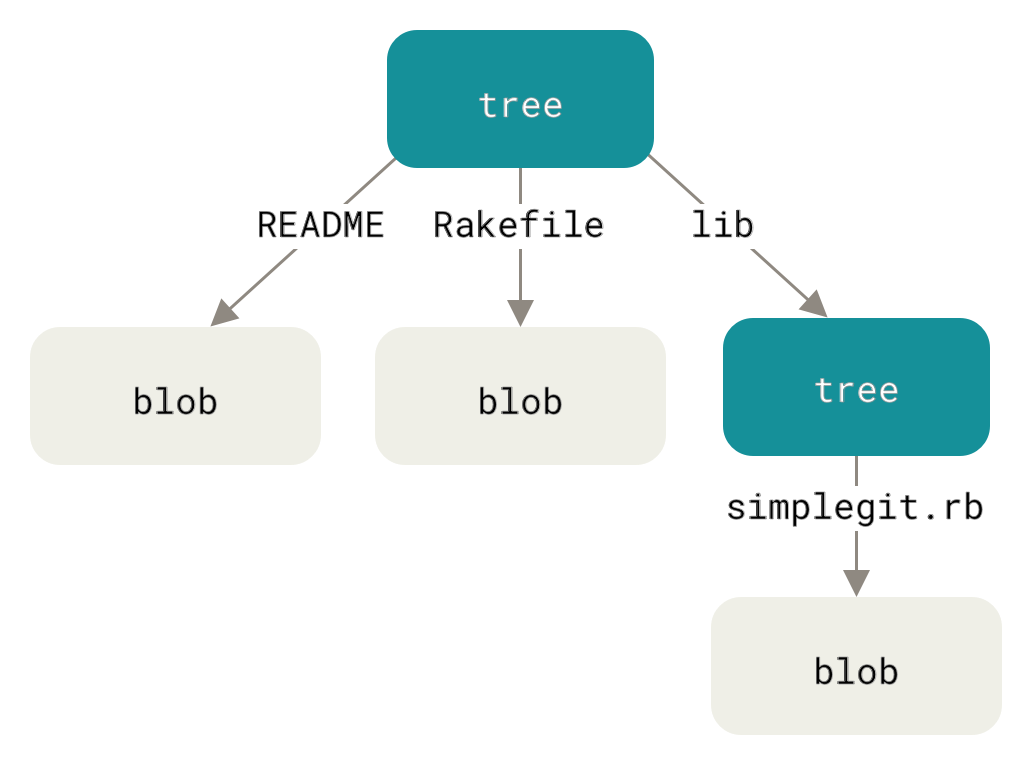
Git은 일반적으로 Staging Area(Index)의 상태대로 Tree 개체를 만들고 기록한다.
그래서 Tree 개체를 만들려면 우선 Staging Area에 파일을 추가해서 Index를 만들어야 한다. -> 우리 과제에선 하나로 통합된 듯?
그럼 JS에서 이 tree 개체를 어떻게 생성할까? 바로 떠오르는 생각은 당연히 js의 object를 이용하는 것이다. 한번 commit을 하면 디렉토리에 있는 모든 blob들을 json tree로 만들고 blob이랑 동일하게 저장하면 될듯?
Commit
아직 남은 어려운 점은 여전히 이 스냅샷(tree?)을 불러오려면 SHA-1 값을 기억하고 있어야 한다는 점이다. 스냅샷을 누가, 언제, 왜 저장했는지에 대한 정보는 아예 없다. 이런 정보는 커밋 개체에 저장된다.
commit 객체의 저장경로는 다음과 같다. .git/index/commits
정리
아주 간단하게 git이 내부에서 어떻게 동작하는지 알아보았다. 여전히 어려운점이 많이 남아있지만, git이 꼬였을 때, 어떤 파일이 어디에 들어가 있는지 생각하면서, 조금 더 효과적으로 git을 사용할 수 있을 것 같다.
