01) 훈련 세트와 테스트 세트
- 지도 학습과 비지도 학습
- 머신러닝 알고리즘
- 지도 학습
: 입력과 타깃으로 이뤄진 훈련 데이터를 가짐
입력으로 사용된 변수들을 특성, 정답을 타깃
=> 알고리즘이 정답을 맞히는 것을 학습 - 비지도 학습
: 입력 데이터만 존재
=> 데이터 파악, 변형
- 훈련 세트와 테스트 세트
- 훈련 세트
: 훈련에 사용 - 테스트 세트
: 평가에 사용

샘플링 편향?
-> 훈련 세트와 테스트 세트에 샘플이 골고루 섞이지 않은 상태
좋은 학습 모델을 생성하기 어려움
- 넘파이
: 파이썬의 대표 배열 라이브러리
- 1차원 배열 -> 선
- 2차원 배열 -> 면
- 3차원 배열 -> 3차원 공간
배열의 시작점을 왼쪽 위로 설정하면 편리

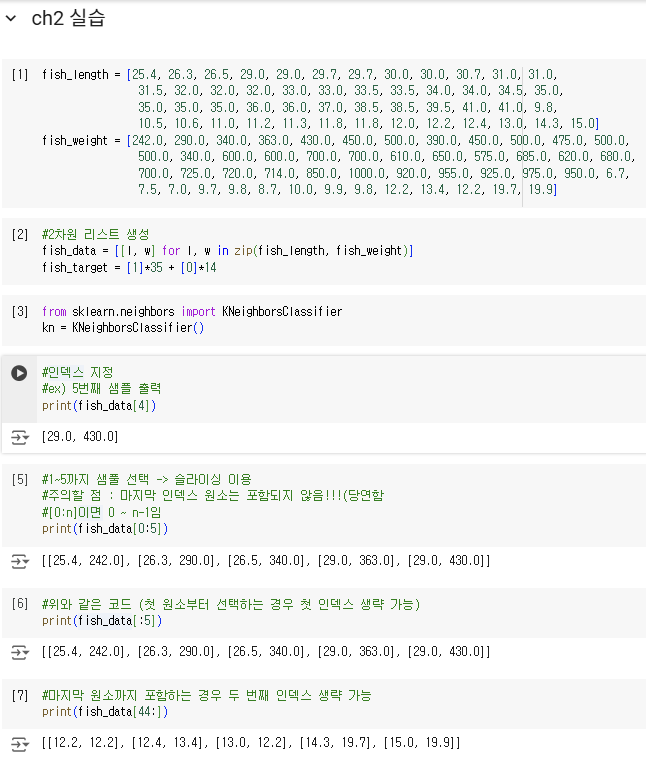
- 생선 데이터에 응용
- 주의할 점 : input_arr와 target_arr에서 같은 위치는 함께 선택!
-> 올바른 훈련을 위해 타깃과 샘플을 함께 이동


=> 샘플링 편향XX
- 두 번째 머신러닝 프로그램

- predict()는 단순 파이썬 리스트가 아니라 넘파이 배열!!
02) 데이터 전처리
 => 마지막 코드에서 연결할 리스트를 튜플로 전달
=> 마지막 코드에서 연결할 리스트를 튜플로 전달
튜플?
-> 리스트와 비슷하지만 수정이 불가능
즉, 매개변수의 값으로 많이 사용
 TIP! 데이터가 클수록 넘파이 배열을 사용하는 것이 좋음
TIP! 데이터가 클수록 넘파이 배열을 사용하는 것이 좋음
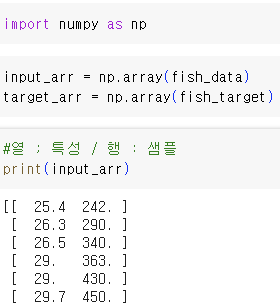
- 사이킷런으로 훈련 세트와 테스트 세트 나누기
- 사이킷런
: 머신러닝 모델을 위한 알고리즘 제공 뿐만 아니라 다양한 유틸리티 도구 제공
=> 빙어 비율이 조금 모자람 (샘플링 편향)
즉, 모델이 샘플을 올바르게 학습하지 못함.

- K-NN 훈련
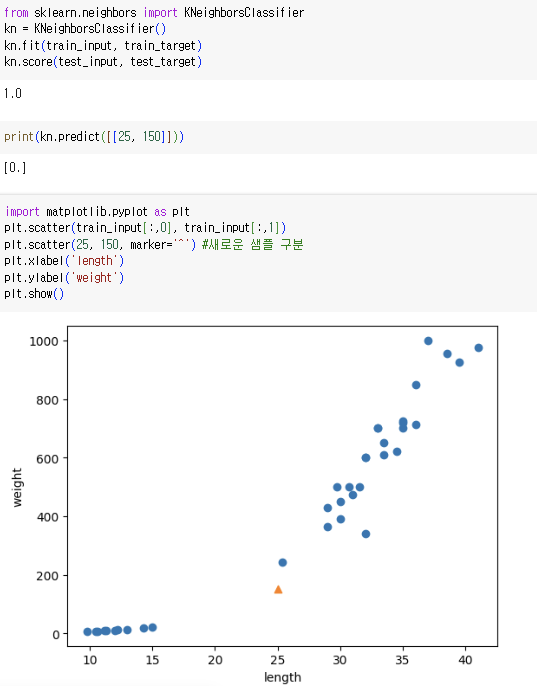
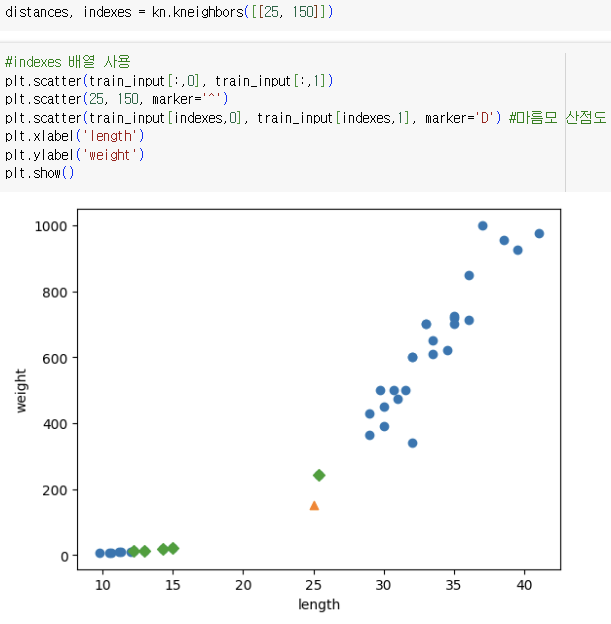

=> 길이 25cm, 무게 150g인 생선에 가까운 이웃은 빙어가 압도적으로 많음
산점도를 보면 도미와 가깝게 보임
-> distances 배열을 출력해 확인
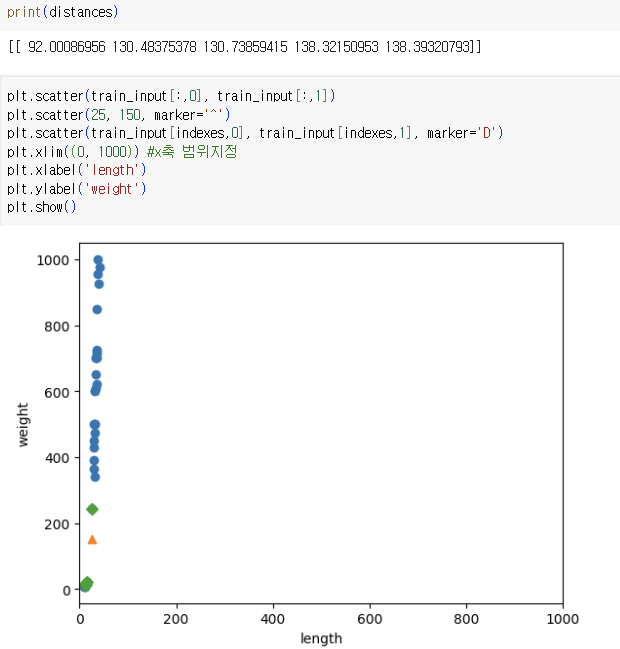
=> 두 특성(x, y축)의 범위가 달라 이런 일이 생기는 것
=> 스케일이 다르다 라고 말함
=> 이런 오류를 방지하기 위해 특성 값들을 일정 기준으로 맞추는 데이터 전처리 과정 필요
- 표준 점수
: 각 특성 값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지 나타냄
=> 실제 특성값의 크기와 상관 없이 동일한 조건으로 비교 가능
- 계산법 : 평균을 빼고 표준편차를 나누기
=> train_input의 모든 행에서 mean에 있는 두 평균값을 뺀 후 std에 있는 두 표준편차 적용 - 브로드 캐스팅
: 크기가 다른 넘파이 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장하여 수행
- 전처리 데이터로 모델 훈련
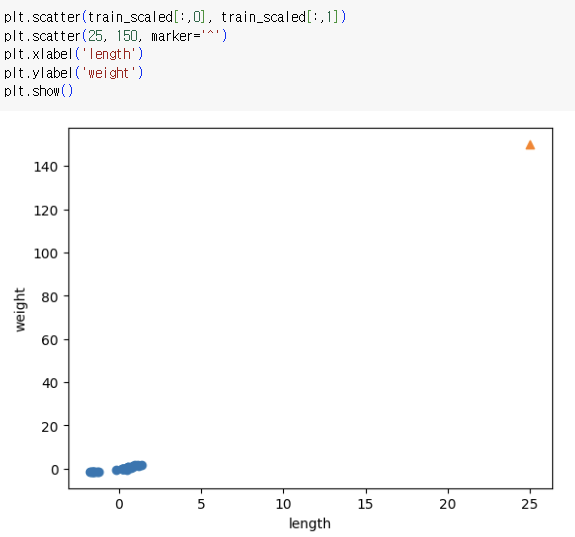
=> 샘플을 동일 기준으로 변환하고 산점도를 그려야 함
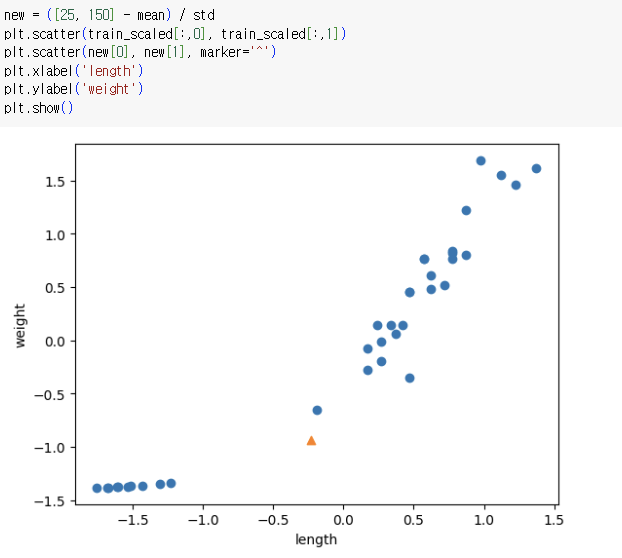 => x, y 축 범위를 보시오!
=> x, y 축 범위를 보시오!
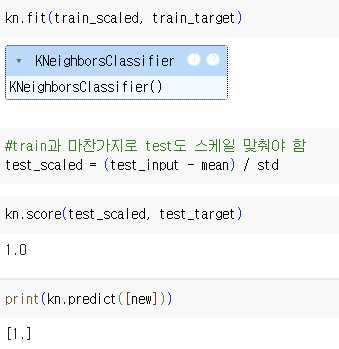
=> 1은 도미! 도미 예측을 정확히 함
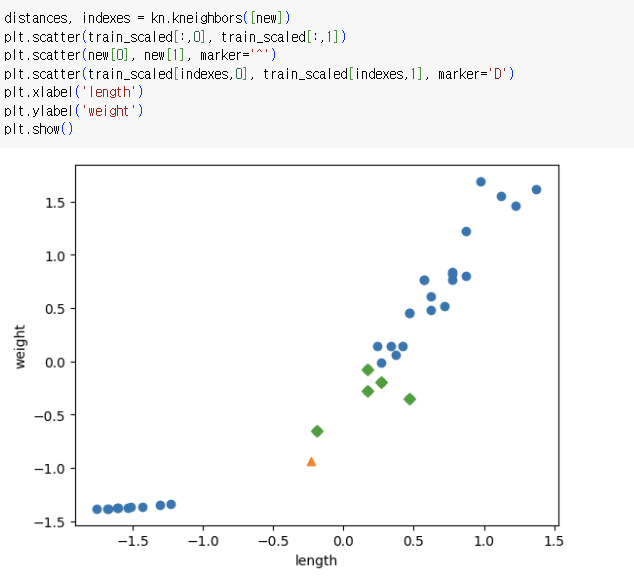
=> 주어진 샘플(세모)와 가장 가까운 샘플은 도미이다.
