파이썬을 설치한다는 것?
컴퓨터에게 파이썬을 알아들을 수 있도록 번역패키지를 설치하는 것과 같다.
변수
a = 2
b = 3
print(a+b)자료형
- 리스트
a = ['사과', '배', '감']
print(a[0])출력: 사과
- dictionary
a = {'name' : '영수', 'age' : 24}
print(a['name'])출력: 영수
함수
def: 함수 선언하겠다는 뜻
함수 뒤에 세미콜론을 입력하고 그 다음줄에 함수 내용 작성
def hey():
print('헤이!')
hey()출력: 헤이!
def sum(a, b, c):
return a+b+c
result = sum(1, 2, 3)
print(result)출력: 6
반복문
ages = [5, 10, 13, 23, 25, 9]
for a in ages:
print(a)출력:
5
10
13
23
25
9
ages = [5, 10, 13, 23, 25, 9]
for a in ages:
if a > 20:
print('성인입니다')
else:
print('청소년입니다')출력:
청소년입니다
청소년입니다
청소년입니다
성인입니다
성인입니다
청소년입니다
조건문
age = 25
if age > 20:
print('성인입니다')
else :
print('청소년입니다')파이썬 패키지
가상환경: 프로젝트별로 라이브러리를 담아두는 폴더를 따로 관리하는 것
터미널에서
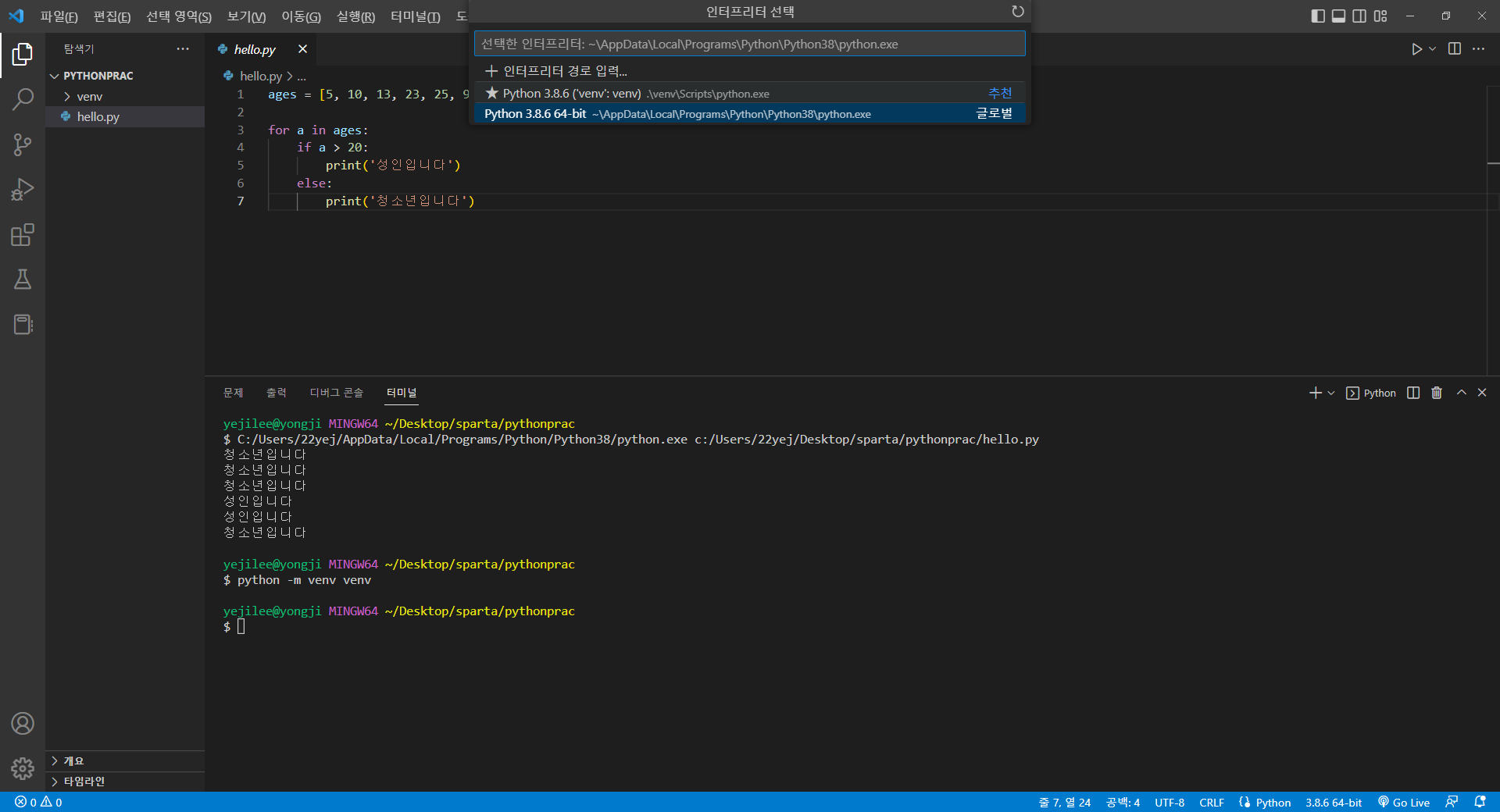
$ python -m venv venv위 코드를 작성하면 작업창에 venv라는 폴더가 생성된다.
그리고 파란색 줄의 3.8.6을 클릭한 후 아래와 같이 인터프리터를 venv로 선택해준다.
그리고 터미널을 재실행하면 아래와 같이 (venv)가 붙어있는 걸 확인할 수 있다.
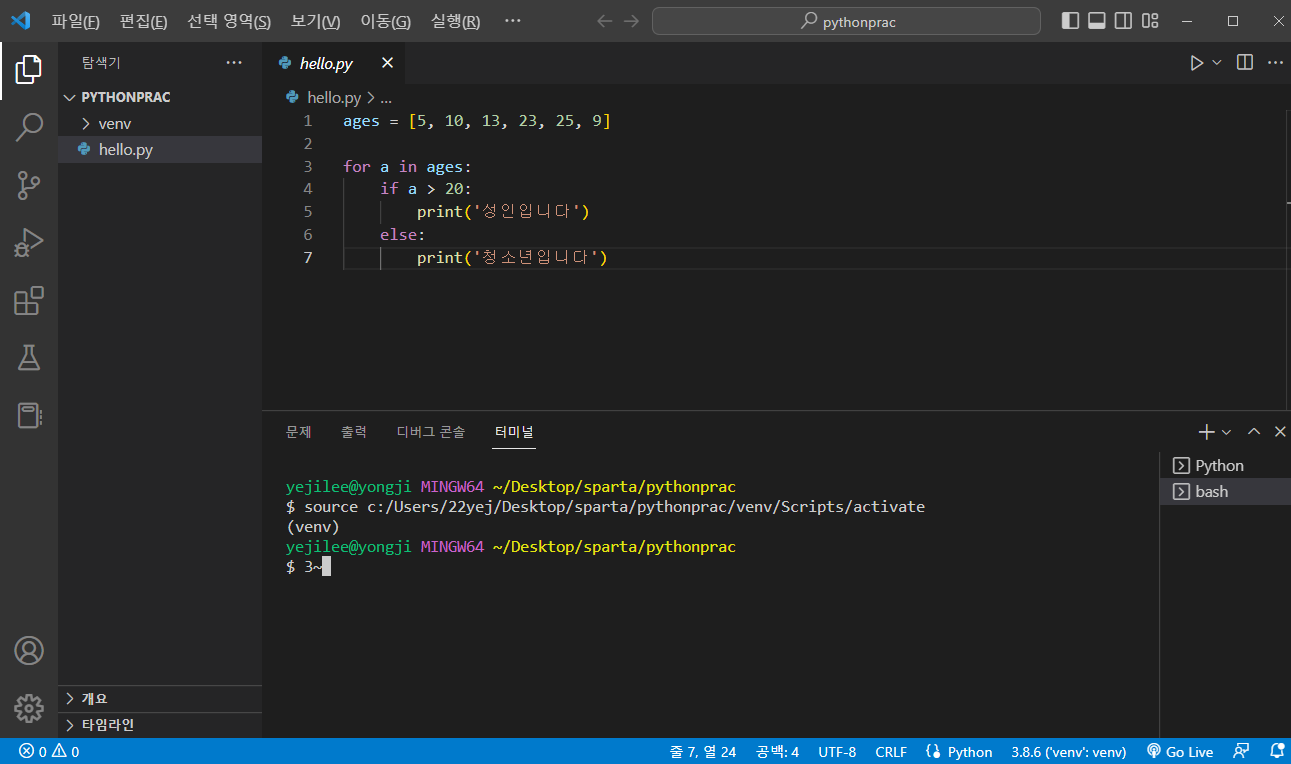
이 폴더(venv)에서 라이브러리를 갖다쓰겠다는 뜻!
$ pip install requestsrequests 라이브러리
javascript의 fetch와 같은 기능
import requests
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
print(rjson)출력화면
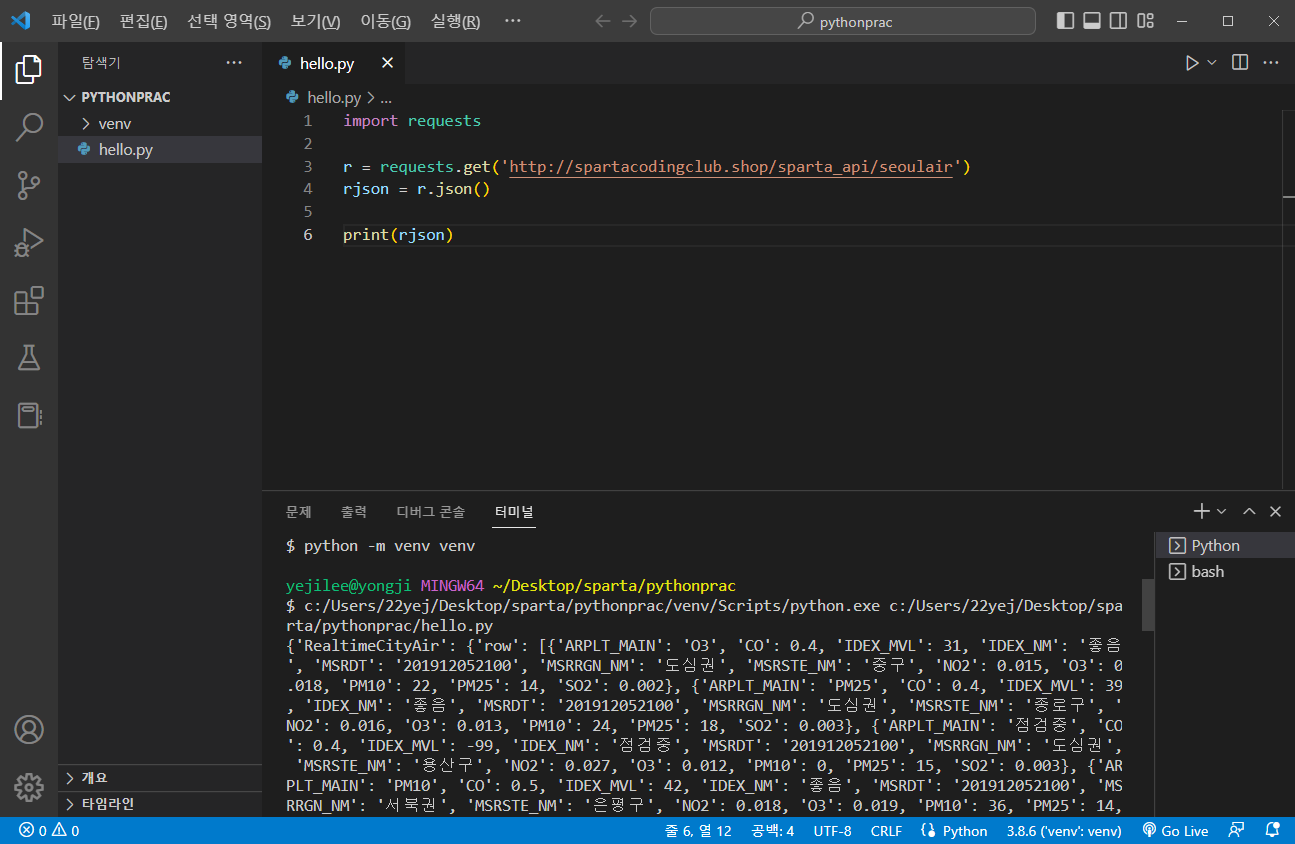
import requests
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
rows = rjson['RealtimeCityAir']['row']
for a in rows:
print(a)구+수치만 출력
import requests
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
rows = rjson['RealtimeCityAir']['row']
for a in rows:
gu_name = a['MSRSTE_NM']
gu_mise = a['IDEX_MVL']
print(gu_name, gu_mise)출력화면
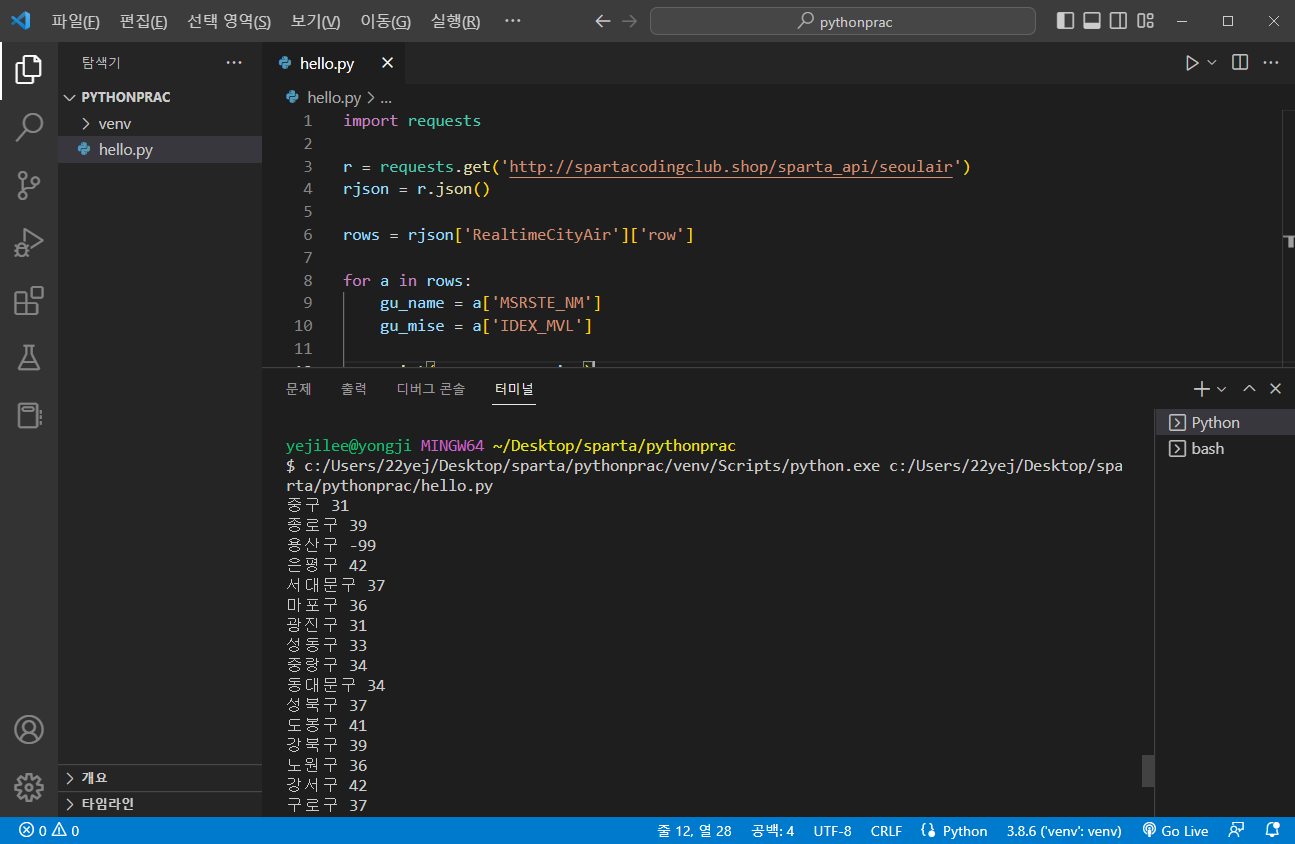
웹스크래핑(크롤링)
크롤링: 웹에 접속해서 데이터를 솎아내어 가지고 오는 것
- requests: 웹에 접속하는 라이브러리
- bs4: 데이터를 솎아내는 라이브러리
bs4 라이브러리 설치
$ pip install bs4네이버 영화 사이트에서 영화제목 우클릭 -> 검사 -> copy -> copy selector
a = select_one('') 작은 따옴표 사이에 붙여넣기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
a = soup.select_one('#old_content > table > tbody > tr:nth-child(3) > td.title > div > a')
print(a)출력화면
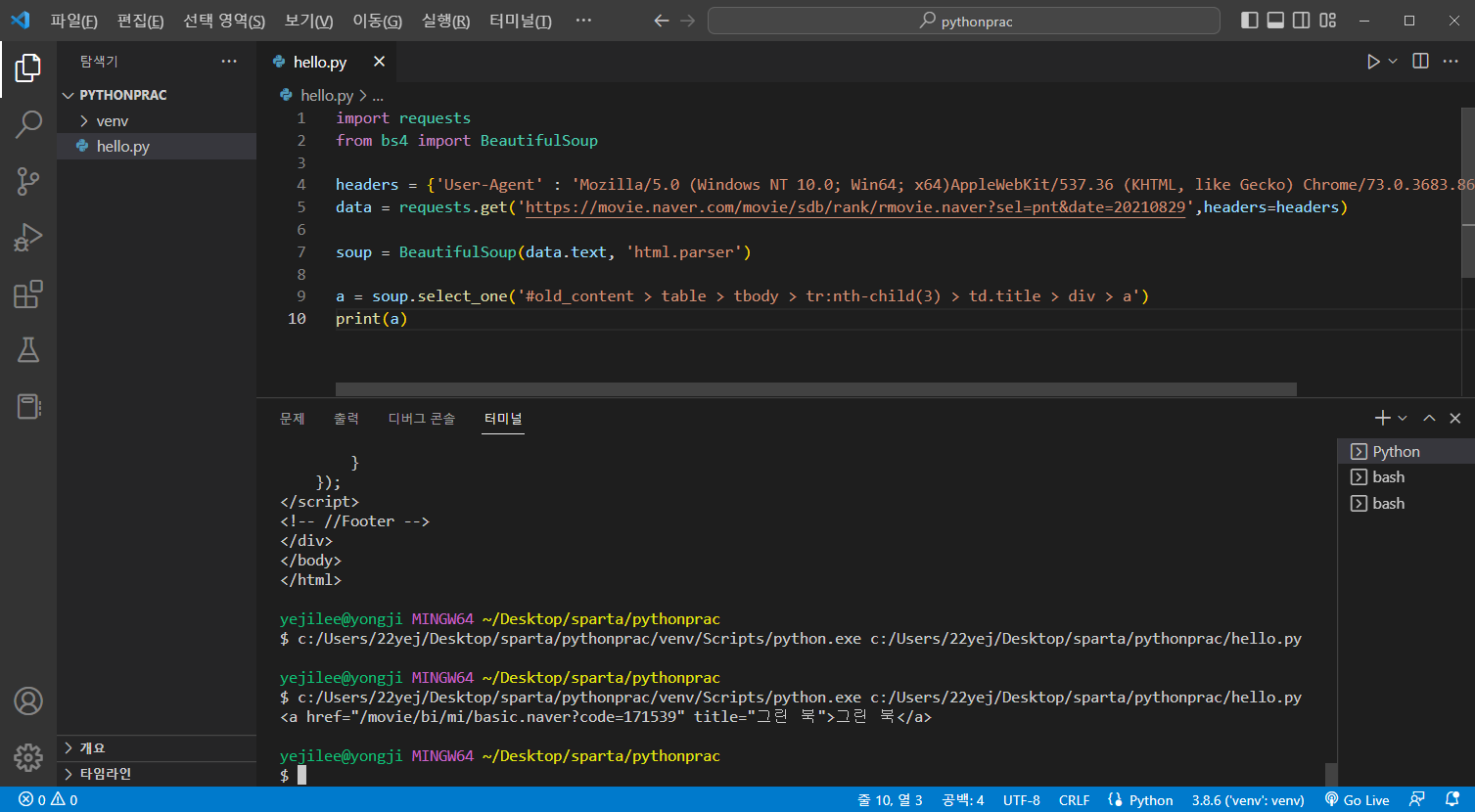
그린북 이라는 제목만 출력해보자
위 코드에서 a.text만 바꾸면 된다.
print(a.text)출력화면

속성값을 출력해보자.
print(a['href'])출력화면
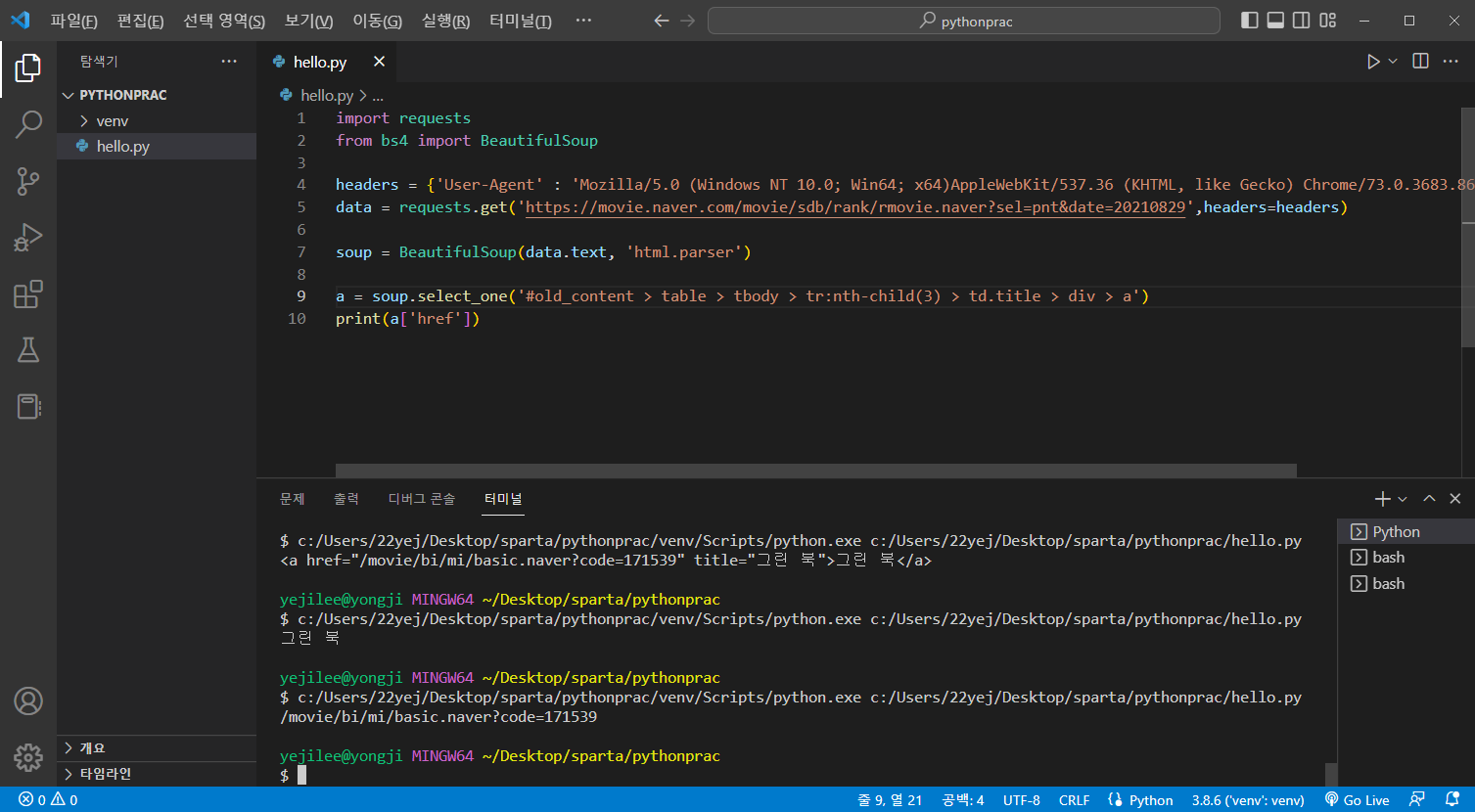
tr을 하나씩 출력해보자.(리스트로 이루어져있음)
각 tr을 복사, 붙여넣기 해서 보면 #old ~ tr까지 같다는 걸 알 수 있다.
#old_content > table > tbody > tr:nth-child(2)
#old_content > table > tbody > tr:nth-child(3)trs에 tr을 모두 가져오기 위해 아래와 같이 select뒤에 같은 부분을 넣어준다.
trs = soup.select('#old_content > table > tbody > tr')tr내 제목을 출력해보자
for tr in trs:
a = tr.select_one('td.title > div > a')
print(a)
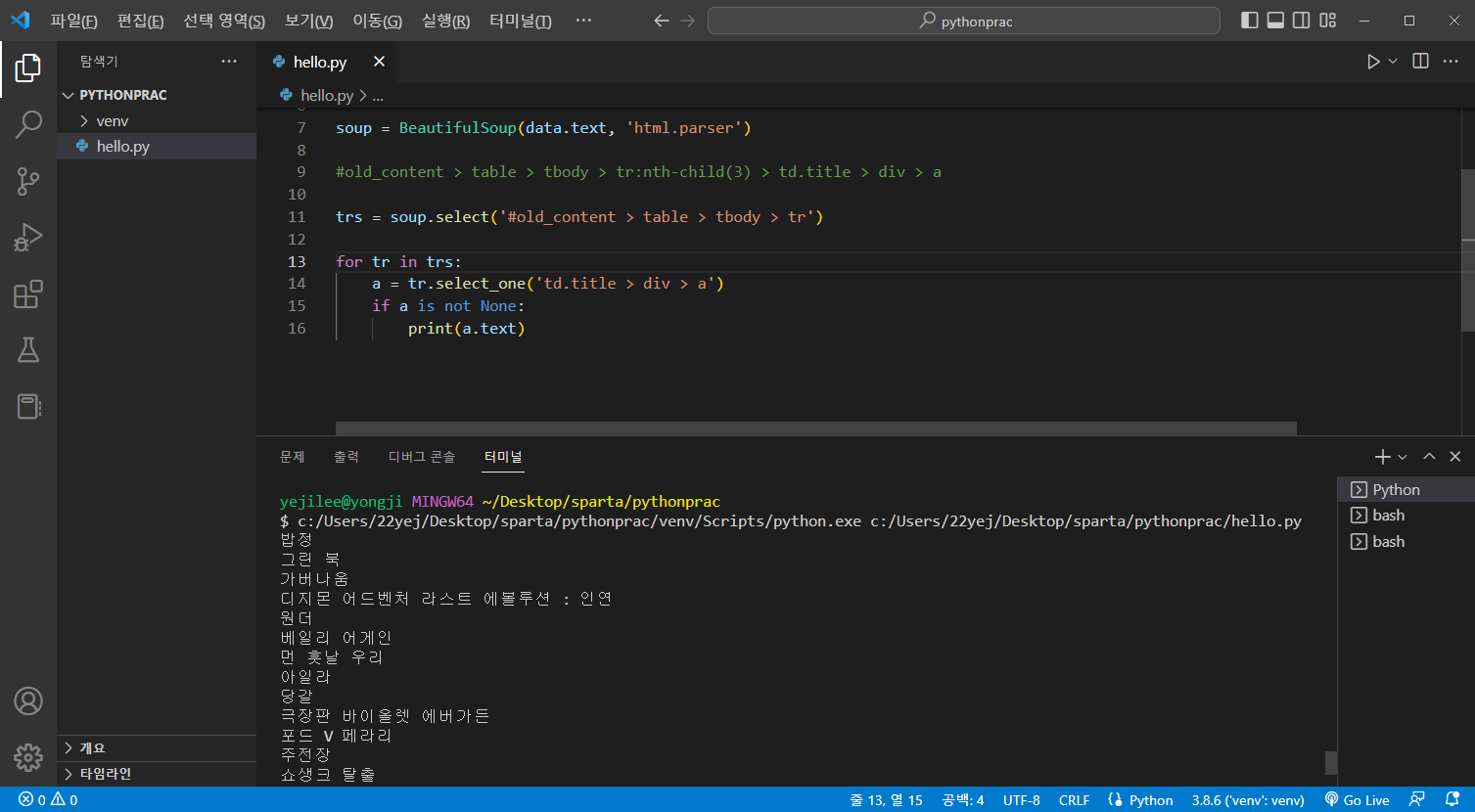
a.text로 제목만 나오게 출력해보자
for tr in trs:
a = tr.select_one('td.title > div > a')
if a is not None:
print(a.text)if a is not None: a에 none이 아닌 경우만 a.text 출력하라
(랭킹화면의 빈 줄도 tr로 들어가 있기 때문에 걸러주는 작업)
출력화면
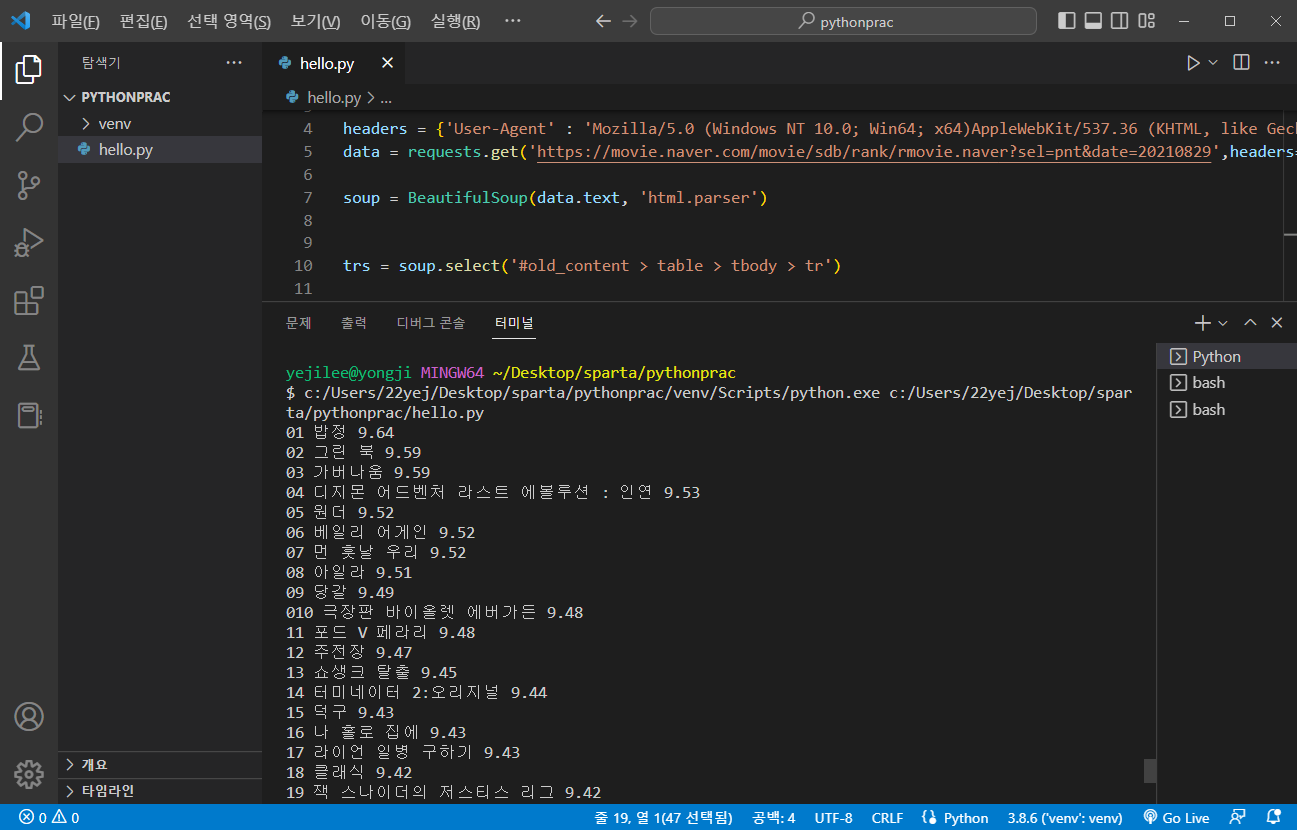
순위와 별점도 출력해보자
for tr in trs:
a = tr.select_one('td.title > div > a')
if a is not None:
title = a.text
rank = tr.select_one('td:nth-child(1) > img')
point = tr.select_one('td.point').text
print(rank['alt'], title, point)출력화면
파이썬은 다른 언어와 달리 자료를 스크래핑하는 게 쉬움
