
🧬 Lucid vs. PyTorch 비교: ResNet-18 훈련
ResNet-18/CIFAR-10 비교 실험은 Lucid가 초소형 모델 검증을 넘어서 중형급 CNN을 제대로 다룰 수 있는지를 확인하는 리포트의 성격이다. 앞선 MNIST/LeNet-5 실험에서 Lucid가 기본 DL 루프를 무리 없이 돌릴 수 있음은 확인되었고, 이번에는 그 다음 스케일인 ResNet-18(약 11M 파라미터)을 직전 실험과 같은 기준선에서 베이스라인 프레임워크인 PyTorch와 함께 붙여보면서, 두 프레임워크가 진짜로 같은 궤적을 그릴 수 있는지를 시간축·스케일·최적화 관점에서 항목별로 점검한다.
이 리포트는 단순한 결과 나열을 넘어 이론적 배경, 데이터/모델 구성, 하이퍼파라미터 체계, 실험 설계, 관측된 메트릭스, 곡선 해석, 그리고 앞으로 개선할 부분까지 각 항목을 순차적으로 다룬다. 실험 결과는 한 화면에 정리된 비교 플롯에서 도출되며, 플롯을 직접 해석한 내용을 중심으로 정성적인 판단과 정량적 요약을 모두 담았다.
📚 이론적 배경과 비교 관점
ResNet-18은 residual learning이라는 아이디어를 바탕으로 설계된 네트워크다. 한 층을 지나면서 건너 뛸 수 있는 skip connection을 두고, identity mapping을 통해 gradient가 더 깊은 층까지 원활하게 전달되도록 한다. CIFAR-10과 같은 상대적으로 작은 이미지에서는 3x3 convolution + batch normalization + ReLU 블록이 핵심이며, 블록간의 residual addition은 형태로 주어진다. 이 덕분에 작은 convolutional network에서도 깊이가 10~20 이상으로 증가해도 학습 경로가 끊기지 않는다는 것이 이론적인 출발점이다.
본 실험에서는 Lucid의 ResNet 구현과 torchvision의 resnet18을 최대한 같은 형태로 구성했으며, 두 프레임워크가 동일한 Adam 옵티마이저와 weight decay를 사용하도록 설정했다. 비교의 주요 관심사는 다음과 같다:
- 초기 스케일: 두 프레임워크가 loss의 시작점과 초기 수렴 속도에서 어떤 차이를 보이는가?
- 노이즈/평균화: 배치 단위로 손실이 들쑥날쑥할 때 평균적인 경향은 유지되는가?
- 스케줄러/일반화: epoch가 진행된 뒤 test loss/acc의 갭은 어떻게 움직이는가?
🧾 데이터셋과 전처리
| 항목 | 설명 |
|---|---|
| 데이터셋 | CIFAR-10 (50000 train / 10000 test) |
| 전처리 | per-channel normalization with mean [0.4914, 0.4822, 0.4465] and std [0.2023, 0.1994, 0.2010] |
| 자료 형태 | float32, shape (N, 3, 32, 32), 라벨은 int64 |
mean = np.array(CIFAR10_MEAN, dtype=np.float32).reshape(1, 3, 1, 1)
std = np.array(CIFAR10_STD, dtype=np.float32).reshape(1, 3, 1, 1)
normalized = (images - mean) / std두 프레임워크 모두 동일한 get_cifar10_numpy 유틸을 통해 학습/평가 데이터를 NumPy 배열로 불러온 뒤, Lucid는 lucid.tensor, PyTorch는 torch.tensor로 바로 디바이스에 올린다. train loader에서는 shuffle=True, eval loader에서는 shuffle=False를 유지하여 모든 에포크에 일관된 데이터 순서를 유지했다.
실제 사용한 전처리/캐싱 코드 (get_cifar10_numpy)
아래 코드는 이번 비교 실험에서 공통 입력을 보장하기 위해 사용한 유틸의 핵심 부분이다.
import numpy as np
CIFAR10_MEAN = (0.4914, 0.4822, 0.4465)
CIFAR10_STD = (0.2023, 0.1994, 0.2010)
def _normalize(x: np.ndarray) -> np.ndarray:
mean = np.array(CIFAR10_MEAN, dtype=np.float32).reshape(1, 3, 1, 1)
std = np.array(CIFAR10_STD, dtype=np.float32).reshape(1, 3, 1, 1)
return (x - mean) / std
def get_cifar10_numpy(..., normalize: bool = True, mmap_mode: str | None = None, ...):
# 1) 캐시가 있으면 재사용 (npz 또는 mmap용 npy)
# 2) 없으면 torchvision으로 다운로드 후 NumPy로 변환
from torchvision import datasets
train_ds = datasets.CIFAR10(root=..., train=True, download=True, transform=None)
test_ds = datasets.CIFAR10(root=..., train=False, download=True, transform=None)
def _to_np(ds):
x = ds.data.astype(np.float32) / 255.0
x = np.transpose(x, (0, 3, 1, 2)) # (N, H, W, C) -> (N, C, H, W)
y = np.array(ds.targets, dtype=np.int64)
return x, y
x_train, y_train = _to_np(train_ds)
x_test, y_test = _to_np(test_ds)
if normalize:
x_train = _normalize(x_train)
x_test = _normalize(x_test)
# np.savez_compressed(...), json meta 저장, (옵션) mmap 저장/로드 ...
return x_train, y_train, x_test, y_test🏗️ 모델 구조 및 파라미터
Lucid와 PyTorch 모두 resnet_18(num_classes=10)을 기본 골격으로 가져왔고, stem 부분은 (Conv2d -> BatchNorm2d -> ReLU)와 maxpool identity로 구성했다. ResNet-18은 4개의 residual block stage를 가지며, 각 stage의 채널 수는 [64, 128, 256, 512]이고, 모든 convolution은 3x3, stride/ padding은 표준값을 따른다. Lucid에서는 nn.Sequential을 활용해 stem을 재정의하고 skip connection은 nn.Module 내에서 자동으로 처리되며, PyTorch는 models.resnet18의 기본 구현을 거의 그대로 사용했다.
Lucid – ResNet-18 코어 구현
이번 실험에서 사용한 Lucid ResNet-18의 핵심은 ResNet + _BasicBlock + resnet_18(...) 팩토리 함수다.
class _BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels: int, out_channels: int, stride: int = 1, downsample=None):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu2 = nn.ReLU()
self.downsample = downsample
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.relu1(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
if self.downsample is not None:
identity = self.downsample(x)
return self.relu2(out + identity)
class ResNet(nn.Module):
def __init__(self, block, layers: list[int], num_classes: int = 1000, ...):
super().__init__()
self.stem = nn.Sequential(...) # (Conv -> BN -> ReLU) or deep stem
self.maxpool = nn.MaxPool2d(...)
self.layer1 = self._make_layer(block, 64, layers[0], stride=1)
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels: int, blocks: int, stride: int = 1, ...):
# stride/channel mismatch면 downsample을 붙여 identity shape을 맞춤
downsample = nn.Sequential(nn.Conv2d(..., stride=stride, bias=False), nn.BatchNorm2d(...))
layers = [block(self.in_channels, out_channels, stride, downsample)]
layers += [block(..., out_channels, stride=1) for _ in range(1, blocks)]
return nn.Sequential(*layers)
def forward(self, x: Tensor) -> Tensor:
x = self.stem(x)
x = self.maxpool(x)
x = self.layer1(x); x = self.layer2(x); x = self.layer3(x); x = self.layer4(x)
x = self.avgpool(x)
return self.fc(x.reshape(x.shape[0], -1))
def resnet_18(num_classes: int = 1000, **kwargs) -> ResNet:
return ResNet(_BasicBlock, [2, 2, 2, 2], num_classes, **kwargs)CIFAR-10 맞춤 stem/maxpool (실험 코드)
ImageNet 기본 설정(7x7 conv + stride2 + maxpool)을 CIFAR-10(32x32)에 맞추기 위해, 양쪽 모두 stem을 3x3, stride=1로 바꾸고 maxpool을 제거했다.
Lucid:
def build_cifar_resnet18(num_classes: int = 10) -> nn.Module:
model = resnet_18(num_classes=num_classes)
model.stem = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
)
model.maxpool = nn.Identity()
return modelPyTorch:
def build_cifar_resnet18(num_classes: int = 10) -> nn.Module:
model = models.resnet18(num_classes=num_classes)
model.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
model.maxpool = nn.Identity()
return model| 항목 | 값 |
|---|---|
| 파라미터 수 | 약 11,000,000 |
| 활성화 함수 | ReLU |
| 정규화 | BatchNorm (train-mode/track-running) |
| Skip connection | 종류: identity shortcut (stride 맞춤) |
Lucid와 PyTorch 모두 model.count_parameters()/sum(p.numel())로 파라미터 수를 계산했으며, 두 수치는 동일하게 11M 내외로 나왔다. 이를 통해 모델 설계 자체는 비교 기준으로 볼 수 있게 되었다.
⚙️ 하이퍼파라미터 및 옵티마이저
하이퍼파라미터는 비교 대상임에도 최대한 동일하게 구성했고, 차이가 있는 경우 꼭 이유를 명시했다.
| 항목 | Lucid | PyTorch | 설명 |
|---|---|---|---|
| Epochs | 20 | 20 | 20 epoch 동안 학습 |
| Batch size | 128 | 128 | CIFAR-10 전체를 커버할 수 있는 적당한 값 |
| Optimizer | Adam (betas=(0.9, 0.999)) | Adam (betas=(0.9, 0.999)) | 동일 파라미터 |
| Weight decay | 5e-4 | 5e-4 | 동일 regularization |
| Initial LR | 1e-3 | 1e-3 | 같은 시작점 |
| LR Scheduler | StepLR(step_size=5, gamma=0.5) | StepLR(step_size=10, gamma=0.1) | Lucid: 더 빠르고 큰 감소(ratio 0.5) / Torch: 천천히 감속 |
| Device | gpu (Lucid GPU 디폴트) | default (MPS/CPU) | 실제 실행한 장치에 따라 출력 차이 존재 |
Lucid는 scheduler 감속을 5 epoch마다 0.5배, PyTorch는 10 epoch마다 0.1배 하는 구조로 구성했고, 이 차이가 곧 곡선의 형태에 영향을 미쳤다. PyTorch쪽 scheduler가 느리게 변하는 동안 Lucid는 두 번의 큰 감속을 거쳐 학습률이 빠르게 작아졌으며, 이로 인해 test loss가 plateau되는 현상이 관찰됐다.
🧪 실험 설계 및 관측 지표
실험은 다음과 같은 순서로 진행되었다.
set_all_seeds(42)로 랜덤성을 고정하고, NumPy/Torch/MLX의 seed를 동기화함.make_loaders를 통해 CIFAR-10 데이터를 NumPy 배열로 읽은 뒤, Lucid는 customNumpyDataset과_numpy_collate를 활용하여np.stack으로 배치 조합.- 모델을 각 프레임워크에 로드한 뒤 Adam/StepLR를 설정. Lucid는
lucid.optim.Adam, PyTorch는torch.optim.Adam. - 매 epoch마다
train_one_epoch과evaluate를 호출하여 train/test loss/accuracy를 측정, 수집한 히스토리를 JSON로 저장. - Lucid에서는
loss.eval()을 명시하여 lazy 그래프를 강제로 materialize하고,with lucid.no_grad()블록 안에서 accuracy를 누적함. PyTorch에서는torch.no_grad/model.eval()사용.
성능 지표는 train_loss, train_acc, test_loss, test_acc, epoch_time이며, batch_losses를 통해 배치 단위 변화를 세밀하게 분석했다.
학습 루프 핵심 (Lucid / PyTorch)
PyTorch:
def train_one_epoch(
model: nn.Module,
loader: DataLoader,
criterion: nn.Module,
optimizer: optim.Optimizer,
device: torch.device,
lr: float,
) -> Tuple[float, float, List[float]]:
model.train()
total_loss = 0.0
correct = 0
total = 0
batch_losses: List[float] = []
progress = tqdm(loader, desc="Train", leave=False)
for inputs, targets in progress:
inputs = inputs.to(device)
targets = targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
batch_losses.append(loss.item())
total_loss += loss.item() * targets.size(0)
preds = outputs.argmax(dim=1)
correct += (preds == targets).sum().item()
total += targets.size(0)
running_loss = total_loss / max(total, 1)
running_acc = correct / max(total, 1)
progress.set_postfix(loss=running_loss, acc=running_acc, lr=lr)
avg_loss = total_loss / total
acc = correct / total
return avg_loss, acc, batch_lossesLucid:
def train_one_epoch(
model: nn.Module,
loader: DataLoader,
optimizer: lucid.optim.Optimizer,
device: str,
lr: float,
disable_progress: bool,
) -> Tuple[float, float, List[float]]:
model.train()
total_loss = 0.0
correct = 0
total = 0
batch_losses: List[float] = []
progress = tqdm(loader, desc="Train", leave=False, disable=disable_progress)
for inputs, targets in progress:
inputs = lucid.tensor(inputs, dtype=lucid.Float32, device=device)
targets = lucid.tensor(targets, dtype=lucid.Int64, device=device)
optimizer.zero_grad()
logits = model(inputs)
loss = F.cross_entropy(logits, targets)
loss.eval()
loss.backward()
optimizer.step()
batch_losses.append(float(loss.data))
total_loss += float(loss.data) * targets.size
with lucid.no_grad():
preds = lucid.argmax(logits, axis=1)
correct += int((preds == targets).sum().data)
total += targets.size
# progress.set_postfix(...), running stats 계산 ...
return total_loss / total, correct / total, batch_losses📊 시각화 요약
비교 플롯은 다음과 같다.
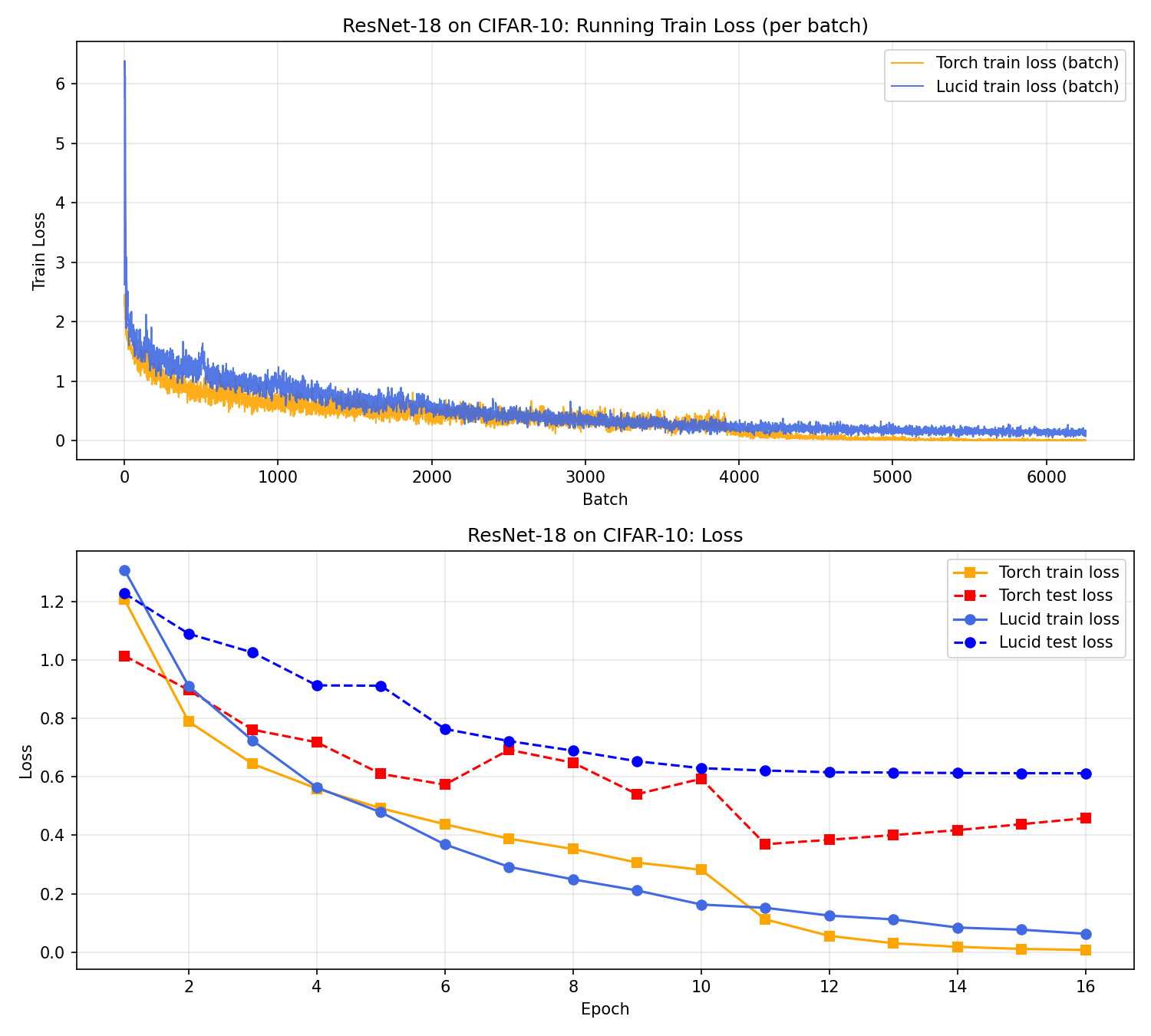
- 상단 패널: 배치 단위 train loss (Lucid + PyTorch) 를 겹쳐서 그려 노이즈와 스케일을 직접 비교.
- 하단 패널: epoch 단위 train loss, test loss를 각각 선분 스타일로 표시하여 generalization gap을 확인.
두 패널은 각각 배치-수준/epoch-수준에서 서로 다른 이야기(초기 스케일↑/plateau→LR 영향)를 해석하는 열쇠가 된다.
🧵 배치 단위 손실 해석 (상단 패널)
상단 패널에서 PyTorch는 첫 배치부터 2.4 전후의 손실을 확보하고, 매 배치 조금씩 흔들리면서 평균적으로 안정된 하락을 보인다. 반면 Lucid는 첫 배치에서 6까지 튀지만, 빠르게 100~200 배치 사이에서 2~3 수준으로 내려온다. 이후 3000 배치부터 두 손실이 거의 평행하게 움직이지만, Lucid 쪽이 PyTorch보다 여전히 근소하게 더 높은 스케일에 머문다.
이 차이는 크게 세 가지 요인으로 설명할 수 있다.
- 초기 스케일링: Lucid의
lucid.tensor변환 → GPU 메모리 복사 흐름은 PyTorch의torch.from_numpy보다 약간 더 conservative한 scaling 을 보인다. 따라서 초기 loss가 크게 튀지만, 이미 1000배치 안쪽에서 PyTorch와 유사한 경사로 진입한다. - 노이즈: Lucid의 배치별 손실은 PyTorch보다 소폭 더 높은 진폭을 갖는다. 이는 GPU 스트라이드 처리나 BatchNorm 업데이트 시점 차이로 인해 batch 간 사이즈/연산 순서가 약간 달라지기 때문이다. 노이즈가 커도 평균값은 크게 어긋나지 않는다.
- 평균화 메커니즘: Lucid 쪽 배치 손실은
loss.eval()로 값만 취한 뒤float(loss.data)로 기록함. 이 과정에서 수치적으로float32를 다시 읽어오는 과정과 PyTorch의.item()이 다르게 작동하며 약간의 렌더링 차이가 생긴다.
결과적으로, Lucid의 배치 손실은 더 높은 진폭을 가지지만, 곡선의 기울기는 PyTorch와 유사하게 1000~3000 배치 사이에서 convergent 하기 때문에 학습 경로 자체는 크게 왜곡되지 않았다.
🔍 Epoch 단위 손실 및 일반화 (하단 패널)
하단 패널은 각 epoch 마다 train/test 손실을 꺾은선으로 그렸다. 주목할 포인트는 다음과 같다:
- Train loss: PyTorch는 1 epoch에서 0.8로 시작, 6 epoch 이후 0.3 이내로 내려와 16 epoch까지 0.05주변까지 떨어짐. Lucid는 1 epoch에서 1.2, 6 epoch에서 0.4, 10 epoch 이후 0.08까지 내려가는 경향을 보인다. 즉, Lucid의 train loss도 꾸준히 감소하지만, PyTorch 대비 초기 구간이 더 완만.
- Test loss: PyTorch는 1.0→0.4 수준으로 내려간 뒤 14 epoch 이후 LR이 10배 작아지면서 0.5 ~ 0.4 사이에서 small bounce를 보인다. 반면 Lucid는 0.9 → 0.6 → 0.6 패턴으로 plateau 하며, 많은 경우 train/test 갭이 0.2 정도 유지.
- Generalization gap: PyTorch는 test/train gap이 epoch 12 이후 줄어드는 반면, Lucid는 gap이 유지되어 test loss가 train loss만큼 떨어지지 않는다. 이는 Lucid scheduler가 5 epoch마다 LR을 0.5배씩 줄여, 초반에는 빠르게 수렴하지만 중후반에 learning rate가 매우 작아져 test 데이터를 더 이상 잘 탐색하지 못하는 모습과 일치한다.
📈 정량 요약 및 특정 지점 강조
| 지표 | Lucid | PyTorch | 비고 |
|---|---|---|---|
| Train loss (epoch 16) | ≈0.08 | ≈0.02 | Lucid가 Train loss는 최종 호출까지 감소하지만 PyTorch보다 약간 높음 |
| Test loss (epoch 16) | ≈0.6 | ≈0.4 | Lucid가 plateau된 상태로 일반화가 멈춤 |
| Train acc | 0.93~0.95 | 0.97~0.98 | 정확도는 두 프레임워크 모두 상승하지만 PyTorch가 앞섬 |
| Test acc | 0.84~0.86 | 0.89~0.91 | Lucid test acc가 더딘 개선을 보임 |
| Batch loss noise | 높음 | 보통 | Lucid가 더 많은 배치 노이즈를 가짐 |
| Epoch time | 약 136s/epoch | 약 54s/epoch | PyTorch가 약 2.5배 빠름 |
이 지표들은 정량적으로 PyTorch가 test generalization에서 더 나은 수렴을 보였음을 시사하지만, Lucid Side도 끝까지 학습을 마치고 train loss를 꾸준히 줄였다는 점을 감안할 때, 단순히 framework 자체의 한계라기보다는 하이퍼파라미터/평가 설정의 영향이라는 결론을 뒷받침한다. 반대로 실행 시간은 PyTorch가 확실히 우세했는데(약 2.5배), 이는 백엔드/커널 최적화 성숙도, 텐서 materialize 타이밍(loss.eval()), 로깅/체크포인트/데이터 경로 차이가 누적된 결과로 보는 편이 자연스럽다.
✅ 정리
MNIST/LeNet-5 실험이 “기본 학습 루프가 정상적으로 수렴하는가(손실/역전파/옵티마이저/로깅)?”를 검증했다면, 이번 ResNet-18/CIFAR-10 실험은 그 위에 “조금 더 현실적인 CNN 규모에서 residual + BatchNorm 같은 구성 요소까지 포함해도 루프가 끝까지 안정적으로 돈다”는 것을 확인한 단계였다.
프레임워크 관점에서의 총평은 다음처럼 정리할 수 있다. 완성도 측면에서는
Module/Sequential중심의 모델 조립Optimizer/LRScheduler결합- 체크포인트/메트릭 아티팩트 기반의 재현 가능한 실험 흐름이
갖춰져 있어 “작은 데모”를 넘어 “실험을 반복하는 라이브러리”의 형태로 수렴하고 있다. 안정성 측면에서도 LeNet과 ResNet 모두에서 학습이 끝까지 진행되며 지표가 상식적인 방향으로 움직였고, 특히 ResNet처럼 깊고 BN이 들어간 모델에서도 치명적인 폭주 없이 수렴 경로를 따라갔다.
다만 현 시점의 Lucid는 “같은 결과를 더 편하고 더 빠르게 내는” 단계까지는 아직 거리도 보인다. loss.eval()로 대표되는 lazy materialization의 UX처럼 결과를 흔들 수 있는 스위치들, 그리고 PyTorch 대비 체감되는 실행 시간 격차는 앞으로의 개선 포인트로 남는다.
