2022.06.27 연구실 공부(PyTorch). 'PyTorch로 시작하는 딥 러닝 입문'< 이 글은 이 책의 내용을 요약 정리한 것임.>(내 저작물이 아니고 저 위 링크에 있는 것이 원본임)
03-04 nn.Module로 구현하는 선형 회귀, 03-05 클래스로 파이토치 모델 구현하기, 03-06 Mini Batch and Data Load, 03-07 Custom Dataset
Summary
- Linear Regression with nn.Module
- Linear Regression with Class
- Mini Batch and Data Load
- Custom Dataset
1. Linear Regression with nn.Module
1-1. Simple Linear Regression
- 필요한 도구 임포트 및 랜덤 시드 고정
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(1)- y=2x라는 식에 맞는 데이터를 미리 준비 후, W,b의 값을 잘 찾는지 확인
# 데이터
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[2], [4], [6]])- nn.Linear()로 선형 회귀 모델 구현
- nn.Linear() : 입력의 차원, 출력의 차원을 인수로 받음
# 모델을 선언 및 초기화. 단순 선형 회귀이므로 input_dim=1, output_dim=1.
model = nn.Linear(1,1)- 위 식(y=2x)은 하나의 입력(x)에 대해 하나의 출력(y)를 가지므로 입력 차원과 출력 차원 모두 1이다.
- model.parameters() : 가중치 W와 편향 b를 저장함
- 옵티마이저 정의 -> model.parameters()를 사용하여 W와 b를 전달(학습률(learning rate)은 0.01)
# optimizer 설정. 경사 하강법 SGD를 사용하고 learning rate를 의미하는 lr은 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) - 모델 코드
# 전체 훈련 데이터에 대해 경사 하강법을 2,000회 반복
nb_epochs = 2000
for epoch in range(nb_epochs+1):
# H(x) 계산
prediction = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train) # <== 파이토치에서 제공하는 평균 제곱 오차 함수
# cost로 H(x) 개선하는 부분
# gradient를 0으로 초기화
optimizer.zero_grad()
# 비용 함수를 미분하여 gradient 계산
cost.backward() # backward 연산
# W와 b를 업데이트
optimizer.step()
if epoch % 100 == 0:
# 100번마다 로그 출력
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))- 출력(2000 epoch를 100 epoch씩 출력)
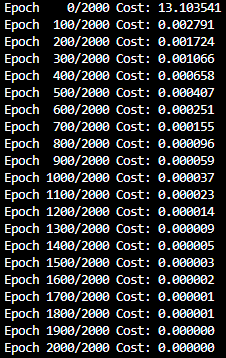
- cost는 거의 0에 가까움, 예측 값(x=4이면 y는 8이 나와야 함)
# 임의의 입력 4를 선언
new_var = torch.FloatTensor([[4.0]])
# 입력한 값 4에 대해서 예측값 y를 리턴받아서 pred_y에 저장
pred_y = model(new_var) # forward 연산
# y = 2x 이므로 입력이 4라면 y가 8에 가까운 값이 나와야 제대로 학습이 된 것
print("훈련 후 입력이 4일 때의 예측값 :", pred_y) 훈련 후 입력이 4일 때의 예측값 : tensor([[7.9989]], grad_fn=<AddmmBackward0>) - 7.9989는 8에 매우 가까우므로 최적화가 잘 되었다고 할 수 있음.
- W, b 출력
print(list(model.parameters()))[Parameter containing:
tensor([[1.9994]], requires_grad=True), Parameter containing:
tensor([0.0014], requires_grad=True)]- W가 1.9994로 2에 매우 가깝고, b는 0.0014로 0에 매우 가까우므로 이 모델은 최적화가 잘 된 것을 알 수 있음.
1-2. Multivariable Linear Regression
- 필요한 도구 임포트 및 랜덤 시드 고정
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(1)- H(x) = w1x1 + w2x2 + w3x3 + w4x4 + b라는 식에 맞는 데이터를 미리 준비 후, W,b의 값을 잘 찾는지 확인
# 훈련 데이터
x_train = torch.FloatTensor([[78, 80, 98, 75],
[84, 76, 87, 72],
[79, 87, 95, 80],
[96, 92, 94, 100],
[75, 92, 85, 89]])
y_train = torch.FloatTensor([[142], [138], [171], [152], [169]])- Linear Regression 모델 구현
- nn.Linear() : 입력의 차원, 출력의 차원을 인수로 받음
# 모델을 선언 및 초기화. 다중 선형 회귀이므로 input_dim=4, output_dim=1.
model = nn.Linear(4,1)- model.parameters() : W, b를 불러옴
print(list(model.parameters()))[Parameter containing:
tensor([[ 0.2576, -0.2207, -0.0969, 0.2347]], requires_grad=True), Parameter containing:
tensor([-0.4707], requires_grad=True)]- 옵티마이저 정의 : 학습률을 0.01이 아닌 0.000001 -> (1e-6)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-6)- 이후로는 Simple 버전의 Linear Regression 구현 코드와 같음
nb_epochs = 2000
for epoch in range(nb_epochs+1):
# H(x) 계산
prediction = model(x_train)
# model(x_train)은 model.forward(x_train)와 동일함.
# cost 계산
cost = F.mse_loss(prediction, y_train) # <== 파이토치에서 제공하는 평균 제곱 오차 함수
# cost로 H(x) 개선하는 부분
# gradient를 0으로 초기화
optimizer.zero_grad()
# 비용 함수를 미분하여 gradient 계산
cost.backward()
# W와 b를 업데이트
optimizer.step()
if epoch % 100 == 0:
# 100번마다 로그 출력
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))- 출력(2000 epoch를 100 epoch씩 출력)
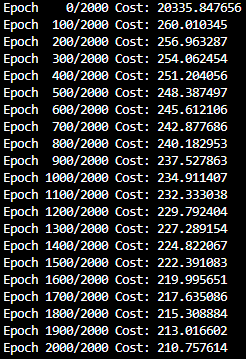
- 예제는 특성이 3개라 cost가 매우 작지만 이 글에서는 특성이 4개라 cost 값이 더 큼
- 따라서 cost를 줄이기 위해 epoch 수를 1000000번으로 늘리고 10000 epoch씩 출력함.

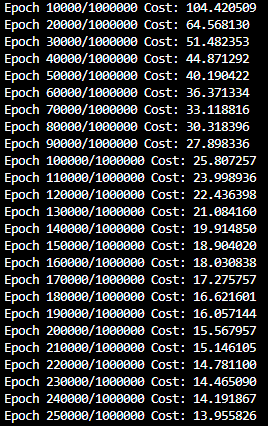
- 초기에는 꽤 큰 폭으로 cost값이 낮아짐
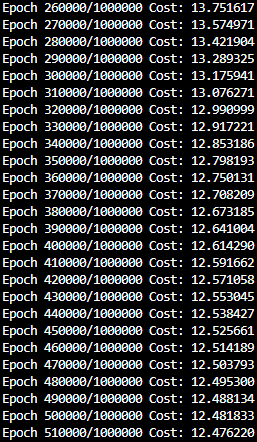
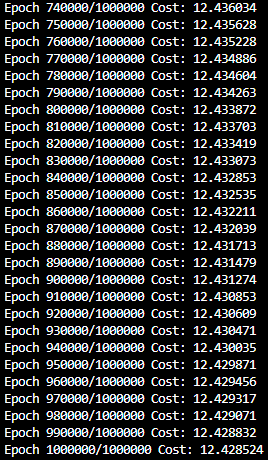
- 750000 epoch 부터는 사실상 의미있게 cost값이 변화하지 않음.
- 행렬의 가장 첫 줄에 넣은 78, 80, 98, 75를 model에 넣고 y값 예측
# 임의의 입력 [78, 80, 98, 75]를 선언
new_var = torch.FloatTensor([[78, 80, 98, 75]])
# 입력한 값 [78, 80, 98, 75]에 대해서 예측값 y를 리턴받아서 pred_y에 저장
pred_y = model(new_var)
print("훈련 후 입력이 78, 80, 98, 75일 때의 예측값 :", pred_y) 훈련 후 입력이 78, 80, 98, 75일 때의 예측값 : tensor([[144.9786]], grad_fn=<AddmmBackward0>)- 결과를 보면 y를 144.9786으로 예측하였는데, 이는 처음에 넣은 y값에 142에 어느정도 가깝다고 할 수 있음. -> w, b가 어느정도 최적화가 된 것으로 보임.
- 예제는 152를 151로 예측하였지만 특성이 3개였고 cost도 2000 epoch때 0.199였으나 이 글의 코드는 특성이 4개에 cost도 1000000 epoch때 12.428 이므로 약간 오차가 더 클 수 있음.
- w와 b의 값 출력
print(list(model.parameters()))[Parameter containing:
tensor([[ 0.0965, 3.9217, -0.4203, -1.7940]], requires_grad=True), Parameter containing:
tensor([-0.5472], requires_grad=True)]2. Linear Regression with Class
2-1. Simple Linear Regression
- class 형태로 모델을 정의할 경우, nn.Module을 상속 받음.
- _._init__() : 모델의 구조와 동작을 정의하는 생성자를 정의(. 은 md 문법 방지용임)
- super() : 여기서 만든 클래스는 nn.Module 클래스의 속성들을 가지고 초기화
- foward() : 모델이 학습데이터를 입력받아서 forward 연산을 진행, model 객체를 데이터와 함께 호출하면 자동으로 실행(H(x) 식에 x로부터 예측된 y를 얻는 것을 forward 연산이라 함)
class LinearRegressionModel(nn.Module): # torch.nn.Module을 상속받는 파이썬 클래스
def __init__(self): #
super().__init__()
self.linear = nn.Linear(1, 1) # 단순 선형 회귀이므로 input_dim=1, output_dim=1.
def forward(self, x):
return self.linear(x)
model = LinearRegressionModel()- 전체 구현 코드
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(1)
# 데이터
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[2], [4], [6]])
class LinearRegressionModel(nn.Module): # torch.nn.Module을 상속받는 파이썬 클래스
def __init__(self): #
super().__init__()
self.linear = nn.Linear(1, 1) # 단순 선형 회귀이므로 input_dim=1, output_dim=1.
def forward(self, x):
return self.linear(x)
model = LinearRegressionModel()
# optimizer 설정. 경사 하강법 SGD를 사용하고 learning rate를 의미하는 lr은 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 전체 훈련 데이터에 대해 경사 하강법을 2,000회 반복
nb_epochs = 2000
for epoch in range(nb_epochs+1):
# H(x) 계산
prediction = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train) # <== 파이토치에서 제공하는 평균 제곱 오차 함수
# cost로 H(x) 개선하는 부분
# gradient를 0으로 초기화
optimizer.zero_grad()
# 비용 함수를 미분하여 gradient 계산
cost.backward() # backward 연산
# W와 b를 업데이트
optimizer.step()
if epoch % 100 == 0:
# 100번마다 로그 출력
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))- 출력(2000 epoch를 100 epoch씩)
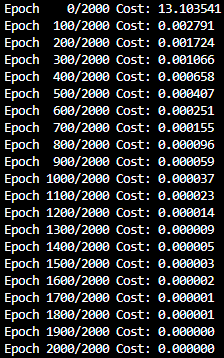
2-2. Multivariable Linear Regression
- class로 구현한 것 외에는 앞선 다중 선형 회귀(Multivariable Linear Regression)와 같다.
- 전체 구현 코드
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(1)
# 데이터
x_train = torch.FloatTensor([[78, 80, 98, 75],
[84, 76, 87, 72],
[79, 87, 95, 80],
[96, 92, 94, 100],
[75, 92, 85, 89]])
y_train = torch.FloatTensor([[142], [138], [171], [152], [169]])
class MultivariateLinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(4, 1) # 다중 선형 회귀이므로 input_dim=4, output_dim=1.
def forward(self, x):
return self.linear(x)
model = MultivariateLinearRegressionModel()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-5)
nb_epochs = 1000000
for epoch in range(nb_epochs+1):
# H(x) 계산
prediction = model(x_train)
# model(x_train)은 model.forward(x_train)와 동일함.
# cost 계산
cost = F.mse_loss(prediction, y_train) # <== 파이토치에서 제공하는 평균 제곱 오차 함수
# cost로 H(x) 개선하는 부분
# gradient를 0으로 초기화
optimizer.zero_grad()
# 비용 함수를 미분하여 gradient 계산
cost.backward()
# W와 b를 업데이트
optimizer.step()
if epoch % 100000 == 0:
# 100000번마다 로그 출력
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))- 출력(1000000 epoch를 100000 epoch씩)
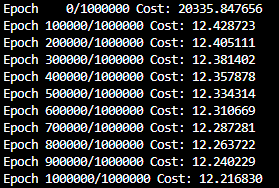
3. Mini Batch and Data Load
3-1. Mini Batch and Batch Size
- Mini Batch : 큰 전체 데이터를 작은 단위로 나누어서 해당 단위로 학습하는 것 for 계산시간, 메모리 등
- Batch Size : 미니 배치의 개수는 결국 미니 배치의 크기를 몇으로 하느냐에 따라서 달라지는데 여기서 미니 배치의 개수를 결정하는 크기를 Batch Size라고 한다.
- Minibatch Gradient Descent : 미니 배치 단위로 경사 하강법(Gradient Descent)을 수행하는 방법, 훈련 속도가 빠르나 최적값 수렴 과정에서 값을 조금 헤매기도 함.
- 배치 크기는 보통 2의 제곱수를 사용( ex) 2, 4, 8, 16, 32, 64... ) 왜냐하면 CPU와 GPU의 메모리가 2의 배수이므로 배치크기가 2의 제곱수일 경우에 데이터 송수신의 효율을 높일 수 있으므로
3-2. Iteration
- iteration, mini batch, batch size, epoch 의 관계

- iteration : 한 번의 epoch 내에서 이루어지는 매개변수인 가중치 W와 b의 업데이트 횟수
- 2,000일 때 배치 크기를 200으로 한다면 이터레이션의 수는 총 10개
3-3. Data Load
- 기본적인 파이토치의 도구들을 임포트
import torch
import torch.nn as nn
import torch.nn.functional as F- TensorDataset과 DataLoader를 임포트
from torch.utils.data import TensorDataset # 텐서데이터셋
from torch.utils.data import DataLoader # 데이터로더- TensorDataset은 기본적으로 Tensor를 입력받고 Tensor 형태로 데이터를 정의
# 데이터
x_train = torch.FloatTensor([[78, 80, 98, 75],
[84, 76, 87, 72],
[79, 87, 95, 80],
[96, 92, 94, 100],
[75, 92, 85, 89]])
y_train = torch.FloatTensor([[142], [138], [171], [152], [169]])- TensorDataset의 입력으로 사용하고 dataset으로 저장
dataset = TensorDataset(x_train, y_train)- DataLoader로 데이터 불러오기(dataset, batch_size, shuffle 등의 매개변수)
- Shuffle의 의미 : 데이터가 같은 순서로 나오는 것을 방지 -> 데이터 셋을 섞음
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)- 모델과 옵티마이저를 설계
model = nn.Linear(4,1)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-6) - 모델 학습 진행 코드
nb_epochs = 200
for epoch in range(nb_epochs + 1):
for batch_idx, samples in enumerate(dataloader):
# print(batch_idx)
# print(samples)
x_train, y_train = samples
# H(x) 계산
prediction = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train)
# cost로 H(x) 계산
optimizer.zero_grad()
cost.backward()
optimizer.step()
print('Epoch {:4d}/{} Batch {}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, batch_idx+1, len(dataloader),
cost.item()
))- 200 epoch 출력

- cost를 더 낮춘 최적화된 모델을 위해 1000000 epoch를 100000 epoch 단위로 출력
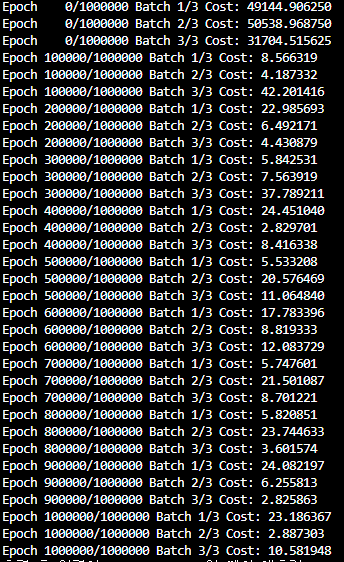
- 모델에 임의의 값 넣어 예측값 확인
# 임의의 입력 [78, 80, 98, 75]를 선언
new_var = torch.FloatTensor([[78, 80, 98, 75]])
# 입력한 값 [78, 80, 98, 75]에 대해서 예측값 y를 리턴받아서 pred_y에 저장
pred_y = model(new_var)
print("훈련 후 입력이 78, 80, 98, 75일 때의 예측값 :", pred_y)
```python
```python
훈련 후 입력이 78, 80, 98, 75일 때의 예측값 : tensor([[144.8790]], grad_fn=<AddmmBackward0>)- 입력한 y값이 142였는데, 예측값은 144이므로 최적화가 잘 되었음을 확인할 수 있음.
4. Custom Dataset
4-1. Custom Dataset의 개념
- torch.utils.data.Dataset을 상속받아 직접 커스텀 데이터셋(Custom Dataset)을 만드는 경우도 있다!
- Custom Dataset의 기본적인 뼈대
class CustomDataset(torch.utils.data.Dataset):
def __init__(self):
데이터셋의 전처리를 해주는 부분
def __len__(self):
데이터셋의 길이. 즉, 총 샘플의 수를 적어주는 부분
def __getitem__(self, idx):
데이터셋에서 특정 1개의 샘플을 가져오는 함수4-2. Linear Regression with Custom Dataset
- Custom Dataset을 활용한 Linear Regression
- _._init__(self) : dataset을 초기화하는 생성자 정의(. 은 md 방지용)
- _._len__(self) : 총 데이터의 개수를 리턴(. 은 md 방지용)
- _._getitem__(self, idx) : 인덱스(idx)를 입력받아 그에 맵핑되는 입출력 데이터를 파이토치의 Tensor 형태로 리턴(. 은 md 방지용)
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# Dataset 상속
class CustomDataset(Dataset):
def __init__(self):
self.x_data = [[78, 80, 98, 75],
[84, 76, 87, 72],
[79, 87, 95, 80],
[96, 92, 94, 100],
[75, 92, 85, 89]]
self.y_data = [[142], [138], [171], [152], [169]]
# 총 데이터의 개수를 리턴
def __len__(self):
return len(self.x_data)
# 인덱스를 입력받아 그에 맵핑되는 입출력 데이터를 파이토치의 Tensor 형태로 리턴
def __getitem__(self, idx):
x = torch.FloatTensor(self.x_data[idx])
y = torch.FloatTensor(self.y_data[idx])
return x, y
dataset = CustomDataset()
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
model = torch.nn.Linear(4,1)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-6)
nb_epochs = 1000000
for epoch in range(nb_epochs + 1):
for batch_idx, samples in enumerate(dataloader):
# print(batch_idx)
# print(samples)
x_train, y_train = samples
# H(x) 계산
prediction = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train)
# cost로 H(x) 계산
optimizer.zero_grad()
cost.backward()
optimizer.step()
if epoch % 100000 == 0:
# 100000번마다 로그 출력
print('Epoch {:4d}/{} Batch {}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, batch_idx+1, len(dataloader),
cost.item()
))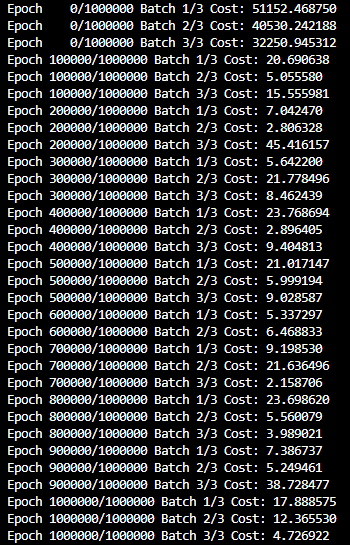
- 임의의 값을 넣어 예측값 확인
# 임의의 입력 [78, 80, 98, 75]를 선언
new_var = torch.FloatTensor([[78, 80, 98, 75]])
# 입력한 값 [78, 80, 98, 75]에 대해서 예측값 y를 리턴받아서 pred_y에 저장
pred_y = model(new_var)
print("훈련 후 입력이 78, 80, 98, 75일 때의 예측값 :", pred_y)훈련 후 입력이 78, 80, 98, 75일 때의 예측값 : tensor([[145.1231]], grad_fn=<AddmmBackward0>) - 입력한 y값이 142였는데, 예측값은 145이므로 최적화가 잘 되었음을 확인할 수 있음.
출처 : 'PyTorch로 시작하는 딥 러닝 입문' <이 책의 내용을 요약 정리한 것임.>

매일 매일 새로워지는 나 자신을 꿈꾸며