리스트에서 보이는 부분만 렌더링하는 두 가지 방법
개요
지금까지, 대량의 스크롤이 필요한 리스트를 최적화한 경험이 2번 있었다. 한 번은 prismic에서 미리보기 이미지 리스트를 최적화한 것이었고, 다른 한 번은 xnb.js에서 대량의 텍스트 미리보기 컴포넌트를 최적화한 것이었다. 두 프로젝트의 골자는 보이는 것만 렌더링하는 것이었으나, 그 구현체는 사뭇 달랐다.
왜 보이는 요소만 렌더링해야 하나요?
렌더링 성능 최적화에 있다. 브라우저에서 대량의 dom 요소가 렌더링될 때, 각 요소들의 위치를 결정하는 레이아웃 과정을 거친다. 레이아웃 과정은 렌더링되는 엘리먼트가 많을수록, 렌더링할 엘리먼트의 depth가 클수록 소요 시간이 증가한다.
따라서 어떠한 컴포넌트의 렌더링 시간이 길어진다면 엘리먼트가 많아서 그럴 가능성을 의심해야 하며, 렌더링할 엘리먼트의 수를 줄이면 레이아웃 속도를 향상시킬 수 있다. 이 중, 보이지 않는 엘리먼트는 굳이 렌더 트리에 없어도 되지 않는가? 라는 아이디어에서 출발한 것이 보이는 요소 렌더링 기법인 것이다.
Prismic에서 사용한 기법 - 가상 리스트(windowing) 기법
Prismic에서는 windowing 기법을 사용하여 보이는 요소만 렌더링했다. windowing 기법이란 컴포넌트의 스크롤 위치에 따라, 보이는 요소의 범위를 계산하여, 실제 보이는 요소만 dom 트리에 추가하고, 나머지 요소는 렌더링 자체를 하지 않아버리는 기법을 의미한다.
리액트에서 windowing 기법을 구현하는 라이브러리로는 react-window, react-virtualized가 있으나, Prismic의 미리보기 컴포넌트는 이중 폴더 구조 형태의 리스트로 구성되어 있기에, 좀더 높은 자유도를 위해 직접 구현하였다.
windowing 기법의 구현 원리
가상 리스트 기법은 다음의 원리로 구현된다.
- 사용자가 scroll 이벤트를 발생시킨다. 컨테이너 컴포넌트의 scrollHeight 요소를 기반으로 렌더링할 요소를 결정한다. (react에서는 여기서 state를 변경하는 방식으로 리렌더링을 유발한다.)
- 수학을 이용하여 렌더링할 요소의 인덱스 범위를 계산한다.
- 각 인덱스 범위에 해당하는 요소의 내용을 렌더링한다. 요소의 위치는 position:absolute를 활용한 절대 좌표로 결정된다.
가상 리스트의 인덱스 공식
2번은 현재 스크롤에서 어느 부분이 보여야 할지를 계산하는 방법으로, 가상 리스트를 이해하는 데 가장 중요하니, 부연설명을 해보겠다.
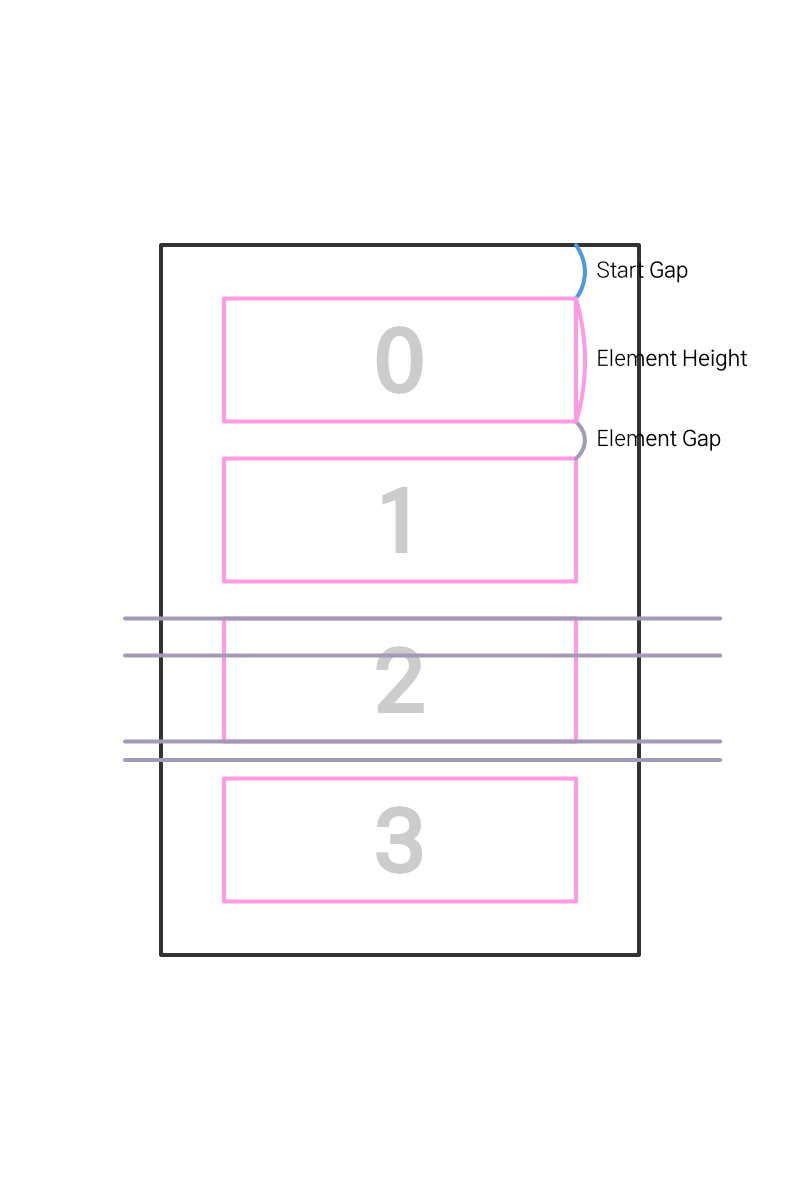
우선, 위의 사진은 리스트의 기본 구조이다. 위에서부터 0번, 1번 순으로 이어지며, 0번과 리스트 컨테이너 사이의 간격을 startPadding, 각 리스트 높이를 elemHeight, 리스트 사이의 간격을 elemGap이라고 하겠다.
여기서 0번 엘리먼트의 시작 y값은 startPadding이며, 종료 y값은 startPadding+elemHeight이다. 1번 엘리먼트의 시작 y값은 startPadding+elemHeight+elemGap이고, 종료 y값은 startPadding+elemHeight+elemHap+elemHeight이다. 이 규칙을 적용하면, i번 엘리먼트의 시작 y값과 종료 y값을 구할 수 있다.
- 시작 y값 :
startPadding + (elemHeight+elemGap)*i - 종료 y값 :
startPadding + (elemHeight+elemGap)*i + elemHeight
이제, 저 리스트에 가상의 가로선을 그어보자. 이 가로선이 보이는 엘리먼트의 기준이 되는 선이다. 가로선이 엘리먼트의 시작점에 있을 때, 엘리먼트 중간에 있을 때, 엘리먼트 종료점에 있을 때,엘리먼트와 엘리먼트 사이 공간에 있을 때로 나눠서 생각해보자.
먼저, 가로선 아래에 있는 엘리먼트가 보인다고 가정해보자. 이 가로선은 스크롤의 시작 가로선이다.
사진의 각 경우를 살펴보자.
- 시작점에 있을 때 : 2번부터 보임
- 중간에 있을 때 : 2번부터 보임
- 끝점에 있을 때 : 3번부터 보임
- 사이공간에 있을 때 : 3번부터 보임
스크롤 시작 가로선의 경우, 끝점을 기준으로 보이는 엘리먼트의 인덱스가 나뉘어진다.
다음으로, 가로선 위에 있는 엘리먼트가 보인다고 가정해보자. 이 가로선은 스크롤의 종료 가로선이다.
사진의 각 경우를 살펴보자.
- 시작점에 있을 때 : 1번부터 보임
- 중간에 있을 때 : 2번부터 보임
- 끝점에 있을 때 : 2번부터 보임
- 사이공간에 있을 때 : 2번부터 보임
스크롤 종료 가로선의 경우, 시작점을 기준으로 보이는 엘리먼트의 인덱스가 나뉘어진다.
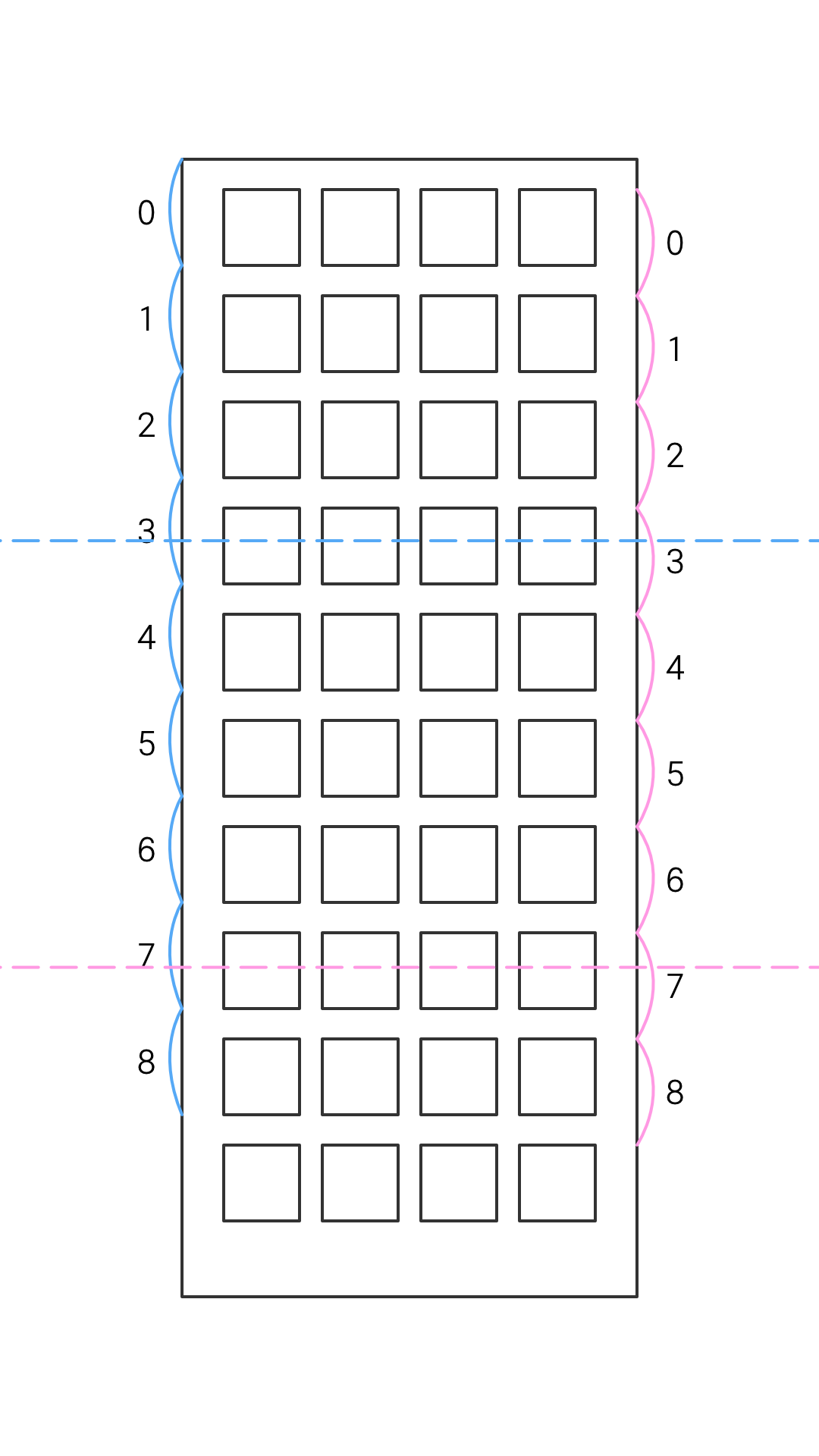
이를 기반으로, 스크롤 시작 지점과 종료 지점에 보이는 엘리먼트의 인덱스 범위를 시각화해 보았다. 왼쪽 숫자가 스크롤 시작 지점 인덱스 범위, 오른쪽 숫자가 스크롤 종료 지점 인덱스 범위다.
잘 보면, (0번을 제외하고) 각 인덱스 범위의 길이는 elemHeight + elemGap으로 동일하고, 몫 연산을 이용하면 스크롤 시작 지점/종료 지점의 y값을 기준으로 보이기 시작하는/보이기 끝나는 엘리먼트의 인덱스 번호를 알 수 있다.
- 시작점 인덱스 :
Math.floor( (scrollStartY - (startGap - elemGap)) / (elemHeight + elemGap) ) - 종료점 인덱스 :
Math.floor( (scrollEndY - startGap) / (elemHeight + elemGap) )
windowing 기법의 장단점
장점
- 페이지 내에서 엘리먼트의 수를 줄일 수 있다.
- 특히, 가상 DOM으로 컴포넌트의 변경 사항을 순회하며 계산하는 리액트와 같은 웹 프레임워크를 사용하는 데에 효과적이다.
- 엘리먼트의 수가 대량으로 줄어드므로, 리플로우 계산에 사용되는 연산 횟수 역시 줄어든다. 엘리먼트 수가 많고 리플로우가 잦은 웹 페이지에 효과적이다.
- 데이터 기반 렌더링에 효과적이다. 리스트의 실제 내용은 데이터의 인덱스를 기반으로 렌더링이 이루어지므로, 인덱싱이 된 데이터를 렌더링할 수 있다.
단점
- 구현/이해에 수학적 지식을 요구한다. 좌표 계산을 잘 하지 못하는 사람들은 구현이 힘들 수 있다.
- 엘리먼트의 추가 및 제거가 빈번하게 일어나므로 이 부분에서 오버헤드가 일어날 수 있다.
- 구현에 사용되는 scroll 이벤트의 호출 빈도가 잦다. 원활한 성능을 위해서는 throttle을 사용하여 렌더링 호출 빈도를 줄일 필요가 있다.
왜 Prismic에서는 windowing 기법을 사용했는가?
Prismic 프로젝트는 대량의 이미지를 분류하기 위해 만들어졌다. 이렇기 때문에, 최소 50개 이상, 최대 3000개의 이미지가 미리보기 컴포넌트에 보여지게 된다.
또한, 유틸리티 웹 어플리케이션이라는 앱의 특성상 싱글 페이지 어플리케이션 구현에 용이한 React를 사용하였다.
이러한 Prismic의 특성으로 인해, 미리보기 리스트의 성능을 향상시키기 위해 windowing 기법을 사용하는 것이 효과적이라고 생각했다. 그 이유는 다음과 같다.
- 엘리먼트의 수가 최대 3000개 이상으로 많다. 즉, 렌더링을 할 때 잦은 스크롤로 발생하는 오버헤드보다 대량의 엘리먼트로 인해 발생하는 연산 오버헤드가 크다고 판단했다. windowing 기법은 dom에서 엘리먼트를 제거하므로, 엘리먼트의 수를 효과적으로 줄일 수 있다.
- React를 사용한다. React는 가상 DOM을 사용해서 엘리먼트의 변경 사항을 비교하는데, 엘리먼트의 수가 많으면 가상 DOM 비교에 들어가는 연산이 커질 수밖에 없다. 따라서 엘리먼트의 수를 줄이는 windowing 기법을 사용했다.
xnb.js에서 사용한 기법 - 보이지 않는 요소 hidden처리
xnb.js에서는 보이지 않는 요소의 css display 속성을 hidden 처리하는 기법을 사용하여 보이는 요소만 렌더링했다. intersection observer api를 이용해, 엘리먼트 영역이 보이면 display 속성을 block으로 처리하고, 보이지 않으면 display 속성을 hidden 처리하여서 렌더 트리에서 해당 엘리먼트를 제거하는 방식으로 구현했다.
보이지 않는 요소 hidden처리 기법의 구현 원리
이 기법은 다음의 원리로 구현된다.
- 모든 요소를 html에 추가한다. 요소는 intersection observer가 감지할 외부 엘리먼트, 실제 내용이 들어갈 내부 엘리먼트로 구성된다.
- intersection observer가 각 요소의 외부 엘리먼트를 감지하도록 한다.
- intersection observer가 요소의 보임을 감지하면, 요소의 내부 엘리먼트의 display 속성을 block으로 전환한다. 그렇지 않으면, display 속성을 hidden으로 전환한다.
보이지 않는 요소 hidden처리 기법의 장단점
장점
- 구현이 상대적으로 간단하다. 요소의 배치와 보이는 요소 감지를 전적으로 브라우저에게 맡기기 때문에, 구현이 쉽다.
- 구현에 사용되는 intersection observer 콜백 호출 빈도가 적다. scroll 이벤트와는 달리 intersection observer의 콜백 함수는 요소가 보일 때, 숨겨질 때 1번 발생한다. 이 점에서 오버헤드를 줄일 수 있다.
단점
- 엘리먼트의 수가 줄어들지 않는다. 이로 인해, 엘리먼트 자체의 연산으로 발생하는 성능 저하를 줄일 수 없다. 리스트 내에 대량의 요소가 존재한다면 이 기법보다는 windowing 기법을 사용하는 것이 효과적이다.
- 중간에 요소가 추가될 때 많은 양의 엘리먼트의 리플로우가 그대로 일어나므로, 해당 부분에서 불리할 수 있다.
- 내부 엘리먼트의 대략적인 크기를 외부 엘리먼트가 알고 있어야 한다.
왜 xnb.js에서는 보이지 않는 요소 hidden처리 기법을 사용했는가?
xnb.js의 미리보기 컴포넌트는 최대 1만 줄의 텍스트를 렌더링해야 하지만, 청크 단위로 구분되면 최대 100개의 청크만 렌더링하게 된다. 이 점으로 미루어 보아, 보이지 않는 요소 hidden 처리 대신 가상 리스트로 얻을 수 있는 이점이 크게 있지 않을 것이라고 생각했다.
또한, xnb.js 1.3 업데이트는 빠르게 대중에게 퍼블리싱해야 할 필요가 있었다. 이미 2만 여 명의 대중에게 배포된 서비스를 업데이트하는 것이기 떄문에, 업데이트 속도가 늦으면 대중이 불편해할 것이기 때문이라고 판단했다. 그렇기 때문에 빠르게 이해하고 적용할 수 있는 보이지 않는 요소 hidden처리 기법을 사용했다.
두 방법의 차이점
windowing 기법과 보이지 않는 요소 hidden 처리는 보이는 부분만 렌더 트리에 존재한다는 공통점이 있으나, 세부적으로 다음의 차이를 보인다.

