캠페인의 큰 비중을 차지하는 대사 시스템을 구현할 차례입니다.
캠페인이 진행되는 동안 게임 내 등장인물들은 무전으로 이야기를 합니다.
심지어 적군 무전도 들을 수 있고, 어떨 때는 서로 대화를 하기도 하죠.
그리고 에이스 컴뱃 시리즈에는 특유의 자막 UI가 있습니다.

<< 이렇게 꺽쇠(부등호) 기호 두 개를 겹쳐서 대사를 감쌉니다. >>
그리고 이름과 기호에 색깔을 입혀서 아군, 적군, 중립을 표현하죠.
음성 파일 구하기
이 프로젝트는 에이스 컴뱃 제로의 마지막 미션을 구현하는 것이 목표입니다.
그 미션에 사용된 음성을 어딘가에서 얻어와야 하는데...
https://www.reddit.com/r/acecombat/comments/4d3vdx/ace_combat_5_and_zero_voice_packs_released_too/
레딧에 있는 능력자분들께서 다 추출해놓으셨더군요.

어느정도 분류는 되어있는 상태입니다만...
어... 무슨 음성인지는 하나도 모르겠네요. 게다가 파일명에 .wav는 왜 들어가있을까요?
그리고 해당 미션에서 등장인물이 어떤 대사를 말하는지도 알아내야 합니다.
다행히 이건 정리된 페이지가 있었습니다.
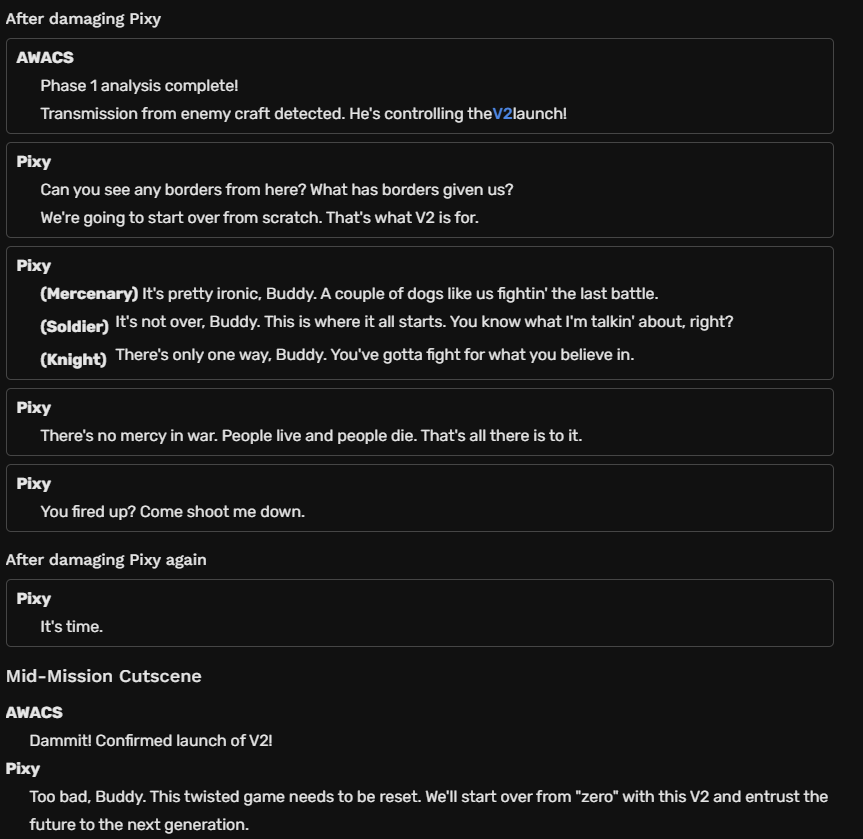
https://acecombat.fandom.com/wiki/Transcript:Zero
각 페이즈별 등장인물의 대사는 물론, 에이스 컴뱃 제로 고유의 "에이스 스타일" 시스템에 따라 다르게 출력되는 대사까지 모두 정리되어 있습니다.
그렇다면...

여기서 저 대사들을 모두 찾아야겠군요.
1시간에 가까운 탐색전 끝에 모두 찾아내서 정리하는 데에 성공했습니다.
파일 이름도 페이즈나 순서에 맞게 정리했고요.
그런데...

컷씬에 사용되는 음성이 없습니다.
이건 어디서 추출할 방법도 없는 것 같네요.
컷씬 음성 추출하기
제가 사용할 수 있는 소스는 사람들이 플레이한 미션 유튜브 영상밖에 없습니다.
그리고 영상의 컷씬에는 모두 배경음악이 깔려있죠.
일단 가장 배경음의 간섭이 덜한 영상의 컷씬을 찾아내서 그 부분을 .wav 파일로 변환했습니다.
여기서 배경음악을 최대한 줄여서 음성 부분만 들어내야 합니다.
AI로 MR을 제거해서 음성 부분만 떼어내주는 사이트가 있었는데요, 큰 효과는 없었습니다.
왜냐하면 컷씬의 음성은 온전한 목소리가 아니라, 무전으로 인해 왜곡된 목소리이기 때문이죠.
목소리가 무전 잡음과 같이 잘려나가버리는 경우가 꽤 많았습니다.
주파수 조절하기
음원에서 반주 부분을 제거하는 방법 중 가장 확실한 방법은 위상차를 이용하는 것입니다.
원래 음원과 반주 음원을 준비해서, 두 음원의 싱크를 완벽하게 맞춘 다음 반주 음원의 위상을 뒤집어서 원곡의 반주 부분을 상쇄시키면 보컬 부분만 남게 되죠.
하지만 게임 영상을 녹음한 오디오에서 위상차 방법을 사용하는 것은 불가능합니다.
게임 오디오를 녹음한 것은 원본 배경 음악과는 차이가 날 수밖에 없기 때문이죠.
그 대안으로, 주파수를 조절하는 방법을 사용하려고 합니다.
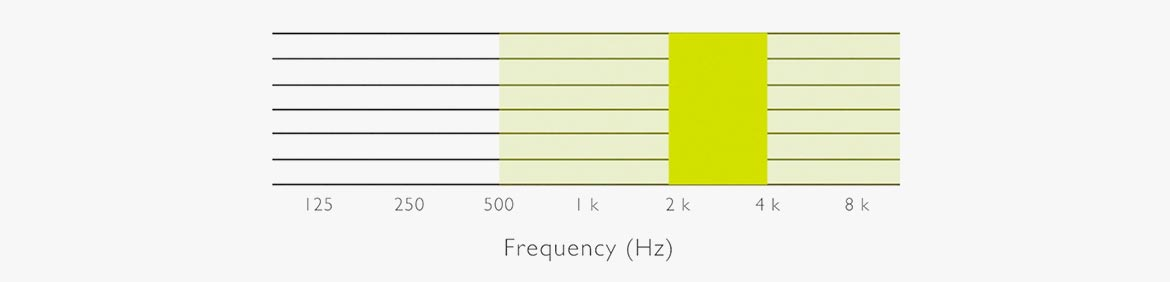
오디오에서 사람의 목소리가 포함된 주파수 대역을 강조하고,
그 밖의 배경음악이 깔려있을 주파수 대역을 낮추는 방법입니다.
깔끔한 방법은 아니지만, 그래도 나름 들어줄만 한 수준으로 배경음을 상쇄시켜줄 겁니다.
물론 목소리 주파수와 배경음 주파수가 비슷한 위치에 있다면 제거가 어렵지만요.
앞서 말씀드렸듯이 지금 추출해야 하는 음성은 무전으로 인해 왜곡된 음성이기 때문에,
일반적인 사람의 목소리 주파수 대역과는 차이가 있을 수 있습니다.
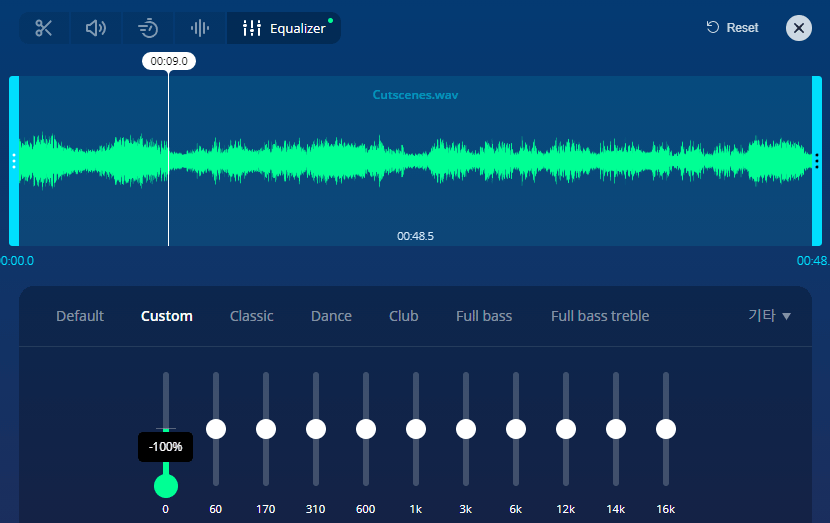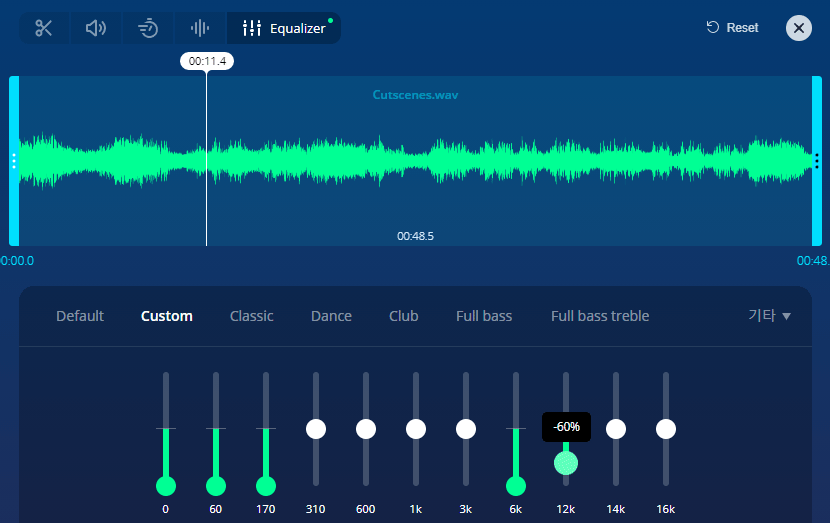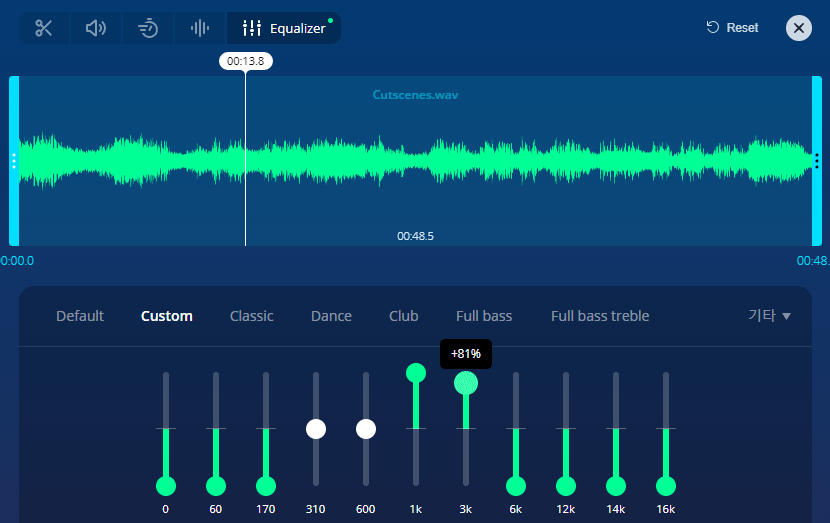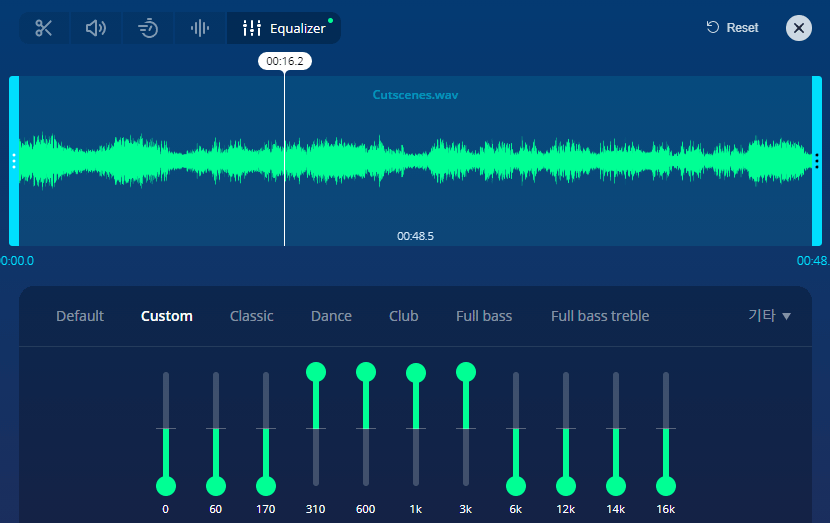
https://mp3cut.net/ko/equalizer
온라인으로 EQ를 설정할 수 있는 사이트가 있었는데... 재생하면서 설정도 할 수 있어요!
이전에 오디오를 편집할 때 사용했던 Audacity는 실시간으로 편집하는 게 불가능했는데요...
사용할 수 있는 방법을 최대한 활용해봤습니다.
위 사이트에서 EQ 조절 2번 +
Audacity로 목소리 증폭 + 노이즈 감소 + 다시 EQ 조절을 거쳐서...
컷씬에 사용할 오디오 소스 최종본이 나왔습니다.
...과연 최종본일지는 두고보죠.
자막 시스템 설계
지금 가장 중요한 주제는, 자막 시스템을 어떻게 만들어야 하냐는 겁니다.
어떤 방식으로 자막 데이터를 가져와서 어떻게 UI에 출력할 수 있느냐가 문제죠.

이렇게 초상화가 있는 자막을 띄워야 할 때도 있고,


적군인 경우에는 이름과 괄호의 색깔을 바꿔줘야 하고,

AWACS의 경우에는 중요한 메시지인 경우 이렇게 이름 양 옆에 느낌표 표시를 띄웁니다.
각각의 자막마다 필요한 요소를 생각해봅시다.
- 자막에 쓸 대사 데이터
- 음성 데이터
- 자막이 출력되는 타이밍
- 등장인물 및 진영(아군/적군/중립)
- 초상화 표시 여부
- 강조 효과
- 자막 출력과 같이 실행할 함수, 딜레이
1. 대사 데이터
저는 이 게임이 영어와 한국어를 지원하게끔 만들려고 합니다. (최중요 목표는 아닙니다.)
그래서 영어 자막 파일과 한국어 자막 파일을 나눈 다음에, 각각의 대사에 헤더를 달아두고,
대사 데이터에서는 헤더만 가지고 있게 하는 식으로 만들어보려고 합니다.
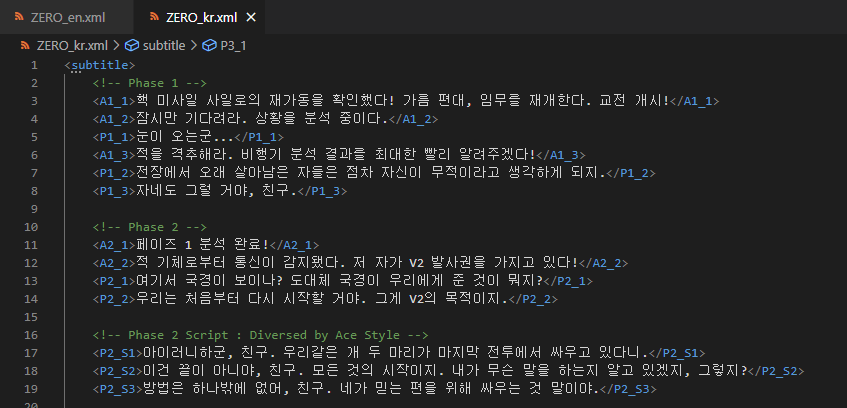
가령 대사 파일에 이렇게 써져 있다고 치면, (예시: JSON)
(한국어 파일)
<A1_1>핵 미사일 사일로의 재가동을 확인했다! 가름 편대, 임무를 재개한다. 교전 개시!</A1_1>
<A1_2>잠시만 기다려라. 상황을 분석 중이다.</A1_2>
<P1_1>눈이 오는군...</P1_1>
(영어 파일)
<A1_1>Confirmed reactivation of nuclear silo! Galm Team, continue your mission. Engage!</A1_1>
<A1_2>Stand by. We're analyzing the situation.</A1_2>
<P1_1>Here comes the snow...</P1_1>대사 데이터에는 헤더 값만 가지고 있으면, 현재 언어 설정에 따라 해당하는 파일의 해당하는 헤더 데이터만 가지고 오면 되겠죠.
이 대사 데이터는 하나의 파일에 모두 담겨지도록 만들려고 합니다.
2. 음성 데이터
이건 대사 데이터의 키 값과 한 세트로 묶으면 되겠네요.
3. 타이밍
페이즈를 시작할 때, 또는 페이즈를 넘어갈 때 고정적으로 출력되는 대사가 있는 반면,
무작위 타이밍에 출력되는 대사도 있고,
상대방의 체력이 일정 수치 이하로 떨어지면 출력해야 하는 대사도 있죠.
고정적으로 출력해야 하는 대사는 시간 데이터를 잡아주고,
랜덤으로 출력해야 하는 대사는 고정적으로 출력해야 하는 대사 이후에 출력되도록 시간을 랜덤으로 설정하고,
특정 조건이 필요한 대사는 그 조건을 실시간으로 감시하도록 만들어야 할 겁니다.
자막을 몇 초동안 띄워야 하는지는 여기서 정할 필요는 없습니다.
음성 오디오의 재생이 끝난 후에 약 0.5초 정도 기다린 다음 꺼버리면 되니까요.
4. 등장인물 및 진영(아군/적군/중립)
5. 초상화 표시 여부
6. 강조 효과
7. 자막 출력과 같이 실행할 함수, 딜레이
이것도 그냥 대사 데이터, 음성 데이터와 한 세트로 묶으면 될 것 같습니다.
대사 데이터: XML
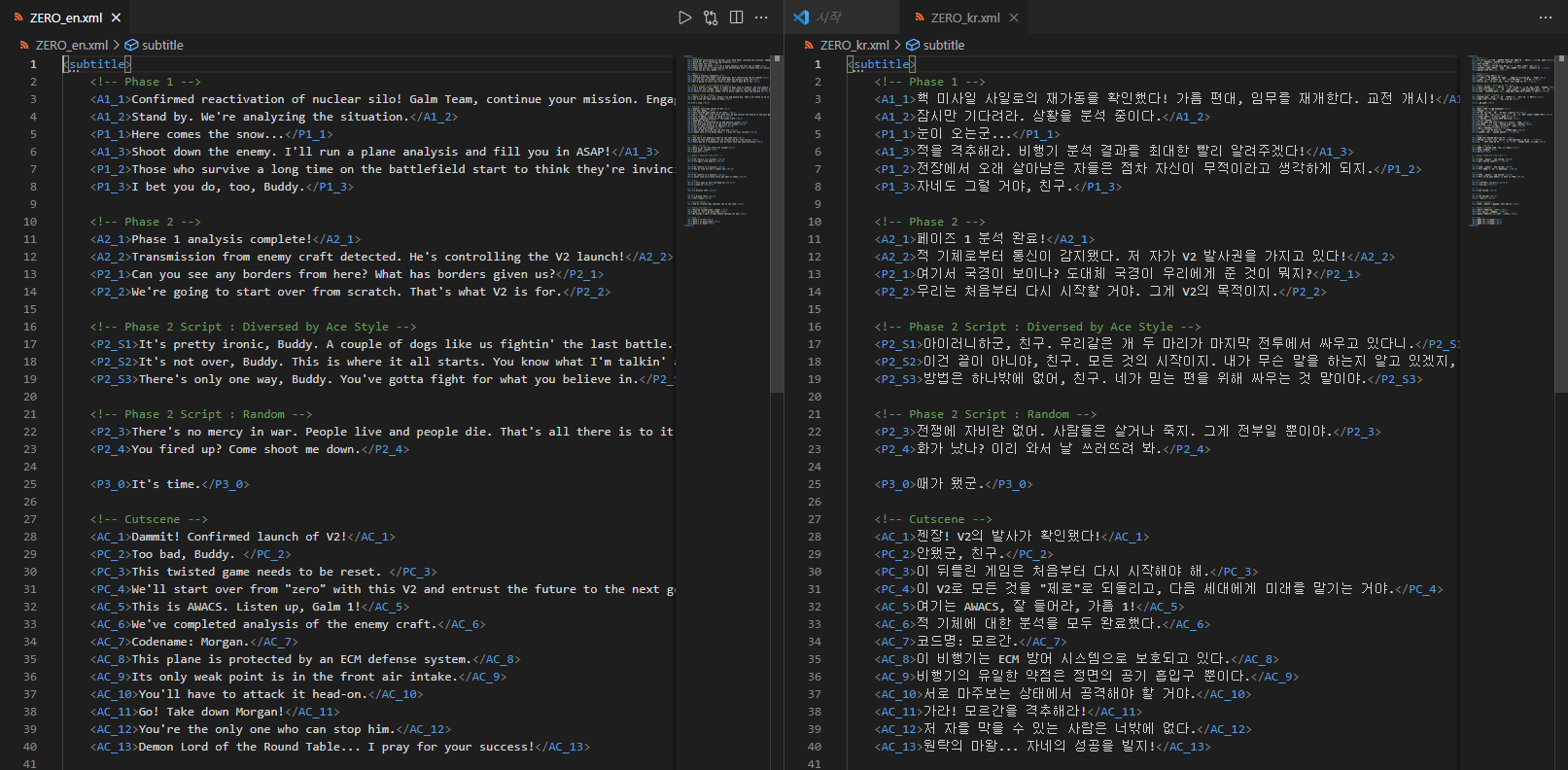
대사 데이터 파일은 이렇게 XML 형식으로 만들었습니다.
자막을 출력할 때 헤더값을 참조해서 해당하는 대사의 데이터를 얻어오게 됩니다.
예를 들어 이 게임의 첫 번째 대사를 출력해야 하는 곳에서 "A1_1"이라고 적어놓으면,
현재 언어에 맞는 XML 파일의 "A1_1"에 있는 데이터를 가져와서 출력하도록 만들 겁니다.
자막 데이터 구조
subtitleKey: 자막에 쓸 대사 데이터와 음성 데이터 (키 값)name: 등장인물 이름side: 진영(아군/적군/중립)
각 자막마다 위에 있는 3가지 속성들을 모두 가지고 있어야 하며, (기본값으로도 대체 가능)
preDelay: 자막이 출력되는 타이밍portrait: 초상화isImportant: 강조 효과invokeFunctionName,invokeFunctionDelay: 같이 실행할 함수와 딜레이isRemovable: 대사 출력 대기열에서 삭제될 수 있는 자막
(출력할 대사가 있는데 출력 전에 게임 오버가 되는 경우에도 그 대사를 꼭 출력해야 하는지에 대한 여부를 결정합니다. 기본값은 true입니다.)
위에 있는 속성들은 필요하다면 선택적으로 가지고 있어야 합니다.
이 자막 데이터를 어떤 식으로 저장할지 생각해야 합니다.
음... ScriptableObject?
각 자막마다 ScriptableObject 파일을 이용해서 저장하는 방식을 생각해보죠.
VS Code같은 텍스트 편집 프로그램을 띄울 필요 없이, Inspector 창에서 그 자막에 필요한 오디오 파일을 드래그/드롭하고 데이터를 적어놓는 건 굉장히 쉬울 겁니다.
그리고 이 미션에서는 대사가 그렇게 많지 않기 때문에, 데이터를 적어놓거나 드래그/드롭하는 양도 딱히 부담을 줄 정도는 아니겠죠.
그런데 이 방식의 단점은 정말 대사 하나하나마다 파일이 생성되어야 한다는 겁니다.
이 미션에서 사용되는 오디오가 50개가 있으면, 자막 파일도 50개를 만들어야 합니다.
"오디오 파일도 각각 나뉘었는데 자막 파일도 나뉘면 어때?" 라고 생각할 수 있겠지만...
글쎄요. 별로 바람직해보이지는 않습니다.
그래서 "한 미션에 사용되는 자막은 한 파일 내에서 관리되어야 한다"라는 전제를 가지고,
자막 데이터를 만들어보려고 합니다.
자막 데이터 : JSON
"subtitles": [
{
"subtitleKey": "A1_1",
"name": "AWACS Eagle Eye",
"side": "A",
"preDelay": 2,
"isImportant": true,
"invokeFunctionName": "Phase1Start",
"invokeFunctionDelay": 2.5
},
{
"subtitleKey": "A1_2",
"name": "AWACS Eagle Eye",
"side": "A"
},
...
]이런 식으로 만들 겁니다.
이 자막 데이터는 언어 설정과는 무관합니다.
로컬라이징은 대사 데이터만 다르게 하면 되고, 자막 데이터는 수정하지 않습니다.
아니, 대사 데이터는 XML 써놓고 여기서는 왜 JSON이냐고요?
자막 데이터는 클래스화하기 좋습니다. 각각의 자막은 일정한 형식을 가지고 있어야 하죠.
하지만 대사 데이터는 그냥 문자열 덩어리에요. 클래스화시키기 애매합니다.
그래서 key:value 형태의 Dictionary 형태로만 저장하기 위해서 XML로 만들어놓았습니다.
변명을 좀 더 하자면, JSON과 XML을 둘 다 사용해보기 위함이었습니다.
데이터 중복, 또는 쓸데없이 여러 번 적는 것을 방지하기 위해 데이터베이스처럼 정규화를 거칠 수 있겠지만, 프로토타입에 가까운 게임이니만큼 그냥 넘어가겠습니다.
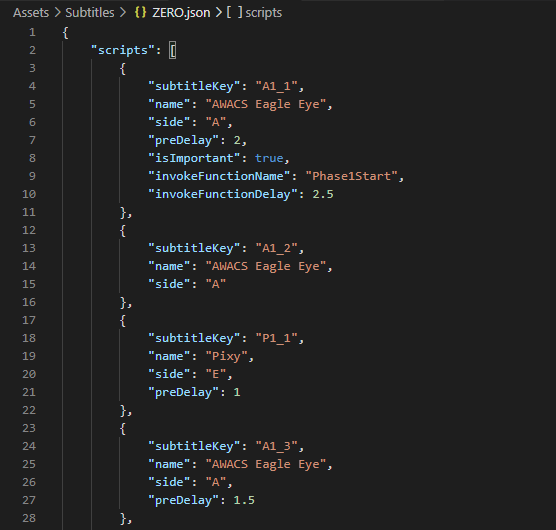
이렇게 각 자막에 필요한 데이터들만 넣어준 모습입니다.
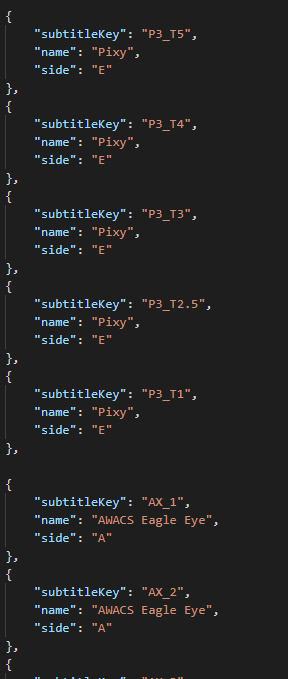
...
중복된 데이터가 많긴 하죠.
AWACS면 항상 아군이고 픽시면 항상 적군이니까 저걸 굳이 저렇게 중복으로 표현해야 하는지,
그리고 이미 키값으로 누가 말하는지 식별할 수 있도록 A와 P를 적어놓았는데 왜 또 써놓는지.
되게 비효율적으로 작성하긴 했죠. 자막 데이터 구성은 처음이라 양해 부탁드립니다.
그래도 지금은 등장인물이 두 명이라 그렇지, 10명이 넘어가면 일일이 써줘야 할 수도 있습니다.
아니면 미션 도중에 등장인물이 갑자기 배신을 때려서 진영이 바뀐다거나 할 수도 있죠.
제대로 된 정규화를 해준다면 해결이 가능합니다만, 프로토타입이니까요...
파일을 동적으로 로드하기 : Addressable
"P1_3": {
"name": "Pixy",
"side": "E"
},이런 자막 데이터를 가져와서 실행한다고 할 때,
P1_3.wav를 가져와서 실행하고, Pixy.png를 가져와서 UI에 붙여줘야 합니다.
게임에서 오디오를 실행하고 초상화를 UI에 붙이기 위해서는 파일명을 파싱한 다음 그 파일들을 게임 실행 도중에 동적으로 로드해서 사용해야 합니다.
유니티에서 파일명을 기반으로 로드할 때 사용할 수 있는 방법이 대표적으로 두 가지가 있습니다.
1. Resources 폴더
유서 깊은 Resources 폴더입니다. 관련된 사용 예시도 정말 많지만...
공식 문서에 적혀있는 강력한 글귀가 있습니다.

https://learn.unity.com/tutorial/assets-resources-and-assetbundles#5c7f8528edbc2a002053b5a7
쓰지 마세요.
그래서 저도 안 쓰려고요.
(문서에는 써도 괜찮은 예시가 적혀 있습니다만, 그래도 안 쓰는게 좋을 것 같습니다.)
2. Addressable
Resources의 문제를 해결하면서도 비슷한 사용법으로 파일을 불러올 수 있는 기능입니다.
간단히 말하자면, 파일들에게 주소(Address)를 부여해서 파일을 관리하는 기능입니다.
이 Addressable이라는 기능을 사용해서 게임 실행 중에 파일을 가져와보겠습니다.
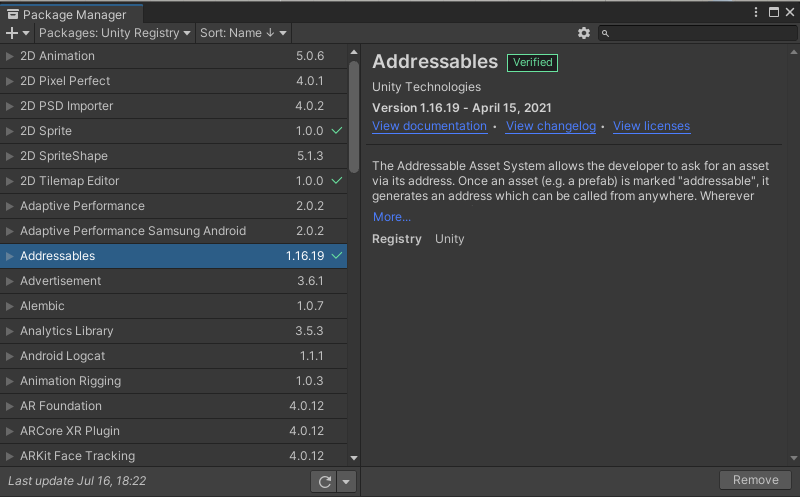
Addressable을 사용하려면 Package Manager에서 "Addressables"를 찾아 설치해줘야 합니다.
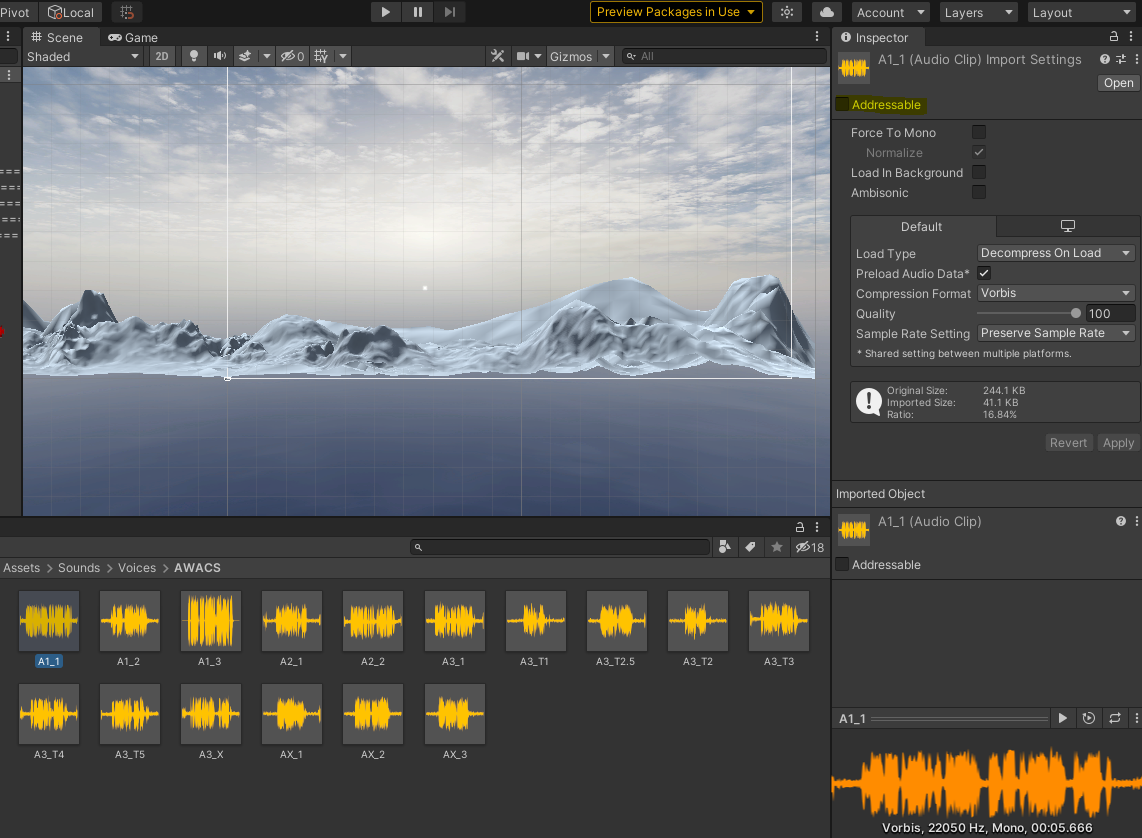
설치 후에 C# 스크립트를 제외한 파일을 클릭해보면 Inspector 창에 "Addressable"이라는 체크박스가 생기게 됩니다.
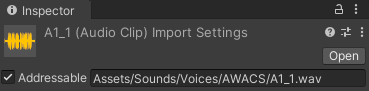
이 체크박스를 누르면 약간의 로딩 후 현재 경로가 자동으로 작성되는 것과 동시에,
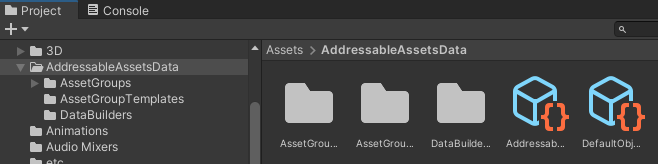
Project에 "AddressableAssetsData"라는 폴더와 함께 여러 파일과 폴더가 생성됩니다.
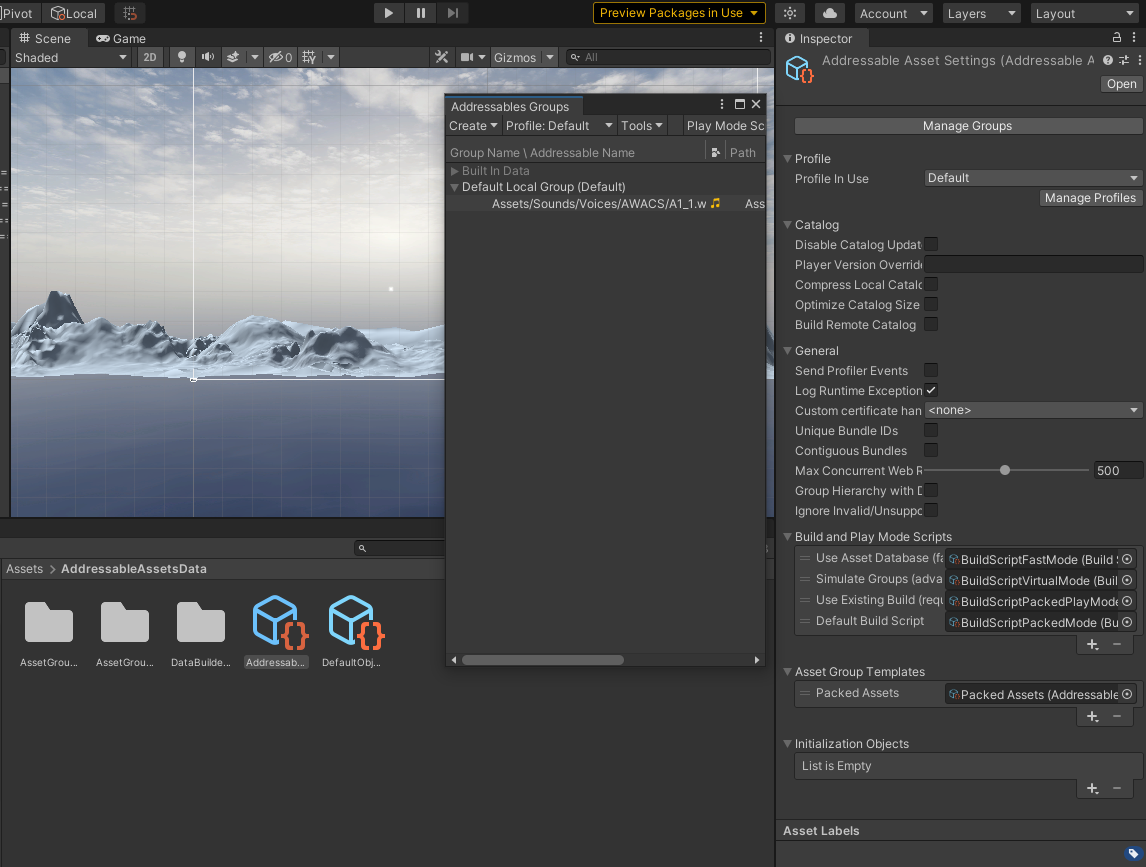
여기서 Addressable Asset Settings 파일을 클릭하면 여러 설정들을 확인할 수 있고,
Manage Groups 버튼을 누르면 Default Local Group에 방금 Addressable을 체크한 항목이 들어가있는 것을 확인할 수 있습니다.
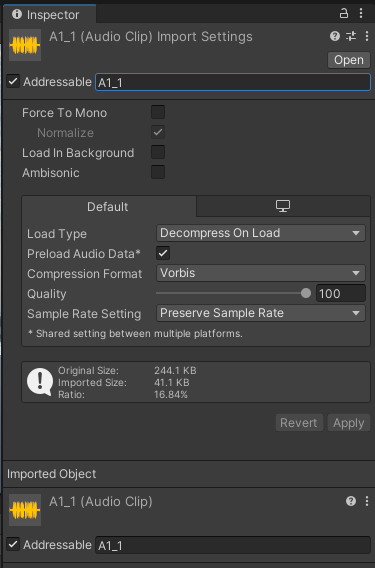
다시 Addressable로 돌아가서,
여기에 적는 Address는 굳이 전체 경로를 적어줄 필요도, 확장자도 적어줄 필요도 없습니다.
가령 제가 여기에 "A1_1"같은 형식으로 써있는 모든 것들을 오디오 파일이라고 두겠다고 하면,
Address를 이렇게 써주고 코드로 "A1_1"을 가져온 다음 오디오 클립으로 형변환하면 됩니다.
JSON 파싱
public class ScriptInfo
{
public string subtitleKey = "";
public string name = "";
public string side = "A"; // "A"lly, "E"nemy, "N"eutral
public float preDelay = 0.5f;
public bool isImportant = false; // AWACS only
public string invokeFunctionName = "";
public float invokeFunctionDelay = 0;
}ScriptInfo는 각 자막마다 가지고 있어야 하는 속성들을 모두 가지고 있는 클래스입니다.
굳이 접근제한자에 얽매일 필요가 없을 것 같아 모두 public으로 선언했습니다.
아까 작성했던 자막 데이터를 ScriptInfo로 파싱하는 것부터 해보죠.
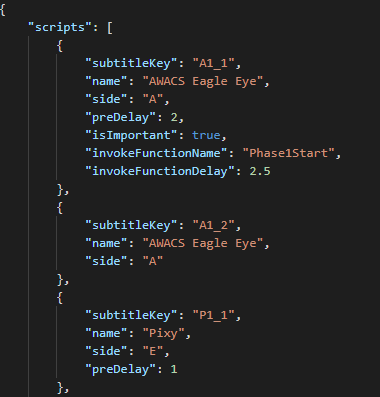
데이터는 이런 형식으로 되어 있습니다.
"subtitles" 내부에 배열로 여러 개의 자막 데이터 정보들이 들어있고,
각 데이터들은 필수적으로 들어가야 하는 데이터와, 필수적이지 않은 데이터가 섞여 있습니다.
ScriptManager.cs
using System.Collections.Generic;
using UnityEngine;
using System;
[Serializable]
public class ScriptData
{
public List<ScriptInfo> scripts;
}
public class ScriptManager : MonoBehaviour
{
Dictionary<string, ScriptInfo> subtitleDictionary;
[SerializeField]
TextAsset subtitleJsonFile;
void ParseJSON()
{
string jsonString = subtitleJsonFile.text;
ScriptData subtitle = JsonUtility.FromJson<ScriptData>(jsonString);
// DEBUG
Debug.Log(subtitle.scripts[0].name);
Debug.Log(subtitle.scripts[0].invokeFunctionName);
}
// Start is called before the first frame update
void Start()
{
ParseJSON();
}
}유니티에서 제공하는 JsonUtility를 이용하면 JSON 문자열을 바로 클래스로 변환할 수 있습니다.
특이한 건 배열 ([])로는 변환이 불가능한데, 리스트 (List<>)로는 변환이 가능하다는 것이죠.
ScriptData라는 클래스에 배열 이름인 "scripts"를 리스트 변수 이름으로 두면, 모든 데이터들이 리스트 형태로 scripts에 파싱됩니다.
파싱이 제대로 되는지 디버깅을 해봅시다.

첫 번째 데이터는 7가지 변수가 다 들어가있습니다. name과 InvokeFunctionName을 출력해보죠.
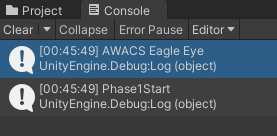
문제없이 출력됩니다.
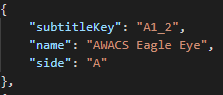
그러면 두 번째 데이터를 봅시다. 여기는 name 있지만 invokeFunctionName은 없습니다.
과연 invokeFunctionName은 어떻게 표시될까요?
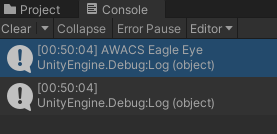
공백으로 표시됩니다.
만약 ScriptInfo에 invokeFunctionName의 기본값을 설정하지 않았다면 "Null"로 표시될 겁니다.
기본값이 제대로 세팅되는지 한 번 더 확인해보죠.
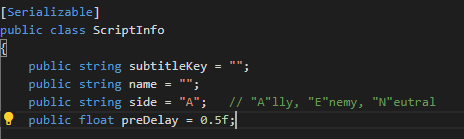
ScriptInfo에서 preDelay의 기본값은 0.5로 설정되어있는데,
위에서 캡쳐한 두 번째 데이터에는 "preDelay" 항목이 없습니다.
그러면 값은 0이 될까요, 0.5가 될까요?
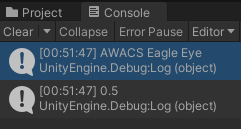
0.5가 됩니다. 적어주지 않을 경우에는 스크립트에서 설정한 기본값으로 초기화됩니다.
Addressable 파일 가져오기
지금까지는 문자열과 숫자같은 기본 데이터 타입을 다뤘었죠.
근데 아까 Addressable 기능으로 파일을 참조한다 했잖아요?
Addressable로 지정했던 파일을 한 번 꺼내보죠.
ScriptManager.cs
void ParseJSON()
{
string jsonString = subtitleJsonFile.text;
ScriptData subtitle = JsonUtility.FromJson<ScriptData>(jsonString);
string audioClipName = subtitle.scripts[0].subtitleKey;
Addressables.LoadAssetAsync<AudioClip>(audioClipName).Completed += (operationHandle) =>
{
AudioClip audioClip = operationHandle.Result;
audioSource.PlayOneShot(audioClip);
};
}이 코드는 첫 번째 데이터의 subtitleKey 값과 일치하는 Addressable 에셋을 가져와서 재생시킵니다.
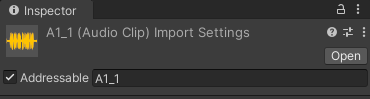
저는 각 오디오 파일의 Address를 파일명으로 모조리 등록해놨었습니다.
첫 번째 데이터의 subtitleKey는 "A1_1"이었고, "A1_1.wav"의 Address도 "A1_1"입니다.
이렇게 설정하고 실행하면, 에셋이 로딩되는 즉시 "A1_1.wav"의 오디오가 실행됩니다.
에셋을 불러오는 작업은 비동기로 진행됩니다.
따라서 에셋을 받아온 후에 실행할 코드를 작성할 때는LoadAssetAsync<>().Completed에 delegate를 추가해주는 방식으로 구현합니다. 매개변수의 타입은AsyncOperationHandle입니다.
구현은 다음 포스트에서
대사 데이터 : XML
자막 데이터 : JSON
파일 동적 호출 방식 : Addressable
자막 데이터, 대사 데이터, 그리고 파일을 불러오는 방법까지 모두 준비됐습니다.
이제 게임에다가 접목시키는 일만 남았습니다.
이 부분부터는 다음 포스트에서 다루겠습니다.
포스트 분량 조절 좀 하려고요.
이 프로젝트의 작업 결과물은 Github에 업로드되고 있습니다.
https://github.com/lunetis/OperationZERO
