월요일: 전기차 충전소 현황
경기도 전기차 충전소 현황
데이터를 활용한 데이터 분석 및 지도 시각화
- 링크 다운로드 받고
* 데이터 분석: 기본 Chart 5개 이상 (데이터 바라보기: 질문 -> 답변 형식)
* 지도 시각화: 충전소 위치...gg_df.isnull().sum() #결측치 확인 여부
df.dropna(axis=0, inplace = True) #결측치 제거
# 충전소 지도
import pandas as pd
import plotly.express as px
import matplotlib.pyplot as plt
import folium
import numpy as np
df = pd.read_csv('/content/전기차충전소현황.csv', encoding = 'utf-8')
gg = df
gg_map = folium.Map(location=[37.275052,127.009447])
gg = gg.astype({'WGS84위도' : 'float64'})
gg = gg.astype({'WGS84경도' : 'float64'})
gg.dropna(axis=0, inplace = True)
gg.reset_index(drop = True, inplace = True)
for i in range(0, len(gg['WGS84위도'])):
folium.Marker([gg.loc[i, 'WGS84위도'], gg.loc[i, 'WGS84경도']],
popup='<pre>'+gg.loc[i,'충전소명']+'</pre>',
icon=folium.Icon(color='blue', icon='info-sign')).add_to(gg_map)
gg_map
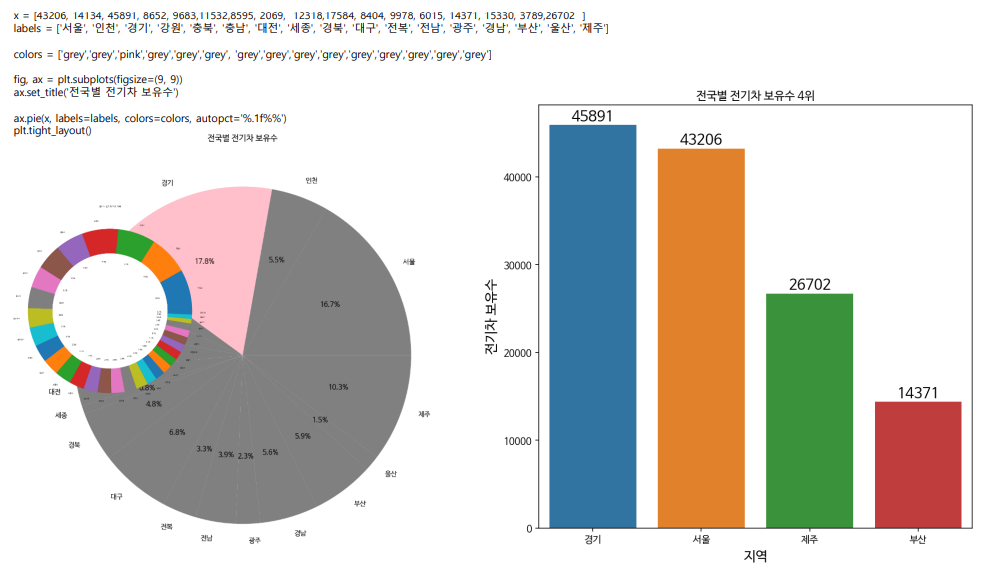
^ 전국별 전기차 보유수(다른 데이터)
^ 별로 알아보기 힘든 그래프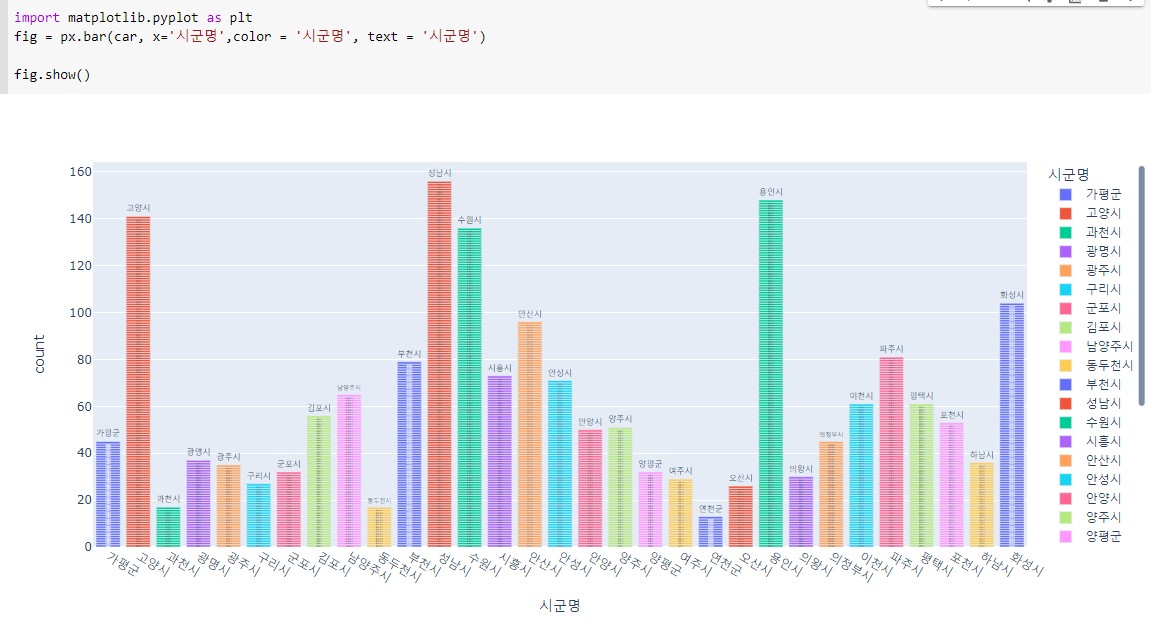
^ 그래프 위에 수치 나타내는 수를 그리고 싶었는데 모르겠다
저게 최선ㅎㅎ....화오전+수요일:
2018~2021년 사망교통사고 현황분석 및 지도 시각화
- 년도별 비교분석:
하나의 dataframe 만들기
* 데이터프레임(머지 혹은 append)으로 불러와 합치는거 가능
- 지도시각화:
년도별로 비교
한 지역 선택해서 2018,2019,2020,2021 중첩되는 지역2개 주제 pdf 5:30까지 올려주기(조이름 정해서 파일 만들기)
storytelling: 문제점-> 데이터 분석 -> 가치 찾음
^ 컬럼 이름 변경하기
^ 컬럼 지워주기 혹은 drop으로 지울 수 있음
^ 1번) 파일 불러오고 : 2018 ~2021 데이터
콜롬 맞춰주고 : ex) 2019년도 이후꺼는 부상자수 없애줌
발생년월일시분 쪼개주고
콜롬 이름 변경해줌
^ 2번) 발생년월일시에서 '시'만 발생시간으로 따로 빼주고
발생년월일 %Y-%m-%d 로 정리하며 시간을 없애줌. 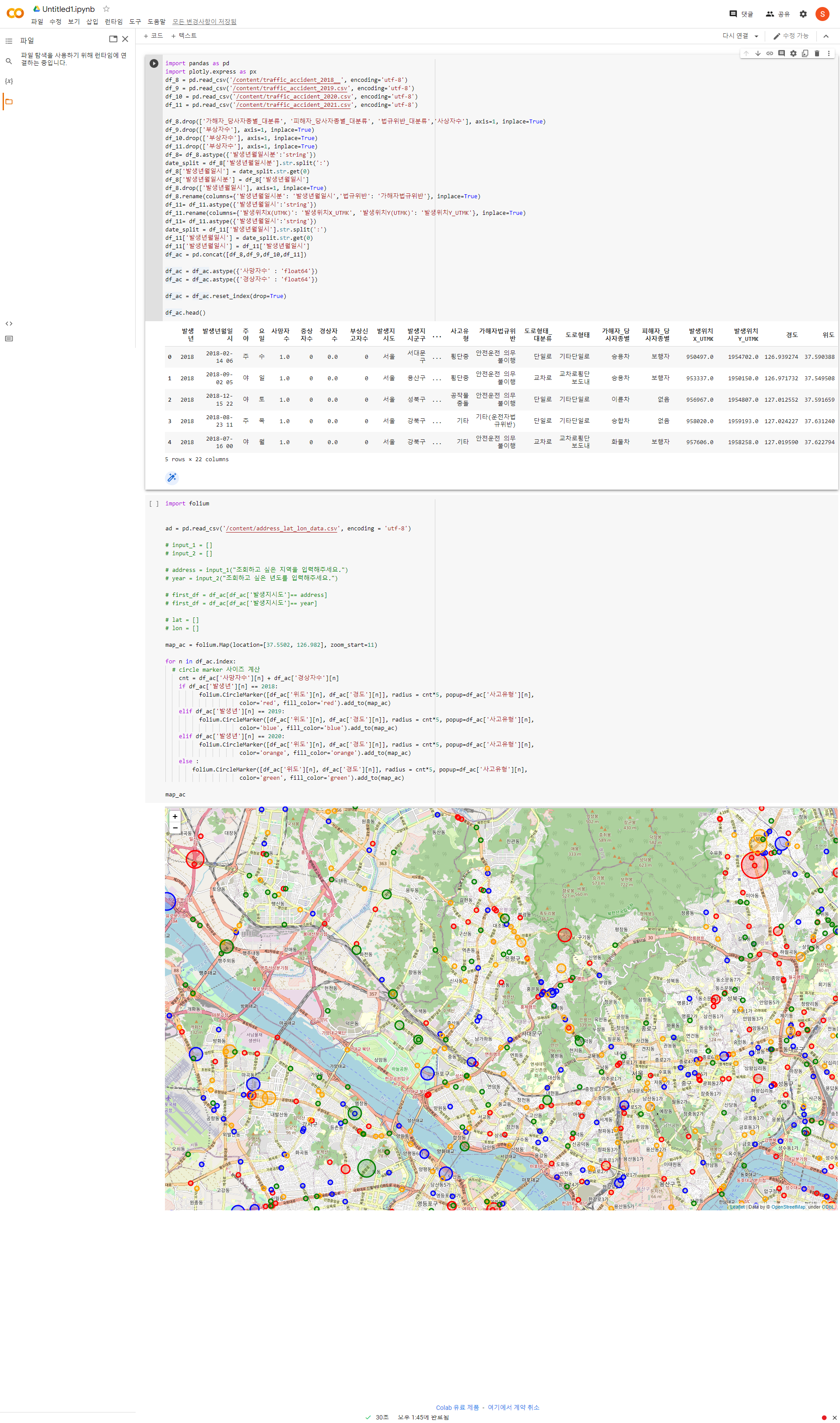
^ 1차 완성pie chart
x = [43206, 14134, 45891, 8652, 9683,11532,8595, 2069, 12318,17584, 8404, 9978, 6015, 14371, 15330, 3789,26702 ]
labels = ['서울', '인천', '경기', '강원', '충북', '충남', '대전', '세종', '경북', '대구', '전복', '전남', '광주', '경남', '부산', '울산', '제주']
fig, ax = plt.subplots(figsize=(9, 9))
ax.set_title('전국별 전기차 보유수')
ax.pie(x, labels=labels, autopct='%.1f%%')
plt.tight_layout()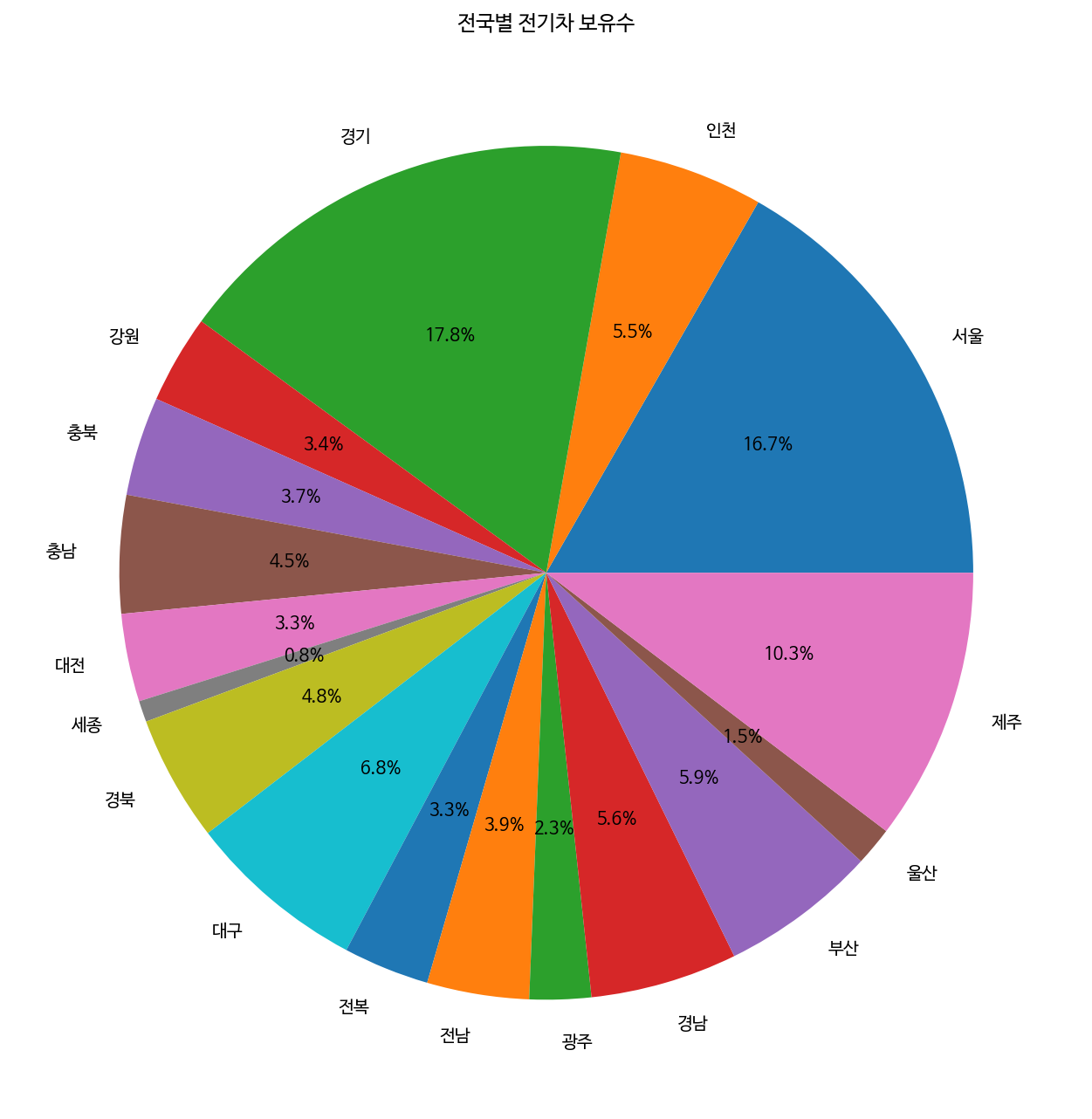
x = [43206, 14134, 45891, 8652, 9683,11532,8595, 2069, 12318,17584, 8404, 9978, 6015, 14371, 15330, 3789,26702 ]
labels = ['서울', '인천', '경기', '강원', '충북', '충남', '대전', '세종', '경북', '대구', '전복', '전남', '광주', '경남', '부산', '울산', '제주']
# colors = ['lightgrey', 'lightgrey', 'pink', 'lightgrey', 'lightgrey','lightgrey','lightgrey','lightgrey','lightgrey','lightgrey','lightgrey','lightgrey','lightgrey','lightgrey','lightgrey',lightgrey', 'grey']
colors = ['grey','grey','pink','grey','grey','grey', 'grey','grey','grey','grey','grey','grey','grey','grey','grey','grey','grey']
fig, ax = plt.subplots(figsize=(9, 9))
ax.set_title('전국별 전기차 보유수')
ax.pie(x, labels=labels, colors=colors, autopct='%.1f%%')
plt.tight_layout()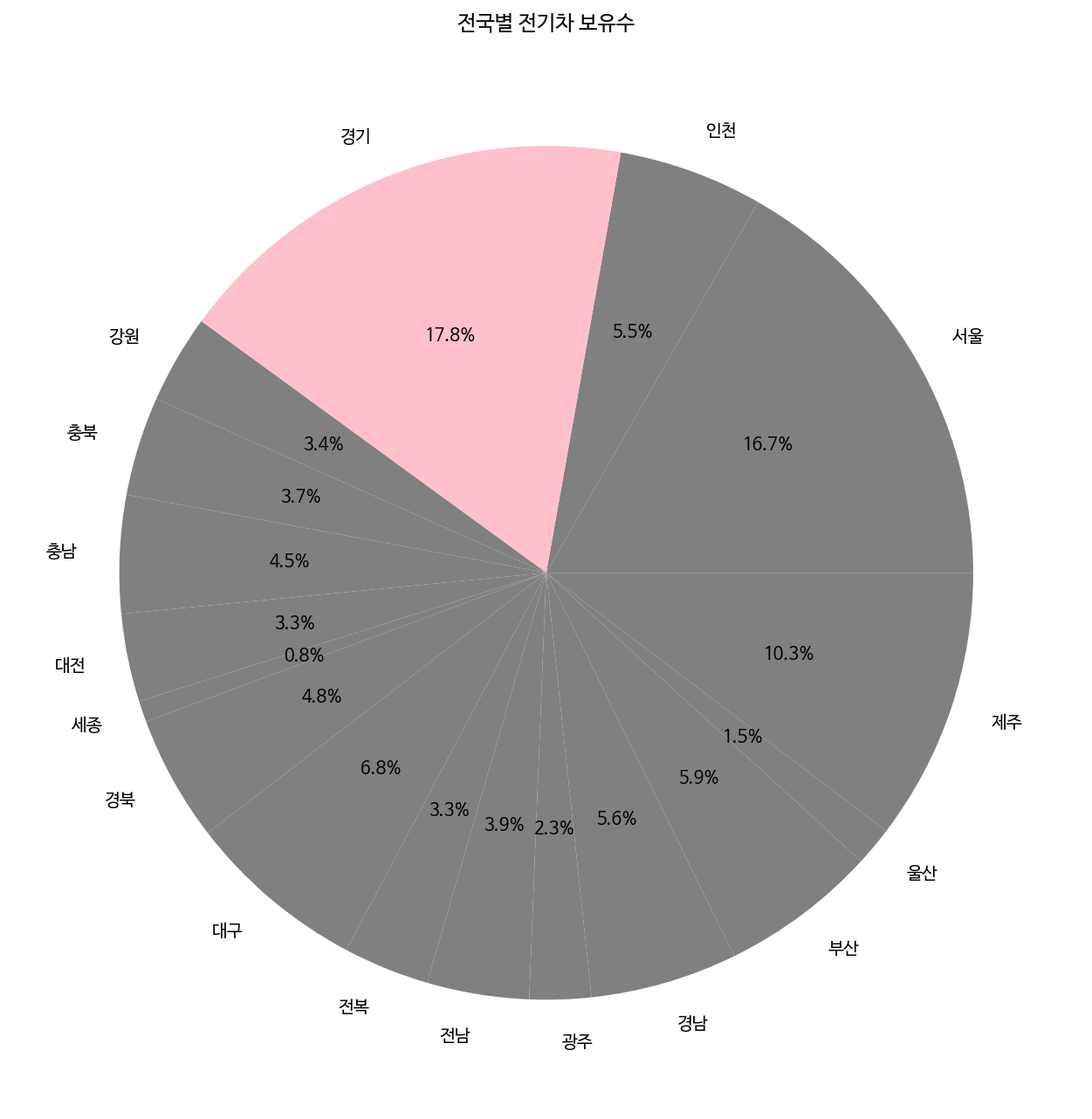
^ pie chart color and %.donut chart
# add a circle at the center to transform it in a donut chart
my_circle=plt.Circle( (0,0), 0.7, color='white')
p=plt.gcf()
p.gca().add_artist(my_circle)
^import matplotlib.pyplot as plt
# create data
size_of_groups=[12,11,3,30]
# Create a pieplot
plt.pie(size_of_groups)
# add a circle at the center to transform it in a donut chart
my_circle=plt.Circle( (0,0), 0.7, color='white')
p=plt.gcf()
p.gca().add_artist(my_circle)
plt.show()x1, x2, y1, y2 bar chart
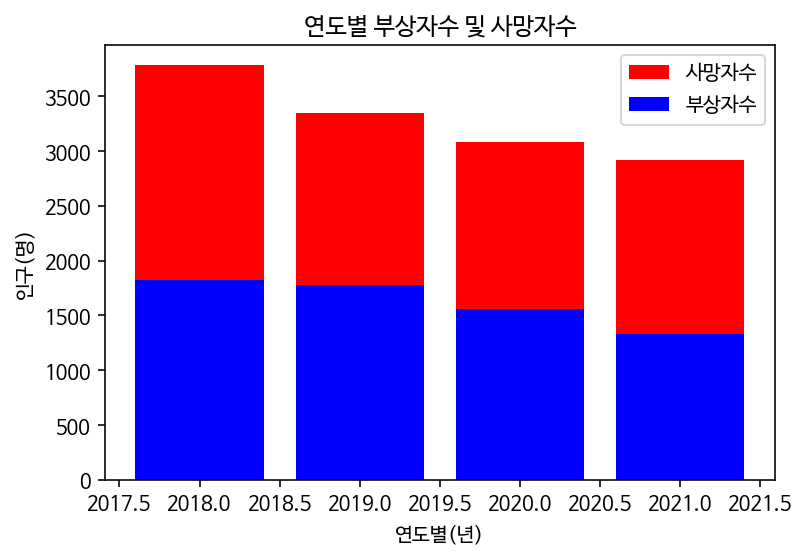
#사망자수
x1 = [2018, 2019, 2020, 2021]
y1 = [3781, 3349, 3081, 2916]
#부상자수
x2 = [2018, 2019, 2020, 2021]
y2 = [1821, 1772, 1561, 1325]
plt.bar(x1, y1, label="사망자수", color='r')
plt.bar(x2, y2, label="부상자수", color='b')
plt.plot()
plt.xlabel("연도별(년)")
plt.ylabel("인구(명)")
plt.title("연도별 부상자수 및 사망자수")
plt.legend()
plt.show()Annotated barplot
(1)
# Importing libraries for dataframe creation
# and graph plotting
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Creating our own dataframe
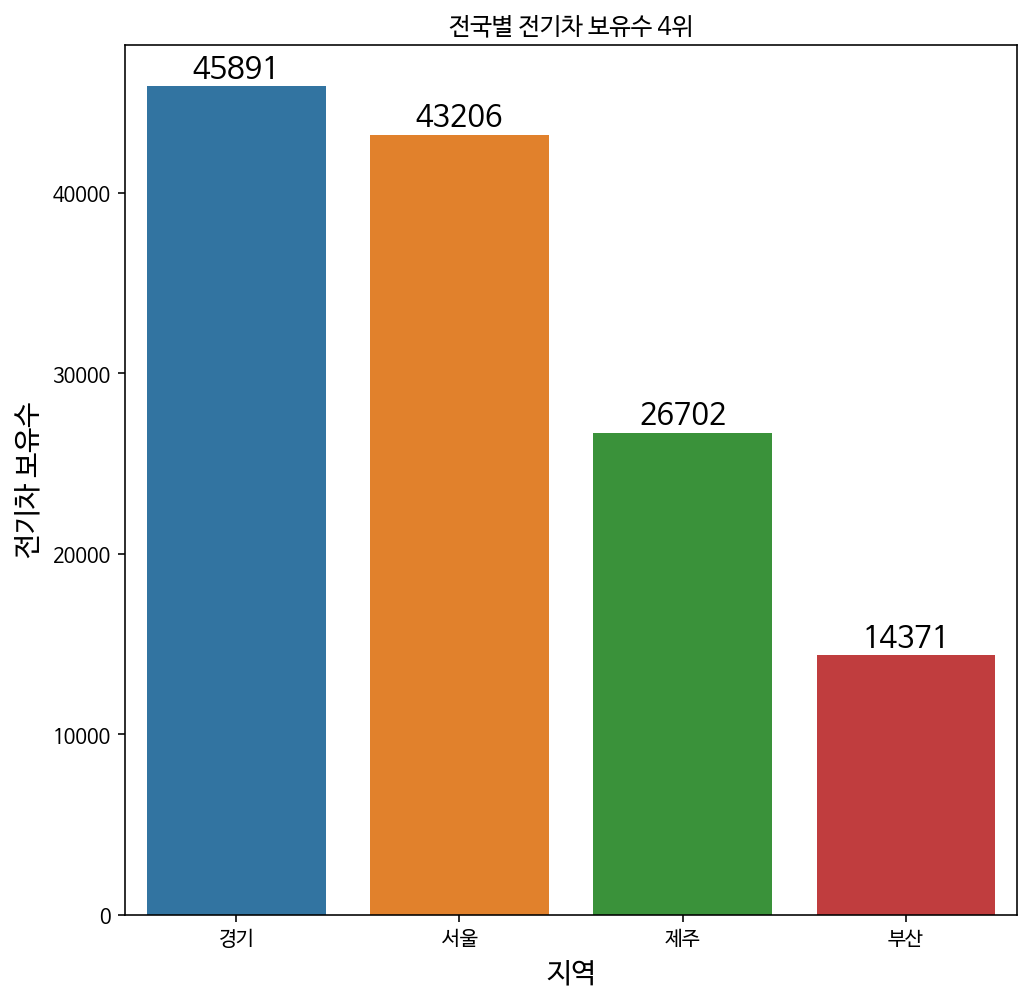
data = {"Name": ["경기", "서울", "제주", "부산"],
"Marks": [45891, 43206, 26702, 14371]}
# Now convert this dictionary type data into a pandas dataframe
# specifying what are the column names
df = pd.DataFrame(data, columns=['Name', 'Marks'])
# Defining the plotsize
plt.figure(figsize=(8, 6))
# Defining the x-axis, the y-axis and the data
# from where the values are to be taken
plots = sns.barplot(x="Name", y="Marks", data=df)
# Setting the x-acis label and its size
plt.xlabel("year", size=15)
# Setting the y-axis label and its size
plt.ylabel("population", size=15)
# Finallt plotting the graph
plt.show()^ 1st round: setting data w/ non-annotated barplot
(2)
# Defining the plot size
plt.figure(figsize=(8, 8))
# Defining the values for x-axis, y-axis
# and from which dataframe the values are to be picked
plots = sns.barplot(x="Name", y="Marks", data=df)
# Iterrating over the bars one-by-one
for bar in plots.patches:
# Using Matplotlib's annotate function and
# passing the coordinates where the annotation shall be done
# x-coordinate: bar.get_x() + bar.get_width() / 2
# y-coordinate: bar.get_height()
# free space to be left to make graph pleasing: (0, 8)
# ha and va stand for the horizontal and vertical alignment
plots.annotate(format(bar.get_height(), '.0f'),
(bar.get_x() + bar.get_width() / 2,
bar.get_height()), ha='center', va='center',
size=15, xytext=(0, 8),
textcoords='offset points')
# Setting the label for x-axis
plt.xlabel("지역", size=14)
# Setting the label for y-axis
plt.ylabel("전기차 보유수", size=14)
# Setting the title for the graph
plt.title("전국별 전기차 보유수 4위")
# Finally showing the plot
plt.show()^ 2nd round: Annotated barplot.
- round off to not make decimal point by <.0f>
발표 PPT