Cost function in pure Python
import numpy as np
X = np.array([1, 2, 3])
Y = np.array([1, 2, 3])
def cost_func(W, X, Y):
c = 0
for i in range(len(X)):
c += (W * X[i] - Y[i]) ** 2
return c / len(x) # 편차 제곱의 평균
for feed_W in np.linspace(-3, 5, num=15): # -3~5까지 15개의 구간
curr_cost = cost_func(feed_W, X, Y)
print("{:6.3f} | {:10.5f}".format(feed_W, curr_cost))
Cost function in TensorFlow
import numpy as np
X = np.array([1, 2, 3])
Y = np.array([1, 2, 3])
def cost_func(W, X, Y):
hypothesis = X * W
return tf.reduce_mean(tf.square(hypothesis - Y))
W_values = np.linspace(-3, 5, num=15)
cost_values = []
for feed_W in W_values:
curr_cost = cost_func(feed_W, X, Y)
cost_values.append(curr_cost)
print("{:6.3f} | {:10.5f}".format(feed_W, curr_cost))
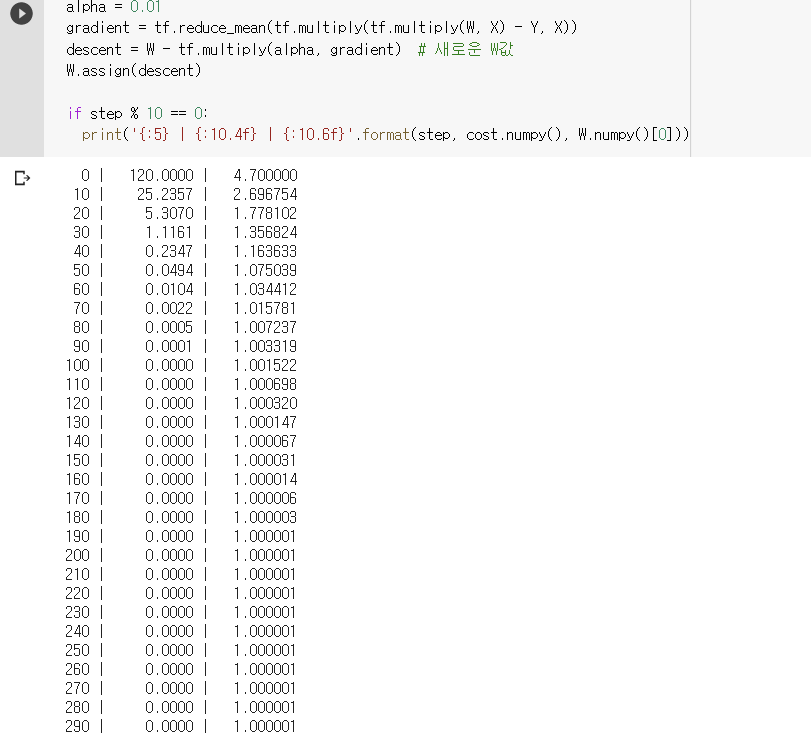
Gradient descent
tf.random.set_seed(0) # for reproducibility
X = [1., 2., 3., 4.]
Y = [1., 2., 3., 4.]
W = tf.Variable(tf.random_normal([1], -100. 100.)) # random
# W = tf.Variable([5.0])
# W에 어떤 값을 주어도 cost는 0으로 W는 특정한 값으로 수렴.
for step in range(300):
hypothesis = W * X
cost = tf.reduce_mean(tf.square(hypothesis - Y))
alpha = 0.01
gradient = tf.reduce_mean(tf.multiply(tf.multiply(W, X) - Y, X))
descent = W - tf.multiply(alpha, gradient) # 새로운 W값
W.assign(descent)
if step % 10 == 0:
print('{:5} | {:10.4f} | {:10.6f}'.format(step, cost.numpy(), W.numpy()[0]))