알고리즘
학습 목표
-
논리적 사고력 향상
-
문제 해결 능력 향상 → 최종 목표는 연습 문제가 아닌 '현실 세계 문제'
알고리즘
유한한 단계를 통해 문제를 해결하기 위한 절차나 방법이다. 주로 컴퓨터용어로 쓰이며, 컴퓨터가 어떤 일을 수행하기 위한 단계적 방법을 말한다.
간단하게 다시 말하면 어떤 문제를 해결하기 위한 절차라고 볼 수 있다.
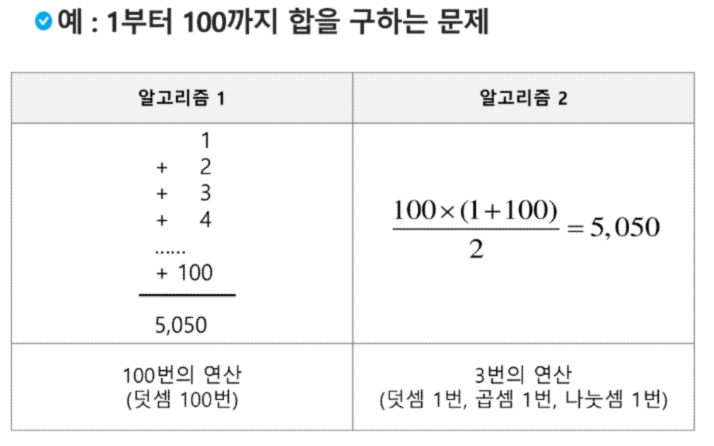
예를 들어 1부터 100까지의 합을 구하는 문제를 생각해 보자.
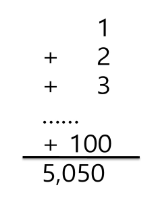
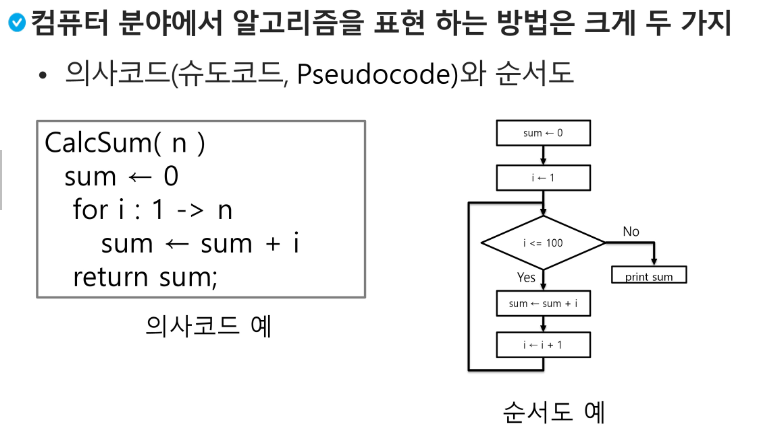
APS 과정의 목표 중 하나는 보다 좋은 알고리즘을 이해하고 활용하는 것이다.
무엇이 좋은 알고리즘인가?
-
정확성 : 얼마나 정확하게 동작하는가
-
작업량 : 얼마나 적은 연산으로 원하는 결과를 얻어내는가
-
메모리 사용량 : 얼마나 적은 메모리를 사용하는가
-
단순성 : 얼마나 단순한가
-
최적성 : 더 이상 개선할 여지없이 최적화되었는가
주어진 문제를 해결하기 위해 여러 개의 다양한 알고리즘이 가능 → 어떤 알고리즘을 사용해야 하는가?
알고리즘의 성능 분석 필요
- 많은 문제에서 성능 분석의 기준으로 알고리즘의 작업량을 비교한다.
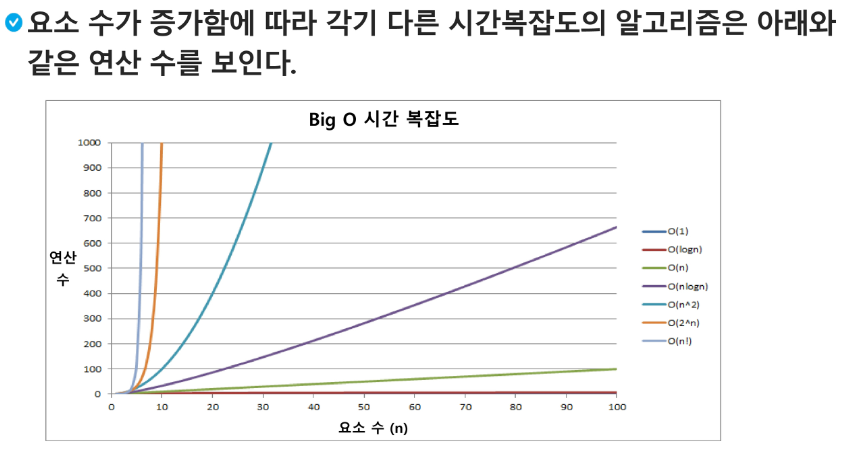
알고리즘의 작업량을 표현할 때 시간복잡도로 표현한다.
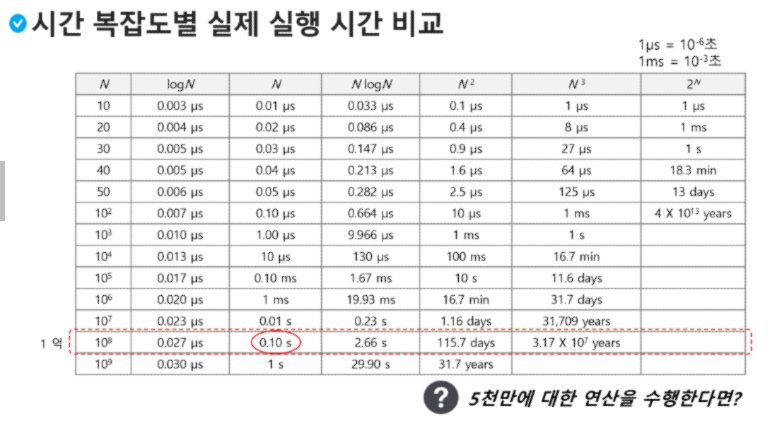
시간 복잡도(Time Complexity)
실제 걸리는 시간을 측정
실행되는 명령문의 갯수를 계산
시간 안에 들어오면 시간 복잡도가 낮고, 시간 보다 오래 걸리면 시간 복잡도가 높은 것이다.

시간 복잡도 〓 빅-오(O) 표기법
빅-오(O) 표기법 (Big-O Notation)
시간 복잡도 함수 중에서 가장 큰 영향력을 주는 n에 대한 항만을 표시
계수 (Coefficient)는 생략해서 표시

n 개의 데이터를 입력 받아 저장한 후 각 데이터에 1씩 증가시킨 후 각 데이터를 화면에 출력하는 알고리즘의 시간복잡도는?
O(n)
배열
배열
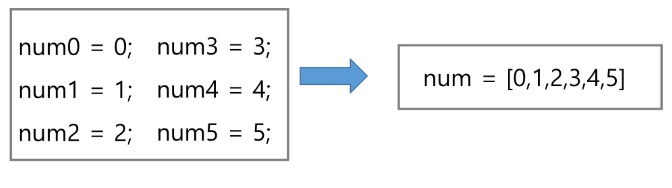
일정한 자료형의 변수들을 하나의 이름으로 열거하여 사용하는 자료 구조
6개의 변수를 사용해야 하는 경우, 이를 배열로 바꾸어 사용하는 예
배열의 필요성
프로그램 내에서 여러 개의 변수가 필요할 때, 일일이 다른 변수명을 이용하여 자료에 접근하는 것은 매우 비효율적일 수 있다.
배열을 사용하면 하나의 선언을 통해서 둘 이상의 변수를 선언할 수 있다.
단순히 다수의 변수 선언을 의미하는 것이 아니라, 다수의 변수로는 하기 힘든 작업을 배열을 활용해 쉽게 할 수 있다.
1차원 배열의 선언
별도의 선언 방법이 없으면 변수에 처음 값을 할당할 때 생성
이름 : 프로그램에서 사용할 배열의 이름
손으로 간단한 것 부터 많이 그려보기!
적절한 인덱스를 사용하고 있는지 확인
1차원 배열의 접근

배열활용예제 : gravity
상자가 쌓여있는 방이 있다. 방이 오른쪽으로 90도 회전하여 상자들이 중력의 영향을 받아 낙하한다고 할 때, 낙차가 가장 큰 상자를 구하여 그 낙차를 리턴하는 프로그램을 작성하시오.
중력은 회전 완료된 후 적용된다.
상자들은 모두 한쪽 벽면에 붙여진 상태로 쌓여 2차원의 형태를 이루며 벽에서 떨어져서 쌓인 상자는 없다.
상자의 가로, 세로 길이는 각각 1이다.
방의 가로 길이는 100이며, 세로 길이도 항상 100이다.
즉 상자는 최소 0, 최대 100 높이로 쌓을 수 있다.
상자가 놓인 가로 칸 수의 N, 다음 줄에 각 칸의 상자 높이가 주어진다.
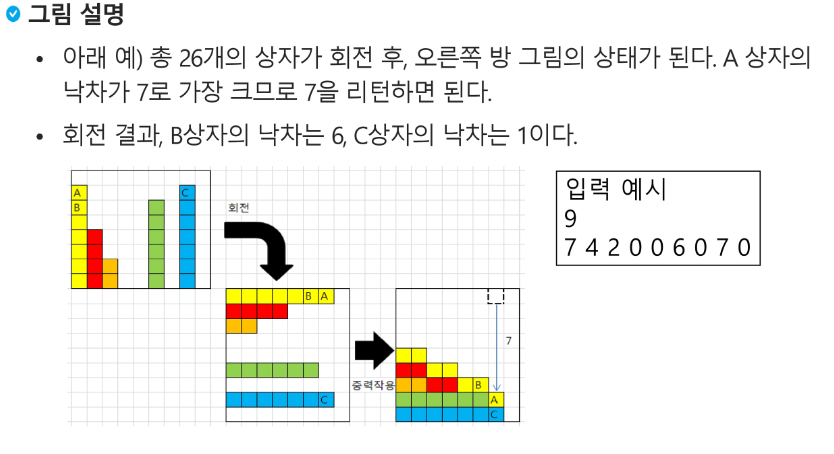
실제로 떨어진 칸수 = 자기 오른쪽 칸들 중 해당 칸보다 작은 얘들의 숫자를 세면 됨
정렬
2개 이상의 자료를 특정 기준에 의해 작은 값부터 큰 값(오름차순), 그 반대의 순서대로 (내림차순) 재배열하는 것
키
- 자료를 정렬하는 기준이 되는 특정 값
N = int(input()) # 상자가 쌓여 있는 가로 길이
arr = list(map(int, input().split())) # ' '공백 표시 꼭 넣을 필요 없음 (오히려 오류 발생 확률 높아짐)
# arr input().split() 이렇게 작성하면 숫자가 인덱스 형태로 입력됨
max_v = 0 # 가장 큰 낙차 (구하고자 하는 값)
for i in range(0, N-1): # i는 낙차를 구할 위치
cnt = 0 # 오른쪽에 더 낮은 높이의 갯수
for j in range(i+1,N): # i 와 비교하기 위해 지정한 범위
if arr[i] > arr[j] : # 오른쪽에 있는 값들보다 작으면
cnt += 1
if max_v < cnt : # 현재의 낙차가 최대 낙차가 크면
max_v = cnt
print(max_v)
대표적인 정렬 방식의 종류
-
버블 정렬(Bubble Sort)
-
카운팅 정렬 (Counting Sort)
-
선택 정렬 (Selection Sort)
-
퀵 정렬 (Quick Sort)
-
삽입 정렬 (Insertion Sort)
-
병합 정렬 (Merge Sort)
APS 과정을 통해 자료구조와 알고리즘을 학습하면서 다양한 형태의 정렬을 학습하게 된다.
버블 정렬(Bubble Sort)
인접한 두개의 원소를 비교함 자리를 계속 교환하는 방식
정렬 과정
-
첫 번째 원소부터 이넙한 원소끼리 계속 자리를 교환하면서 맨 마지막 자리까지 이동한다.
-
한 단계가 끝나면 가장 큰 원소가 마지막 자리로 정렬된다.
-
교환하며 자리를 이동하는 모습이 물 위에 올라오는 거품 모양과 같다고 하여 버블정렬이라고 한다.

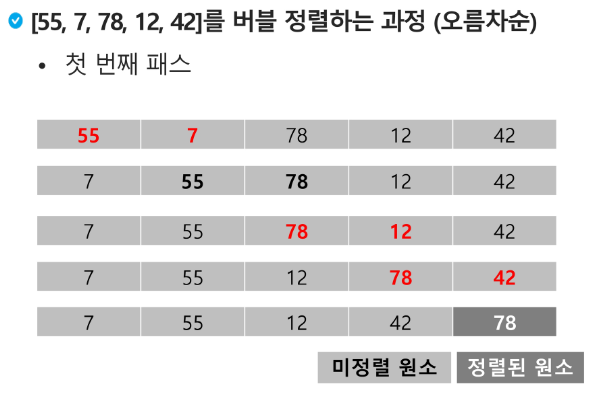



배열을 활용한 버블 정렬
- 앞서 살펴 본 정렬 과정을 코드로 구현하면 아래와 같다. (오름차순)


N = 6
arr = [7, 2, 5, 3, 1, 4]
for i in range(N-1, 0, -1): # for i : N-1 -> 1정렬할 구간의 마지막 인덱스 (감소하는 for문)
for j in range(i): # for j L 0 -> i-1 j는 비교할 두 원소 중 왼쪽의 인덱스
if arr[j] > arr[j+1]: # 오름차순일 경우 큰 수를 오른 쪽으로 보냄
arr[j], arr[j+1] = arr[j+1], arr[j]
print(arr)
카운팅 정렬(Counting Sort)
항목들을 순서대로 결정하기 위해 집합에 각 항목이 몇 개씩 있는지 세는 작업을 하여, 선형 시간에 정렬하는 효율적인 알고리즘
제한사항
-
정수나 정수로 표현할 수 있는 자료에 대해서만 적용 가능 : 각 항목의 발생 회수를 기록하기 위해, 정수 항목으로 인덱스 되는 카운트들의 배열을 사용하기 때문이다.
-
카운트들을 위한 충분한 공간을 할당하려면 집합 내의 가장 큰 정수를 알아야 한다.

