
🤗 소개
심층 생성 모델(Deep Generative Models; DGM) 은 이미지, 텍스트, 오디오와 같은 고차원 데이터 를 학습하여, 원본 데이터와 유사한 새로운 샘플을 만들어내는 신경망이다. 모델이 학습하는 분포 를 , 실제 데이터의 분포 를 라 하며, 주어진 유한한 데이터셋으로부터 를 에 최대한 가깝게 만드는 것 이 학습의 목표이다.
학습이 완료되면, 모델의 샘플링 절차를 통해 를 생성할 수 있고, 의 값이 직접 계산 가능한지(tractable) 는 모델 유형에 따라 다르다.
모델의 성능은 생성된 샘플이 실제 데이터의 통계적 특성과 얼마나 잘 일치하는지, 그리고 특정 과제에서 얼마나 자연스러운지를 기준으로 평가된다.
✨ 심층 생성 모델이란
심층 생성 모델(DGM)은 현실 세계에서 얻은 대규모의 실제 데이터를 입력으로 받는다. 이 데이터들은 복잡하고 알 수 없는 분포 로부터 추출된 것이다. DGM은 이를 학습하여, 그 분포를 근사하는 확률 분포 를 매개변수화(parameterize)한 신경망 을 출력한다.
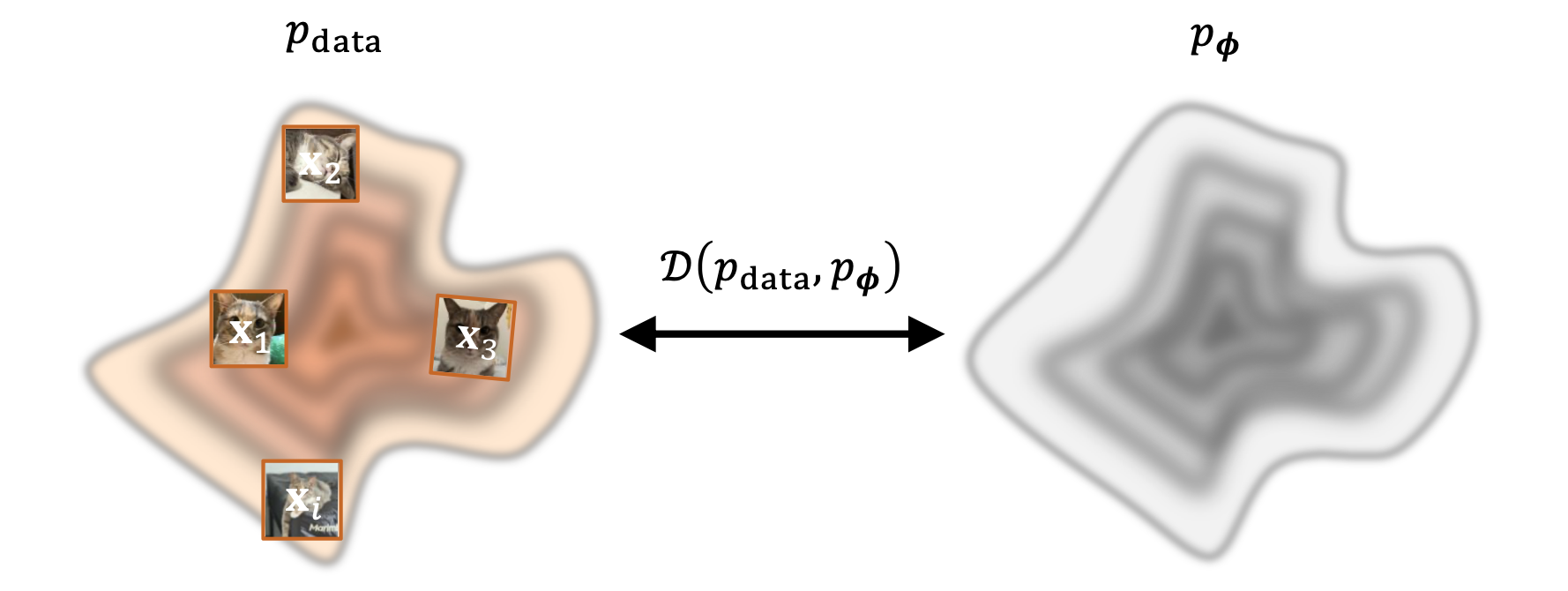
심층 생성 모델의 목표는 크게 두 가지이다:
1. 사실적인 생성 (Realistic Generation) : 실제 데이터와 구별되지 않을 만큼 자연스럽고 현실적인 새로운 샘플을 생성하는 것.
2. 조절 가능한 생성 (Controllable Generation) : 생성 과정에 대해 세밀하고 해석 가능한 제어를 가능하게 하는 것.
이 절에서는 DGM의 기본적인 개념과 그 개발 동기를 다루며, 이후 이어질 수학적 구조와 실질적인 응용에 대한 심화적인 탐구를 위한 기반을 마련할 예정이다.
1️⃣ 수학적 설정
일반적으로는 현실 세계의 복잡한 데이터 분포 로부터 독립적이고 동일한 분포 ()를 따르는 유한 개의 샘플 집합을 가지고 있다고 가정한다.
🎯 DGM의 목표
DGM의 주된 목표는 유한한 데이터셋으로부터 계산 가능한 확률 분포(tractable probability distribution)을 학습 하는 것이다. 이 데이터들은 모두 알 수 없는 복잡한 실제 분포 에서 추출된 관측값이다. 하지만 의 형태를 명시적으로 알 수 없기 때문에, 이로부터 직접 새로운 샘플을 뽑는 것은 불가능 하다.
따라서 핵심 과제는 실제 데이터 분포 를 충분히 잘 근사 하여, 현실적인 새로운 샘플을 생성할 수 있는 모델을 만드는 것이다. 를 위해 DGM은 심층 신경망(Deep Neural Network; DNN) 이용해 모델 분포 를 parameterize한다. 여기서 는 신경망의 학습 가능한(learnable) 파라미터들을 의미한다.
훈련의 목적은 와 간의 분포 간 거리(divergence) 를 최소화 하는 최적의 파라미터 를 찾는 것이다. 개념적으로 이는 다음과 같은 관계로 표현된다.
최적화된 통계적 모델 이 실제 데이터 분포 를 충분히 근사하게 되면, 그 모델은 새로운 샘플을 생성하거나 확률값을 평가하는 게 사용할 수 있다. 이러한 를 일반적으로 생성 모델(Generative Model) 이라 부른다.
🔨 DGM의 능력과 그 학습
데이터 분포의 근사치인 가 준비되면, 몬테카를로 샘플링(Monte Carlo sampling) 등의 방법을 사용하여 로부터 임의 개수의 새로운 데이터를 생성할 수 있다. 또한, 주어진 특정 데이터 샘플 에 대해 그 데이터가 모델에 의해 생성될 확률(또는 가능도; likelihood) 을 를 계산함으로써 평가할 수도 있다.
DGM은 모델 집합 의 파라미터 는 실제 데이터 분포 와 모델 분포 간의 차이(discrepancy) 를 최소화 하도록 학습된다.
그러나 실제 데이터 분포 는 명시적으로 알려져 있지 않기 때문에, 실제로는 샘플만으로 효율적으로 추정 가능한 형태의 를 선택해야 한다.
모델이 충분한 표현 능력(capacity) 을 가지고 있다면, 학습된 모델 분포 는 실제 분포 를 매우 근접하게 근사할 수 있다.
🎭 Forward KL과 최대우도추정법(Maximum Likelihood Estimation; MLE)
Discrepancy 기준 로 가장 표준적으로 쓰이는 것은 바로 (forward) Kullback-Leibler 발산(KL-Divergence) 이다.
참고로, KL 발산은 교환법칙이 성립하지 않는다. 즉 다음 부등식이 성립한다.
중요한 점은 을 최소화 하는것은 모드 커버링(mode covering) 을 유도한다는 것이다. 다른 말로 하자면, 만약 어떤 집합 에 대해 인데 즉, 모델이 그 구역에 확률 질량(probability mass)를 전혀 할당하지 않는 경우라면, 적분항에 포함된 로그 항은 가 되어 가 된다.
따라서 전방향 KL 발산을 최소화하는 학습 과정은 데이터가 존재하는 모든 영역, 즉 인 부분에 모델 분포 가 반드시 확률 질량을 할당하도록 강제 한다.
비록 실제 데이터의 확률밀도 함수 는 명시적으로 계산될 수 없지만, KL 발산은 다음과 같이 분해할 수 있다.
여기서 는 데이터 분포의 엔트로피(entropy) 이며, 이는 와 무관한 상수이다. 이로부터 다음과 같은 동등 관계(equivalence) 가 성립한다.
보조정리 1.1.1 – KL의 최소화 MLE
즉, 전방향 KL 발산 최소화는 데이터의 로그 가능도(log-likelihood) 최대화와 동치 이다.
실제로는 전체 분포에 대한 기댓값을 직접 계산할 수 없으므로, 데이터 분포 로부터 샘플링된 표본 를 사용하여 Monte Carlo 방식으로 근사한다.
이를 통해 얻어지는 경험적 최대우도추정(empirical MLE) 의 목적 함수는 다음과 같다.
이 목적 함수는 미니배치(mini-batch) 단위로 확률적 경사 하강법(stochastic gradient descent, SGD) 등을 통해 최적화된다. 이 과정에서는 의 값을 명시적으로 계산할 필요가 없다 는 점이 중요하다.
📐 Fisher 발산
또 다른 중요한 개념으로 Fisher 발산(Fisher Divergence) 이 있다. 이는 특히 점수 기반(score-based) diffusion 모델에서 핵심적으로 사용된다. 이에 대한 내용은 이후의 글에서 자세히 다루겠다.
두 확률분포 와 에 대해 Fisher 발산은 다음과 같이 정의된다.
이 식은 두 분포의 점수 함수(score function), 즉 와 사이의 차이를 측정한다. Score function은 각 위치 에서 확률이 높은 방향으로 향하는 벡터장(vector field) 를 의미한다. 간단히 말해, 이 되는 경우는 거의 모든 곳 에서 일 때뿐이다.
Fisher 발산은 normalization constant에 대해 불변 이다. 이는 score function이 log-density의 gradient에만 의존 하기 때문이다. 이 성질 덕분에 Fisher 발산은 이후에 더 자세히 다룰 Score matching 의 기초가 된다.
간략하게 설명하자면, score matching은 log-density의 gradient를 직접 학습하여 데이터를 생성하는 방법, 즉 점수 기반 생성 모델(score-based generative model) 을 구축하는 접근법이다. 이때 데이터 분포 가 목표(target) 가 되고, 모델 분포 는 자신의 score field이 데이터의 그것과 일치하도록 학습된다.
🚀 KL을 넘어서
비록 KL 발산이 확률 분포 간 차이를 측정하는 가장 널리 사용되는 척도이지만 그것이 유일한 방법은 아니다. 서로 다른 발산(divergence)은 확률 분포 간의 불일치를 서로 다른 기하학적 혹은 통계학적 관점 에서 포착하며, 이는 곧 학습 알고리즘의 최적화 과정(optimization dynamics) 에도 영향을 미친다.
이러한 다양한 발산 척도들을 포괄하는 넓은 범주의 개념이 바로 f-발산(f-divergence) 이다.
여기서 는 볼록 함수(convex function)이다. 를 바꿔가면서 잘 알려진 다양한 발산들을 얻을 수 있다.
| Divergence | Notation | -function |
|---|---|---|
| forward KL | ||
| Jensen-Shannon | ||
| total variation |
명시적인 형태를 소개하자면 다음과 같다.
직관적으로, JS 발산(Jensen-Shannon divergence) 은 두 분포를 균형 있게 고려하면서, KL 발산의 무한대 penalty 문제 를 피하는 부드럽고 symmetric한 discrepancy 측정 방법이다. 이 특성 덕분에 JS 발산은 GAN(Generative Adversarial Network) 의 학습 과정을 해석하는 데 핵심적인 역할을 하며, 두 분포가 얼마나 잘 겹치는지를 안정적으로 평가할 수 있게 해준다.
반면, 총변동 거리(total variation distance) 는 두 확률 분포 간의 가장 큰 확률 차이(maximum probability difference) 를 측정하는 척도로, 두 분포가 겹치지 않는 영역에서의 차이를 직접적으로 포착한다.
각 divergence는 확률 분포 간 가까움(closeness) 의 개념을 서로 다르게 정의하며, 이에 따라 학습 과정에서의 learning behavior 또한 달라진다. 이 Diffusion 101 시리즈에 걸쳐, 생성 모델링(generative modeling)의 다양한 맥락 속에서 이러한 발산들이 자연스럽게 등장하는 지점마다 다시 다뤄볼 예정이다.
2️⃣ 확률 분포 모델링의 어려움
복잡한 데이터 분포를 모델링하기 위해 신경망(neural network) 에 매개변수 를 부여하여 확률밀도함수 를 근사하도록 parameterize할 수 있다. 이렇게 정의된 모델을 라고 한다.
모델 가 유효한 확률밀도함수(valid PDF) 가 되기 위해서는 다음의 두 가지 기본 조건 을 만족해야 한다.
1. 비음수성(Non-Negativity): , 모든 입력 에 대해 확률밀도는 음수가 될 수 없다.
2. 정규화(Normalization): , 전체 정의역(domain)에 걸쳐 확률밀도의 적분값은 반드시 이 되어야 한다.
신경망은 입력 에 대해 자연스럽게 실수 스칼라 값 를 출력할 수 있다. 하지만 이 출력을 valid PDF 로 해석하기 위해서는 앞서 제시한 두 가지 조건(non-negativity & normalization)을 만족하도록 변환해야 한다.
실용적인 대안으로는, 를 비정규화된 확률밀도(unnormalized density) 로 간주하고, 이후 필요한 정규화 조건을 명시적으로 부여하는 방식을 취할 수 있다.
-
비음수성 확보하기
모델이 항상 non-negative가 되도록 보장하기 위해서는 신경망의 원시 출력값 의 양의 함수를 적용 하면 된다. 가장 일반적이고 편리한 선택은 지수 함수(exponential function) 을 사용하는 것이다.이를 통해 항상 양수인 unnormalized density 를 얻을 수 있다.
이때 이 항상 성립하므로, 확률밀도로 사용하기 위한 비음수 조건을 자동 으로 만족한다.
-
정규화 강제하기
함수 는 항상 양수이지만 그 자체로는 전체 space에 대해 적분했을 때 이 되지 않는다. 즉, 아직 normalization이 이루어지지 않은 상태이다. 따라서 이를 valid PDF로 만들기 위해서는 전체 space에 대한 적분값으로 나누어 정규화해야 한다.이로부터 모델의 최종 형태는 다음과 같이 도출된다.
여기서 는 정규화 상수(normalizing constant) 혹은 분배 함수(partition function) 이라 불리며, 모델이 전체 확률 질량을 로 맞추는 역할을 한다.
이 절차를 통해 를 valid PDF로 구성할 수 있지만 여기에는 중대한 계산적 어려움 이 따른다. 고차원 데이터의 경우, 를 계산하기 위해 필요한 적분 은 대부분의 상황에서 intractable 하다.
이러한 정규화 불가능성(intractable normalization) 문제는 DGM의 여러 다른 계열, 예를 들어 VAE, GAN, Flow 기반 모델, Diffusion 모델 등이 개발되게 된 핵심적인 동기로 작용한다.
🎩 주요 심층 생성 모델
생성 모델링(generative modeling) 에서의 핵심 과제는 고차원 데이터의 풍부하고 복잡한 구조 를 포착할 수 있는 표현력 있는 확률 모델 을 학습하는 것이다. 이 목표를 달성하기 위해 지난 수년간 다양한 접근법이 제안되어 왔다. 각 접근법은 계산 가능성(tractability), 표현력(expressiveness), 그리고 학습 효율성(training efficiency) 사이에서 서로 다른 trade-off를 취한다.
이 절에서는 생성 모델 연구의 방향을 결정지어 온 가장 영향력 있는 모델링 전략 들을 살펴보고 그들의 계산 그래프(computational graph) 구조를 비교하고자 한다.
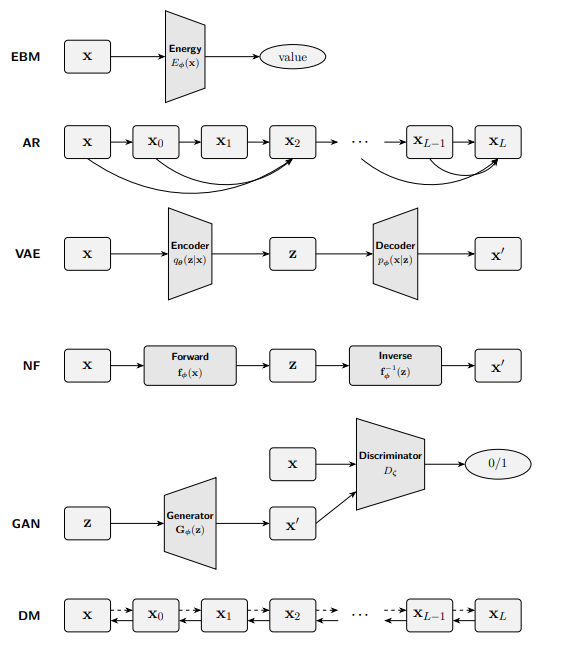
1️⃣ 에너지 기반 모델 (EBM)
에너지 기반 모델(Energy-Based Models; EBM) 은 입력 데이터 에 대해 에너지 함수(energy function) 를 정의함으로써 확률 분포를 모델링한다. 이 함수는 더 가능성이 높은 데이터일수록 낮은 에너지 값을 할당한다.
확률 분포는 다음과 같이 정의된다.
여기서 는 partition function이다.
EBM의 학습은 일반적으로 데이터의 로그 가능도(log-likelihood)를 최대화 하는 방식으로 진행된다. 하지만 이는 의 intractability 문제로 인해 계산적으로 매우 어렵다. 따라서 실제 학습에서는 이를 근사하거나 우회하기 위한 다양한 기법이 필요하다.
이후 글에서는 diffusion 모델 이 이러한 문제를 어떻게 해결하는지 살펴볼 예정이다. Diffusion 모델은 로그 밀도의 gradient, 즉 앞서 언급한 score function 을 이용해 데이터를 생성하기 때문에 정규화 상수 에 의존하지 않으며, 결과적으로 partition function 계산을 완전히 회피 한다.
2️⃣ 자기회귀 모델 (AR)
심층 자기회귀 모델(Deep Autoregressive Models; AR) 은 확률의 연쇄 법칙(chain rule of probability) 을 이용해 데이터의 결합 분포(joint distribution) 를 조건부 확률들의 곱으로 factorize한다.
여기서 이고, 이다. 각 조건부 확률 는 신경망(예를 들어 트랜스포머; Transformer)에 의해 매개변수화되며, 이를 통해 복잡한 종속 관계 를 유연하게 모델링할 수 있다. 또한 각 조건부 항은 구조적으로 이미 normalized 되어 있다. 예를 들어,
- 이산(discrete) 변수의 경우 softmax 함수를 사용하고,
- 연속(continuous) 변수의 경우 parameterized Gaussian을 사용한다.
따라서 AR 모델은 global normalization이 자동으로 보장 되어 따로 정규화 상수 계산을 할 필요가 없다.
AR의 학습은 명시적 가능도(exact likelihood)를 최대화 하거나, 동등하게 음의 로그 가능도(NLL)을 최소화 하는 방식으로 진행된다. 이러한 모델은 정확한 확률 계산이 가능한 밀도 추정(density estimation) 을 수행할 수 있으며, 이 점에서 매우 강력한 성능을 보인다.
그러나 AR 모델은 순차적(sequential) 구조 를 갖기 때문에 샘플을 하나씩 순서대로 생성해야 한다는 제약으로 인해 샘플링 속도가 느리고, 또한 고정된 순서때문에 표현의 유연성이 제한될 수 있다.
그럼에도 불구하고 AR 모델은 가능도 기반 생성 모델의 근본적인 형태로서, 현대 생성 모델 연구의 핵심적인 접근법 중 하나로 자리하고 있다.
3️⃣ 변분 오토인코더 (VAE)
변분 오토인코더(Variational Autoencoders; VAE) 는 기존의 autoencoder를 확장하여 데이터 속에 존재하는 숨겨진 구조를 표현하는 잠재 변수(latent variable) 를 도입한 확률적 생성 모델(stochastic generative model) 이다.
VAE는 와 사이의 직접적인 mapping을 학습하는 대신, 이를 확률적 관점에서 접근한다. 즉, 두 개의 확률 분포를 동시에 학습한다.
-
인코더(Encoder) : 주어진 데이터 로부터 잠재 변수 의 분포를 근사(approximate) 한다.
-
디코더(Decoder) : 잠재 변수 로부터 데이터를 복원(reconstruct) 한다.
그러나 실제 로그 가능도 는 intractable하기 때문에 VAE는 이를 대신할 수 있는, 근사 가능하고 tractable한 대체 목표함수인 증거 하한(Evidence Lower Bound; ELBO) 를 최대화한다.
여기서 ELBO의 첫 번째 항은 데이터의 정확한 복원(reconstruction) 을 유도하며, 두 번째 항은 잠재 변수(latent variable)가 단순한 사전 분포(prior distribution) (보통 )와 가깝도록 normalize 하는 역할을 한다.
VAE는 신경망과 잠재 변수 모델을 이론적으로 일관성 있게 결합 하는 방법을 제시했으며, 현재까지도 가능도 기반(likelihood-based) 생성 모델 중 가장 널리 사용되는 접근법 중 하나이다.
하지만 VAE는 몇 가지 실질적인 한계도 지닌다. 예를 들어, 생성된 샘플의 선명도(sharpness)가 부족 하거나, 학습 중 encoder가 latent variable을 무시 하는 현상이 발생하기도 한다. 그럼에도 불구하고, VAE는 이후 등장한 diffusion 모델을 포함한 현대 생성 모델 발전의 핵심적인 토대 를 마련한 중요한 연구이다.
4️⃣ 노멀라이징 플로 모델 (NF)
고전적인 플로우 기반 모델(Flow-based models) 에는 대표적으로 노멀라이징 플로(Normalizing Flows; NF) 와 Neural ODE(NODE) 가 있는데, 이들은 단순한 잠재 분포 와 복잡한 데이터 분포 사이의 쌍방향 변환(bijective mapping) 를 학습하는 것을 목표로 한다.
이러한 변환은,
- NF 에서는 여러 개의 가역적 변환(invertible transformations) 을 순차적으로 결합함으로써,
- Neural ODE 에서는 상미분방정식(Ordinary Differential Equation; ODE) 의 형태로 데이터 변환 과정을 연속적으로 모델링함으로써 이루어진다.
이들 모델은 확률밀도의 변수변환 공식(change-of-variable formula for densities) 을 활용하여 MLE 기반의 학습 을 가능하게 한다.
여기서 는 잠재 변수 를 데이터 공간의 로 변환하는 가역 변환을 의미한다.
NF는 이러한 가역 변환을 이용해 normalized된 확률밀도를 명시적으로(explicitly) 모델링한다. 즉, 각 변환 단계는 Jacobian 행렬의 determinant를 계산할 수 있도록 설계되어 있어 density의 변화를 정확히 추적할 수 있다.
이 경우, normalizing constant는 변수변환 공식 을 통해 분석적으로(analytically) 흡수되므로, 최종적으로 가능도 계산이 tractable 하다. 따라서 flow 기반 모델은 정확한 가능도 계산과 효율적인 학습이 모두 가능한 likelihood-based generative model의 대표적인 형태로 평가된다.
이렇듯, 개념적으로는 매우 우아한 구조를 지녔지만, 고전적인 flow-based model은 실제 적용 시 여러 실용적 한계 에 직면한다. 예를 들어,
- NF 는 가역성(bijectivity) 을 보장하기 위해 네트워크 구조에 제약적인 설계 조건 을 부여해야 한다.
- Neural ODE 는 ODE를 수치적으로 푸는 과정에서 계산 비용이 커져 학습 비효율 이 발생할 수 있다.
이 두 접근법 모두 고차원 데이터 로 확장될 때 계산 복잡도와 메모리 사용량 측면에서 scaling의 어려움을 겪는다.
5️⃣ 적대적 생성 신경망 (GAN)
적대적 생성 신경망(Generative Adversarial Networks; GAN) 은 두 개의 신경망, 즉 생성기(Generator) 와 판별기(Discriminator) 로 구성되어 이 둘은 서로 적대적(adversarial)인 관계를 형성한다
생성기 는 무작위 노이즈 로부터 실제 데이터와 구분되지 않을 정도로 사실적인 샘플 를 생성하려 하고, 판별기 는 입력이 실제 데이터 인지 혹은 생성된 데이터 인지를 판별(distinguish)하려 한다.
GAN의 학습 목적함수는 다음과 같이 정의된다.
GAN은 명시적인 확률밀도함수를 정의하지 않기 때문에, 가능도 추정을 전혀 수행하지 않는다. 즉, normalization constant를 계산하거나 데이터의 확률값을 직접 평가하는 대신, 데이터 분포와 시각적으로 구분되지 않을 만큼 유사한 샘플을 생성 하는데 초점을 맞춘다.
따라서 GAN은 명시적 확률 모델(explicit probabilistic model)이 아닌, 샘플 기반(sample-based) 생성 접근법 의 대표적인 예시이다.
Divergence의 관점에서 보자면, GAN의 판별기는 실제 데이터 분포 와 생성기 로부터 생성된 분포 간의 discrepancy를 암묵적으로(implicitly) 측정 하는 역할을 한다.
여기서 는 노이즈 분포 를 생성기 에 통과시켜 얻은 생성 샘플의 분포(distribution of generated samples) 를 의미한다. 생성기 가 고정되어 있을 때, 최적의 판별기 는 다음과 같이 계산된다.
생성기의 최소화는 다음과 같이 정리된다.
이를 통해 GAN은 implicit하게 를 최소화한다는 것을 알 수 있다.
GAN은 매우 고품질의 데이터 를 생성할 수 있는 강력한 모델이지만, 그 핵심인 미니맥스(min-max) 최적화 과정 은 극도로 불안정 한 것으로 잘 알려져 있다. 이로 인해 GAN을 성공적으로 학습시키기 위해서는 세심하게 설계된 아키텍쳐와 다양한 엔지니어링 기법이 필요하다.
그럼에도 불구하고 최근에는 GAN이 단독 모델로 사용되기보다는 보조 구성 요소(auxilary component) 로서 다시 주목받고 있다. 특히 diffusion 모델과 결합되어 샘플의 선명도와 사실감을 높이는 데 중요한 역할을 한다.
✅ 요약
심층 생성 모델(Deep Generative Models; DGM) 의 목표는
실제 데이터 분포 를 근사하는 모델 분포 를 학습해
현실적인 샘플을 생성하는 것이다. 학습은 주로 KL 발산 최소화 로그 가능도 최대화(MLE)로 이뤄진다.
고차원 데이터의 정규화 상수 계산이 어려워 다양한 생성 모델이 등장했다:
- EBM — 에너지 함수로 확률 분포를 정의하지만, 정규화 상수 계산이 어려움.
- AR — 확률의 연쇄 법칙을 사용해 정확한 가능도 추정 가능, 그러나 순차적 구조로 느림.
- VAE — 인코더·디코더를 통해 잠재 공간을 학습하며 ELBO를 최적화, 다만 샘플이 흐릿함.
- NF — 가역 변환을 통해 명시적 확률모델을 학습, 고차원 확장에서 제약 존재.
- GAN — 명시적 확률모델 없이 현실적인 샘플을 생성, 학습이 불안정하지만 시각적 품질이 높음.
이러한 모델들은 복잡한 데이터 분포를 효율적으로 학습·생성하려는 공통된 목표를 공유하며, 최근에는 Diffusion 모델이 이들의 한계를 극복하는 차세대 접근법으로 부상하고 있다.
다음 글에서는 심층 생성 모델의 역사에 있어서 큰 발자취를 남긴 VAE 에 대해 깊게 알아보겠다.
📄 출처
[1] Lai, Chieh-Hsin, et al. The Principles of Diffusion Models. arXiv, 24 Oct. 2025, arXiv:2510.21890.
