Docker 기반 ML 협업 워크플로우
제출자: 이영호
제출일: 2025년 10월 13일
1. 미션 개요
- 두 명의 연구자가 협업하는 시나리오를 참고하여 도커 기반 워크플로우를 설계하고, 필요한 도커 파일을 작성하는 미션.
- 연구자 1 : 데이터 전처리, 탐색적 데이터 분석(EDA), 모델링 및 모델 파일 추출
- 연구자 2 : 추출된 모델을 활용한 추론
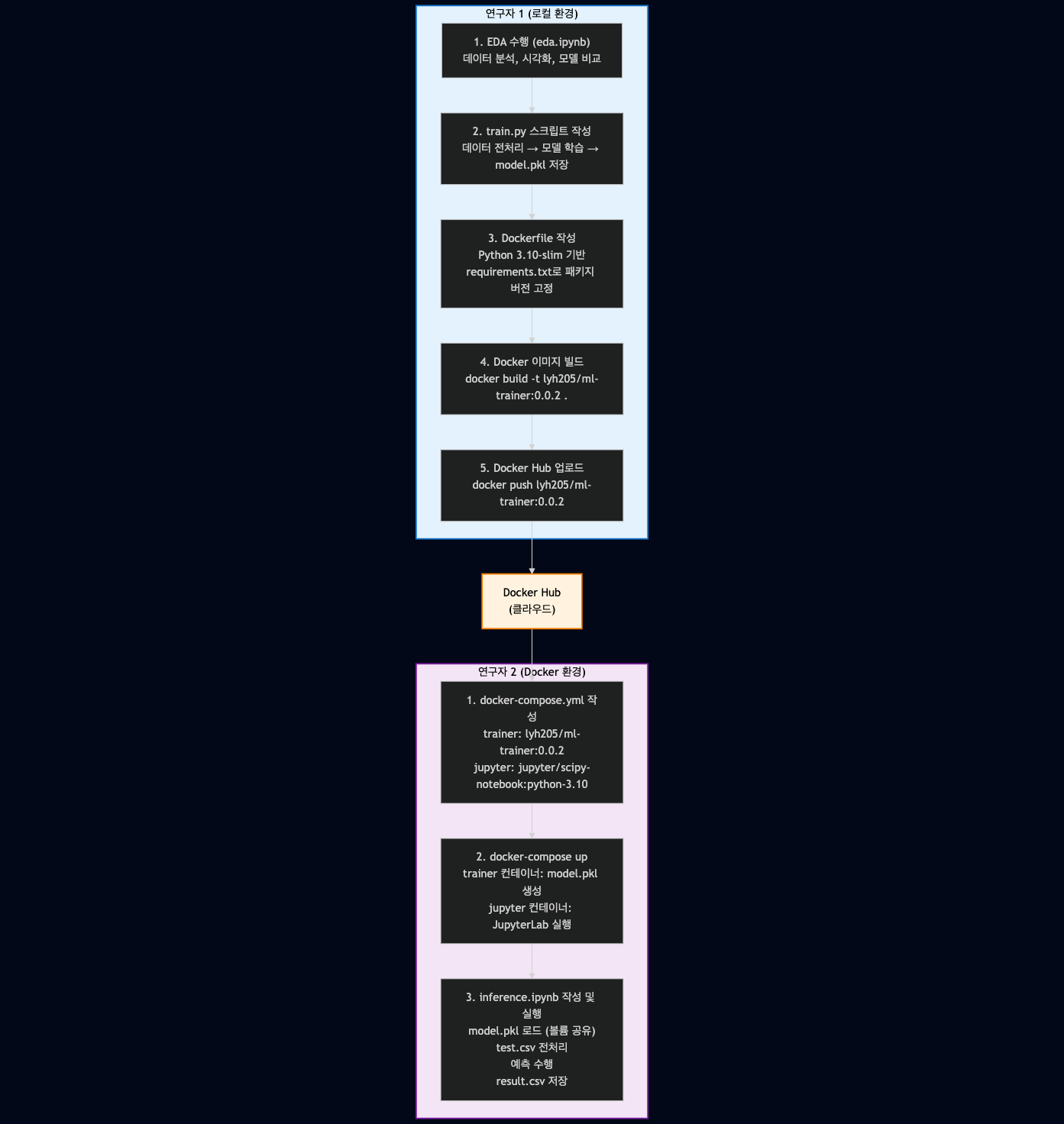
1.1 협업 시나리오
연구자 1
- [연구자 1]은
train.csv데이터를 기반으로 Jupyter Notebook(.ipynb)에서
데이터 전처리, 탐색적 데이터 분석(EDA), 그리고scikit-learn을 사용한 회귀 모델링을 수행한다. - 모델 성능은 RMSE로 평가하며, 최종 모델은
model.pkl파일로 저장한다. - 이후, 전처리 - 모델링 - 모델 저장 과정을 하나의
.py스크립트로 정리한다. - [연구자 1]은 이 작업을 자동화하는 도커 이미지를 구축하여 Docker Hub에 업로드한다.
연구자 2
- [연구자 2]는 [연구자 1]이 생성한 도커 이미지와 별도의 Jupyter Notebook 도커 이미지를
docker-compose로 구성한다. - [연구자 2]는 [연구자 1]의 도커 컨테이너에서 생성된
model.pkl파일과 컨테이너 내부의test.csv파일을 활용하여
Jupyter Notebook 컨테이너에서 추론을 수행하고, 결과를result.csv파일로 저장한다. - 전체 추론 과정이 담긴 inference.ipynb 파일을 별도로 저장한다.
(참고: [연구자 2]는 사전에 데이터나 모델 파일을 보유하지 않은 상태이며,
[연구자 1]의 Docker Hub 이미지를 통해 필요한 파일을 가져와야 한다.)
2. Docker Hub URL
Repository: https://hub.docker.com/r/lyh205/ml-trainer
사용 가능한 태그:
lyh205/ml-trainer:0.0.2(최신 버전, 649MB)lyh205/ml-trainer:latest(0.0.2와 동일)lyh205/ml-trainer:0.0.1(이전 버전, 671MB)
Pull 명령어:
docker pull lyh205/ml-trainer:0.0.23. 연구자 1의 데이터 전처리 및 모델링 결과
3.1 데이터셋 개요
- Train Set: 7,000개 샘플
- Test Set: 3,000개 샘플
- 특성 변수 (5개):
- Hours Studied (공부 시간)
- Previous Scores (이전 점수)
- Extracurricular Activities (과외 활동 여부)
- Sleep Hours (수면 시간)
- Sample Question Papers Practiced (모의고사 연습 수)
- 목표 변수: Performance Index (10-100)
3.2 데이터 전처리
- 결측치 처리: 결측치 없음
- 범주형 변수 인코딩: Extracurricular Activities (Yes=1, No=0)
- 데이터 분할: Train 80% (5,600개) / Validation 20% (1,400개)
3.3 모델 실험 결과
여러 모델을 비교 실험한 결과:
| 모델 | Train RMSE | Val RMSE | Val MAE | Val R² |
|---|---|---|---|---|
| Linear Regression | 2.51 | 2.48 | 1.93 | 0.982 |
| Ridge | 2.51 | 2.48 | 1.93 | 0.982 |
| Lasso | 2.51 | 2.48 | 1.93 | 0.982 |
| Random Forest | 0.75 | 2.24 | 1.71 | 0.986 |
| Gradient Boosting | 1.52 | 2.38 | 1.85 | 0.984 |
3.4 최종 모델 선정
선택된 모델: Random Forest Regressor
하이퍼파라미터:
- n_estimators: 100
- random_state: 42
- n_jobs: -1 (병렬 처리)
최종 성능 지표:
- Validation RMSE: 2.2437
- Validation MAE: 1.71
- Validation R²: 0.986
Feature Importance (상위 3개):
1. Previous Scores: 0.6421 (64.2%)
2. Hours Studied: 0.2157 (21.6%)
3. Sample Question Papers Practiced: 0.0842 (8.4%)
3.5 주요 발견 사항
- Previous Scores가 Performance Index에 가장 큰 영향 (64%)
- Hours Studied와 Performance Index 간 강한 양의 상관관계
- 과외 활동 참여 여부는 상대적으로 낮은 영향력
4. 코드 아키텍처 도식 및 설명
4.1 전체 워크플로우
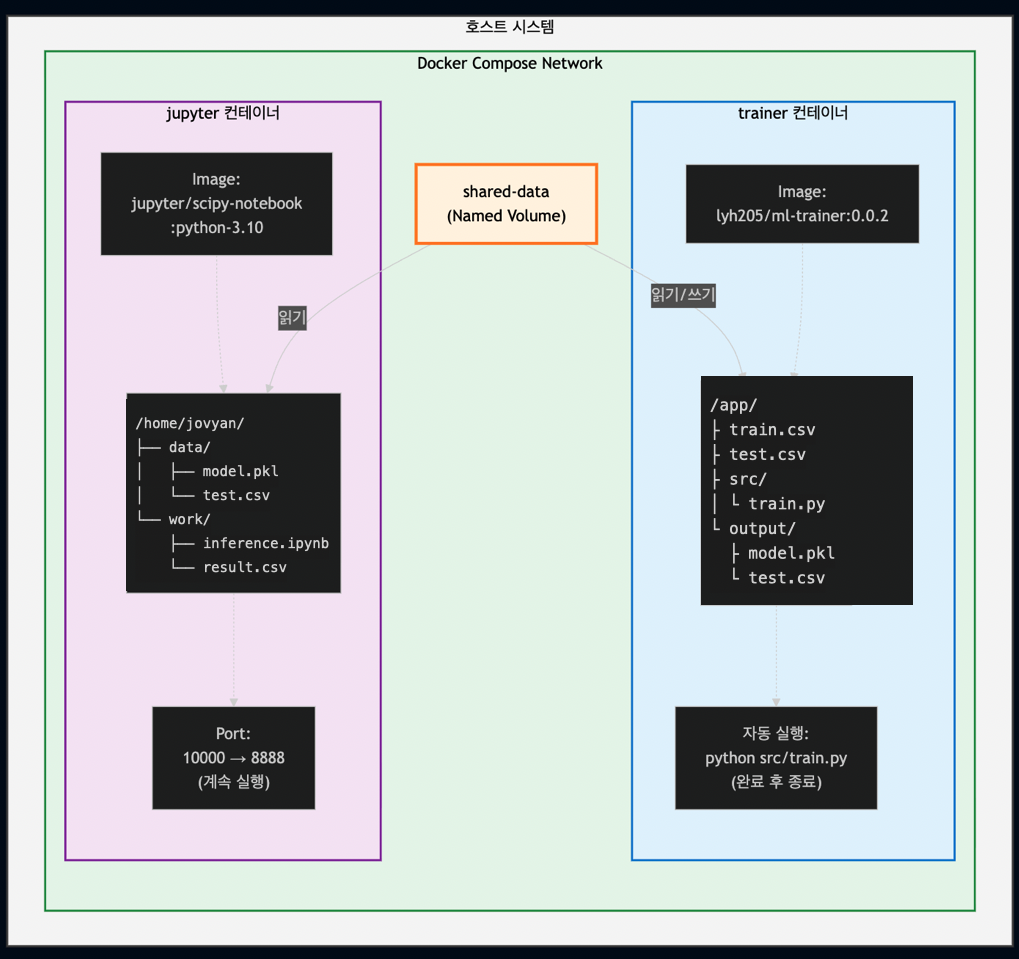
4.2 Docker 컨테이너 구조
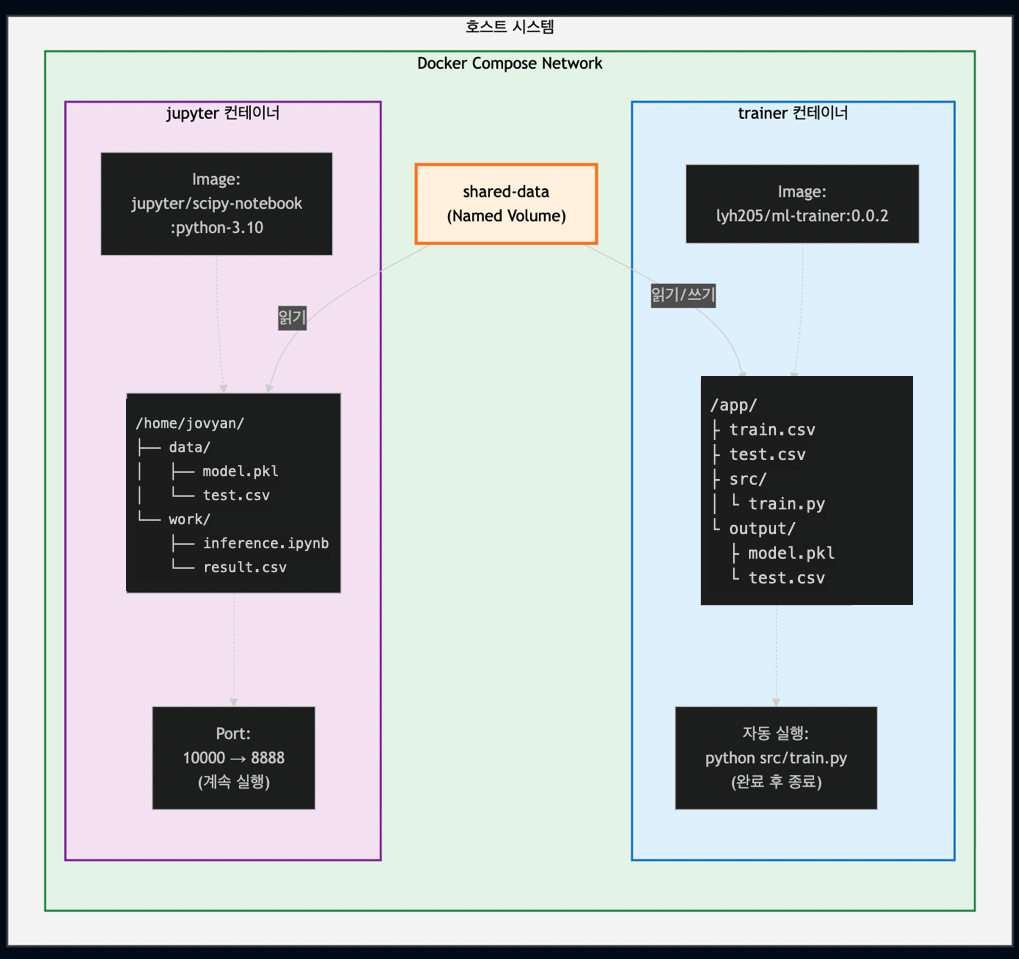
4.3 파일 공유 전략
1. Named Volume 사용 (shared-data)
volumes:
shared-data: # Docker가 관리하는 영구 볼륨
services:
trainer:
volumes:
- shared-data:/app/output # 쓰기 (model.pkl 생성)
jupyter:
volumes:
- shared-data:/home/jovyan/data # 읽기 (model.pkl 사용)2. 호스트 폴더 마운트
jupyter:
volumes:
- ./notebooks:/home/jovyan/work # 양방향 동기화장점:
- 컨테이너 간 데이터 공유 용이
- 영구 데이터 보존
- 호스트와 컨테이너 간 파일 동기화
5. 기술적 특징 및 고려사항
5.1 환경 일관성 보장
Python 버전 통일:
- 모든 컨테이너에서 Python 3.10 사용
python:3.10-slim베이스 이미지
패키지 버전 고정:
pandas==2.0.3
numpy==1.24.3
scikit-learn==1.3.0버전 불일치 해결:
- trainer와 jupyter 컨테이너 모두 동일한
requirements.txt사용 - docker-compose에서 jupyter 컨테이너 시작 시 자동 설치
5.2 컨테이너 간 의존성 관리
jupyter:
depends_on:
- trainer # trainer 컨테이너 먼저 시작실행 순서:
1. trainer 컨테이너 시작 → model.pkl 생성 → 종료
2. jupyter 컨테이너 시작 → model.pkl 사용 → 추론
5.3 보안 및 접근성
Jupyter Token 설정:
environment:
- JUPYTER_TOKEN=easy # 간편한 접근 (개발 환경용)포트 매핑:
- 호스트 10000번 포트 → 컨테이너 8888번 포트
- 충돌 방지 및 명시적 관리
5.4 이미지 최적화
슬림 이미지 사용:
python:3.10-slim(649MB)alpine대신slim사용 (C 컴파일러 필요)
레이어 캐싱:
COPY requirements.txt .
RUN pip install -r requirements.txt # 자주 변경 안 됨 (캐시)
COPY src/ ./src/ # 자주 변경됨6. 결론
본 프로젝트에서는 Docker를 활용하여 두 연구자가 서로 다른 환경에서 협업할 수 있는 ML 워크플로우를 성공적으로 구축하였습니다.
주요 성과:
1. ✅ 재현 가능한 환경 구축 (Docker 이미지)
2. ✅ 효율적인 파일 공유 메커니즘 (Named Volume)
3. ✅ 버전 일관성 보장 (requirements.txt)
4. ✅ 우수한 모델 성능 (RMSE 2.24, R² 0.986)
학습 내용:
- Docker 이미지 빌드 및 배포
- Docker Compose를 통한 멀티 컨테이너 오케스트레이션
- 볼륨을 통한 데이터 공유 전략
- 컨테이너 간 의존성 및 네트워크 관리
