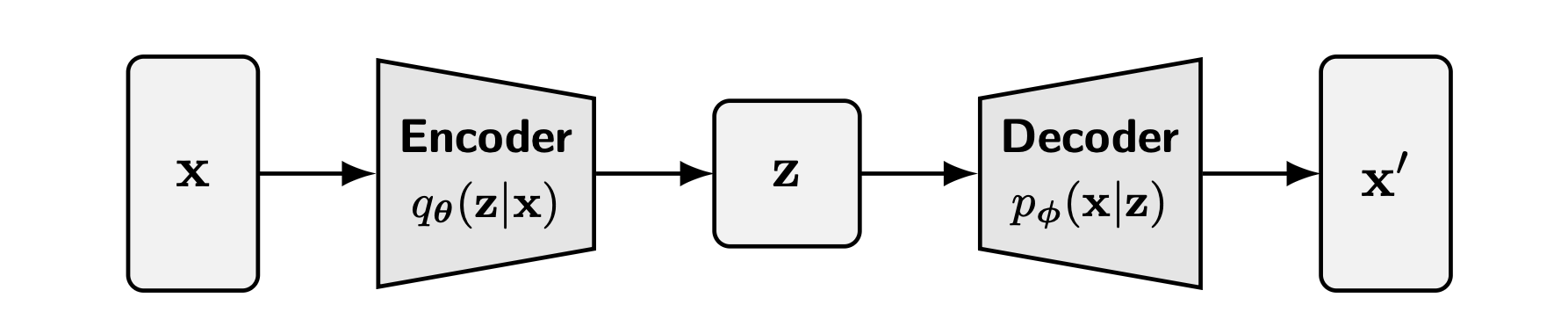
이번 글에서는 diffusion 모델을 변분법적(variational) 관점에서 살펴보고자 한다. 먼저 변분 오토인코더(Variational Autoencoder; VAE) 를 알아보자. VAE는 잠재 변수(latent variable) 을 사용해 데이터를 표현하며, 로그 가능도를 직접 계산하기 어렵기 때문에 그에 대한 하한(lower bound)인 ELBO(Evidence Lower Bound) 를 최대화하는 방식으로 학습된다.
이 과정에서 학습된 인코더(encoder) 는 관측 데이터 x를 잠재 변수 z로 매핑하고, 디코더(decoder) 는 그 z를 다시 원래의 데이터 space로 복원한다.
즉, 인코더가 데이터를 압축하고 디코더가 이를 복원하는 과정을 통해 데이터 생성의 흐름 이 하나의 모델링 루프(modeling loop) 으로 완성된다. 이 패턴을 확장하면, 계층형 VAE(Hierarchical VAE; HVAE) 를 만날 수 있는데, HVAE는 여러 개의 잠재 계층(latent layer) 을 쌓아 올려 다양한 스케일의 구조를 포착할 수 있는 VAE의 한 변형이다.
🧩 VAE 파헤치기
신경망이 현실적인 데이터를 생성(generate) 하도록 학습하려면 과연 어떻게 해야 할까. 그 출발점으로 가장 자연스러운 접근은 오토인코더(Autoencoder) 이다.
Autoencoder는 두 개의 신경망 으로 구성된다:
입력 데이터를 저차원 잠재 코드(latent code) 로 압축하는 결정적 인코더(deterministic encoder)
그 코드를 다시 원본 형태로 복원 하는 결정적 디코더(deterministic decoder)
이 모델은 학습 과정에서 원본 입력과 복원 입력 간의 재구성 오차(reconstruction error) 를 최소화한다.
🚧 단순 Autoencoder의 한계
이 방식으로 입력을 정확하게 복원할 수는 있지만, latent space는 구조화되어 있지 않다. 따라서 이 latent space에서 임의로 값을 샘플링하면 대부분 의미 없는 출력 이 생성된다. 즉, 단순한 autoencoder는 정확한 복원 은 가능하지만, 새로운 데이터를 생성하는 능력은 제한적 이라는 한계가 있다.
변분 오토인코더(Variational Autoencoder; VAE) 는 이러한 한계를 latent space의 확률적 구조(probabilistic structure) 를 부여함으로써 해결한다.
이제 latent code가 단순한 벡터가 아니라 명시적인 확률분포 에서 샘플링된 변수가 되며, 모델 전체가 확률적 생성 과정 으로 해석될 수 있게 된다. 그 결과, VAE는 단순한 복원 모델을 넘어 새로운 데이터까지 만들어낼 수 있는 진정한 generative한 모델 로 변모하여, 더 현실적이고 다양한 샘플을 생성할 수 있게 된다.
1️⃣ 확률적 인코더와 디코더
🔧 디코더(생성기)의 설계
VAE에서는 두 종류의 변수를 구분한다. 먼저 관측 변수(observed variable)x는 우리가 실제로 보는 데이터 (대표적으로 이미지)를 의미한다. 반면, 잠재 변수(latent variable)z는 관측되지 않은 숨겨진 변화 요인 들, 예를 들어 물체의 형태, 색상, 스타일 같은 특성을 담고 있다.
모델은 각 관측치 x가 어떤 잠재 변수 z로부터 생성된다고 가정한다. 이 z는 보통 표준정규분포N(0,1)와 같은 간단한 사전 분포(prior)에서 샘플링된다. 즉, z∼pprior:=N(0,1)라는 의미이며, z가 디코더를 통해 x를 생성한다고 보는 것이 VAE의 기본 구조이다.
잠재 변수 z를 다시 데이터 space로 되돌리기 위해, 우리는 디코더(decoder) 또는 생성기(generator) 라 불리는 조건부 분포 pϕ(x∣z)를 정의한다.
실제 구현에서는 이 decoder를 가능한 한 단순하게 유지하는 경우가 많다. 예를 들어 요소별로 독립된(factorized) Gaussian 분포 등을 사용한다. 이렇게 하면 모델이 데이터를 통째로 외우는 데 focusing하지 않고, 유용한 잠재 표현(latent representation) 을 학습하는 데 더 집중할 수 있게 된다.
직관적으로 생각해보면, 이미지의 픽셀을 하나하나 직접 생성하는 것은 매우 어려운 작업 이다. 하지만 잠재 변수 z가 데이터의 핵심적인 구조를 압축 하여 담고 있다면, 그 z를 기반으로 전체 픽셀 배열을 복원하는 과정은 훨씬 쉬워진다.
VAE에서 새로운 샘플을 생성하는 절차는 다음과 같다.
1. 우선 잠재 변수를 z∼pprior에서 샘플링하고, 2. 이를 디코더에 넣어 z∼pϕ(x∣z)를 통해 데이터를 생성한다.
이처럼 VAE는 간단한 확률적 잠재 공간→복잡한 데이터 공간으로의 mapping 을 학습해 새로운 현실적 샘플을 생성할 수 있게 된다.
VAE는 다음과 같은 주변가능도(marginal likelihood) 를 통해 잠재 변수 기반의 생성 모델을 정의한다.
pϕ(x)=∫pϕ(x∣z)p(z)dz
이 식은 "잠재 변수 z를 모두 고려했을 때, 데이터 x가 생성될 확률"을 의미한다.
이상적으로는 최대우도추정(Maximum Likelihood Estimation; MLE) 의 방식처럼 이 marginal likelihood를 최대화하도록 디코더의 파라미터 ϕ를 학습하는 것이 가장 바람직하지만, 현실적으로는 다음과 같은 문제점들이 발생한다.
이 한계를 해결하기 위해 등장한 것이 바로 변분 추론(variational inference) 이며, VAE는 이 variational한 접근법을 사용해 위의 문제들을 파훼한다.
🌌 인코더(추론 네트워크)의 설계
복잡한 생성 모델을 실제 데이터와 연결하려면, 거꾸로 이렇게 생각해 볼 수도 있다.
관측된 데이터 x를 만든 잠재 변수 z는 무엇일까?
베이즈 정리(Bayes' Theorem) 을 사용하면 그 답은 다음과 같은 사후분포(posterior)로 표현된다.
pϕ(z∣x)=pϕ(x)pϕ(x∣z)p(z)
하지만 여기서 큰 문제가 생긴다. 분모에 있는 pϕ(x), 즉 marginal likelihood는 모든 z에 대해 적분 ∫pϕ(x∣z)p(z)dz 해야 한다. 그런데 디코더 pϕ(x∣z)가 non-linear한 신경망 이다 보니, 이 적분은 사실상 계산이 불가능(intractable) 하다.
그래서 결론은, 관측된 x로부터 pϕ(z∣x)같은 정확한 posterior를 얻는 것은 계산량이 너무 커서 현실적이지 않다는 것이다.
VAE의 변분(variational) 단계는 intractable한 posterior를 tractable한 근사 분포 로 대체함으로써 이 문제를 해결한다. 이를 위해 parameterized된 인코더 (또는 추론 네트워크) qθ(z∣x)를 도입한다.
이 인코더의 역할은 다음과 같은 learnable한 대리자(proxy)가 되는 것이다.
qθ(z∣x)∼pϕ(z∣x)
실제로 인코더는 관측된 각 데이터 x를 latent code의 분포로 mapping하여 x에서 z로 되돌아가는 현실적이고 학습 가능한 경로 를 제공한다.
2️⃣ ELBO를 통한 학습
이제 계산 가능한, tractable한 학습 목적 함수를 정의해보자. logpϕ(x)를 직접 최적화할 수는 없지만, 그 값에 대한 하한인 증거 하한(Evidence Lower Bound; ELBO) 를 최대화할 수는 있다.
정리 2.1.1 – Evidence Lower Bound (ELBO)
임의의 데이터 x에 대해 로그 가능도(log-likelihood)는 다음을 만족한다.
재구성(Reconstruction)Ez∼qθ(z∣x)[logpϕ(x∣z)]:
latent code z로부터 x를 정확하게 복원 하도록 유도하는 항이다.
인코더와 디코더가 Gaussian을 따른다고 가정하면, 이 항은 일반적인 autoencoder의 재구성 손실과 정확히 동일한 형태로 단순화된다.
하지만 autoencoder와 마찬가지로, 이 항만을 최적화하면 훈련 데이터를 그대로 암기해버릴(overfitting) 가능성이 있기 때문에 추가적인 정규화 항이 필요하다.
잠재 KLDKL(qθ(z∣x)∣∣p(z)):
인코더 분포 qθ(z∣x)가 간단한 Gaussian prior pprior(z)와 가까워지도록 유도 하는 항이다.
이 정규화는 latent space를 부드럽고 연속적인 구조 로 형성하여, prior 분포에서 샘플을 뽑았을 때도 디코더가 신뢰할 수 있는 데이터를 생성할 수 있도록 돕는다.
이 균형을 통해 정확한 재구성과 일관된 샘플 생성 을 동시에 달성할 수 있다.
🥅 발산 경계로서의 ELBO
ELBO 목적 함수는 자연스럽게 정보 이론(Information Theory) 적인 해석을 갖는다. MLE 학습을 수행한다는 것은 곧 다음의 KL 발산을 최소화한다는 뜻이다.
DKL(pdata(x)∣∣pϕ(x))
즉, 모델 분포가 실제 데이터 분포를 얼마나 잘 근사하는지를 측정하는 지표이다. 하지만 이 항은 일반적으로 intractable하기 때문에, 변분 추론법(variational inference)은 이를 직접 비교하는 대신 결합 분포(joint distribution) 를 이용한 비교 방식을 도입한다.
구체적으로, 다음의 두 결합 분포를 이용한다.
생성 모델의 결합 분포: pϕ(x,z)=p(z)pϕ(x∣z), 이는 모델이 잠재 변수 z로부터 어떻게 데이터를 생성하는지를 나타낸다.
추론 결합 분포: qθ(x,z)=pdata(x)qθ(z∣x), 이는 실제 데이터 x롸 그로부터 추론한 잠재 변수 z를 결합한 분포이다.
이 두 결합 분포를 비교함으로써 다음의 부등식을 도출해낼 수 있다.
DKL(pdata(x)∣∣pϕ(x))≤DKL(qθ(x,z)∣∣pϕ(x,z))
이는 KL 발산의 연쇄 법칙(chain rule for KL divergence) 라 불린다.
직관적으로 설명하면, 겉으로 보이는 marginal한 분포(x)를 비교하는 것만으로는 모델과 데이터 사이의 불일치가 잘 드러나지 않을 수 있다. 하지만 잠재 변수-데이터의 전체 결합 분포(x,z) 를 비교하게 되면 숨겨진 차이점들이 훨씬 명확하게 드러난다.
수학적으로 결합(joint) KL을 전개해보면 다음과 같다.
Total Error BoundDKL(qθ(x,z)∣∣pϕ(x,z))=Eqθ(x,z)[logpϕ(x)pϕ(z∣x)pdata(x)qθ(z∣x)]=Epdata(x)qθ(z∣x)[logpϕ(x)pdata(x)]+Epdata(x)qθ(z∣x)[logpϕ(z∣x)qθ(z∣x)]=Epdata(x)[logpϕ(x)pdata(x)]+Epdata(x)[∫qθ(z∣x)logpϕ(z∣x)qθ(z∣x)dz]=True Modeling ErrorDKL(pdata(x)∣∣pϕ(x))+Inference ErrorEpdata(x)[DKL(qθ(z∣x)∣∣pϕ(z∣x))]
첫 번째 항은 모델이 실제 데이터를 얼마나 잘 설명하지 못하는지에 대한 true 모델링 오차 를 의미한다. 두 번째 항은 posterior와 실제 posterior 사이의 차이, 즉 추론 오차 를 나타내며 이 값은 항상 0 이상 이다.
바로 이 성질 때문에 위의 부등식이 성립한다. ELBO가 항상 로그 주변가능도의 lower bound가 되는 이유가 여기에 있다.
마지막으로 다음 관계를 살펴보면,
logpϕ(x)−LELBO(θ,ϕ;x)=DKL(qθ(z∣x)∣∣pϕ(z∣x))
추론 오차는 바로 로그 가능도와 ELBO 사이의 차이와 정확히 일치한다. 따라서 ELBO를 최대화하는 것은 곧 이 추론 오차를 직접적으로 줄이는 것 이 되며, 이는 곧 전체 bound에서 의미 있는 부분을 최소화하는 효과를 갖는다.
3️⃣ Gaussian VAE
표준적인 VAE 설계에서는 인코더와 디코더 모두 Gaussian 분포 를 사용하는 방식을 택한다.
인코더 qθ(z∣x)는 보통 다음과 같은 Gaussian 분포로 모델링된다.
qθ(z∣x):=N(z;μθ(x),diag(σθ2(x)))
여기서 μθ:RD→Rd와 σθ:RD→R+D는 인코더 신경망 이 출력하는 deterministic한 함수들이다.
디코더 pϕ(x∣z) 역시 보통 고정된 분산을 갖는 Gaussian 분포로 모델링된다.
pϕ(x∣z):=N(x;μϕ(z),σ2I)
여기서 μϕ:Rd→RD는 디코더 신경망 이며, σ>0은 분산의 크기를 조절하는 작은 상수이다.