
🤗 소개
앞 글에서는 단일 노이즈 수준에서의 Denoising Score Matching(DSM)이 score 학습과 denoising, 그리고 Bayes 최적 추정과 어떻게 연결되는지를 살펴보았다. 그러나 하나의 고정된 노이즈 수준만으로는 데이터 분포의 전역 구조와 국소 구조를 동시에 포착하는 데 한계가 있다. 이번 글에서는 이러한 문제를 해결하기 위해 여러 노이즈 수준에 걸쳐 score를 학습하는 접근법, 즉 Multi-Noise Level Denoising Score Matching 을 소개한다.
이 방법은 서로 다른 스케일에서의 score 정보를 통합함으로써 보다 안정적인 학습과 효과적인 샘플링을 가능하게 하며, 이후 전개되는 Noise-Conditional Score Networks(NCSN) 및 현대적인 score-based diffusion 모델의 핵심 아이디어를 형성한다.
🏘️ DSM에서 NCSN으로
단일 노이즈 수준에서의 DSM은 score 기반 생성의 핵심 메커니즘을 잘 드러내지만, 실제 생성 과정에서는 노이즈의 크기에 따라 모델이 수행해야 하는 역할이 크게 달라진다. 노이즈가 큰 영역에서는 global한 구조를 포착하는 능력이 중요하고, 노이즈가 작아질수록 점점 더 정밀한 local한 정보가 요구된다.
이러한 관찰은 score를 하나의 고정된 스케일에서 학습하기보다는, 여러 노이즈 수준에 조건부로 학습하는 방식이 보다 자연스럽고 효과적일 수 있음을 시사한다.
1️⃣ 다중 노이즈의 동기
데이터 분포에 하나의 고정된 분산을 갖는 Gaussian 노이즈를 추가하면 분포가 일정 수준까지는 매끄럽게 되지만, 단일 노이즈 수준에서만 score 기반 모델을 학습하는 것은 몇 가지 중요한 한계를 가진다. 주입된 노이즈의 크기가 작은 경우, 저밀도 영역에서 기울기가 거의 사라지기 때문에 Langevin dynamics는 다봉(multimodal) 분포의 서로 다른 mode 사이를 효과적으로 이동하지 못한다.
반대로 노이즈 수준이 큰 경우에는 샘플링 자체는 쉬워지지만, 모델이 분포의 거친 구조만을 포착하게 되어 세부적인 정보를 잃은 흐릿한 샘플이 생성된다.
더 나아가, Langevin dynamics는 고차원 공간에서 수렴 속도가 느리거나 심지어 실패할 수도 있다. 이 방법은 로그 density의 기울기(score)에 의존해 샘플을 유도하기 때문에, 초기화가 좋지 않은 경우, 특히 평탄한 영역이나 안장점(saddle point) 근처에서는 탐색이 제대로 이루어지지 않거나 샘플러가 하나의 mode에 갇히는 문제가 발생할 수 있다.
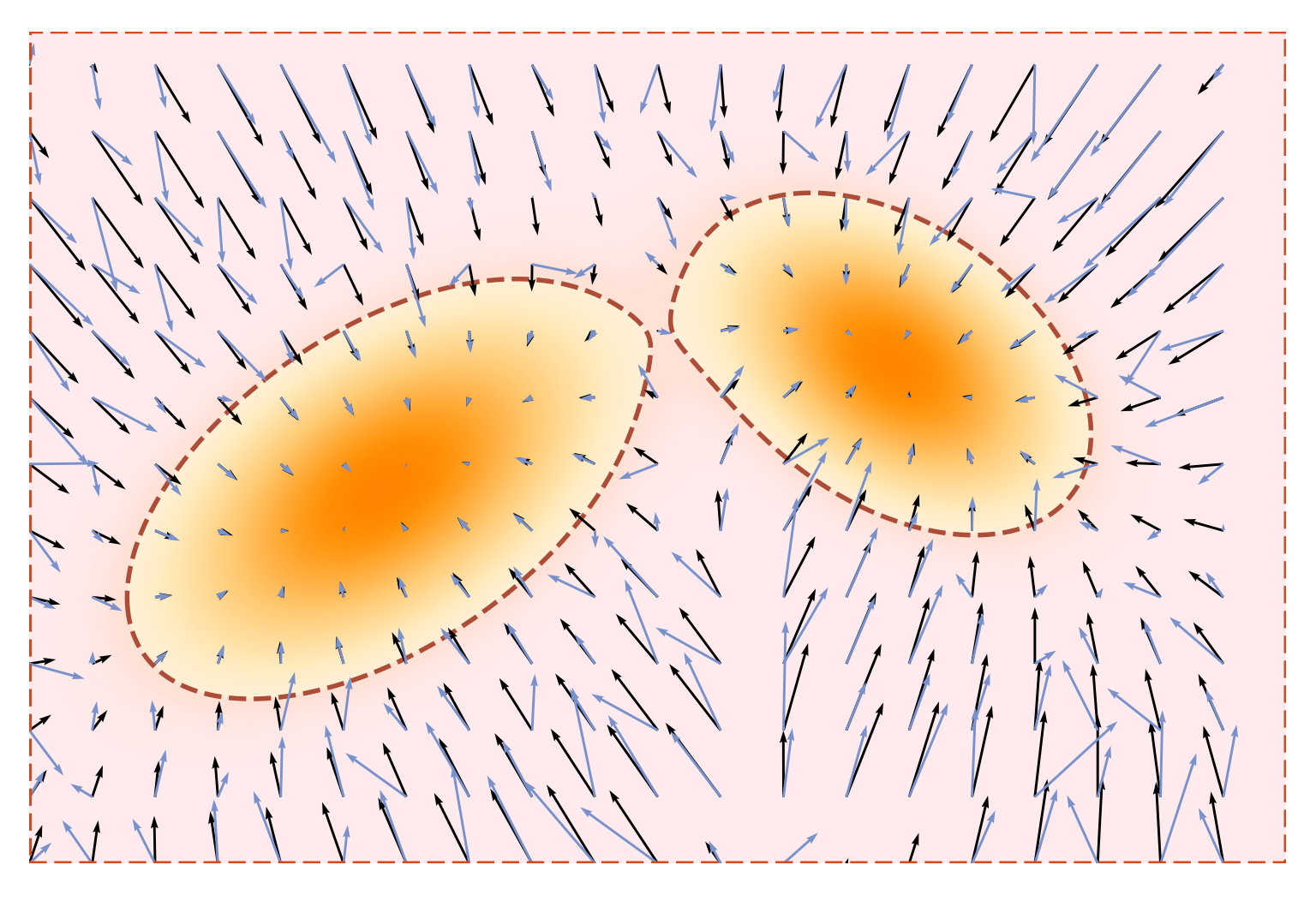
이러한 문제들을 해결하기 위해 Song과 Ermon(2019) 은 여러 노이즈 수준에서 Gaussian 노이즈를 데이터 분포에 주입하고, 다양한 노이즈 스케일에 걸친 score 함수를 추정하도록 노이즈 조건부 score 네트워크(Noise-Conditional Score Network; NCSN) 를 공동으로 학습하는 방법을 제안하였다.
생성 단계에서는 Langevin dynamics를 noise annealing 방식으로 적용하는데, 먼저 높은 노이즈 수준에서 시작하여 global한 탐색을 가능하게 한 뒤, 점차 노이즈 수준을 낮추면서 세부적인 구조를 복원해 나간다.
2️⃣ 다중 노이즈 학습
단일 노이즈 수준에서 학습된 score 기반 모델의 한계를 극복하기 위해, Song과 Ermon(2019)는 위에서 언급한 대로 여러 노이즈 수준에서 Gaussian 노이즈를 데이터 분포에 추가하는 방법을 제안하였다.
구체적으로,
을 만족하는 개의 노이즈 수준 을 선택한다. 여기서 은 데이터의 대부분의 세부 구조를 보존할 수 있을 만큼 충분히 작고, 은 분포를 충분히 평활화하여 학습을 보다 용이하게 만들 수 있을 만큼 충분히 크게 설정된다.
각 노이즈 수준 에 대한 관측 샘플은, 깨끗한 데이터 샘플 에 Gaussian 노이즈를 추가함으로써 생성되며, 와 같이 정의된다.
이를 통해 다음 두 가지를 정의할 수 있다.
- 섭동(Perturbation) 커널: 이고, 이는 아래를 유도한다.
- 주변(Marginal) 분포: 이고, 이는 각 노이즈 레벨 마다 정의된다.
이들은 평활화된 Gaussian 분포를 생성한다.
🏓 NCSN의 목적 함수
목표는 노이즈 조건부 score 신경망 를 학습하여, 모든 노이즈 수준 에 대해 score 함수 를 추정하는 것이다. 이를 위해 모든 노이즈 수준에 걸쳐 DSM 목적 함수를 최소화한다.
여기서
이며, 는 각 노이즈 스케일에 대한 가중 함수이다. 이 목적 함수 를 최소화하면, 각 노이즈 수준에서의 true score 함수를 회복하는 score 모델
을 얻게 되는데, 이는 본질적으로 DSM 최소화 문제이기 때문이다.
👩🏼❤️👨🏻 DDPM 손실과의 관계
이고, 이라 가정하자. 또한 를 이에 대응하는 marginal 분포로 설정하면, Tweedie 공식에 의해 다음이 성립한다.
따라서 NCSN의 최적해는 true score 인 반면, 이전 글에서 소개한 DDPM 손실에서의 Bayes 최적 노이즈 예측기는 이다. 이 둘은 다음과 같은 관계를 통해 정확히 동치 관계를 가진다.
DDPM의 이산(discrete) 시간 인덱스 를 갖는 섭동(perturbation) 방정식
에 대해서도 동일한 관계가 성립하여,
를 얻을 수 있다. 따라서 DDPM 손실을 최소화하는 것은 에 대한 조건부 denoiser를 학습하는 것이며, 이는 노이즈 수준 에서의 true score를 스케일링한 재매개변수화 에 해당한다.
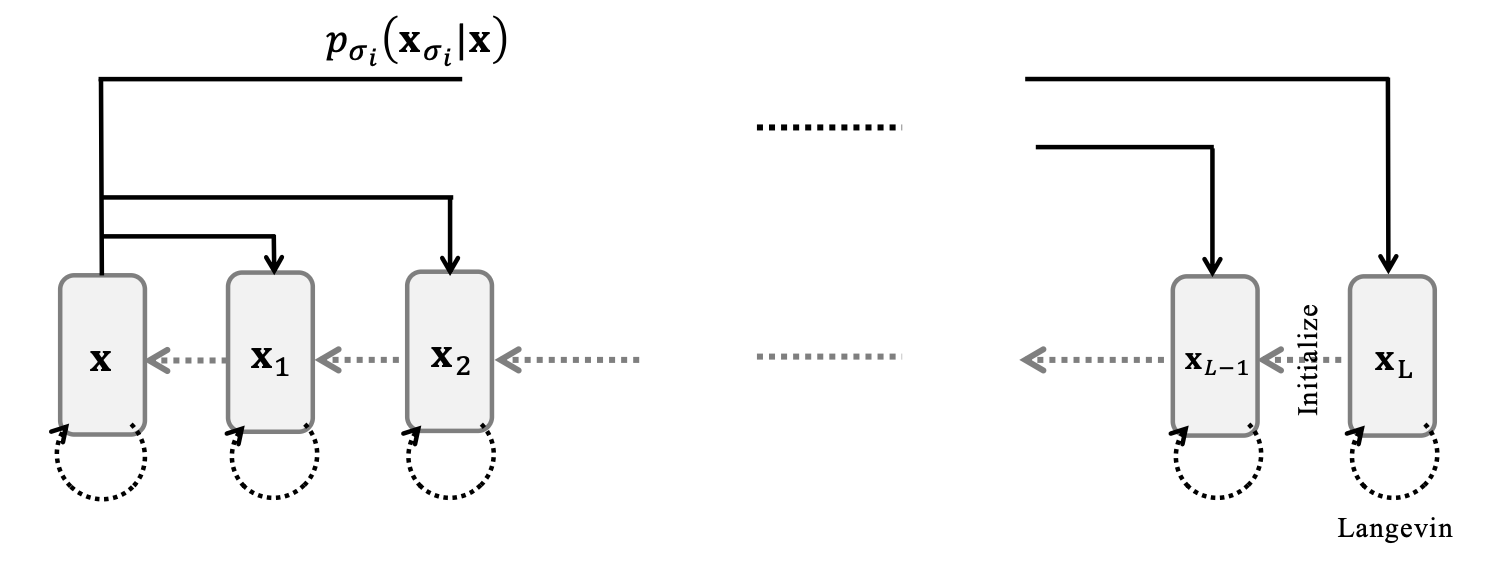
3️⃣ NCSN에서의 샘플링
여러 노이즈 수준에서 학습된 score 네트워크
가 주어졌을 때, Annealed Langevin Dynamics라 불리는 샘플링 절차(Song and Ermon, 2019)는 높은 노이즈 수준 에서 시작하여 낮은 노이즈 수준 까지 점진적으로 denoising을 수행 함으로써 데이터를 생성한다.
이 알고리즘은 Gaussian 노이즈 에서 시작하여, 각 노이즈 수준 마다 Langevin dynamics를 적용하여 섭동된 분포 로부터의 샘플링을 근사적으로 수행한다. 노이즈 수준 에서 얻어진 출력은, 다음으로 더 낮은 노이즈 수준 에서의 더 나은 초기값(initialization) 으로 사용된다.
각 노이즈 수준에서 Langevin dynamics는 다음과 같이 반복적으로 업데이트 된다.
초기값은 로 설정된다. 스텝 크기(step-size)는 일반적으로 노이즈 수준에 따라 스케일링되며,
와 같이 정해진다.
이와 같은 노이즈 annealing 기반의 점진적 정제 과정은 최저 노이즈 수준 까지 진행되며, 최종적으로 샘플 을 얻게 된다. 이전 단계의 출력을 다음 단계의 더 나은 초기값으로 지속적으로 활용함으로써, 이 전략은 복잡한 데이터 분포에 대해 보다 효과적인 탐색과 향상된 coverage를 가능하게 한다.
이에 대한 전반적인 알고리즘은 아래에 의사코드로 정리되어 있다.
🧩 알고리즘 1 – Annealed Langevin Dynamics
입력: 학습된 score 함수 , 각 노이즈 수준 에 대한 스텝 크기 , 그리고 Langevin 반복 횟수
- for do
- ▷ 이전 노이즈 수준의 출력을 초기값으로 사용하여 Langevin 초기화
- for to do
- end for
- ▷ 다음 노이즈 수준에서의 초기값으로 사용
- end for
출력: 모든 denoising이 완료된
🐢 NCSN의 느린 샘플링 속도
NCSN은 노이즈 스케일 전반에 걸쳐 annealing된 MCMC(주로 Langevin dynamics) 를 사용하여 샘플을 생성한다. 각 노이즈 스케일 마다, 모델은 score 에 기반해 을 업데이트하고, 여기에 작은 무작위 섭동을 더하는 형태의 반복 업데이트를 회 수행하며, 각 업데이트마다 score 네트워크에 대한 한 번의 순전파가 필요하다.
이러한 구조로 인해 전체 샘플링 과정에는 가 요구되는데, 그 이유는 다음의 두 가지이다.
-
국소적 정확도와 안정성 – Local Accuracy & Stability
학습된 score는 작은 섭동에 대해서만 신뢰할 수 있으므로, 편향이나 불안정성을 피하기 위해 각 노이즈 수준마다 작은 스텝 크기와 많은 반복 횟수 가 필요하다. -
고차원에서의 느린 혼합 – Slow Mixing in high Dimensions
국소적인 MCMC 이동은 다봉(multimodal)이고 고차원인 목표 분포를 비효율적으로 탐색하므로, 전형적인 데이터 영역에 도달하기까지 많은 반복 이 요구된다.
업데이트가 엄격히 순차적(strictly sequential; 각 반복이 이전 상태에 의존)이며, 각 단계마다 비용이 큰 네트워크 evaluation이 필요하기 때문에, 전체 계산 비용은 순차적인 네트워크 순전파 에 해당한다. 이로 인해 NCSN의 샘플링은 계산적으로 매우 느리다.
4️⃣ NCSN과 DDPM의 비교
다음은 NCSN과 DDPM을 비교한 표이다.

위 표는 NCSN과 DDPM이 서로 다른 정식화를 취하고 있음에도 불구하고 매우 밀접하게 대응되는 구조를 가지고 있음을 보여준다.
NCSN에서는 노이즈가 직접적으로 데이터에 추가되어 형태로 정의되며, 인접한 노이즈 수준 사이의 전이는 로 유도된다. 반면 DDPM에서는 forward 과정이 Markov chain으로 명시적으로 정의되어 , 그리고 와 같은 형태를 갖는다.
이로 인해 NCSN은 marginal 분포 를 직접 다루는 반면, DDPM은 시간에 따라 정의된 잠재 변수들의 연쇄를 통해 분포를 모델링한다는 차이가 있다. 또한 사전 분포 역시 NCSN은 , DDPM은 로 설정되어 노이즈 스케일링 방식에서 차이를 보인다.
손실 함수의 관점에서 보면, 두 방법의 관계는 더욱 명확해진다. NCSN은 각 노이즈 수준에서 score를 직접 학습하며, 손실은 의 형태로 주어진다. 반면 DDPM은 노이즈 자체를 예측하는 방향으로 파라미터화되어 를 최소화한다.
그러나 Tweedie 공식에 의해 가 성립하므로, 두 손실은 서로 다른 변수에 대한 재매개변수화(reparametrization) 일 뿐, 동일한 Bayes 최적 해를 공유한다.
샘플링 단계에서도 차이가 드러나는데, NCSN은 각 노이즈 레벨마다 Langevin dynamics를 적용하고 그 출력을 다음 단계의 초기값으로 사용하는 반면, DDPM은 학습된 역전이 를 따라 Markov chain을 역으로 순회한다. 그럼에도 불구하고 두 방법 모두 조밀한 시간 이산화(time discretization)에 의존 한다는 공통된 bottleneck을 가지며, 이는 이후 샘플링 가속 기법의 필요성을 자연스럽게 제기한다.
✅ 정리
앞선 글들과 이번 글을 통해 EBM에 뿌리를 둔 score 기반 관점에서 출발하여, 확산 모델로 이어지는 두 번째 주요 경로를 살펴보았다. 먼저 EBM의 핵심적인 난제인 partition function의 intractability를 짚고, 이를 완전히 우회할 수 있는 강력한 도구로서 score 함수 를 도입하였다.
이후 고전적인 score matching에서 출발해, 보다 확장 가능하고 안정적인 변형인 denoising score matching(DSM) 으로 나아갔다. DSM을 통해 데이터에 노이즈를 주입하면 조건화를 활용한 단순한 회귀 문제 로 학습 목표를 구성할 수 있음을 보았으며, 이를 통해 계산적으로 tractable한 학습이 가능해짐을 확인하였다. 더 나아가 Tweedie 공식을 통해 score 추정과 denoising 행위 사이의 깊은 연결을 확립하였는데, 이는 score가 노이즈가 섞인 관측치로부터 깨끗한 신호를 추정하는 데 필요한 정확한 방향 정보를 제공함을 보여준다.
이러한 원리는 단일 노이즈 수준에 국한되지 않고, noise-conditional score networks(NCSN )를 통해 연속적인 노이즈 스케일 전반으로 확장되었다. NCSN은 여러 노이즈 수준에 조건부로 학습된 하나의 score 모델을 통해 annealing된 Langevin dynamics 를 사용하여 샘플을 생성한다. 탐구에 마지막에 이르러, 기원은 다르지만 NCSN과 변분적 관점의 DDPM이 매우 유사한 구조와 공통된 병목을 공유한다는 사실 또한 발견하였다.
이러한 수렴은 우연이 아니다. 이는 더 깊은 수준에서의 통합된 수학적 구조가 존재함을 시사한다. 이산 시간 모델들이 지닌 한계를 보다 일반적인 프레임워크의 필요성을 자연스럽게 이끌어낸다. 앞으로 이어질 글들에서는 이 결정적인 단계로 나아가는 과정을 다룰 예정이다.
-
연속 시간 관점으로 전환하여, DDPM과 NCSN이 하나의 강력한 확률 과정, 즉 확률 미분 방정식(stochastic differential equation; SDE) 의 서로 다른 이산화(discretization)로 우아하게 통합될 수 있음을 보일 예정이다.
-
이 Score SDE 프레임워크는 변분적 관점과 score 기반 관점을 형식적으로 연결하며, 생성 문제를 미분 방정식을 푸는 문제로 재정식화한다.
이러한 통합적 시각은 이론적인 명료성을 제공할 뿐만 아니라, 느린 샘플링이라는 근본적인 문제를 해결하기 위해 설계된 새로운 고급 수치적 방법들을 가능하게 하는 문을 열어준다.
📄 출처
[1] Lai, Chieh-Hsin, et al. The Principles of Diffusion Models. arXiv, 24 Oct. 2025, arXiv:2510.21890.
