#1. LLM의 한계 및 방안
1) LLM의 한계
- LLM(Large Language Model)은 딥러닝 기반 모델로서 긴 문장 처리와 학습 데이터의 정보량에 한계를 가진다.
1. 환각 현상
-
딥러닝 모델의 학습 한계: 학습된 데이터 이외의 정보에 취약함
- 오픈AI의 최신 모델인 GPT-4o는 2023년 9월까지, Claude Sonnet 3.5는 2024년 4월까지의 데이터로 학습되어, 이후의 정보는 알지 못한다.
2. 기억 불가
-
LLM은 사전학습 시에 받아들인 정보 외의 것은 배우지 못한다.
- 따라서 오픈AI의 GPT-4o와 Anthropic의 Claude Sonnet 3.5는 이후에 대한 대화나 내용을 기억하지 못한다.
3. 토큰 제한
-
LLM은 입력값의 길이가 길어지면 계산량이 크게 늘어나, 대부분의 모델이 단일 입력값에 대해 길이 제한이 존재함.
- 예: GPT-4o의 입력값 제한은 128,000토큰(문자 단위), Claude Sonnet 3.5도 200,000토큰이다.
2) RAG(Retrieval-Augmented Generation)
RAG란?
-
RAG(Retrieval-Augmented Generation)는 AI 모델이 외부 데이터베이스에서 관련 정보를 검색하고, 이를 활용하여 더 정확하고 최신의 응답을 생성하는 기술.
-
이를 통해 LLM이 가진 한계를 극복할 수 있음.
1. Retrieval (검색)
-
사용자의 질문이나 프롬프트 입력
-
입력 내용 분석 → 키워드/의미 추출
-
추출된 정보 기반으로 DB에서 관련 정보 검색
- 문서, 단락, 데이터 조각 등 다양한 형태로 검색
-
벡터 유사도 기반 검색 기술 활용
2. Augmented (보강)
-
검색된 정보와 사용자의 원래 질문/프롬프트 결합
-
정보의 적절성과 품질 평가 → 선별
-
선별된 정보를 프롬프트에 추가하여 보강된 입력 생성
-
문맥, 문체, 정보 양 등에 맞춰 조정
-
정확하고 관련성 높은 응답 생성을 위한 기반 마련
3. Generation (생성)
-
보강된 프롬프트를 LLM에 입력
-
LLM이 이를 기반으로:
- 기존 지식 + 새로운 정보 반영
- 다양한 형태(답변, 요약, 분석 등)로 응답 생성
-
최종적으로 사용자에게 적절한 응답 제공
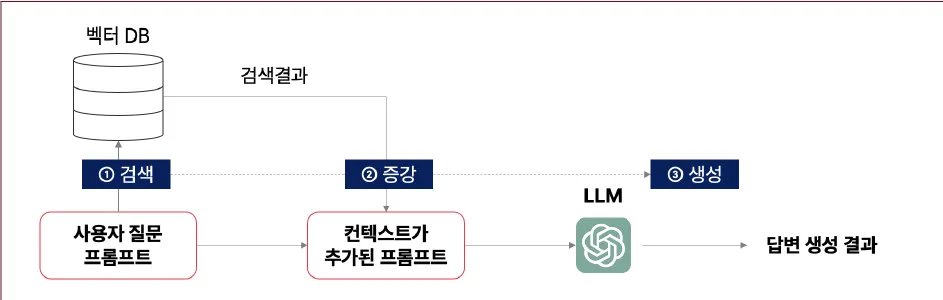
3) RAG 파이프라인
4) RAG의 한계
RAG의 한계
-
RAG 시스템은 외부 지식 기반에서 정보를 검색해 답변을 생성하지만, 정확한 응답을 위해 검색 단계의 정교함이 매우 중요함.
-
검색 과정을 크게 두 단계로 나눔:
- Pre-Retrieval (사전 처리 단계 / Indexing)
- Retrieval & Post-Retrieval (검색 및 후처리 단계)
Naive RAG 파이프라인의 문제
-
사용자 질문 → 벡터 DB에서 검색 → 관련 문서 조각(Retrieved Chunk) 추가 → 응답 생성
-
문제: 검색 정확도가 낮으면 잘못된 문서를 기반으로 한 부정확한 응답 발생 가능
1. Pre-Retrieval (Indexing: 문서를 벡터 DB에 저장하는 단계)
-
문서 → 분할(Chunking) → 임베딩(Embedding) → 벡터 DB에 저장
-
고려할 점:
- 문서를 어떤 기준으로 나눌지 (단락, 의미 단위 등)
- 어떤 임베딩 모델을 사용할지
- 메타데이터 활용 여부 등
-
이 단계가 부실하면 검색 품질이 전체적으로 낮아짐
시행착오가 필수적!
2. Retrieval & Post-Retrieval (검색 및 후처리 단계)
-
사용자 질문 → 임베딩 → 벡터 DB에서 검색 → 관련 문서 조각 검색
-
하지만...
- 적절하지 않은 문서가 검색되기도 함
- 추가적인 정렬/재구성/필터링 없이는 정확도 떨어짐
-
검색 후에도 불필요하거나 오래된 정보 제거, 유사 문서 통합 등 후처리 작업 필요
요약
-
RAG 성능을 높이려면:
- 문서 저장 단계(Pre-Retrieval)에서 분할, 임베딩 전략을 잘 설정해야 하고
- 검색 이후 단계(Post-Retrieval)에서는 정제, 필터링 등의 후처리 작업이 중요함
5) LLM vs RAG vs AI Agent
역할 및 주요 기능
| 구분 | LLM | RAG | AI 에이전트 |
|---|---|---|---|
| 역할 | 두뇌 | 정보 수집 | 작업 관리자 |
| 주요 기능 | 질문 이해, 자연어 처리, 응답 생성 | 외부 DB 또는 웹에서 정보 검색 | 목표 설정, 계획 생성, 작업 실행, 재계획 |
상세 비교
| 항목 | LLM | RAG | AI 에이전트 |
|---|---|---|---|
| 핵심 역할 | 텍스트 생성 | 검색 + 생성 | 작업 계획 + 실행 + 재계획 |
| 구성 요소 | 단일 LLM | LLM + 검색 엔진 | LLM + 계획 + 메모리 + 실행 |
| 도구 사용 | 불가능 | 제한적 (검색 도구만) | 광범위 (API, 코드 실행 등) |
| 정보 출처 | 훈련 데이터만 사용 | 훈련 데이터 + 검색 데이터 | 훈련 데이터 + 웹 검색 + 작업 결과 |
| 실시간 정보 | ✕ | 웹에서 실시간 검색 가능 | 웹 검색, 작업 실행 |
| 목표 지향성 | 단일 질문에 대한 응답만 | 단일 질문에 대한 응답만 | 사용자의 목표에 맞춰 스스로 작업 실행 |
| 자율성 | 낮음 | 중간 | 높음 |
| 복잡한 작업 수행 | 단일 응답 생성만 가능 | 지식 기반 응답만 가능 | 다단계 작업 수행 가능 |
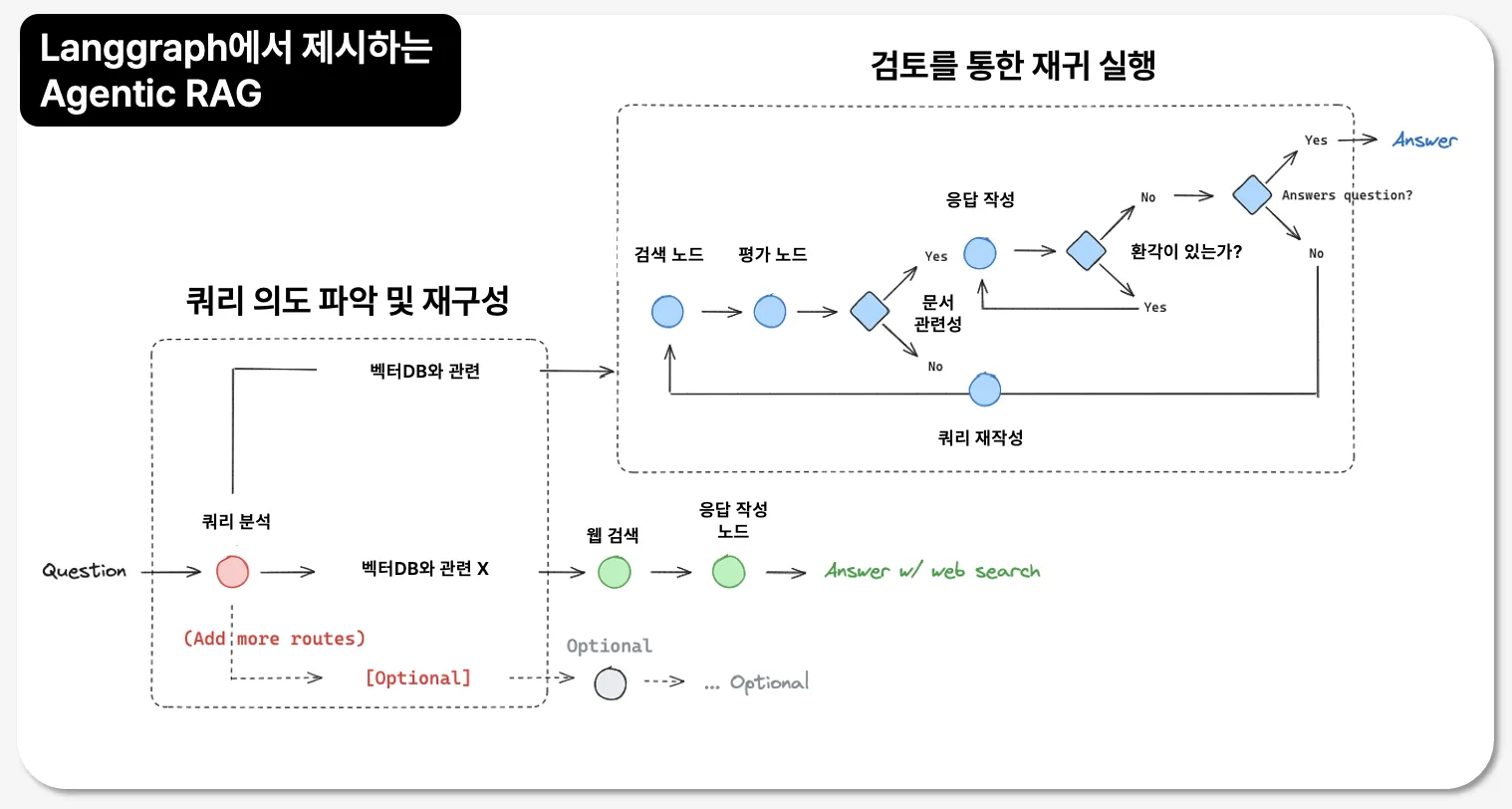
사용자 질문 → 임베딩 → 웹 검색 → 문서 조각화 → **유사도 평가** → 정보 선별 → LLM 응답 생성6) Agent RAG를 통한 한계 극복
#1. AI Agent 이해
AI Evolution
AI Evolution: Model to Intelligence
AI는 좁은 작업만 가능한 수준에서부터 사람처럼 사고하고 추론할 수 있는 수준까지 진화하는 흐름으로 설명됨.
1. ANI (Artificial Narrow Intelligence) – 인공지능 1단계
: 특정 업무(또는 분야)에 특화된 인공지능
-
정의: 단 하나의 작업만 잘 수행하는 AI. 범용성이 없음.
-
기술적 특징:
- 규칙 기반 시스템 (예: 전문가 시스템)
- 전통적인 머신러닝 알고리즘 (SVM, XGBoost, Ensemble 등)
- 딥러닝 서비스 (얼굴 인식, 바둑 AI 등)
-
예시:
- 챗봇, 바둑 AI(알파고), 스팸 필터, 얼굴 인식
2. G.AI (Generative AI) – 생성형 인공지능
: 다양한 콘텐츠를 생성하고, 여러 감각 정보를 이해하는 인공지능
-
Single Modal (단일 모달)
: 하나의 형태(모달리티)에 집중된 생성 AI
- 텍스트: ChatGPT, GPT 등 LLM
- 이미지: DALL·E, Stable Diffusion, Midjourney
- 음성: TTS(Text-to-Speech), Voice Conversion, AI 작곡 등
-
Multi Modal (다중 모달)
: 텍스트 + 이미지 + 오디오 + 비디오 등 여러 정보를 함께 처리
- 예: GPT-4(Vision), Flamingo, Kosmos-2
- 텍스트와 이미지를 동시에 이해하고 응답 가능 (예: 이미지 설명)
-
Actuation with Perception (감각 기반 제어)
: 인공지능이 **행동(Action)**과 **감지(Perception)**를 통합해서 실제 동작을 수행
- 로봇 제어 AI: 휴머노이드, 산업 로봇
- 자율주행 자동차, 드론 등
- Perception-Action Loop: 감지 → 판단 → 동작 반복
3. AGI (Artificial General Intelligence) – 범용 인공지능
: 인간 수준의 광범위하고 유연한 추론, 학습 능력을 가진 AI (아직 존재하지 않음)
-
목표: 사람처럼 사고하고, 여러 분야에서 자유롭게 문제 해결
-
특징:
- 한 가지가 아니라 모든 지식 영역에서 자유롭게 학습, 응용 가능
- 현재는 개념적인 목표일 뿐 실현된 사례 없음
-
*더 나아가면 → ASI (초지능)**로 진화 가능성도 있음
핵심 정리
| 구분 | 설명 | 예시 |
|---|---|---|
| ANI | 특정 업무 전용 AI | 얼굴 인식, 추천 시스템 |
| G.AI | 생성 + 이해 + 행동 기반 AI | ChatGPT, DALL·E, GPT-4V |
| AGI | 인간처럼 다방면 문제 해결 가능한 AI | 아직 없음 (연구 중) |
1. Tool
AI Agent는 크게 Tool과 LLM으로 이루어짐
1. Tools: LangChain의 핵심 인터페이스
Tools(도구)는 Agent, Chain, 또는 LLM이 외부 시스템이나 기능과 상호작용할 수 있게 하는 인터페이스입니다.
Tools의 종류
LangChain에서는 도구를 두 가지 방식으로 제공/정의할 수 있습니다:
① Built-in Tools (내장 도구)
-
LangChain에서 기본 제공하는 사전 정의된 도구와 툴킷(toolkit)
-
Tool: 하나의 기능을 수행하는 단위 도구
-
Toolkit: 여러 개의 Tool을 묶어 하나로 구성한 도구 모음
-
대표 예시:
- 검색 도구, 계산기, 웹 브라우징 도구 등
-
공식 문서 링크:
② Custom Tools (사용자 정의 도구)
-
사용자가 직접 정의해서 도구로 등록하는 방식
-
예시: 내가 만든 파이썬 함수를 LangChain에서 사용할 수 있게 등록
-
사용 방법:
@tool데코레이터를 이용해 함수를 도구로 변환from langchain.tools import tool @tool def get_weather(location: str) -> str: """입력한 지역의 날씨를 반환합니다""" ...- 이처럼 Python 함수에 주석(docstring)을 달아야, LLM이 기능을 이해하고 사용할 수 있음 (영문 주석 필수!)
-
Custom Tool은 일반 파이썬 함수를 자동화된 업무로 확장할 때 유용
-
다양한 백엔드 시스템과 연결 가능 (DB 조회, API 호출 등)
요약
| 구분 | 설명 | 특징 |
|---|---|---|
| Built-in Tools | LangChain이 제공하는 기본 도구들 | 사전 정의, Toolkit 형태도 존재 |
| Custom Tools | 사용자가 직접 정의한 도구 | @tool 데코레이터 사용, 함수 → 도구 변환 가능 |
1-(1). Tool Calling Agent란?
정의
Tool Calling Agent는 문제를 해결하기 위해 적절한 도구(tool)를 반복적으로 호출하고,
그 결과를 기반으로 다음 행동을 결정하여 최종적으로 답을 도출하는 에이전트입니다.
작동 원리 요약
-
LLM이 도구 호출 필요 여부 판단
-
필요한 도구를 호출하여 작업 수행 (예: 검색, 코드 실행 등)
-
결과(Observation)를 바탕으로 추가 도구 호출 또는 답 도출
-
문제 해결될 때까지 반복
핵심 개념 정리
| 항목 | 설명 |
|---|---|
| Thought | LLM이 "어떤 도구를 사용할지" 생각함 (내적 사고 단계) |
| Action | 선택된 도구를 실제로 호출함 (예: Web Search 실행) |
| Observation | 도구로부터 얻은 결과를 수집 |
| 정보 확인 (IF) | 도구 결과가 충분한지 판단 → 불충분하면 다시 Thought 단계로 |
| Answer | 충분한 정보가 모이면 최종 답변 도출 |
사용 예시 도구 (Tools)
-
RAG (Retrieval-Augmented Generation): DB나 문서에서 정보 검색
-
Web Search: 인터넷 실시간 정보 검색
-
코드 실행: 계산, 분석 등을 위한 코드 수행
실제 예시 시나리오
질문: "이번 주에 볼 만한 영화를 추천해줘"
-
Thought: "영화 정보를 알아보려면 어떤 도구가 필요하지?"
-
Action:
Web Search도구 호출 → 실시간 영화 순위 검색 -
Observation: "현재 인기 영화 목록 확인"
-
정보 확인: "이걸로 충분한 답변이 가능하겠군"
-
Answer: "추천 영화는 '듄: 파트2', '파묘', '파라마운트 플러스' 등입니다."
요약
-
Tool Calling Agent는 문제 해결을 위한 도구 호출 흐름을 LLM이 스스로 관리하는 방식
-
다단계 추론 + 도구 활용 능력을 가진 에이전트
-
단순 질의응답을 넘어 실제 업무 자동화, 복잡한 정보 검색 등에 매우 유용
1-(2). ReAct Framework란?
정의
ReAct는 Reason + Act의 줄임말로,
LLM이 스스로 생각하고(Reason), 행동하며(Act) 문제를 해결해 나가는 방식입니다.
즉, "생각 → 행동 → 결과 확인 → 다시 생각..." 의 반복 루프라고 보면 됩니다.
작동 흐름 요약
순서: Question → Reason(생각) → Action(행동) → Observation(관찰) → 필요시 반복
구성 요소 상세 설명
| 단계 | 설명 |
|---|---|
| 🧠 Thought | - 사용자의 질문을 이해하고 - 어떤 행동을 할지 고민하는 사고 과정 → Reasoning |
| ⚙️ Action | - 생각한 바에 따라 도구를 실행 → 검색, 코드 실행, 외부 API 호출 등 |
| 👀 Observation | - Action 결과를 받아들이고 분석 → 검색 결과나 API 응답 확인 |
| 정보 확인 | - 이 정보로 답변 가능한가? - 부족하면 다시 Thought 단계로 돌아감 |
| Answer | - 정보가 충분하면 사용자에게 최종 답변 제공 |
특징 요약
| 항목 | 설명 |
|---|---|
| 유연한 사고 + 행동 결합 | 단순 응답이 아니라 스스로 사고하고 반복적으로 행동 |
| 복잡한 요청 처리에 적합 | 사용자 요청이 단계를 요구하거나 외부 정보를 요구할 때 유용 |
| Tool Calling Agent의 핵심 전략 | LangChain에서 다양한 Agent들이 사용하는 핵심 구조 |
예시 시나리오
Q: "서울의 오늘 날씨를 알려줘"
-
Thought: "날씨를 확인해야겠군"
-
Action:
Web Search도구 호출 -
Observation: "서울 현재 기온은 19도, 맑음"
-
정보 확인: 충분 → 사용자에게 응답
-
Answer: "오늘 서울은 맑고 19도입니다"
요약
- ReAct는 LLM이 단순히 지식만 말하는 게 아니라, 직접 도구를 쓰고, 결과를 보고, 다시 판단하는 방식입니다.
- 복잡한 문제 해결, 반복적 작업, 동적 정보 처리에 특히 강력합니다.
1-(3). Tool Calling Process
LangChain에서 LLM이 도구를 사용하도록 만드는 일련의 과정입니다.
도구 정의 → 프롬프트 설정 → 에이전트 생성 → 실행의 4단계로 구성돼요.
전체 흐름 요약
1. 도구 생성 (@tool)
-
Python 함수에
@tool데코레이터를 붙여서 도구로 정의함. -
여러 개의 도구는 리스트에 묶어서 LLM에게 제공할 수 있음.
tools = [A, B, C, D] # 예: 웹 검색, 계산기, 뉴스 요약 등2. Agent Prompt 생성
-
ChatPromptTemplate.from_messages()를 통해 시스템 프롬프트 정의. -
prompt 내에서 LLM이 어떤 도구를 언제 사용할지를 설명함.
-
주요 변수:
input: 사용자 질문chat_history: 이전 대화 저장용agent_scratchpad: 중간 결과 저장용
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant. Use 'A' tool for news search."),
("placeholder", "chat_history"),
("human", "{input}"),
("placeholder", "agent_scratchpad")
])3. Agent 생성
- 위에서 만든 LLM, 도구, 프롬프트를 기반으로 agent 생성
agent = create_tool_calling_agent(llm, tools, prompt)4. Agent 실행
-
AgentExecutor로 실행 가능한 에이전트 생성 -
invoke()또는stream()방식으로 실행 가능
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
max_iterations=10,
max_execution_time=10,
)
agent_executor.invoke(
{"input": "AI 법령과 관련된 뉴스를 검색해 주세요."}
)정리
| 단계 | 설명 |
|---|---|
| 도구 생성 | 사용할 툴 정의 (@tool) |
| 프롬프트 생성 | 툴 사용 조건을 알려주는 템플릿 설정 |
| 에이전트 생성 | create_tool_calling_agent() 사용 |
| 실행 | AgentExecutor로 실행, 결과 받기 |
2. Inference vs Reasoning
Reasoning (추론 과정)
-
정의: 어떤 결론이나 판단에 도달하기 위해 논리적으로 사고하는 행위를 의미합니다.
-
영어 설명: "The action of thinking about something in a logical way in order to form a conclusion or judgment."
-
초점: 생각의 전개 과정에 중점을 둡니다.
- 사고 과정 → 결론 도출로 구분되는 논리적 사고의 과정.
Inference (추론)
-
정의: 증거나 추론을 바탕으로 도달한 결론을 뜻합니다.
-
영어 설명: "A conclusion reached on the basis of evidence and reasoning."
-
초점: 결론 또는 추론된 결과에 중점을 둡니다.
- 추론된 결과 자체를 가리키는 경우가 많음.
Inference와 관련된 개념 정리
1. Inference의 정의
-
머신러닝/딥러닝 관점: 학습이 끝난 모델을 이용하여 새로운 데이터에 대한 출력을 생성하는 단계.
- 즉, "모델의 생성 결과" 또는 "예측"과 유사한 의미.
-
LLM(Large Language Model) 관점:
- 딥러닝 모델을 실행하여 결과를 생성하는 기술적 과정.
- 모델 입장에서 inference는 결과값을 출력하는 단계.
2. Inference와 Reasoning의 차이
-
Inference: 확률적으로 가장 가능성이 높은 답을 예측하는 과정.
-
Reasoning: 논리적 사고를 통해 결론에 도달하는 과정.
3. Inference의 특징
-
LLM에서는 inference 단계와 논리적 reasoning 단계가 동일하지 않음.
- Inference는 단순히 예측값을 출력하는 기술적 과정에 해당.
Reasoning에 대한 설명
사전적 의미
-
논리적 사고를 통해 결론을 도출하는 과정.
-
주어진 정보나 사실을 바탕으로 원인 → 결과, 전체 → 논리 전개 → 결론으로 나아가는 사고 흐름을 포함.
- 예시: "비가 오면 길이 젖는다 → 지금 길이 젖었다 → 아, 비가 왔겠구나."
LLM에서의 활용
-
사고 능력이나 문제 해결 능력과 관련됨.
-
단순한 암기나 패턴 응답이 아닌, 논리 구조를 따라가며 정답에 도달하는 과정을 의미.
- 예시 1: "한국의 수도는 어디입니까?" → 단순 정보 응답 (non-reasoning).
- 예시 2: "A는 B보다 무겁고, B는 C보다 무겁다. 누가 가장 무겁나?" → 논리적 사고를 요하는 reasoning.
Reasoning은 단순한 정보 제공을 넘어, 복잡한 문제를 해결하기 위한 추론 과정과 논리적 사고를 포함합니다.
LLM Reasoning
LLM 모델의 성능 향상이 아닌, “기존 정보로부터 희망하는 결론에 도출하는 과정”으로 봐야 함
LLM Reasoning 보완 전략
1. Prompt-level 보완
-
Chain-of-Thought (CoT):
- 모델이 사고 과정을 단계 별로 설명하도록 유도하는 프롬프트 설계 방식.
- 목적: 단순히 정답만 제공하는 것이 아니라, 생각의 흐름을 명확히 표현하여 신뢰도를 높임.
-
Self-Consistency Decoding:
- 하나의 프롬프트에 대해 여러 경로를 통해 추론 결과를 생성하고, 가장 일관된 정답을 선택.
- 목적: 사고 흐름 중 가장 논리적인 결과를 선택하여 신뢰성을 확보.
2. Model-level 보완
-
Inference-time Scaling:
- 추론 단계에서 중간 결과를 생성하도록 하는 메커니즘.
- 목적: Reasoning 과정의 조절 및 개선.
-
Supervised Finetuning + RL (SFT + RL):
- 사람이 직접 만든 정답 데이터를 학습시키고, 강화 학습(RL)을 추가적으로 적용.
- 목적: 논리적 사고력을 강화하고 학습 효율성을 높임.
-
Post-hoc Reasoning Step Injection (Distillation):
- 추론이 끝난 후, 모델의 사고 과정을 다른 모델에 학습시키는 방식(Teacher → Student 모델).
- 목적: 잘 훈련된 모델의 추론 방식을 복제하여 성능 향상.
3. Tool-level 보완
-
Tool Augmentation:
- 계산기, 검색 엔진, 외부 데이터베이스 등 다양한 도구와 결합하여 사고력을 보완.
- 목적: 외부 도구를 활용해 복잡한 문제를 해결하고 사고력을 확장.
-
RAG-based (Retrieval-Augmented Generation):
- DB/문서에서 관련 정보를 찾아 연결하고, 이를 바탕으로 정보를 생성.
- 목적: 지식의 한계를 극복하며 정보 기반 추론 능력을 강화.
-
Scratchpad:
- 모델이 사고 과정을 메모 형태로 연산 및 텍스트로 기록하며 진행.
- 목적: 추론의 투명성과 디버깅 가능성을 추가.
요약
이 전략들은 LLM이 단순히 답변을 생성하는 것을 넘어, 실제로 논리적인 사고를 하고 있는 것처럼 보이도록 설계된 다양한 기술과 방법론을 포함합니다.
이를 통해 LLM은 더 신뢰할 수 있고 복잡한 문제 해결 능력을 갖추게 됩니다.
3. MCP, Model Context Protocol
MCP (Model Context Protocol) 개요
목적
-
AI 에이전트와 다양한 데이터베이스를 쉽고 효율적으로 연결할 수 있는 오픈소스 프로토콜 제공.
-
이를 통해 AI 시스템이 외부 정보에 직접 접근하여 성과와 활용도를 극대화할 수 있음.
기능 및 특징
-
표준화된 인터페이스
- 다양한 AI 시스템과 데이터 소스 간의 상호 운영성을 높이기 위해 통일된 규칙과 형식을 정의.
- 서로 다른 환경에서도 일관된 연결 가능.
-
통합된 용이성
- 각 데이터 소스에 맞춰 별도의 인터페이스나 코드를 작성할 필요 없이, 통합된 프로토콜을 통해 여러 데이터 소스와 연결 가능.
- 개발자와 사용자 모두에게 편리한 접근성 제공.
요약
MCP는 AI 시스템과 데이터 소스를 연결하는 데 필요한 복잡성을 줄이고, 다양한 환경에서 쉽게 활용할 수 있도록 설계된 표준화된 프로토콜입니다.
이를 통해 AI의 활용 범위를 확장하고 개발 효율성을 높이는 데 기여합니다.
Standardized protocol that connects AI agents to various external tools and data sources
MCP의 필요성에 대한 설명
에이전트나 모델이 각각의 “context”를 명시적으로 정의, 관리 및 교환 할 수 있게 해 주는 구조
1. LLM은 세션 중심 구조
-
LLM의 동작 방식:
- LLM(Large Language Model)은 하나의 입력(prompt)에 대해 하나의 출력(response)을 생성하는 방식으로 작동합니다.
- 모델은 세션 내에서만 요청과 응답을 처리하며, 이전 작업에 대한 기억을 자동으로 유지하거나 공유하지 못합니다.
-
문제점:
- 어떤 context(문맥)에서 작업을 했는지 기억하지 못하기 때문에, 이전 대화 내용을 모두 프롬프트에 포함시켜야 합니다.
- 예를 들어, 사용자가 이전 작업 내용을 모델에 남기고 싶다면, 직접 내용을 복사해서 프롬프트에 넣어야 하는 번거로움이 있습니다.
2. 내부 메모리 없는, 기억 없는 모델
-
GPT, Claude, Gemini와 같은 대부분의 LLM은 stateless 구조를 가지고 있습니다.
- 즉, 모델 자체는 이전 대화나 작업 내용을 기억하지 못합니다.
-
문제점:
- 기억을 하지 않는 구조적 한계 때문에 매번 새로운 context를 전달해야 하며, 이는 효율성과 사용자 경험에 영향을 미칩니다.
- 예를 들어, "이전 상태"를 기준으로 판단해야 하는 작업에서는 별도의 메모리 저장소나 검색 도구를 통해 정보를 참조해야 합니다.
3. Prompt 자체로는 Context 관리에 부족함
-
LLM은 문장 기반 프롬프트를 받아서 처리하는데, 이 방식은 구조적 context 관리에 한계가 있습니다.
-
문제점:
- 문맥을 유지하거나 공유하려면 사용자가 직접 데이터를 재구성하여 전달해야 합니다.
- 예를 들어, 이전 작업 내용을 보고서처럼 작성해 전달해야 하며, 이는 비효율적입니다.
4. 시스템 간 Context 교환을 위한 공통 포맷 부재
-
현재 AI 시스템 간에는 context 교환을 위한 표준화된 형식이 없습니다.
-
문제점:
- 서로 다른 모델 간에 context 전달이 사실상 불가능합니다.
- 예를 들어, GPT에서 생성한 내용을 Claude와 같은 다른 모델로 넘기려면 별도의 복잡한 변환 과정(예: JSON, YAML 등)이 필요합니다.
결론
MCP는 이러한 한계를 해결하기 위해 등장한 프로토콜로서, AI 모델과 시스템 간의 문맥(context)을 명확히 정의하고 효율적으로 관리 및 교환할 수 있는 환경을 제공합니다.
이를 통해 사용자는 더 편리하게 AI와 상호작용하고, 다양한 시스템 간 협업도 가능해집니다.
https://modulabs.co.kr/community/momos/8/feeds/653
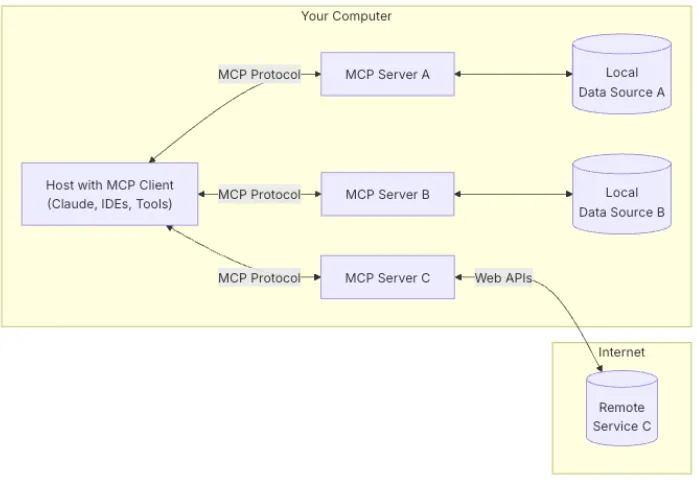
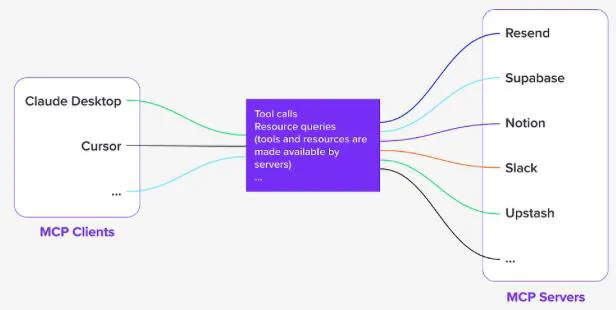
구성 요소 및 흐름
-
Host with MCP Client
-
Claude, IDE, 또는 기타 AI 도구가 MCP 클라이언트를 통해 서버와 통신합니다.
-
호스트는 MCP 프로토콜을 사용하여 필요한 데이터를 요청하거나 도구를 호출합니다.
-
-
MCP Server
-
각각의 서버(A, B, C)는 특정 데이터 소스 또는 서비스와 연결됩니다.
-
MCP Server A/B: 로컬 데이터 소스(A, B)와 연결되어 데이터를 제공합니다.
-
MCP Server C: 인터넷을 통해 원격 서비스(Web APIs)와 연결됩니다.
-
-
Local Data Source
-
사용자의 컴퓨터에 저장된 파일, 데이터베이스 등 로컬 자원입니다.
-
예: 데이터베이스 쿼리, 파일 검색 등.
-
-
Remote Service
-
인터넷 상의 외부 시스템(API)으로, MCP Server C를 통해 접근 가능합니다.
-
예: 클라우드 서비스, 외부 API 호출 등.
-
데이터 흐름
-
호스트가 MCP 클라이언트를 통해 데이터를 요청하거나 작업을 실행합니다.
-
MCP 클라이언트는 적절한 MCP 서버(A, B, C)로 요청을 전달합니다.
-
각 서버는 연결된 로컬 데이터 소스 또는 원격 서비스에서 데이터를 가져옵니다.
-
결과는 MCP 클라이언트를 통해 호스트로 반환되며, LLM은 이를 바탕으로 응답을 생성합니다.
핵심 요약
-
이 다이어그램은 MCP가 로컬 및 원격 데이터를 통합하여 LLM 기반 애플리케이션이 필요로 하는 정보를 효율적으로 제공하는 과정을 보여줍니다.
-
이를 통해 LLM은 다양한 데이터 소스와 도구를 활용하여 더 강력한 맞춤형 워크플로우를 지원할 수 있습니다.
MCP는 레고 블록 조립처럼 개발자가 원하는 기능을 LLM에 추가할 수 있는 프레임워크입니다.
단순한 채팅봇을 넘어, 도구 호출 → 데이터 분석 → 자동화 작업까지 수행하는 고급 AI 에이전트를 쉽게 구축할 수 있게 해줍니다.
기존 LLM 구조 vs MCP 기반 구조 비교
| 항목 | 기존 LLM 구조 | MCP 기반 구조 |
|---|---|---|
| 프로세스 | - 자연어 프롬프트 입력 - 단순한 입력-출력 구조 | - 명시적 Context 객체로 상태 저장 및 전이 가능 - 구조화된 JSON/YAML 기반 Context Object |
| 기억 (메모리) | - Stateless (메모리 없음) | - Context를 다른 에이전트나 모델에 그대로 전달 가능 |
| 입력 방식 | - 자연어 프롬프트 기반 - 비구조적, 단방향 | - MCP context에 agent_id, task, memory 등을 명시하여 처리 가능 |
| 작업 전이 | - 수동으로 복사해 전달, 사용자 정의 로직으로 처리 | - 각 단계의 Context 기록 - 작업 흐름 및 디버깅 가능 |
| 다중 에이전트 입력 | - Memory 공유가 어렵고, 그에 따른 상태 추적 안됨 | - 공통 포맷으로 모델 간 상호운용성(interoperability) 확보 |
| 문맥 흐름 추적 | - 거의 불가능- 어떤 세션에서 무슨 일을 했는지 알 수 없음 | - 문맥 흐름 추적 가능- 각 단계별 기록 유지 |
| 상호 운용성 | - 모델/시스템 간 Context 전환 어려움 | - MCP를 통해 다양한 시스템 간 Context 교환 가능 |
| 보안/제한 설정 | - 프롬프트 내 명시 불가능 | - Context에 역할/도구 제한, 사용자 권한 명시도 가능 |
요약
MCP 기반 구조는 기존 LLM의 한계를 보완하여 문맥(Context)을 명확히 정의하고 저장하며, 다중 에이전트와의 상호작용 및 작업 전이를 효율적으로 관리할 수 있도록 설계된 새로운 표준입니다.
MCP + LangGraph
MCP는 에이전트 간 상태 전달을 구조화 하여 협력과 추적으로 가능하게 함
MCP 적용 시, 작업의 주체와 목적이 명시되어 에이전트 흐름의 추적성과 확장성이 강화됨
AI 에이전트 유형 정리
AI 에이전트는 환경과 상호작용하며 목표를 달성하는 시스템으로, 역할과 작동 방식에 따라 아래와 같이 분류됩니다.
1. 반응형 에이전트 (Reactive Agent)
-
특징:
- 과거 경험이나 내부 상태 없이 현재 환경 상태에만 반응.
- 단순한 조건-행동 규칙에 기반.
-
장점: 빠르고 단순.
-
단점: 복잡한 상황이나 추론에는 한계.
-
예시: "지금 입력에 이렇게 답변, 바로 이 행동!"
2. 계획형 에이전트 (Deliberative Agent)
-
특징:
- 환경을 이해하고 계획을 세워 행동함.
- 내부 모델을 통해 상황을 예측하거나 시뮬레이션.
-
장점: 경로를 탐색하고, 시뮬레이션 기반 의사결정을 수행.
-
예시: "지금 이렇게 행동하면 어떤 결과가 나올까? 먼저 생각해보자."
3. 학습형 에이전트 (Learning Agent)
-
특징:
- 경험을 통해 스스로 행동 전략을 개선.
- 강화학습, 지도학습, 피드백 기반 학습 등을 활용.
-
장점: 강화학습을 기반으로 게임 에이전트나 추천 시스템 등에 활용.
-
예시: "이 행동은 좋은 결과였어. 다음엔 더 잘해보자!"
4. 자율 에이전트 (Autonomous Agent)
-
특징:
- 외부 개입 없이 스스로 판단, 계획, 실행.
- Reasoning(추론), Tool Calling(도구 호출), Memory 유지 등을 통합적으로 활용.
-
대표 사례:
- Tool-using LLM Agent (예: AutoGPT, Agent Workflow).
-
예시: "내가 스스로 도구도 고르고 계획도 짜볼게!"
요약
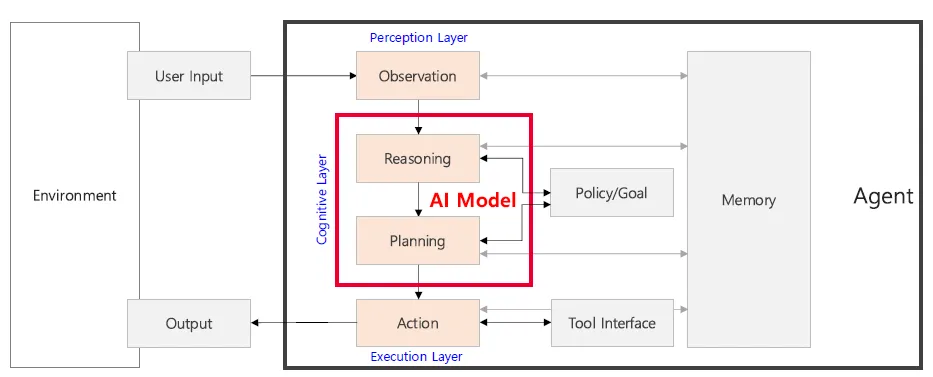
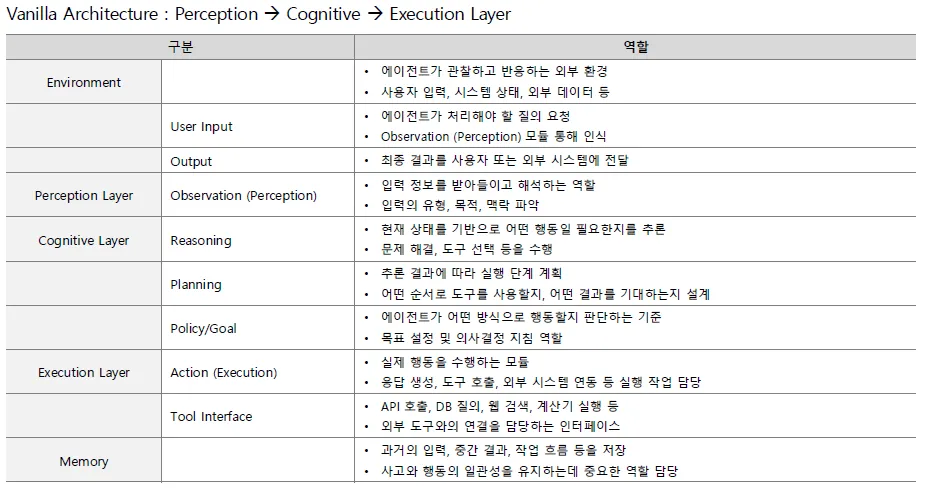
Reasoning-Planning-Action 수행
-
Cognitive Layer는 AI Agent의 핵심 사고 과정이 이루어지는 영역으로, LLM이나 다른 AI모델이 주로 위치함
-
AI 에이전트는 단순히 반응하는 시스템에서부터 스스로 학습하고 계획하며 자율적으로 실행하는 시스템까지 다양한 형태로 발전하고 있습니다.
AI Agent Architecture