02_ 피마족 인디언 당뇨병 발명 유무 예측.ipynb
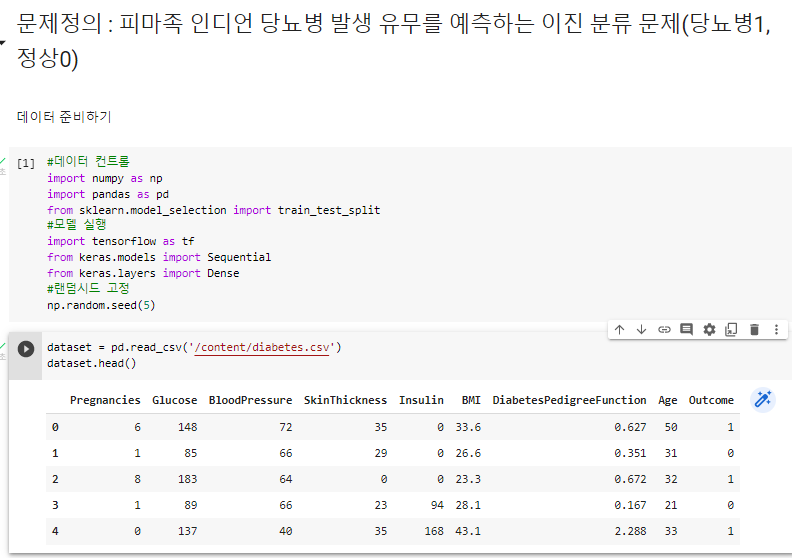
^ 데이터 파일 불러오기
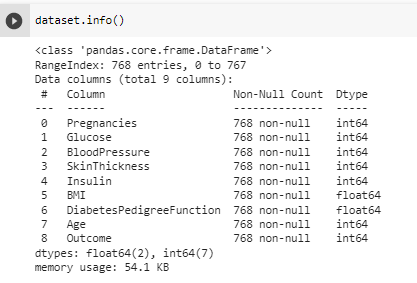
^ 데이터 타입 잘 들어왔는지 확인 가능
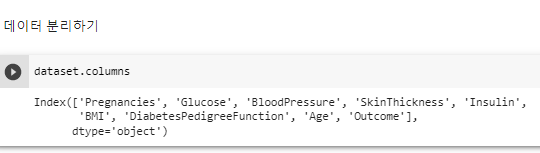
^ 콜럼명 보기

^ X랑 y 나눔

^ train:test 구분함

^ 모델 구성하기
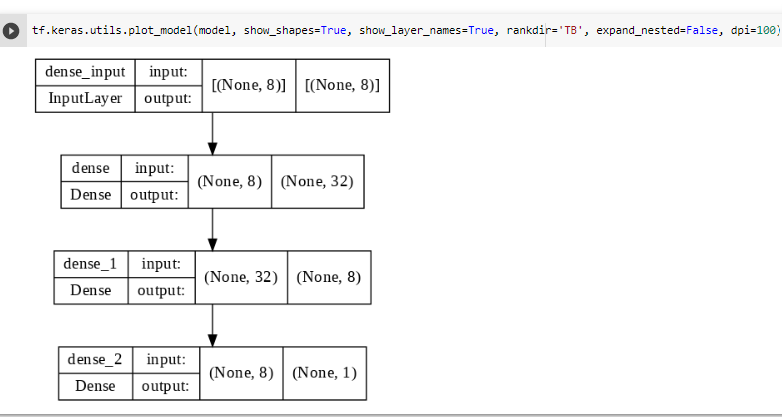
^ 모델 구성한 것 시각화도 가능함

^ 모델 설정하기

^ 모델 학습하기

import matplotlib.pyplot as plt
his_dict = history.history
loss = his_dict['loss']
epochs = range(1, len(loss) + 1)
fig = plt.figure(figsize = (10, 5))
# 훈련 및 검증 손실 그리기
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs, loss, color = 'orange', label = 'train_loss')
ax1.set_title('train loss')
ax1.set_xlabel('epochs')
ax1.set_ylabel('loss')
ax1.legend()
acc = his_dict['accuracy']
# 훈련 및 검증 정확도 그리기
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs, acc, color = 'blue', label = 'train_accuracy')
ax2.set_title('train accuracy')
ax2.set_xlabel('epochs')
ax2.set_ylabel('accuracy')
ax2.legend()
plt.show()^ 학습결과 그려보기

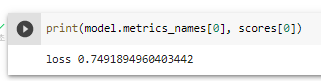

^ 모델 평가하기 -> over-fit 된 상태이다.
ㅇㄹㅇ
ㅇㄹㅇㄹㅇㄹㅇㄹㅇㄹ
HOW TO 정규화
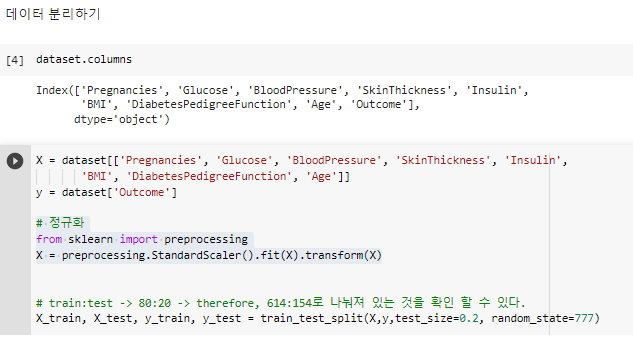
# 정규화
from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X)