- Agent(에이전트) = “LLM이 도구(tool) 를 선택·호출하며 목표를 달성하도록 이끄는 정책(Policy) + 상태(State) + 루프(Loop)”.
- RAG용 Agent는 단순 “질문→검색→생성” 체인보다 한 단계 더 나아가, 필요 시 여러 번 검색·요약·검증하고, 출처 인용·후처리(예: 표/코드/요약)까지 자동화한다.
- 구현은 보통 (1) 툴 정의(벡터DB retriever 등) → (2) 프롬프트/정책(예: ReAct) → (3) 상태/메모리 → (4) 종료 조건/가드레일 → (5) 로깅·평가 순서로 한다.
개념 정리 (What & Why)
Agent가 뭔가요?
- 정의: LLM이 상황을 해석(Reason) → 다음 행동을 결정(Act) → 툴 실행 결과를 반영(Observe) 하는 반복 루프를 갖춘 실행 주체.
- 구성:
• Policy(정책): ReAct, Plan-and-Execute, Toolformer, MRKL 등.
• Tools: 벡터 검색기(retriever), 웹 검색, 코드 실행기, 계산기, SQL, 함수/REST API…
• State/Memory: 대화 맥락, 조회된 문서, 중간 가설(scratchpad), 종료 플래그.
• Guardrails: 금칙어/PII 필터, 출처 미존재 시 재조회, 응답 길이/형식 규약. - RAG에서의 역할:
1. 쿼리 재작성(Query Rewriting) → 2) 다중 검색(Retrieval) → 3) 통합/랭킹 → 4) 답안 작성 + 근거 인용 → 5) 불확실성 판단 시 재시도/거절.
“일반 RAG 체인”과 “RAG 에이전트”의 차이
- 체인: 고정된 단계(분리 불가). “질문→임베딩→검색→생성” 일직선.
- 에이전트: 상황 따라 검색 반복/분기/도구 교체가 가능. 예) “출처가 모자라면 추가 검색 → 표로 정리 → 수치 검증 후 응답”.
아키텍처 (How)
사용자 질의
│
▼
[Agent Policy (ReAct/Planner)]
│ decide(tool? re-query? stop?)
├──► [Retriever Tool] ──► Vector DB(FAISS/Qdrant/Pinecone…)
├──► [Web Search/API Tool]
├──► [Calculator/Code Tool]
▼
중간 상태(State: thoughts, contexts, citations)
│ loop until: enough evidence / max_steps / timeout
▼
[Answer Synthesizer + Citation Formatter]
▼
최종 응답(근거/출처 포함)최소 재현 예제(Quick): LangChain Agents + Retriever Tool
목표: 로컬 문서를 벡터화하여 검색 툴로 등록하고, ReAct 에이전트가 필요 시 검색→답변을 수행하도록.
의존성 설치
pip install langchain langchain-community langchain-core langchain-openai
pip install sentence-transformers faiss-cpu
# (LLM은 원하는 백엔드 사용) OpenAI:
export OPENAI_API_KEY=YOUR_KEY
# 또는 로컬 LLM(Ollama 등)을 쓰려면 langchain-ollama 설치 후 ChatOllama 사용코드 (mre_agent.py)
# python >=3.10 권장
from langchain_core.documents import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import SentenceTransformerEmbeddings
from langchain.tools.retriever import create_retriever_tool
from langchain_openai import ChatOpenAI # 로컬 LLM이면 ChatOllama 등으로 교체
from langchain.agents import AgentExecutor, create_react_agent
from langchain_core.prompts import PromptTemplate
# 0) 샘플 문서 준비(실무에선 파일 로더 사용)
docs = [
Document(page_content="RAG는 검색-증거 기반으로 LLM 생성 품질을 높이는 기법입니다.", metadata={"source":"local:intro.md"}),
Document(page_content="FAISS는 로컬 벡터 색인 라이브러리로, 빠른 근접 검색을 지원합니다.", metadata={"source":"local:faiss.md"}),
Document(page_content="BGE-M3 임베딩은 다국어/멀티기능 임베딩으로 한국어에서도 성능이 좋습니다.", metadata={"source":"local:bge-m3.md"}),
]
# 1) 청크 & 임베딩 & 벡터스토어
splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)
chunks = splitter.split_documents(docs)
emb = SentenceTransformerEmbeddings(model_name="BAAI/bge-m3", encode_kwargs={"normalize_embeddings": True})
vs = FAISS.from_documents(chunks, emb)
retriever = vs.as_retriever(search_kwargs={"k":4})
# 2) 툴 정의(설명은 정책이 올바르게 선택하도록 매우 중요)
retriever_tool = create_retriever_tool(
retriever,
name="kb_search",
description=(
"사내/로컬 지식베이스 검색 도구. 질문의 근거가 필요하거나 모르는 정보일 때 호출하라. "
"항상 관련 문서의 'source'를 인용으로 남겨라."
),
)
tools = [retriever_tool]
# 3) LLM 및 ReAct 프롬프트(간결 버전)
prompt = PromptTemplate.from_template(
"""당신은 근거 기반으로 답하는 전문가 에이전트입니다.
도구를 적절히 사용해 사실을 확인하세요.
형식:
Thought: 문제에 대한 당신의 생각
Action: 사용할 도구 이름 (없으면 'none')
Action Input: JSON 또는 텍스트 입력
Observation: 도구의 결과
도구 사용을 반복하되, 충분한 근거가 모이면 'Final Answer:'로 답하세요.
반드시 근거 문서의 source를 '출처:'로 나열하세요.
질문: {input}
{agent_scratchpad}
"""
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0) # 또는 ChatOllama(model="llama3.1", temperature=0)
agent = create_react_agent(llm, tools, prompt)
executor = AgentExecutor(agent=agent, tools=tools, verbose=True, handle_parsing_errors=True)
def ask(q: str):
return executor.invoke({"input": q})["output"]
if __name__ == "__main__":
print(ask("RAG가 무엇이고, 관련 도구와 출처를 알려줘."))실행 방법
python mre_agent.py간단 테스트(“출처” 포함 여부)
python - <<'PY'
from mre_agent import ask
out = ask("FAISS와 BGE-M3를 어떻게 같이 쓰나요? 핵심만, 출처 표시.")
assert "출처" in out, "출처가 없습니다. 프롬프트/툴 설명을 점검하세요."
print("OK\n", out)
PY상태 제어가 필요한 실전형: LangGraph 스켈레톤
복잡한 분기(다중 재검색, 실패 복구, 최대 스텝, 가드레일)를 그래프 상태 기계로 명확히 관리.
# pip install langgraph
from typing import TypedDict, List, Any
from langgraph.graph import StateGraph, END
from langchain_core.messages import HumanMessage
# (llm, retriever는 위 예제 재사용)
class AgentState(TypedDict):
question: str
contexts: List[str]
citations: List[str]
steps: int
answer: str | None
MAX_STEPS = 3
def route(state: AgentState) -> str:
# 규칙 예: 근거 부족 or steps < MAX → retrieve, 아니면 synthesize
if len(state["contexts"]) < 2 and state["steps"] < MAX_STEPS:
return "retrieve"
return "synthesize"
def retrieve_node(state: AgentState) -> AgentState:
q = state["question"]
docs = retriever.get_relevant_documents(q)
ctxs = state["contexts"] + [d.page_content for d in docs]
cits = state["citations"] + [d.metadata.get("source","unknown") for d in docs]
return {**state, "contexts": ctxs, "citations": cits, "steps": state["steps"]+1}
def synthesize_node(state: AgentState) -> AgentState:
system = "주어진 contexts만으로 간결하고 정확히 답하세요. 항상 '출처:'를 포함."
prompt = f"Q: {state['question']}\n\nContexts:\n- " + "\n- ".join(state["contexts"])
msg = [HumanMessage(content=prompt)]
resp = llm.invoke(msg)
ans = f"{resp.content}\n\n출처: {sorted(set(state['citations']))}"
return {**state, "answer": ans}
g = StateGraph(AgentState)
g.add_node("retrieve", retrieve_node)
g.add_node("synthesize", synthesize_node)
g.set_entry_point("retrieve")
g.add_conditional_edges("retrieve", route, {"retrieve":"retrieve", "synthesize":"synthesize"})
g.add_edge("synthesize", END)
graph = g.compile()
# 사용 예시
# result = graph.invoke({"question":"RAG와 벡터DB 관계?", "contexts":[], "citations":[], "steps":0, "answer":None})
# print(result["answer"])프로덕션 체크리스트
• 프롬프트/정책
• ReAct vs Plan-and-Execute 중 택1(+실험).
• “출처 없으면 재검색” 규칙, “불확실 시 거절” 문구 명시.
• 툴 설계
• Retriever 설명에 언제·왜 써야 하는지 구체적으로.
• 검색 k, 임베딩(normalize), 메타데이터(source,title,url,section) 보존.
• 상태 & 가드레일
• MAX_STEPS, 토큰 상한, 시간 제한.
• PII/정책 필터(전후처리), 응답 템플릿(요약/표/코드 블록).
• 관측성
• 로그/트레이스(각 Thought/Action/Observation), 실패율, 재시도율.
• 평가(offline/online)
• RAGAS: faithfulness, answer/retrieval relevancy, context precision/recall.
• A/B: 사용자 만족도, 클릭률, 피드백 태그(“근거부족/느림/정확/불친절”).
• 성능/비용
• 캐시, rerank(한번 더 랭킹), 쿼리 재작성, 임베딩 배치, partial compress(summary) 저장.
• 보안
• 비공개 문서 스코프, 감사로그, 출처 마스킹 옵션.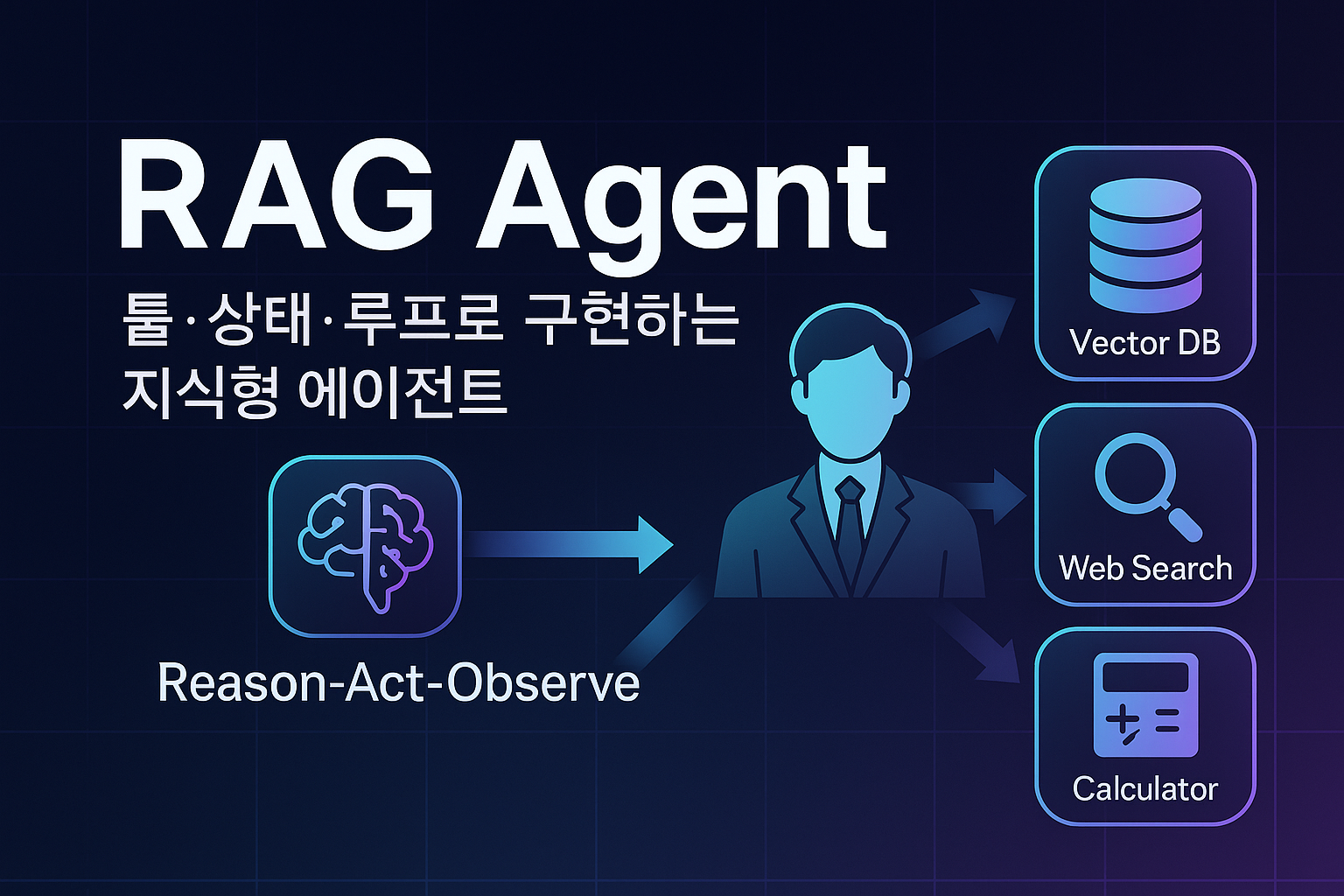

개발자