
🏴T-test(T검정)
두 집단 간의 평균을 비교하는 모수적 통계방법 (표본이 정규성, 등분산성, 독립성 등을 만족할때 적용가능)
조건)
- 독립성 : 두 그룹이 연결되어 있는 (paired) 쌍인지
- 등분산성 : 두 그룹이 어느정도 유사한 수준의 분산 값을 가지는지
- 정규성: 데이터가 정규성을 나타는지 -> 정규분포를 따르는가?
모수적 방법: 모집단의 특성을 가정하여
🌏T-test Process
-
귀무 가설 (Null Hypothesis) 를 설정 ( 모집단 평균 = 표본의 평균 )
-
대안 가설 (Alternative Hypothesis) 를 설정 ( 모집단 평균 != 표본의 평균 )
-
신뢰도를 설정 (Confidence Level) : 모수가 신뢰구간 안에 포함될 확률 (보통 95, 99% 등을 사용)
◾ 신뢰도 95%의 의미
= 모수가 신뢰 구간 안에 포함될 확률이 95%
= 귀무가설이 틀렸지만 우연히 성립할 확률이 5% -
P-value를 확인 : 주어진 가설에 대해서 "얼마나 근거가 있는지"에 대한 값을 0과 1사이의 값으로 scale한 지표, 단측검정or 양측검정일때에 따라 다름
- 단측검정(ond-tailed test) : 샘플 데이터의 평균이 X와 같다 / 같지 않다. 를 검정하는 내용
- 양측검정(two-tailed test) : 샘플 데이터의 평균이 X보다 크다 혹은 작다 를 검정하는 내용
- 이후 p-value를 바탕으로 가설에 대해 결론을 내림
☝ One Sample T-Test
: 1개의 sample 값들의 평균이 특정값과 동일한지 비교하기 위해 사용.
파이썬 scipy의 stats.ttest_1samp() 함수를 사용하여 stastics값과 pvalue값을 구할 수 있다.
📌사용 예시)
from scipy import stats
# ttest_1samp 함수의 파라미터 1) Sample 데이터, 2) 비교하려는 특정값
stats.ttest_1samp(coinflips, .5)✌ Two Sample T-Test
: 2개의 sample 값들의 평균이 서로 동일한지 비교하기 위해 사용.
scipy에서 stats.ttest_ind() 함수를 사용하여 stastics값과 pvalue값을 구할 수 있다.
📌사용 예시)
# ttest_ind 함수의 파라미터 1) Sample 값1 , 2) Sample 값2, 3) 대립가설 설정
stats.ttest_ind(coin1, coin2, alternative ='')🚨TypeError
- 1종 오류 : 귀무가설이 참인데 잘못 판단해 기각 해버리는 오류
- 1종오류를 범할 확률은 pvalue와 같은 의미이다.
- 2종 오류 : 귀무가설을 거짓인데도 기각하지 않아서 생기는 오류
- 예시) 화재경보가 울리는 경우에 대한 TypeError
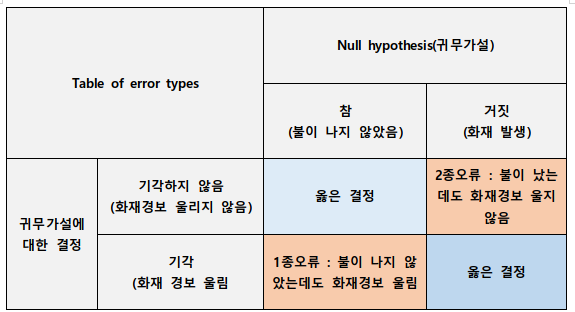
- 예시) 화재경보가 울리는 경우에 대한 TypeError
