LLM
1.MCP에 대한 깊고 대단한 고찰
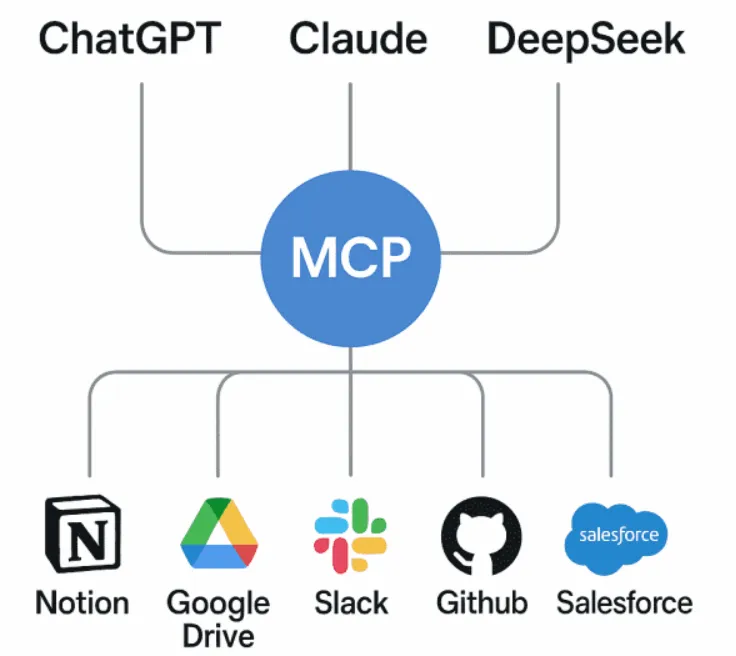
MCP에 대한 깊고 대단한 고찰_2조 image.png MCP 정의 MCP(Model Context Protocol)는 AI 모델과 외부 애플리케이션, 시스템 또는 로컬 파일과의 상호작용을 표준화하는 프로토콜. 기존의 API 호출 방식과 달리, MCP는 AI가
2.생성형 AI 서비스 개발 (1)

자연어 처리 작업에서 사용되는 언어 모델을 연결하고 체인화, 오픈 소스 프레임워크→ 여러 모델을 순차적으로 연결하여 실행각각의 LangChain 모듈을 파이프(|)를 통해 체인으로 연결암호화하고자 하는 내용을 알파벳 별로 일정한 거리만큼 밀어서, 다른 알파벳으로 치환하
3.생성형 AI 서비스 개발 (2)
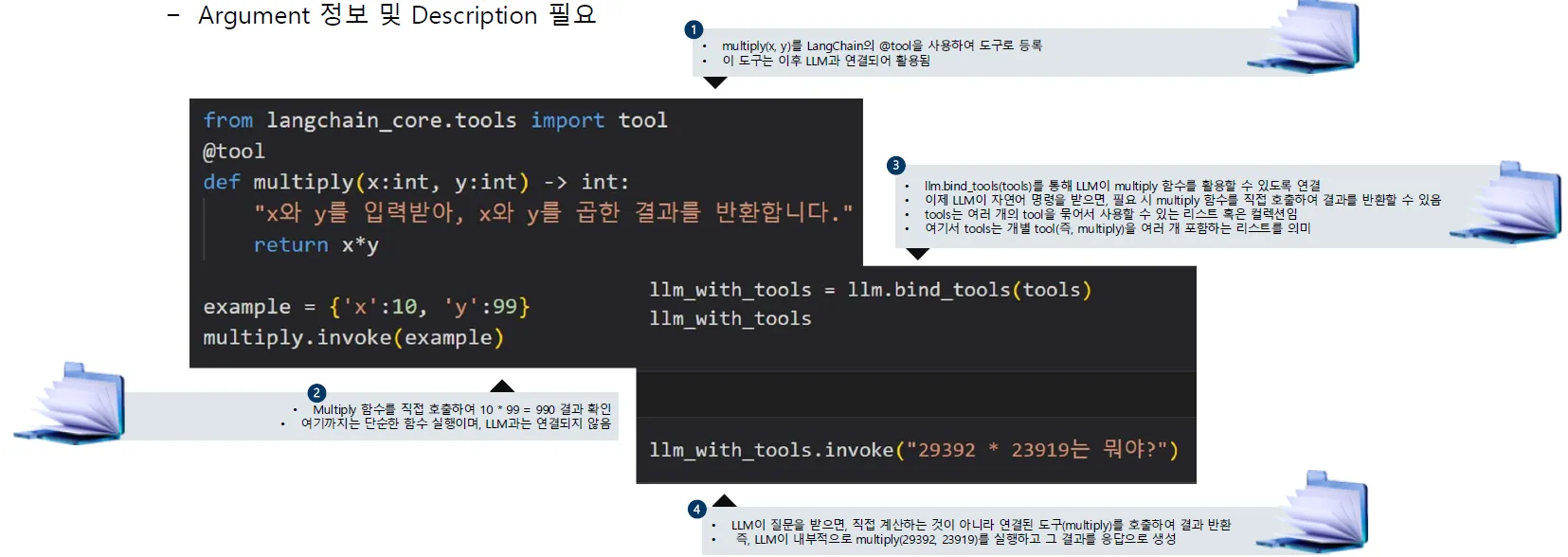
Agent는 사용자의 요청에 대해, 툴(Tool)로 표현되는 외부 모듈을 활용하여 문제를 해결하는 기능. Tool은 LLM이 답변을 출력하기 위해 활용할 수 있는 다양한 수단을 의미. LLM은 Tool을 사용하기 위해 Tool 이름과 Argument를
4.생성형 AI 서비스 개발 (3)

Fine-tuning PEFT(Parameter Efficient Fine Tuning): 기존 사전학습된 대형 모델의 대부분 파라미터를 고정(freeze)하고, 일부 작은 부위만 학습 가능하게 만들어 파인튜닝하는 방식 목적 GPU 메모리 절약 빠른 학습 속도
5.LLM 기초: Word Embedding의 역사

시계열은 준비되어 있어야 함Rag를 이용해서, 증명된 투자자의 자료, 기록을 학습시켜 답변을 뱉어내도록One-Hot Vector는 주로 자연어 처리(NLP)나 머신러닝에서 카테고리형 데이터를 숫자로 변환하는 방법 중 하나입니다. 이 방법은 각 카테고리를 이진 벡터로
6.LLM 기초: Transformer 씹고 뜯고 맛보기
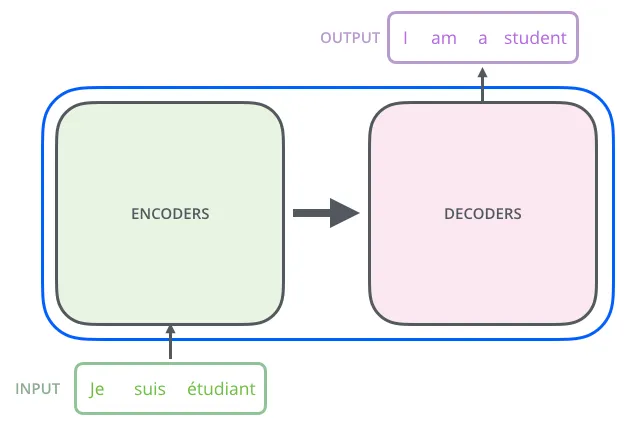
https://nlpinkorean.github.io/illustrated-transformer/multi-head self-attention을 이용해 sequential computation을 줄여 더 많은 부분을 병렬처리가 가능하게 만들면서 동시에 더 많은
7.프롬프트 엔지니어링 (1)

Prompt Engineering LLM의 입력에 해당하는 프롬프트를 효과적으로 만들고 최적화하는 과정 Prompt 중요성 Prompt의 역할: Prompt는 지시문과 사용자 입력으로 구성되며, 모델이 작업을 수행하는 데 중요한 역할을 합니다. 정보 포함: 사용
8.AI Agent 설계 및 구축
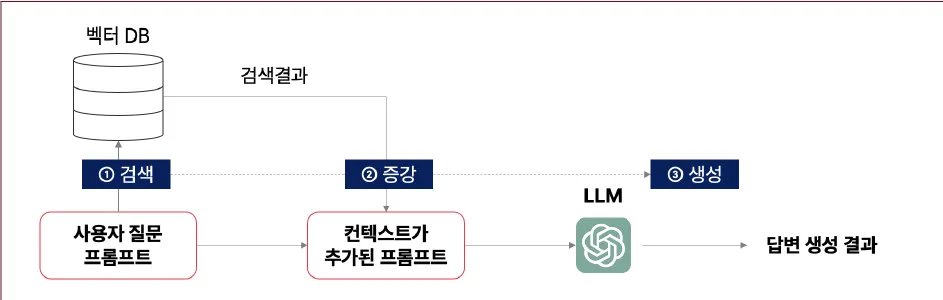
LLM(Large Language Model)은 딥러닝 기반 모델로서 긴 문장 처리와 학습 데이터의 정보량에 한계를 가진다.딥러닝 모델의 학습 한계: 학습된 데이터 이외의 정보에 취약함오픈AI의 최신 모델인 GPT-4o는 2023년 9월까지, Claude Sonnet
9.Agentic RAG
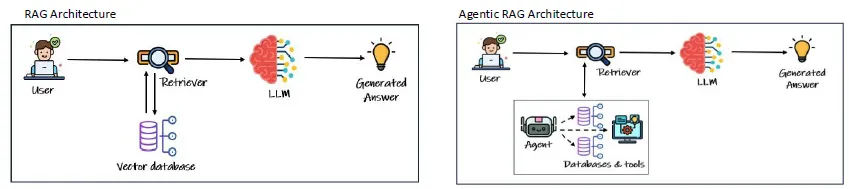
Goal →Planning →Execution →Reflection →(Iteration) →Collaboration복잡한 목표를 단계적으로 나누어 AI가 실행할 수 있도록 계획을 수립하는 과정입니다.예시:목표 작성 → 정보 수집 → 초안 작성 → 검토 → 최종화핵심
10.AI Agent 프레임워크

AI Agent: 인간처럼 자율적으로 환경을 인식하고, 계획을 세우고, 행동을 수행하며, 결과를 바탕으로 학습하는 시스템을 의미함AI 에이전트 프레임워크: AI 에이전트(Agent)를 만들고 실행하는 데 필요한 구조, 도구, 모듈을 제공하는 소프트웨어 프레임워크최근에는
11.벡터 DB (1) - 개발 환경 설정
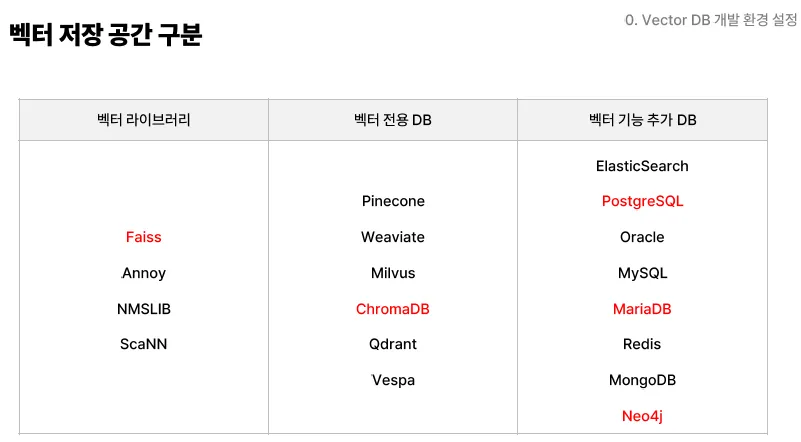
Python 버전 확인 명령어Python 다운로드 링크https://www.python.org/downloads/release/python-31010/설치 시 주의 사항설치 시 "Add Python to PATH" 옵션 체크 필수설치 완료 후 확인 방법VSCo
12.벡터 DB (2) - 개요
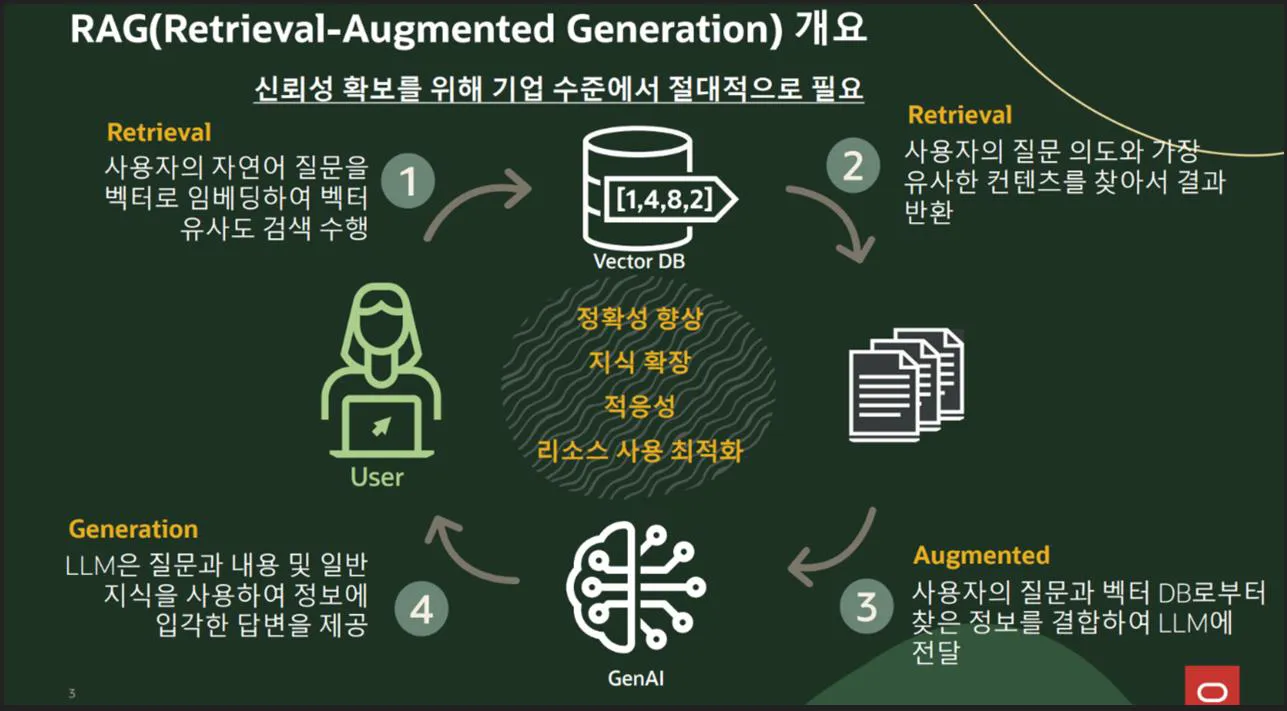
생성형 AI가 발전하면서 환각 없는 생성형 콘텐츠의 중요성이 확대됐고, 환각을 최소화하는 방안으로 RAG가 각광받고 있습니다.또한, RAG를 위해서는 벡터 DB가 반드시 필요합니다.전통적인 데이터베이스는 ‘정확한 값을 찾는 데 강함’벡터 데이터베이스는 ‘비슷한 것을 찾
13.벡터 DB (3) - 벡터 Embedding 기초
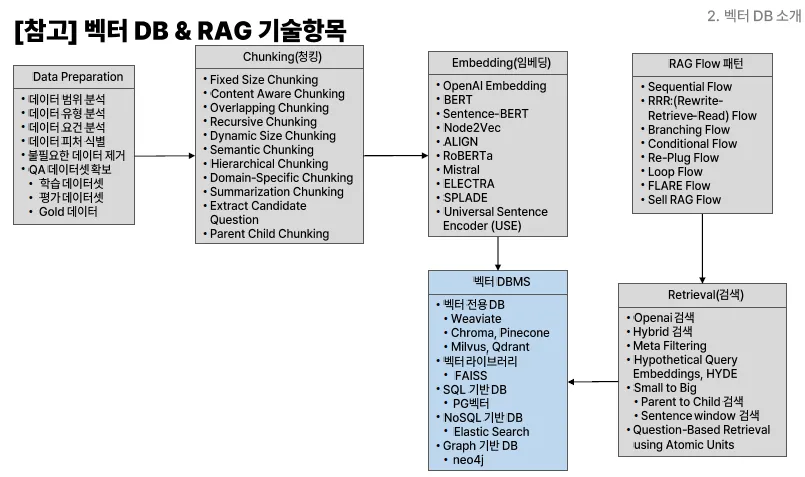
"고차원 벡터 데이터를 효율적으로 저장, 관리, 검색하기 위해 설계된 데이터베이스"텍스트, 이미지, 오디오 등의 데이터를 임베딩(벡터화)하여 저장하고, 관리하며, 검색 기능을 제공하는 임베딩 벡터 전용 DB고차원(벡터 차원 수)의 공간(인덱스)에 임베디드 벡터를 인덱싱
14.Huggingface를 활용한 텍스트 벡터화
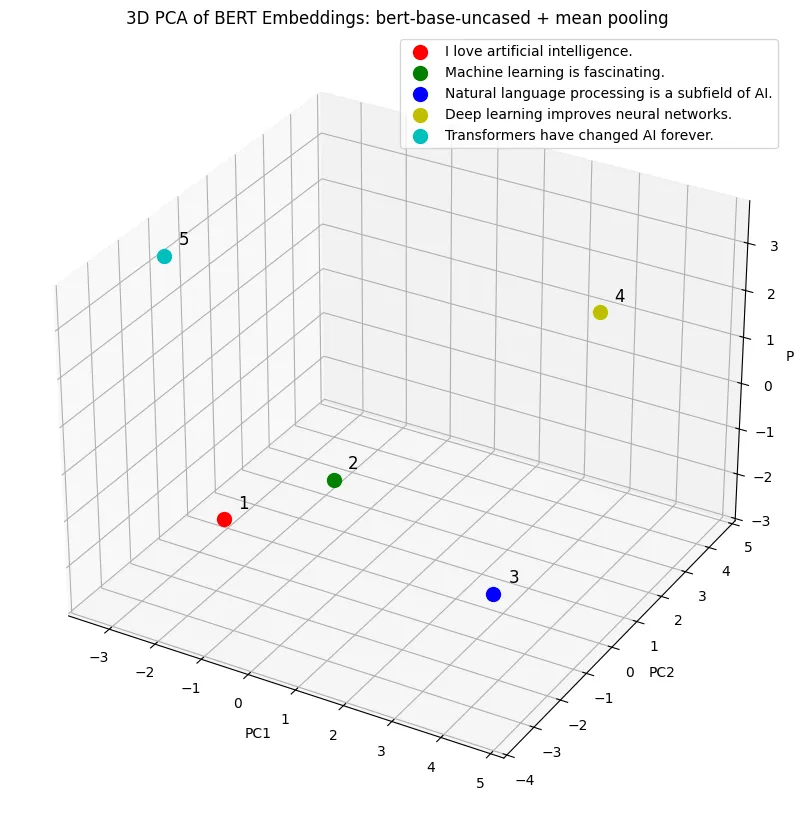
해당 텍스트들을 어떠한 용도로 사용할지 모르기 때문에, 범용성을 가지는 일반 Bert를 활용문장 리스트로 구성된 입력 데이터padding=True: 문장 길이를 맞춤truncation=True: 최대 길이 초과 시 자름return_tensors="pt": PyTorch
15.질문 기반 유사 문서 검색 서비스
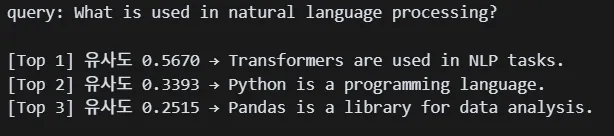
벡터DB화와 유사도를 측정하기 위한 실습이므로, 'all-MiniLM-L6-v2' 모델을 사용함.ChromaDB의 클라이언트 객체를 생성하여, ChromaDB와 상호작용함.ChromaDB가 내부적으로 문서나 쿼리를 벡터로 바꿀 때 사용할 임베딩 생성기를 지정 Chrom
16.벡터 DB (4) - 벡터 Indexing

데이터베이스에 벡터 데이터를 구조화된 인덱스에 담는 행위추후 검색 성능을 고려하여 KNN이 아닌 ANN(Approximate Nearest Neighbor) 가능한 구조로 설계목표: 검색 정확도 ↔ 검색 속도 간의 tradeoff 관계 최적화Quantinized(양자화
17.벡터 DB (5) - 유사도 측정
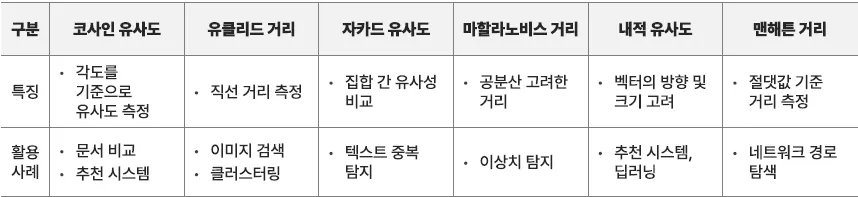
두 데이터 간의 유사성을 평가하는 방법머신러닝, 정보 검색, 자연어 처리 등 다양한 분야에서 활용데이터 간의 관계를 수치화할 때 유용두 벡터 사이의 각도를 기준으로 유사도를 측정하는 방식.→ 두 벡터가 이루는 각도가 작을수록(즉, 방향이 비슷할수록) 유사도가 높음.수식
18.벡터 DB (6) - 근사 최근접 이웃 (ANN) 검색

ANN이란 질문 벡터(Query 벡터)에 대해 가장 비슷한 데티어(Nearest Neighbor)를 찾는 작업정확도는 조금 낮아져도, 속도를 크게 높이는 것이 목표!!VDB 검색 알고리즘■ VDB고차원 벡터 데이터를 저장벡터 간의 유사성 검색을 효율적으로 수행하는 시스
19.Word2Vec & 벡터 DB - 나무위키 학습
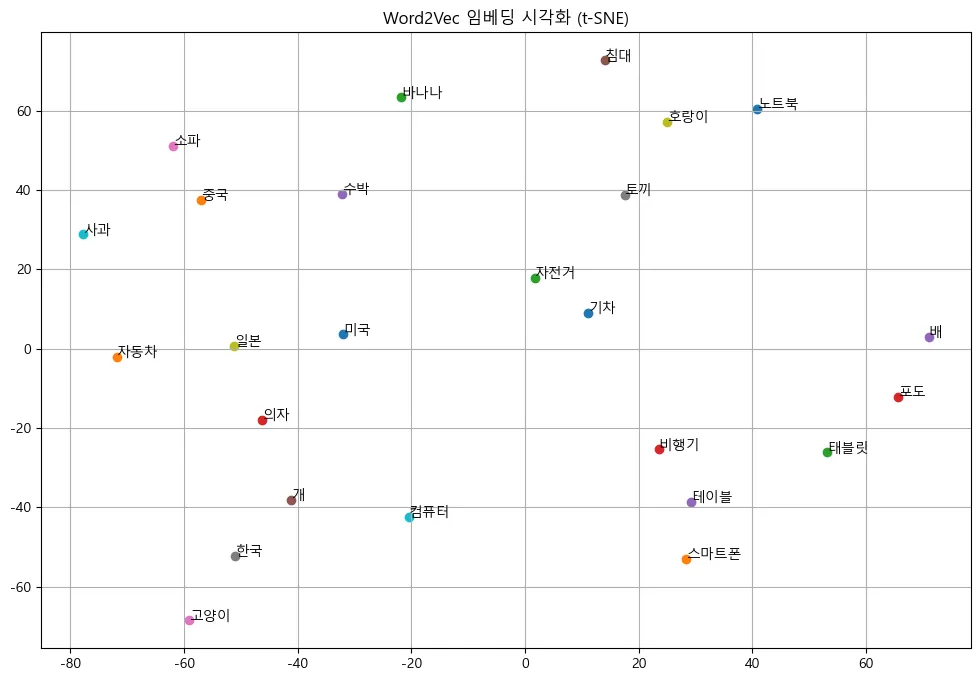
주어진 단어들을 바탕으로 Word2Vec 모델을 학습시켰다.임베딩된 단어들을 시각화하였을 때 다음 이미지처럼 나왔는데, 학습 데이터가 굉장히 적어 적절한 임베딩이 되지 않았다고 생각하였다.FAISS 대신 ANNOY를 사용하여 진행해보았고, '사과'와 유사한 단어:사과일
20.벡터 DB (7) - 벡터 DB 스키마 설계
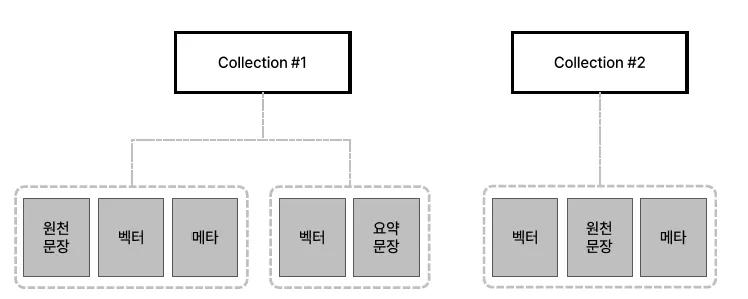
벡터 DB 스키마 설계는 벡터 임베딩을 효율적으로 저장하고 검색하는 구조를 계획하는 과정 데이터 특성과 Application의 요구사항을 고려하여 수행1\. 데이터 구조 계획데이터 유형 결정벡터 임베딩의 출처(이미지, 텍스트, 지리 좌표 등)에 따라 저장할 데이터 유형
21.벡터 DB (8) - 원천 테이터 청킹 전략
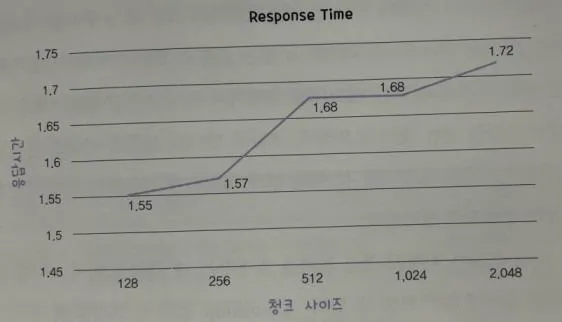
Vector화 할 대상이 되는 데이터청크로 구분된 데이터는 임베딩 처리를 통해 고정된 크기의 Vector 값으로 변환청크 크기와 응답시간 간의 관계는 정보 검색 및 자연어 처리 시스템의 전체적인 성능에 매우 중요한 영향을 미침청크 크기를 적절하게 설정하는 것이 시스템의
22.벡터 DB (9) - 벡터 DB 검색

벡터 DB는 텍스트, 이미지, 음성 등을 벡터(숫자 배열)로 변환한 뒤, 비슷한 벡터끼리 검색하므로 검색 요청 시 4단계를 거쳐 결과를 출력검색어나 질문을 벡터로 변환하는 단계사용자가 입력한 텍스트(예: "붉은 드레스")를 벡터로 변환NLP 또는 멀티모달 AI 모델(B
23.벡터 DB (10) - 벡터 DB 쿼리 처리
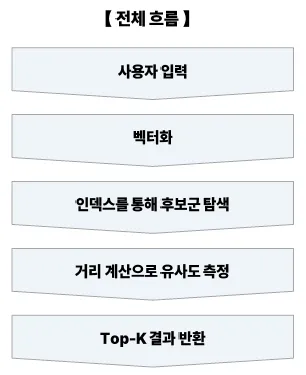
단순 키워드 검색이 아닌 텍스트, 이미지, 오디오 등의 의미 기반 유사성 검색병렬처리 개요이런 연산을 하나하나 직렬로 처리하면 느려서 병렬처리 필요병렬 처리 방식예시사용자가 query_vector 하나로 1,000만 개 벡터와 유사도 비교 요청 시직렬 처리: 1 CPU
24.벡터 DB (11) - AI와 머신러닝에서의 활용

벡터가 왜 필요할까?1\. 기존 추천 시스템의 한계명시적 행동 기반 추천 (예: A를 샀으니 B 추천)유저의 구매 이력 + 제품 속성 조합으로 추천 → 의미 기반 유사성 파악에 어려움 존재 벡터 기반 추천 시스템작동 방식사용자 행동 데이터 수집 (클릭, 시청, 좋아
25.MariaDB를 활용한 VectorDB 하이브리드 검색
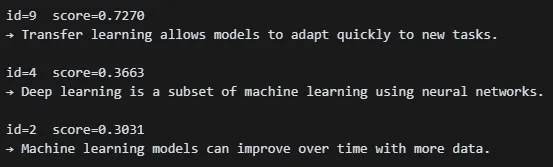
.env 에 정의해 둔 DB 접속 정보를 읽어서 파이썬 변수(HOST, PORT, USER, PASSWORD, DB_NAME)로 할당테이블을 만들고 데이터(문장)을 삽입결과 : ✅ test_db.documents 테이블에 10개 레코드 삽입 완료✅ documents 테