비지도 학습
unsupervised-learning
: 알고 있는 출력값이나 정보 없이 학습 알고리즘을 가르쳐야 하는
모든 종류의 머신러닝
: 정답이 없다보니 성능평가 하기 너무 어려움.
: 정보가 없을 때 데이터를 분석할 수 있는 유일한 방법
: 지도 학습에 있는 거 반대로 해봐. (y축 없애고)
scikit-learn 에 있는 실제 데이터셋인 digits, iris, cancer 데이터 셋에
직접 군집과 분해 알고리즘을 적용하는 연습이 도움됨.군집clustering
: 데이터셋을 cluster라는 그룹으로 나누는 작업
: x 값으로만 학습을 하고 군집을 만듦. (y=?)
1) k-평균 군집: 데이터의 어떤 영역을 대표하는 클러스터 중심 찾기
2) 병합 군집: 종료 조건 만족까지 비슷한 클러스터 합치기(평균값..?)
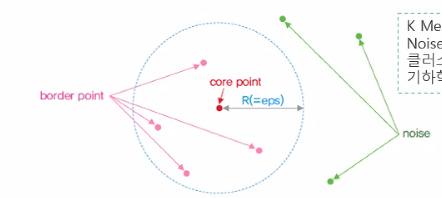
3) DBSCAN: 데이터가 위치하고 있는 공간 밀집도 기준으로 클러스터 구분1) k-평균 군집 (K-Means)
어떤 데이터에 대해서 k개의 클러스터가 주어졌을때
평균적으로 가까운 거리를 이용3) DBSCAN (Density-based Spatial Clustering of Applications with Noise)
01_K-Means 도매업 고객 군집 분석.ipynb

^ 라이브러리 준비

^ 데이터 준비하기
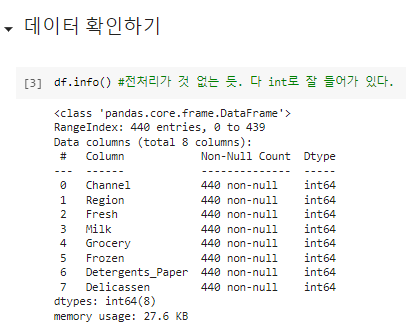
^ 데이터 확인하기. object 전처리 할 것 없는지 확인.

^ 어떻게 구성되어 있는지 확인

^ 데이터 전처리

^ 표 잘 나오는지 봐보기
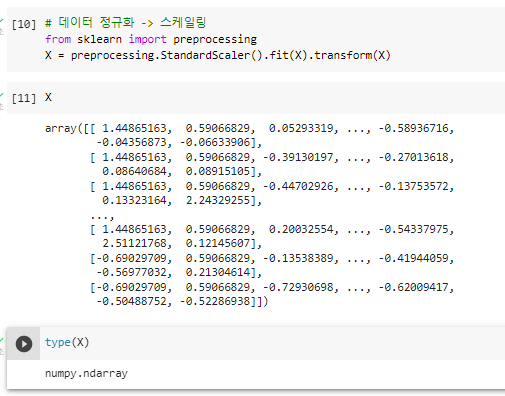
^ 데이터셋 준비 끝

^ 군집 모델 설정
# random_state 지정해줄 수도 있다:
kmeans = cluster.KMeans(n_clusters=5, random_state=7)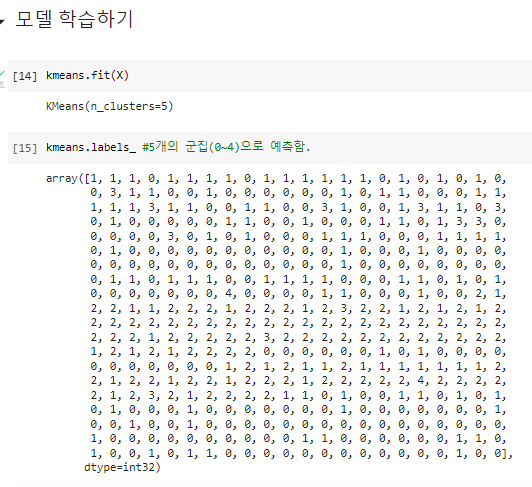
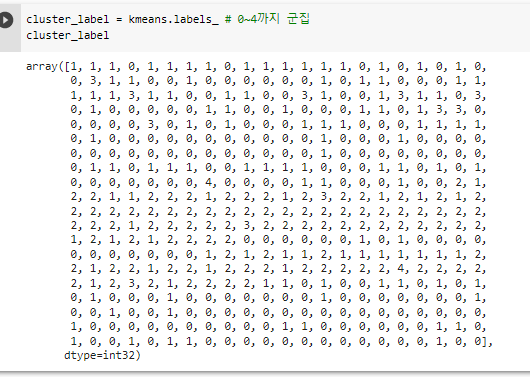
^ 모델 학습하기 + 변수명으로 담아줌
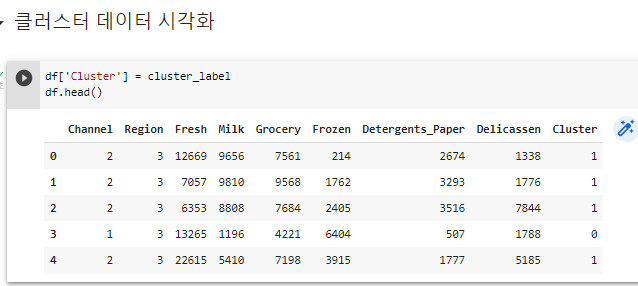
^ 군집분석해 cluster한 데이터

^ - 다음 그려볼 시각화 이해하는 방법:
- 상승 곡선 그래프 일 경우 x축과 y축에
해당하는 품목들간의 연관성이 있는 것.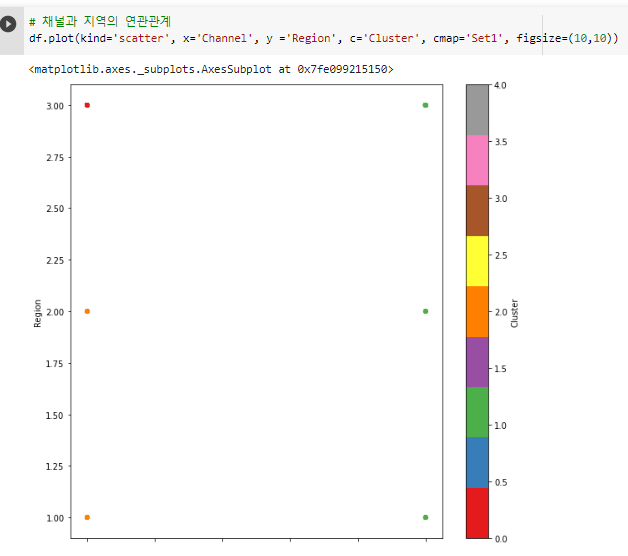
^ 채널에 따른 지역(cluster) 시각화
ex) 주황색은 2번 클러스터시각화를 통해 패턴을 분석할 수 있다.
# 2 Cluster Channel 2(Retail channel), Region 1,2,3
# 1 Cluster Channel 1, Region 3
# 0 Cluster Channel 1, Region 1,2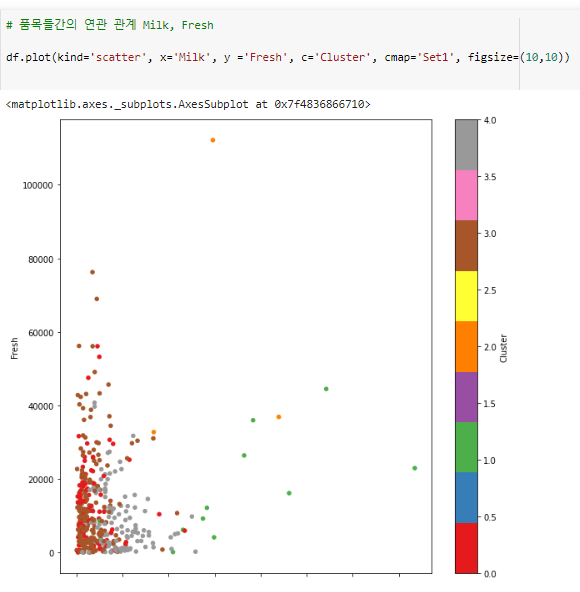
^ - 위 시각화를 보고 도출한 결론:
- milk 랑 fresh 는 밀접한 관계가 있는 것이 아니다.
- 상관관계가 있다면 x축 y축 같이 증가하는
상승 그래프를 띄어야 한다.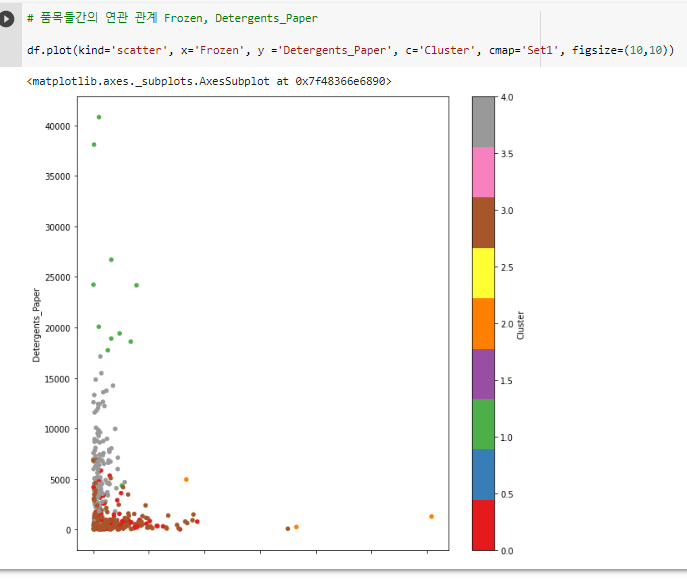
^ - 시각화 해석:
- Frozen 과 Detergents_Paper 랑 관계 없음.
- 연관성이 있다면 상승 그래프 곡선을 띄어야 함.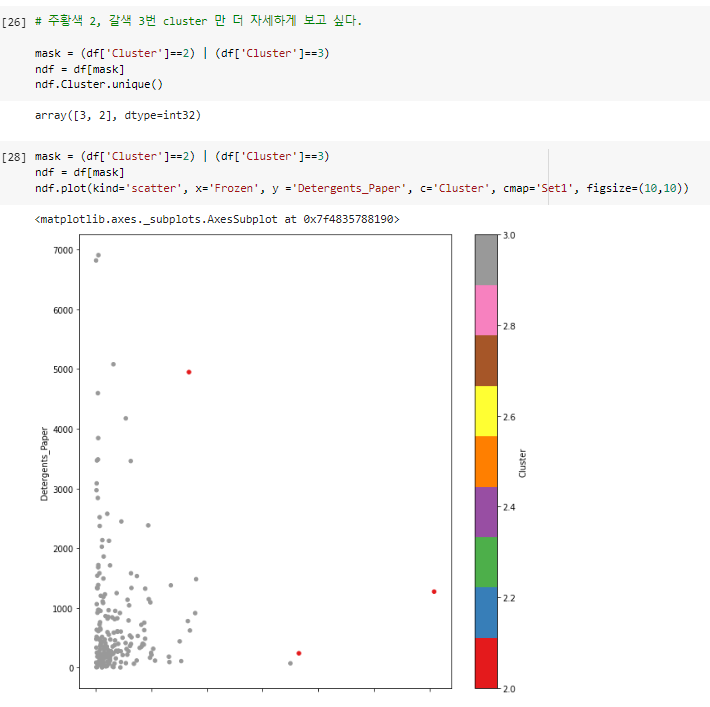
^ 2번, 3번 클러스터만 자세하게 뽑아내기
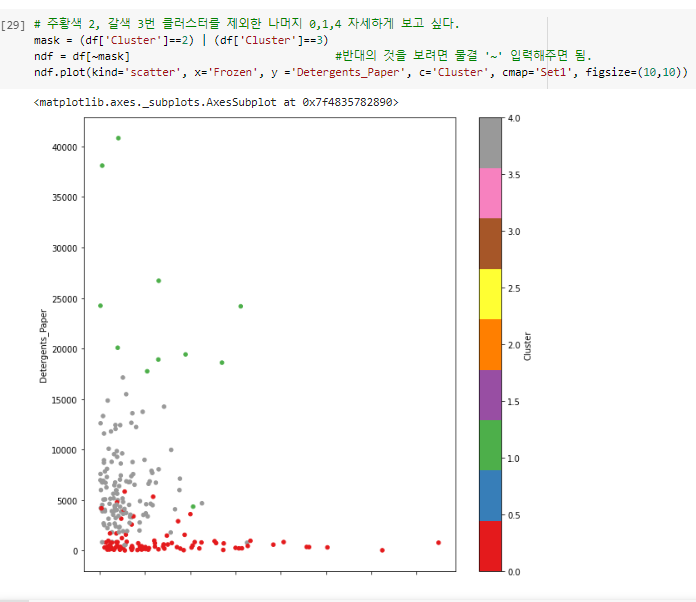
^ 2번, 3번을 제외한 나머지 클러스터 보기
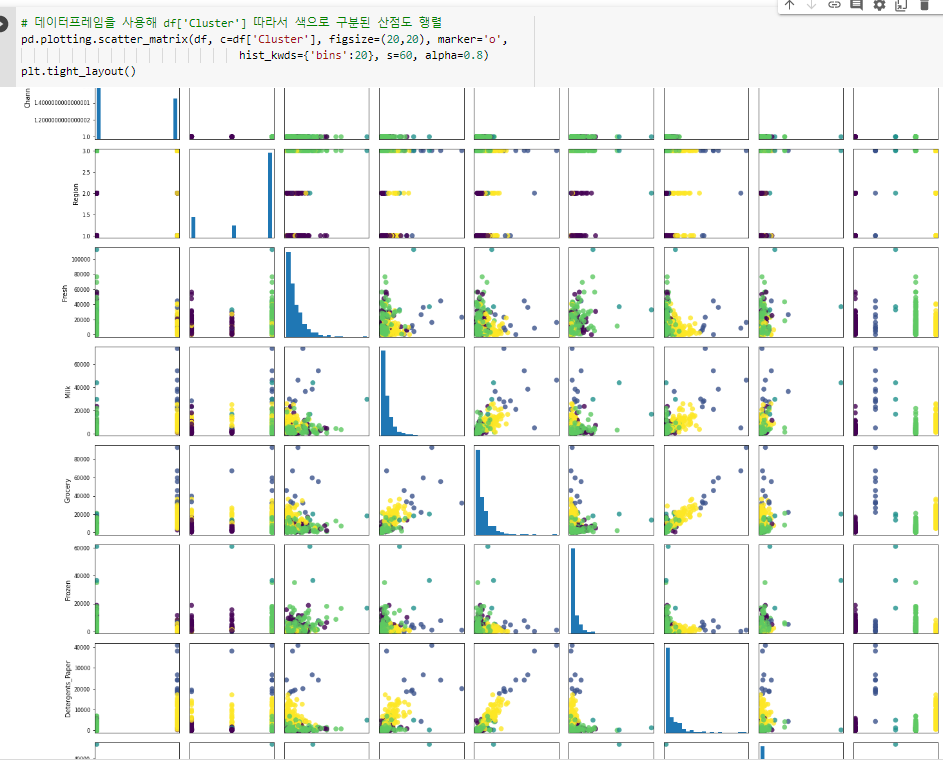
^ 산점도 행렬
이를 보고 상승 곡선 그래프를 찾자.

^ 표를 보고 두 개의 막대기가 왜 작을까해서 자세히 봄.

^ 색이 어떤 것인지 확인
