❄️ 스프링 배치
사전적 의미의 "배치"는 일정 시간 동안 대량의 데이터를 한 번에 처리하는 방식입니다.
대비되는 것으로는 "실시간 처리"로 우리가 웹에서 경험하고 있는 페이지 응답, 유저 정보 응답 처리 같은 것입니다. 배치는 한달, 일년에 한번 대량의 데이털르 모아서 한번에 계산하고 저장하는 방식입니다.
만약 10만개의 데이터를 복잡한 JOIN을 걸어 DB간 이동시키는 도중 프로그램이 멈춰버리면 처음부터 다시 시작할 수 없기 때문에 작업 지점을 기록해야 합니다. -> 어디까지 동작했고 다시 시작할 때 새당 지점부터 시작할 수 있도록 할 수 있습니다.
급여나 은행 이자 시스템의 경우 어제 실행한 배치에서 이어서 하지 않고 다시 실행하게 되면 이자가 중복해서 나가기 때문에 문제가 생기기 때문에 어제자 파라미터에 대해서 오늘 것으로 해서 이어서 하도록 배치 프레임워크를 사용하여 처리합니다.
🔻 프레임워크를 사용하는 이유
아주 많은 데이터를 처리하는 중간에 프로그램이 멈출 수 있는 상황을 대비해 안전 장치를 마련하기 위해 배치 프레임워크를 사용합니다.
또한, 운영 로직에만 집중해서 프로그램을 만들 수 있기 때문에 프레임워크를 사용합니다.
🔻 구현
서로 다른 DB를 연결해서 메타 테이블 DB / 운영 테이블 DB 자체를 분리
운영 테이블에서 특정한 데이터를 처리할 때 테이블에서 테이블로 데이터 이동시키는 테이블 간 배치, 엑셀을 불러와서 엑셀에서 테이블로 옮기는 배치, 웹에서 데이터 불러와 테이블에 남기는 배치에 대한 구현을 시작.
주기적으로 실행이 돼야 하므로 스케쥴(크론식), 주기적이 아닌 내가 원할 때인 웹 핸들 기반 실행
🔻 버전
Spring Boot 3.3.1
Spring Batch 5.X
Spring Data JPA - MySQL
JDBC API - MySQL
Lombok
Gradle-Groovy
Java 17 ~
❄️ 스프링 배치 동작
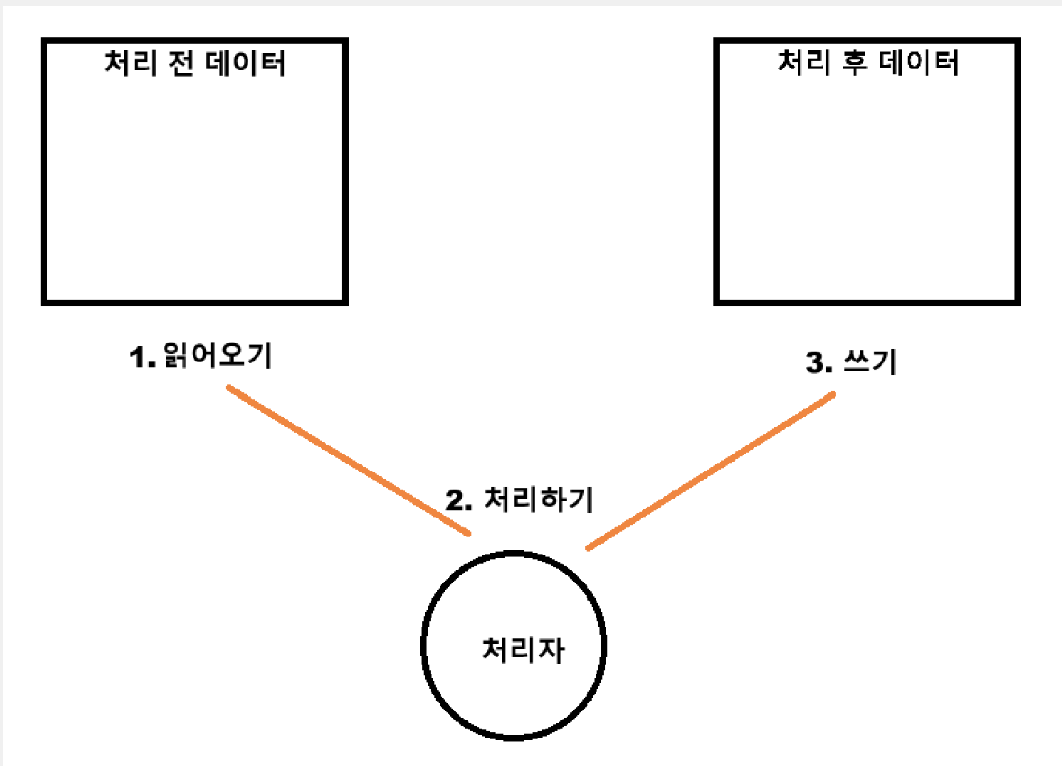
처리 전과 후의 데이터는 하나의 테이블을 가리킬 수도 있고 다른 테이블에서 관리할 수도 있습니다.
배치를 처리하기 위해서는 데이터를 효율적으로 빠르게 처리하는 것도 중요하지만 내가 하고 있는 작업을 어디까지 했는지 계속 파악해야 한다는 점과 이미 했던 일을 중복하지 않게 파악해야 한다는 점입니다.
이러한 놓치는 부분 파악을 위해 "기록"이 중요합니다.
🔻 배치의 흐름
배치는 데이터를 읽어오고 처리하고 쓰는 과정을 읽어올 데이터가 존재하지 않을 때까지 반복합니다.
한번에 모든 데이터를 읽어오지 않는 이유는 한번에 많은 양의 데이터를 메모리에 적재하지 못하거나 처리 실패의 위험성이 존재하기 때문에, 속도 면에서도 문제가 발생하기 때문입니다. 그래서 처리할 수 있는 데이터 양만큼 끊어서 처리합니다.
반복 작업을 기록하기 위해서는 메타 데이터가 필요합니다. 메타 데이터 테이블을 만들어 내가 어디까지 했고 어느 작업이 끝이 났는지 기록이 필요합니다.
🔻 스프링 배치 내부 구조도
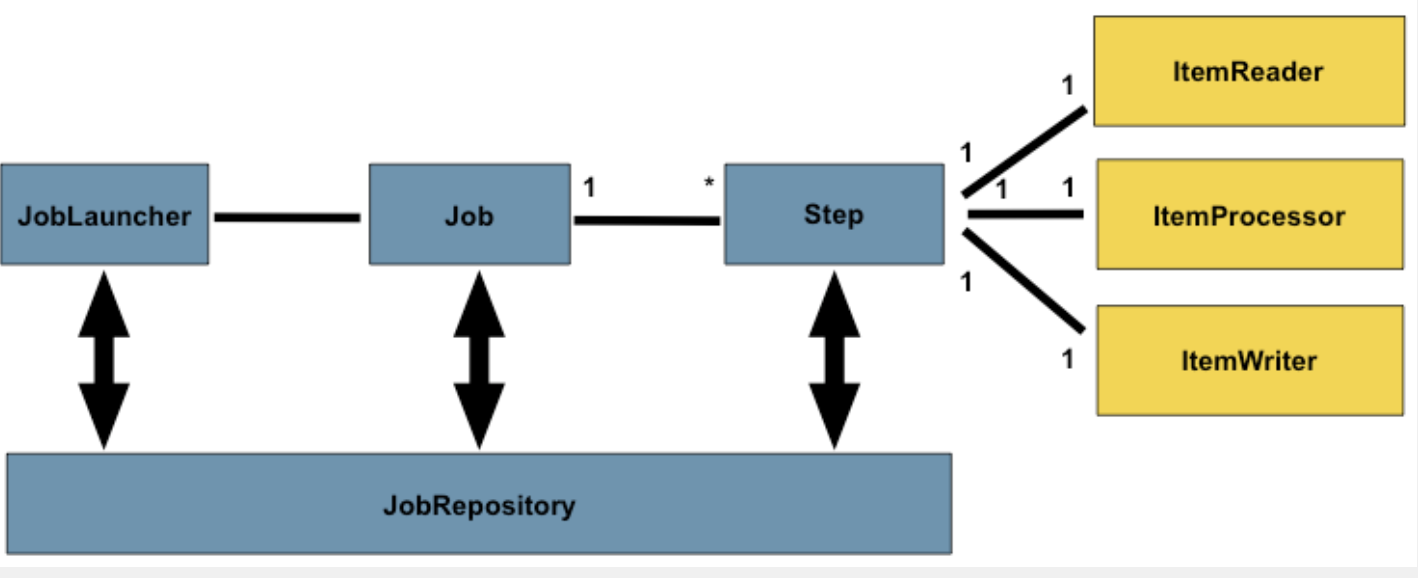
JobLauncher : 하나의 배치 작업을 실행시키는 시작점이라고 생각하면 됩니다. 웹 엔드포인트로 URL이 있는 컨트롤러에서 요청하면 이것을 가지고 배치 작업을 시작하고 스케쥴러에 등록하면 주기적으로 작업을 실행할 수 있도록 할 수 있습니다.
Job : JobLauncher를 시작하면 그에 해당하는 배치 작업이 실행되는데 이 배치 작업을 Job이라고 합니다. Job 안에는 세부적인 분류체계가 있는데 N개의 Steps가 있습니다. 이 Steps가 실제로 읽어오고 처리하고 쓰는 과정을 담당합니다
JobRepository : 배치가 동작하면서 어디까지 실행했는지를 저장하는 곳입니다. JobRepository가 계속 참조하여 메타 테이블에 저장합니다. 메타 테이블은 따로 DB에 구성해두면 JobRepository가 계속 실행 흐름을 읽어서 메타 테이블에 저장합니다.
🔻 배치 자동 실행 방지
spring.batch.job.enabled=false
스프링 배치는 1개의 배치 작업에 대해 프로젝트를 실행하면 자동으로 배치 작업이 가동되기 때문에 해당 과정을 막아야 합니다.
❄️ 2개의 데이터베이스 연결
실무에서는 메타데이터를 저장할 메타 데이터 테이블과 실제 배치를 처리할 배치 테이블이 서로 다른 DB에 저장되어 있는 경우가 많습니다.
spring:
# jdbc 의존성을 받았다면 url을 jdbc-url로 작성
datasource-meta:
jdbc-url: jdbc:mysql://localhost:3306/firstDB?useSSL=false&useUnicode=true&serverTimezone=Asia/Seoul&allowPublicKeyRetrieval=true
username: root
password: 12341234
driver-class-name: com.mysql.cj.jdbc.Driver
datasource-data:
jdbc-url: jdbc:mysql://localhost:3306/secondDB?useSSL=false&useUnicode=true&serverTimezone=Asia/Seoul&allowPublicKeyRetrieval=true
username: root
password: 12341234
driver-class-name: com.mysql.cj.jdbc.Driver스프링 부트에서 2개 이상의 DB를 연결하려면 Config 클래스를 필수적으로 작성해야 하며, 충돌ㅇ르 방지하여 우선 순위를 위해 @Primary config를 설정해야 합니다.
메타 데이터 테이블은 @Primary로 잡혀있는 DB 소스에 생성됩니다.
❄️ DB 연결 config 파일
2개 이상의 DB를 연결하려면 Config 클래스를 필수적으로 작성해야 하며, 충돌을 방지하여 우선 순위를 설정합니다.
@Configuration
public class MetaDBConfig {
@Bean
@Primary // DB 충돌 방지
@ConfigurationProperties(prefix = "spring.datasource-meta") // application.yml에 있는 변수 설정값을 자동으로 불러올 수 있는 애노테이션
public DataSource metaDBSource() {
return DataSourceBuilder.create().build();
}
@Primary
@Bean
public PlatformTransactionManager metaTransactionManager() {
return new DataSourceTransactionManager(metaDBSource());
}
} @Configuration
@EnableJpaRepositories( // basePackages의 경우 DataDBConfig가 어떤 패키지에 대해서 동작하는지 세팅이 필요합니
basePackages = "com.example.springessentialguide.repository",
entityManagerFactoryRef = "dataEntityManager", // 메서드명을 지정
transactionManagerRef = "dataTransactionManager"
)
public class DataDBConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource-data")
public DataSource dataDBSource() {
return DataSourceBuilder.create().build();
}
/**
* 엔티티를 관리할 매니저
*/
@Bean
public LocalContainerEntityManagerFactoryBean dataEntityManager() {
// JPA를 사용하기 위해 엔티티 매니저 팩토리 빈을 생성
LocalContainerEntityManagerFactoryBean em = new LocalContainerEntityManagerFactoryBean();
// 데이터베이스 소스를 설정
// dataEntityManager() 메서드는 데이터베이스 연결을 위한 데이터 소스를 반환해야 합니다.
em.setDataSource(dataDBSource());
// 엔티티들이 모여질 패키지 등록 -> JPA가 엔티티 클래스를 찾을 패키지를 지정합니다.
em.setPackagesToScan(new String[]{"com.example.springessentialguide.entity"});
// JPA의 구현체로 Hibernate를 사용하도록 설정, HibernateJpaVendorAdapter는 Hibernate에 특화된 설정을 제공
em. setJpaVendorAdapter(new HibernateJpaVendorAdapter());
HashMap<String, Object> properties = new HashMap<>();
properties.put("hibernate.hbm2ddl.auto", "update"); // 데이터베이스 스키마를 관리
properties.put("hibernate.show_sql", "true"); // SQL 쿼리를 콘솔에 출력하도록 설정
em.setJpaPropertyMap(properties);
return em;
}
@Bean
public PlatformTransactionManager dataTransactionManager() {
JpaTransactionManager transactionManager = new JpaTransactionManager();
transactionManager.setEntityManagerFactory(dataEntityManager().getObject());
return transactionManager;
}
}❄️ 메타 테이블
메타 데이터 테이블은 배치에서 중요한 작업에 대한 트래킹을 수행하는 테이블로, 스프링 배치에서도 메타 데이터를 관리해야 합니다.
보통은 DB 테이블에 저장하며, application.yml 변수 설정 시 @Primary로 설정한 테이블에 테이블을 자동으로 생성할 수 있습니다.
🔻 yml에서 메타데이터 테이블 생성 설정
spring:
batch:
jdbc:
initialize-schema: always
schema: classpath:org/springframework/batch/core/schema-mysql.sqlinitialize-schema 는 해당 베치 테이블을 생성할 것인지 여부로 always라면 스프링 배치에 의해 해당 배치 메타 데이터 테이블이 생성됩니다.
schema는 어떤 DB를 사용할 것인지를 정한 것입니다.
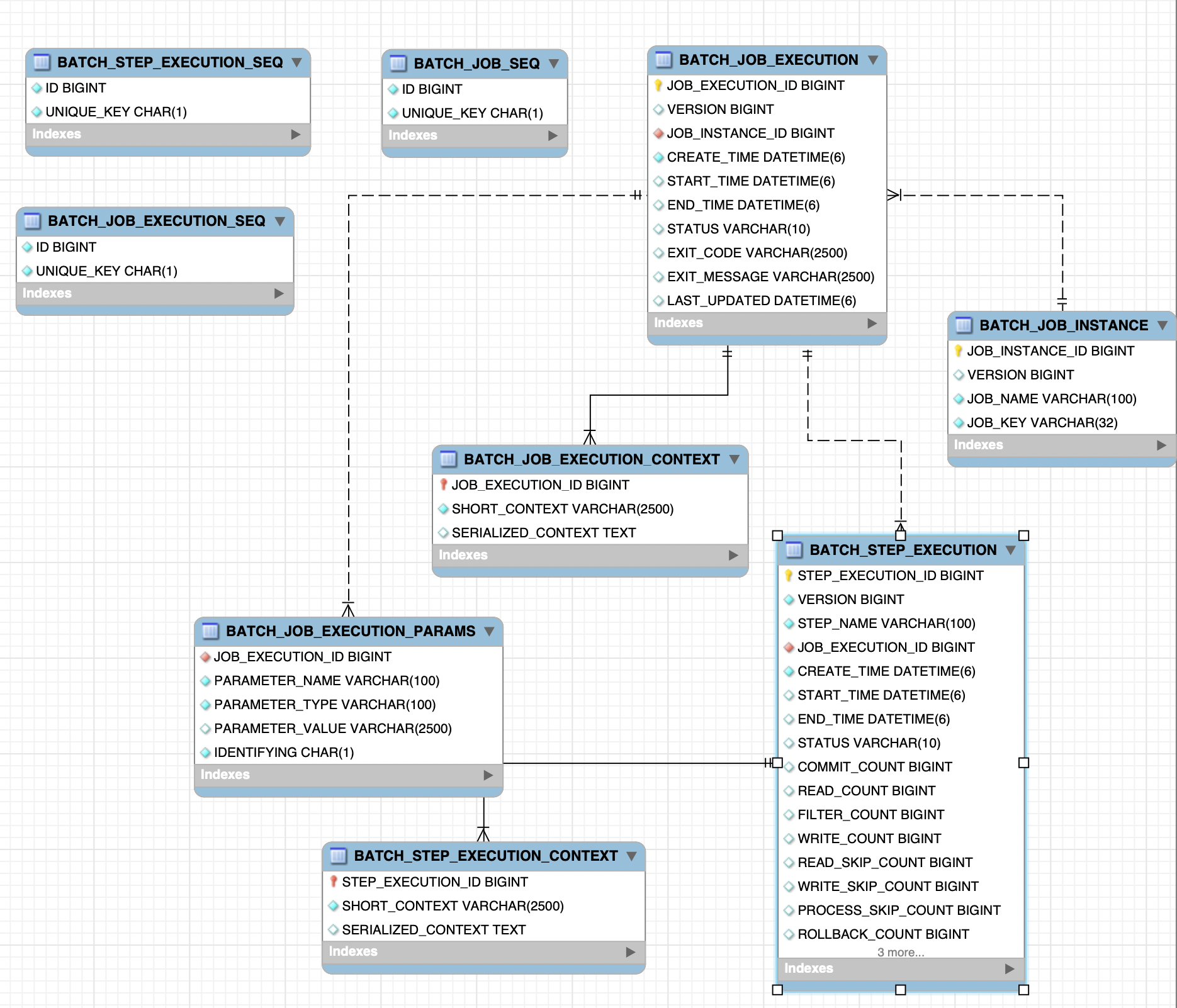
생성한 메타 데이터 테이블의 ERD입니다.
❄️ 기초 테이블 간 데이터 이동 (잘 사용 X)
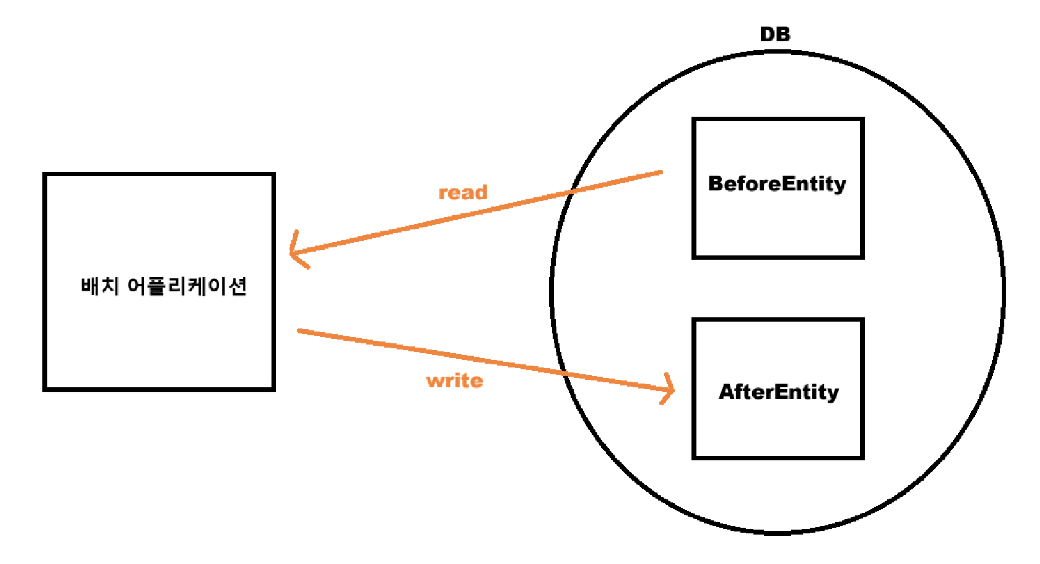
하나의 DB 안에서 BeforeEntity라는 데이터를 읽어들여서 AfterEntity라는 데이터에 복사하는 데이터 복제를 한 작업입니다.
먼저 BeforeEntity와 AfterEntity를 생성하고 BeforeEntity에 데이터를 삽입했습니다.
스프링 배치 그림에서 본 것처럼 JobLauncher를 통해 배치를 시작하고 작업을 진행하여 JobRepository가 메타 데이터 테이블에 계속 접근하여 해당 작업이 얼마만큼 진행되었는지 참조합니다.
이제 배치 Job을 정의할 클래스를 생성하고 Job 메서드를 등록해야 합니다.
@Configuration
@RequiredArgsConstructor
public class FirstBatch {
private final JobRepository jobRepository;
private final PlatformTransactionManager platformTransactionManager;
private final BeforeRepository beforeRepository;
private final AfterRepository afterRepository;
// Job 메서드
@Bean
public Job firstJob() {
System.out.println("first job");
// 두 번째 인자 값으로 해당 작업에 대해 트래킹을 하기 위해 스프링 배치가 알아서 작업이 진행 됐는지 안 됐는지를 본다.
return new JobBuilder("firstJob", jobRepository)
.start() // Step이 들어갈 자리
.build();
}
}🔻 Step 정의
Job을 정의했으니 실제 배치 처리를 Step에서 수행되도록 해야 합니다.
Step에서는 "읽기 - 처리 - 쓰기" 과정을 구상해야 하며 Step을 등록하기 위한 @Bean을 등록합니다.
@Bean
public Step firstStep() {
System.out.println("first step");
return new StepBuilder("firstStep", jobRepository)
.<BeforeEntity, AfterEntity> chunk(10, platformTransactionManager)
.reader(읽는메소드자리) // beforeReader()로 교체
.processor(처리메소드자리)
.writer(쓰기메소드자리)
.build();
}chunk 메서드
대량의 데이터를 부분부분 끊어서 읽어들일 단위를 정해주는 메서드입니다.
위 코드에서는 10개씩 끊어서 Step 과정으로 처리합니다.
chunk 단위를 너무 작게하면 I/O처리가 많아지고 오버헤드 발생합니다.
너무 크게하면 적재 및 자원 사용에 대한 비용과 실패시 부담이 커집니다.
그래서 데이터의 수량과 하드웨어의 성능을 보고 적당량 단위로 세팅해야 합니다.
🔻 Read 메서드
Step에서 Read 메서드로 BeforeEntity 테이블에서 읽어오는 메서드입니다.
@Bean
public RepositoryItemReader<BeforeEntity> beforeReader() {
return new RepositoryItemReaderBuilder<BeforeEntity>()
.name("beforeReader")
.pageSize(10)
.methodName("findAll")
.repository(beforeRepository)
.sorts(Map.of("id", Sort.Direction.ASC))
.build();
}🔻 Process 메서드
읽어온 데이터를 처리하는 메서드
@Bean
public ItemProcessor<BeforeEntity, AfterEntity> middleProcessor() {
return new ItemProcessor<BeforeEntity, AfterEntity>() {
@Override
public AfterEntity process(BeforeEntity item) throws Exception {
AfterEntity afterEntity = new AfterEntity();
afterEntity.setUsername(item.getUsername());
return afterEntity;
}
};
}🔻 Write 메서드
AfterEntity에 처리한 결과를 저장하는 Writer
@Bean
public RepositoryItemWriter<AfterEntity> afterWriter() {
return new RepositoryItemWriterBuilder<AfterEntity>()
.repository(afterRepository)
.methodName("save")
.build();
}애플리케이션 실행해도 배치 작업 실행 안됨
yml에서 batch.job.enabled=false 로 했기 때문입니다. 그 이유는 단순하게 애플리케이션을 실행했다고 해서 해당 배치가 실행되버리면 내가 원하지 않은 때에 잘못 돌아갈 수 있습니다.
그래서 URL 요청을 통해서 또는 스케쥴러를 통해 배치가 실행되도록 할 것입니다.
❄️ 실행 및 스케쥴
정의한 Job을 실행시키기 위한 구현입니다.
JobRegistry : 빈으로 등록해둔 특정 배치를 가지고 올 수 있는 것
jobParameters : 파라미터로 job이 특정 일자나 번호를 가지고 실행될 수 있도록 해줌.
특정 일자에만 실행되고 이미 실행한 일자를 넣었다면 실행을 막을 수 있도록 세팅합니다.
private final JobLauncher jobLauncher;
private final JobRegistry jobRegistry;
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", value)
.toJobParameters();
jobLauncher.run(jobRegistry.getJob("firstJob"), jobParameters);🔻 컨트롤러에서 실행
@RestController
@RequiredArgsConstructor
public class MainController {
private final JobLauncher jobLauncher;
private final JobRegistry jobRegistry;
/**
* 파라미터를 받는 이유는 배칠르 실행시킬 때 특정 일자에만 실행시키고 겹치는 일자에 배치가 들어오면 실행되지 않도록 하기 위함
*/
@GetMapping("/first")
public String firstApi(@RequestParam("value") String value) throws Exception {
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", value)
.toJobParameters();
// callable 과 같은 도구로 비동기 처리가 가능하다고 합니다.
jobLauncher.run(jobRegistry.getJob("firstJob"), jobParameters);
return "ok";
}
}🔻 스케쥴로 실행
@Configuration
@RequiredArgsConstructor
public class FirstSchedule {
private final JobLauncher jobLauncher;
private final JobRegistry jobRegistry;
@Scheduled(cron = "10 * * * * *", zone = "Asia/Seoul") // 10초마다 실행
public void runFirstJob() throws Exception {
System.out.println("first schedule start");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd-hh-mm-ss");
String date = dateFormat.format(new Date());
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", date)
.toJobParameters();
jobLauncher.run(jobRegistry.getJob("firstJob"), jobParameters);
}
}이렇게 하면 매 10초마다 BeforeEntity에 있는 데이터가 AfterEntity로 복제가 됩니다. 실제로 MySQL에서 truncate AfterEntity한 뒤에 다시 select * from AfterEntity; 를 하면 데이터가 다시 복제가 됩니다.
truncate - 모든 행 삭제
하지만 Date를 계속 new로 해서 찍어주면 매번 새롭게 새로운 날짜에 실행되므로 커스텀이 필요합니다.
해당 배치가 특정 조건만 갖춰서 파라미터를 받아서 실행될 수 있도록 JobParameter를 구성해야 합니다.
JobLauncher로 Job 실행시 JobParameter를 주는 이유
실행한 작업에 대한 일자, 순번등을 부여해 동일한 일자에 대한 작업의 수행 여부를 확인하여 중복 실행 및 미실행을 예방할 수 있습니다.
❄️ 테이블 조건
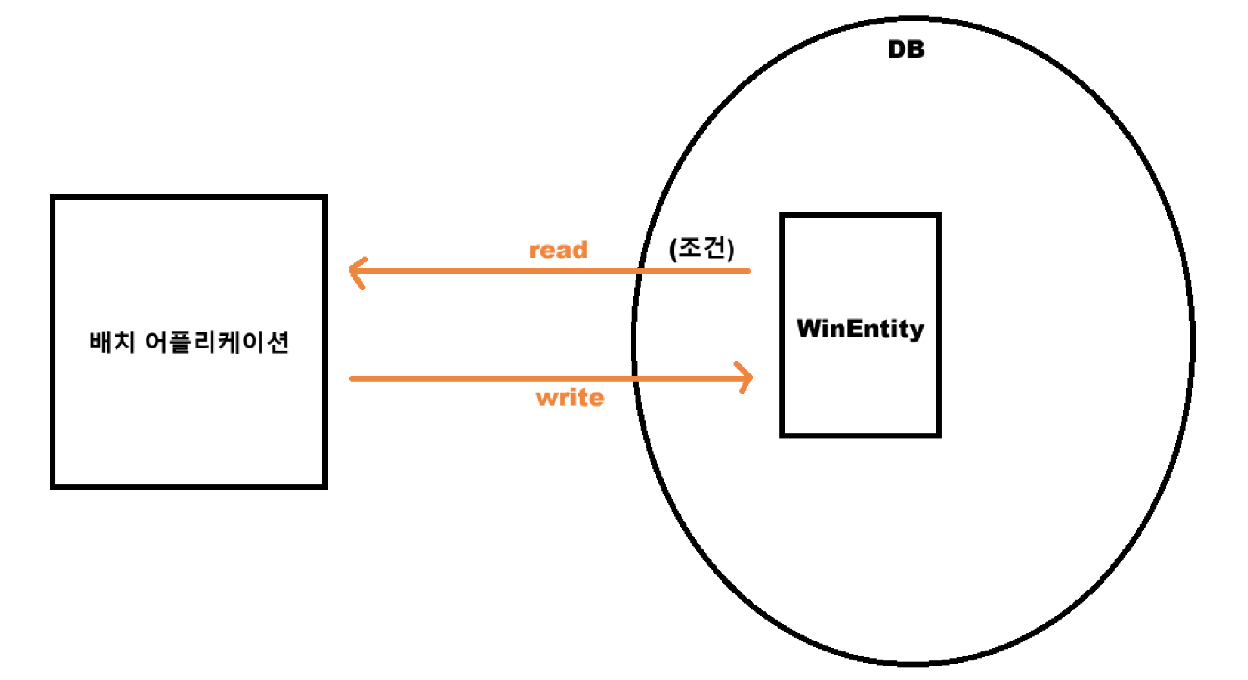
이번에는 하나의 테이블에서 조건을 통해 데이터를 읽은 후 데이터를 변경하고 다시 테이블에 저장하는 작업입니다.
모든 데이터가 아닌 where 로 조건을 주어 특정 데이터만 읽어들이고 처리해서 Write 하는 배치입니다.
"win"이라는 컬럼값이 10을 넘으면 "reward" 컬럼에 true 값을 줄 것입니다.
ex)한 달에 한 번씩 배치를 돌려 유저의 특정 조건이 만족한다면 보상을 주는 것과 같은 작업
이전에 했던 작업과는 다른 배치이므로 새로 Job 을 정의할 클래스 생성과 Job 메서드를 등록해야 합니다.
@Repository
public interface WinRepository {
Page<WinEntity> findByWinGreaterThanEqual(Long win, Pageable pageable);
}나머지는 이전 것과 같지만 Repository에서 정의한 조건만 추가해주면 됩니다. ```java @Repository public interface WinRepository { Page findByWinGreaterThanEqual(Long win, Pageable pageable); } ```
// Read 작업
@Bean
public RepositoryItemReader<WinEntity> winReader() {
return new RepositoryItemReaderBuilder<WinEntity>()
.name("winReader")
.pageSize(10)
.methodName("findByWinGreaterThanEqual") // Repository에서 만들어준 것으로 설정
.arguments(Collections.singletonList(10L)) // 조건 -> 여기서 정의해준 10보다 같거나 같을 경우
.repository(winRepository)
.sorts(Map.of("id", Sort.Direction.ASC))
.build();
}🔻 데이터 처리
"win"이라는 컬럼이 10보다 같거나 클 때 보상을 주기로 했으므로 set을 설정해줍니다.
@Bean
public ItemProcessor<WinEntity, WinEntity> trueProcessor() {
return item -> {
item.setReward(true);
return item;
};
}❄️ 영속성별 구현법
현재까지 JPA를 사용했는데 스프링 배치에서는 일반 소스 JDBC 쿼리들이 성능이 저조하게 됩니다.
다양한 테이블로 데이터를 복제시키는 것이 작성하기 힘들기도 합니다.
그래서 주로 JDBC를 사용합니다.
JDBC에는 cursor 방식과 paging 방식이 있습니다
cursor 방식은 데이터베이스 자체의 cursor를 사용하여 전체 테이블에서 cursor가 한 칸씩 이동하여 데이터를 가져옵니다.
@Bean
public JdbcCursorItemReader<CustomerCredit> itemReader(DataSource dataSource) {
String sql = "select ID, NAME, CREDIT from CUSTOMER";
return new JdbcCursorItemReaderBuilder<CustomerCredit>().name("customerReader")
.dataSource(dataSource)
.sql(sql)
.rowMapper(new CustomerCreditRowMapper())
.build();
}paging 방식은 데이터를 묶음 방식으로 페이지 처리, limit 처리해서 가져옵니다.
성능 상으로는 paging 방식이 더 좋다고 합니다.
@Bean
@StepScope
public JdbcPagingItemReader<CustomerCredit> itemReader(DataSource dataSource,
@Value("#{jobParameters['credit']}") Double credit) {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("statusCode", "PE");
parameterValues.put("credit", credit);
parameterValues.put("type", "COLLECTION");
return new JdbcPagingItemReaderBuilder<CustomerCredit>().name("customerReader")
.dataSource(dataSource)
.selectClause("select NAME, ID, CREDIT")
.fromClause("FROM CUSTOMER")
.whereClause("WHERE CREDIT > :credit")
.sortKeys(Map.of("ID", Order.ASCENDING))
.rowMapper(new CustomerCreditRowMapper())
.pageSize(2)
.parameterValues(parameterValues)
.build();
}@Bean
public JdbcBatchItemWriter<CustomerCredit> itemWriter(DataSource dataSource) {
String sql = "UPDATE CUSTOMER set credit = :credit where id = :id";
return new JdbcBatchItemWriterBuilder<CustomerCredit>().dataSource(dataSource)
.sql(sql)
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.assertUpdates(true)
.build();
}Write의 경우에는 JdbcBatchItemWriter 를 통해서 UPDATE, INSERT 쿼리를 날리면 수행됩니다.
추가로 MongoDB나 다른 DB를 사용한다면 샘플을 통해서 확인하도록 합니다.
🖇️ 스프링 배치 MongoDB
🖇️ 스프링 배치 여러 샘플들
❄️ 엑셀 to 테이블
이번에는 엑셀 파일의 한 시트에서 데이터를 가져와 데이터베이스 테이블로 이동시키는 일입니다.
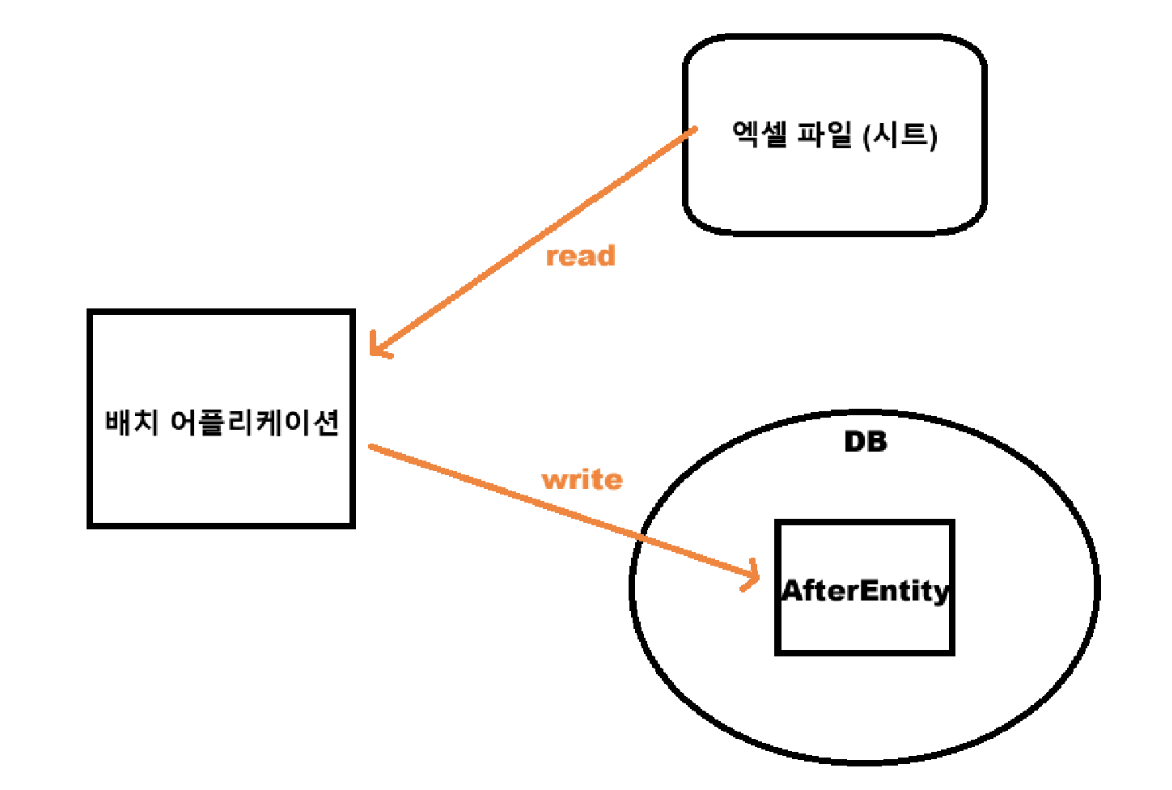
행 단위로 데이터를 모두 읽어와서 배치 애플리케이션에서 처리를 진행하고 DB에 있는 AfterEntity를 쓰는 과정입니다.
엑셀 시트를 다룰 수 있는 의존성이 필요합니다.
implementation 'org.apache.poi:poi-ooxml:5.3.0
그리고 엑셀 파일에서 시트를 정의해줘야 합니다. (엑셀 파일 가서 이것저것 작성해놓으면 됨)
똑같이 Job을 정의합니다.
@Configuration
@RequiredArgsConstructor
public class FourthBatch {
private final JobRepository jobRepository;
private final PlatformTransactionManager platformTransactionManager;
private final AfterRepository afterRepository;
@Bean
public Job fourthJob() {
System.out.println("fourth job");
return new JobBuilder("fourthJob", jobRepository)
.start(fourthStep())
.build();
}
@Bean
public Step fourthStep() {
return new StepBuilder("fourthStep", jobRepository)
.<Row, AfterEntity> chunk(10, platformTransactionManager)
.reader(excelReader())
.processor(fourthProcessor())
.writer(fourthAfterWriter())
.build();
}
@Bean
public ItemStreamReader<Row> excelReader() {
try {
return new ExcelRowReader("/Users/bagsang-u/Desktop/무제.xlsx");
//리눅스나 맥은 /User/형태로
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}하지만 엑셀을 수행하므로 ItemStreamReader 부분은 수정이 필요합니다.
이후 ExcelRowReader를 정의합니다.
🔻 Read
ItemStreamReader는 각각 4가지의 메서드를 구현해야 합니다. -> open, read, update, close
open : ItemStreamReader가 제일 처음 시작됐을 때 한 번만 실행되는 메서드로 엑셀 파일을 열거나 특정 초기화를 진행하는 메서드입니다.
read : 연 후에 배치가 chunk 단위로 진행될 때 매번 불려지는 메서드입니다. 데이터 각각의 행을 읽어들이는 작업을 합니다.
update : read한 후에 특정 변수 값을 수정하는 작업을 하는 메서드입니다.
close : 배치 작업 끝난 후에 한 번만 불려지는 메서드입니다. 열려있는 파일을 닫는다던지 변수값을 초기화하는 세팅을 합니다.
public class ExcelRowReader implements ItemStreamReader<Row> {
private final String filePath; // 엑셀 파일의 경로를 받을 변수
private FileInputStream fileInputStream; // 해당 경로를 기반으로 파일을 열 객체
private Workbook workbook; // 엑셀 파일을 받을 워크북
private Iterator<Row> rowCursor; // 엑셀 파일 내부 시트에 각각의 행들을 반복할 커서
private int currentRowNumber; // 어디 행까지 수행을 했는지 행번호로 기록할 객체
private final String CURRENT_ROW_KEY = "current.row.number"; // 메타 데이터 테이블에 어떤 행까지 수행했는지 기록할 객체
public ExcelRowReader(String filePath) throws IOException {
this.filePath = filePath;
this.currentRowNumber = 0;
}
@Override
public void open(ExecutionContext executionContext) throws ItemStreamException {
try {
fileInputStream = new FileInputStream(filePath); // 엑셀 파일 열기
workbook = WorkbookFactory.create(fileInputStream);
Sheet sheet = workbook.getSheetAt(0); // 첫번째 엑셀 시트를 가져옴
this.rowCursor = sheet.iterator(); // 각각의 행을 반복하도록 세팅
// 이미 동일한 배치 처리를 했다거나 일부분만 처리를 했을 경우 메타 데이터 테이블에 동일한 배치와 파라미터를 가지고
// 특정 키인 CURRENT_ROW_KEY라는 어떤 행까지 진행했는지에 대한 변수가 있으면 가져옵니다. 중복 처리를 하지 않기 위함입니다.
// 동일 배치 파라미터에 대해 특정 키 값 "current.row.number"의 값이 존재한다면 초기화
if (executionContext.containsKey(CURRENT_ROW_KEY)) {
currentRowNumber = executionContext.getInt(CURRENT_ROW_KEY);
}
// 위의 값을 가져와 이미 실행한 부분은 건너 뜀
for (int i = 0; i < currentRowNumber && rowCursor.hasNext(); i++) {
rowCursor.next();
}
} catch (IOException e) {
throw new ItemStreamException(e);
}
}
@Override
public Row read() {
if (rowCursor != null && rowCursor.hasNext()) {
currentRowNumber++; // 어디 행까지 수행을 했는지 행번호로 기록할 객체
return rowCursor.next();
} else {
return null;
}
}
@Override
public void update(ExecutionContext executionContext) throws ItemStreamException {
executionContext.putInt(CURRENT_ROW_KEY, currentRowNumber);
}
@Override
public void close() throws ItemStreamException {
try {
if (workbook != null) {
workbook.close();
}
if (fileInputStream != null) {
fileInputStream.close();
}
} catch (IOException e) {
throw new ItemStreamException(e);
}
}
}🔻 Process와 Write
/**
* Row 형태로 불러들인 데이터를 AfterEntity로 변환한 과정입니다.
* @return
*/
@Bean
public ItemProcessor<Row, AfterEntity> fourthProcessor() {
return new ItemProcessor<Row, AfterEntity>() {
@Override
public AfterEntity process(Row item) {
AfterEntity afterEntity = new AfterEntity();
afterEntity.setUsername(item.getCell(0).getStringCellValue());
return afterEntity;
}
};
}
@Bean
public RepositoryItemWriter<AfterEntity> fourthAfterWriter() {
return new RepositoryItemWriterBuilder<AfterEntity>()
.repository(afterRepository)
.methodName("save")
.build();
}이제 컨트롤러에서 호출하면 id와 username으로 AfterEntity에 저장되는 것을 확인할 수 있습니다.
ItemStreamReader에서 엑셀 파일은 언제 열리고 언제 닫힐까?
처음open메서드에서 파일이 열리도록 세팅하는 이유는 매번 Read에서 chunk 단위로 파일이 열리고 닫히면 오버헤드가 발생하거나 CPU 성능적으로 문제가 발생할 수 있습니다.
그래서open()에서 파일을 한번 열어두고 각각의 read에서는 이미 열린 파일에 대해서 행 부분을 나눠서 읽도록 세팅합니다.
- 파일이 열리고 닫히는 것은 컴퓨터 자원에 부하를 주기 때문에 구현 시 고민이 필요.
엑셀 파일에서 데이터를 읽다가 프로그램이 멈춘다면, 다시 실행 했을때 중단점부터 해당 작업을 수행할 수 있도록 ExecutionContext에서 관리할 수 있도록 하는 부분도 중요합니다.
배치의 메타 데이터 테이블에 특정 변수에 대해서 값을 계속 기록해야 합니다. 이 과정을 할 수 있는 곳이ExecutionContext입니다. -> update()에 있습니다.
❄️ 테이블 to 엑셀
@Bean
public RepositoryItemReader<BeforeEntity> fifthBeforeReader() {
RepositoryItemReader<BeforeEntity> reader = new RepositoryItemReaderBuilder<BeforeEntity>()
.name("beforeReader")
.pageSize(10)
.methodName("findAll")
.repository(beforeRepository)
.sorts(Map.of("id", Sort.Direction.ASC))
.build();
// 전체 데이터 셋에서 어디까지 수행 했는지의 값을 저장하지 않음
reader.setSaveState(false);
return reader;
}기존과는 다르게 reader라는 변수를 만들어서 리턴해줬습니다.
데이터를 읽어들여서 엑셀에 저장을 해야 하는데 배치가 실패할 경우 다시 첫번째부터 시작을 해야 하므로 어디까지 수행을 했는지에 대한 기록을 하지 못하도록 해야 합니다.
그래서 reader.setSaveState() 를 false로 합니다.
만약 새로 엑셀 파일을 생성하는 것이 아닌 기존에 있던 파일에 데이터를 추가한다고 하면 상황에 따라서 true로 하거나 reader.setSaveState()를 없애면 됩니다.
Process와 Write
// BeforeEntity 타입으로 받아온 데이터를 BeforeEntity로 형태로 리턴해주면 됩니다.
@Bean
public ItemProcessor<BeforeEntity, BeforeEntity> fifthProcessor() {
return item -> item;
}
@Bean
public ItemStreamWriter<BeforeEntity> excelWriter() {
try {
return new ExcelRowWriter("/Users/bagsang-u/Desktop/무제.xlsx");
//리눅스나 맥은 /User/형태로
} catch (IOException e) {
throw new RuntimeException(e);
}
}🔻 ExcelRowWriter
ItemStreamWriter에는 open, write, close가 있습니다.
open은 한번만 실행되는 메서드로 엑셀 파일을 생성하거나 값을 초기화하도록 세팅합니다.
write는 매 chunk마다 데이터가 write되도록 하는 메서드입니다. 각각의 행에 접근해서 데이터를 쓰도록 세팅합니다.
close는 배치가 모두 처리되고 난 후에 파일을 닫거나 그동안 사용했던 객체 변수를 초기화하도록 세팅합니다.
public class ExcelRowWriter implements ItemStreamWriter<BeforeEntity> {
private final String filePath; // 데이터 엑셀 파일을 생성할 경로
private Workbook workbook;
private Sheet sheet;
private int currentRowNumber; // 시트 내부에 각각의 행에 대해서 어디까지 데이터를 수행했는지에 대한 번호
private boolean isClosed;
public ExcelRowWriter(String filePath) throws IOException {
this.filePath = filePath;
this.isClosed = false;
this.currentRowNumber = 0;
}
@Override
public void open(ExecutionContext executionContext) throws ItemStreamException {
workbook = new XSSFWorkbook();
sheet = workbook.createSheet("Sheet1");
}
@Override
public void write(Chunk<? extends BeforeEntity> chunk) {
for (BeforeEntity entity : chunk) {
Row row = sheet.createRow(currentRowNumber++);
row.createCell(0).setCellValue(entity.getUsername());
}
}
@Override
public void close() throws ItemStreamException {
if (isClosed) {
return;
}
try (FileOutputStream fileOut = new FileOutputStream(filePath)) {
workbook.write(fileOut);
} catch (IOException e) {
throw new ItemStreamException(e);
} finally {
try {
workbook.close();
} catch (IOException e) {
throw new ItemStreamException(e);
} finally {
isClosed = true;
}
}
}
}또 Controller에서 요청을 보내면 DB의 테이블에 있는 데이터가 엑셀로 넘어가 저장되는 것을 확인할 수 있습니다.
❄️ Step 설정
🔻 Skip
@Bean
public Step sixthStep() {
return new StepBuilder("sixthStep", jobRepository)
.<BeforeEntity, AfterEntity> chunk(10, platformTransactionManager)
.reader(beforeSixthReader())
.processor(middleSixthProcessor())
.writer(afterSixthWriter())
.faultTolerant()
.skip(Exception.class)
.noSkip(FileNotFoundException.class)
.noSkip(IOException.class)
.skipLimit(10)
.build();
}skip은 예외가 발생하면 예외를 특정 수까지 건너 뛸 수 있도록 설정하는 방법입니다.
Step 메서드에 .faultTolerant()를 선언하고 skip 설정을 하면 됩니다.
특정한 예외에 대해서 Skip과 noSkip을 지정하고 .skipLimit()의 경우 10번까지는 예외를 허용할 수 있습니다.
🔻 Retry
Retry는 Step의 과정 중 예외가 발생하여 예외를 특정 수까지 반복할 수 있도록 설정하는 것입니다.
@Bean
public Step sixthStep() {
return new StepBuilder("sixthStep", jobRepository)
.<BeforeEntity, AfterEntity> chunk(10, platformTransactionManager)
.reader(beforeSixthReader())
.processor(middleSixthProcessor())
.writer(afterSixthWriter())
.faultTolerant()
.retryLimit(3)
.retry(SQLException.class)
.retry(IOException.class)
.noRetry(FileNotFoundException.class)
.build();
}🔻 Writer 롤백 제어
특정 예외가 터지면 트랜잭션을 제외해서 트랜잭션이 일어나지 않도록 세팅하는 방법입니다.
@Bean
public Step step1(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("step1", jobRepository)
.<String, String>chunk(2, transactionManager)
.reader(itemReader())
.writer(itemWriter())
.faultTolerant()
.noRollback(ValidationException.class)
.build();
}noRollback()을 설정하여 데이터를 쓰는 과정에서 validation 예외가 터져도 롤백하지 않도록 설정한 것입니다.
🔻 Step listener
@Bean
public StepExecutionListener stepExecutionListener() {
return new StepExecutionListener() {
@Override
public void beforeStep(StepExecution stepExecution) {
StepExecutionListener.super.beforeStep(stepExecution);
}
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
return StepExecutionListener.super.afterStep(stepExecution);
}
};
}
@Bean
public Step sixthStep() {
return new StepBuilder("sixthStep", jobRepository)
.<BeforeEntity, AfterEntity> chunk(10, platformTransactionManager)
.reader(beforeSixthReader())
.processor(middleSixthProcessor())
.writer(afterSixthWriter())
.listener(stepExecutionListener())
.build();
}Step의 실행 전후에 특정 작업을 수행하도록 설정하는 것입니다.
Step이 실행하기 전후에 로그를 남기거나 다음 Step이 준비되었는지, 변수 초기화 등을 세팅할 수 있습니다.
.listener()로 설정할 수 있습니다.
❄️ Job 설정
여러 개의 Step을 구성하게 될 때 조건을 둘 수 있는 방법이 있습니다.
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}.next()를 통해 순차적으로 Step를 실행합니다.
하지만 이전 Step이 실패한다면 연달아 등장하는 Step들 또한 실행되지 않습니다.
🔻 조건에 따른 실행
@Bean
public Job job(JobRepository jobRepository, Step stepA, Step stepB, Step stepC, Step stepD) {
return new JobBuilder("job", jobRepository)
.start(stepA)
.on("*").to(stepB)
.from(stepA).on("FAILED").to(stepC)
.from(stepA).on("COMPLETED").to(stepD)
.end()
.build();
}.on(*)는 FAILED가 응답되든 COMPLETED가 오든 무조건 stepB를 실행해줍니다.
.from()을 통해 stepA가 실패하면 stepC를 수행하고 성공하면 stepD를 수행하도록 할 수 있습니다.
🔻 Job listener
@Bean
public JobExecutionListener jobExecutionListener() {
return new JobExecutionListener() {
@Override
public void beforeJob(JobExecution jobExecution) {
JobExecutionListener.super.beforeJob(jobExecution);
}
@Override
public void afterJob(JobExecution jobExecution) {
JobExecutionListener.super.afterJob(jobExecution);
}
};
}
@Bean
public Job sixthBatch() {
return new JobBuilder("sixthBatch", jobRepository)
.start(sixthStep())
.listener(jobExecutionListener())
.build();
}Job도 실행 전후에 특정 작업을 수행시킬 수 있습니다.
❄️ JPA 성능 문제와 JDBC
스프링 배치 read와 write 부분을 JPA로 구성하면 JDBC 대비 처리 속도가 많이 저하됩니다.
Reader의 경우 큰 영향을 미치지는 않지만 Writer의 경우 많은 영향을 키칩니다.
🔻 Bulk 쿼리 실패
Entity를 보면 IDENTITY로 설정을 해서 1을 증가시킨 값을 저장하게 되는데 여기서 Batch 처리 chunk 단위 bulk insert 수행이 무너지게 됩니다.
JDBC 기반으로 작성하게 된다면 chunk로 설정한 값이 모이게 된다면 bulk 쿼리로 단 1번의 insert가 실행되지만 JPA의 IDENTITY 전략 때문에 Bulk 쿼리 대신 각각의 수만큼 insert가 수행됩니다.
만약 10개 단위로 chunk를 하면 10개를 읽고 처리한 후 한번에 하나의 쿼리로 insert를 수행합니다. 이게 Bulk인데 IDENTITY 전략때문에 10개의 쿼리가 날라갑니다.
따라서 JDBC로 수정했습니다.
RepositoryItemReader -> JdbcPaingItemReader
@Bean
public JdbcPagingItemReader<BeforeEntity> beforeSixthReader() {
return new JdbcPagingItemReaderBuilder<BeforeEntity>()
.name("beforeSixthReader")
.dataSource(dataSource)
.selectClause("SELECT id, username")
.fromClause("FROM BeforeEntity")
.sortKeys(Map.of("id", Order.ASCENDING))
.rowMapper(new CustomBeforeRowMapper())
.pageSize(10)
.build();
}JdbcBatchItemWriter -> JdbcBatchItemWriter
@Bean
public JdbcBatchItemWriter<AfterEntity> afterSixthWriter() {
String sql = "INSERT INTO AfterEntity (username) VALUES (:username)";
return new JdbcBatchItemWriterBuilder<AfterEntity>()
.dataSource(dataSource)
.sql(sql)
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.build();
}