[웹개발 종합반] 3주차 강의
🎯 수업 목표
- 파이썬 기초 문법을 안다.
- 원하는 페이지를 크롤링 할 수 있다.
- pymongo를 통해 mongoDB를 제어할 수 있다.
🎯 목차
- 연습 겸 복습 -스파르타피디아에 OpenAPI 붙여보기
- 파이썬 시작하기
- 파이썬 기초공부
- 파이썬 패키지 설치하기
- 패키지 사용해보기
- 웹스크래핑(크롤링) 기초
- Quiz_웹스크래핑(크롤링) 연습
...
1. Python - venv
가상환경을 만들어주는 파이썬 라이브러리
Why? 필요할까?
| 글로벌 파이썬 환경 | 가상환경 |
|---|---|
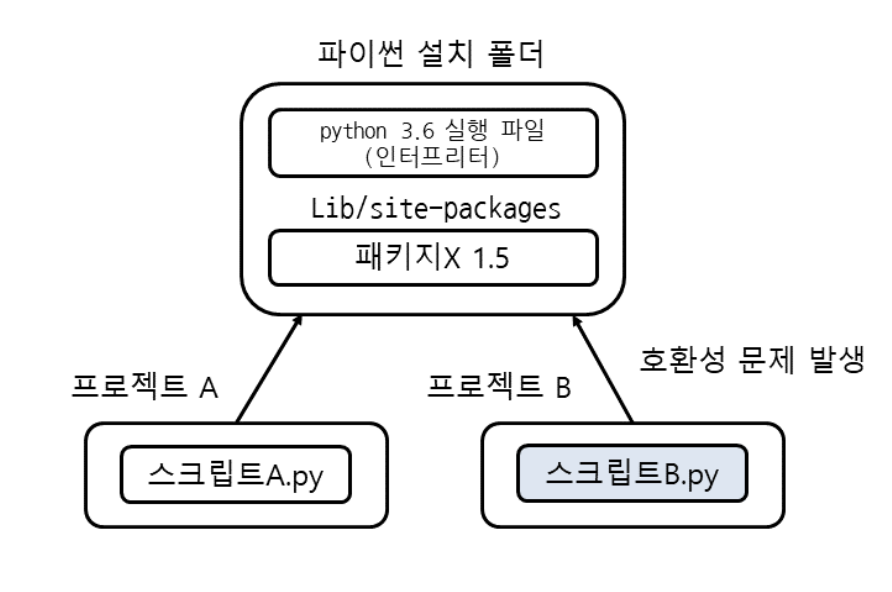 | 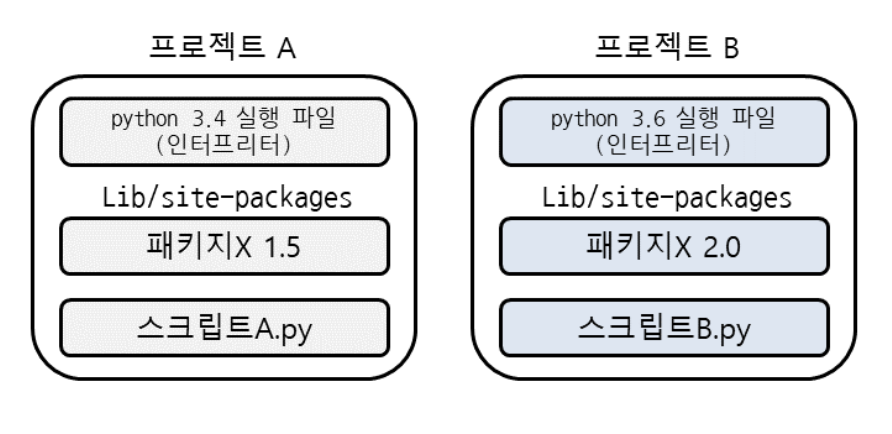 |
왼쪽과 같은 상황에서는, 프로젝트를 여러개 개발할 경우 패키지의 버전 문제가 생긴다. 버전이 달라 패키지별 호환이 되지 않는다면 개발하기 상당히 불편해진다. 이러한 문제를 해결하기 위해 가상환경(virtual environment)를 제공한다. 즉, 프로젝트별 독립적인 환경을 갖게 된다!
2. Python - requests
Requests란, Python용 HTTP 라이브러리로, API 데이터를 추출할 때 사용한다.
- 설치
pip install requests- 요청 method별 함수
requests.get('URL) # GET방식
requests.post('URL') # POST방식
requests.put('URL') # PUT방식
requests.delete('URL') # DELETE방식- Requests 라이브러리 사용해보기
import requests # requests 라이브러리 설치 필요
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
gus = rjson['RealtimeCityAir']['row']
for gu in gus:
print(gu['MSRSTE_NM'], gu['IDEX_MVL'])3. Python - bs4(beautifulsoup4)
BeautifulSoup은 HTML과 XML 문서들의 구문을 분석하기 위한 파이썬 라이브러리이다. HTML로부터 데이터를 추출하기 위해 사용할 수 있는 파싱된 페이지의 파스트리를 만드는데, 이는 웹 스크래핑에 유용하다.
- 설치
pip install bs4- 기본 세팅
가장 먼저 HTML 데이터를 가져와야 한다.
보통 requests 통신으로 요청하여 HTML 코드를 가져온 후 BeautifulSoup 객체로 만들어준다.
첫 번째 인자로 HTML코드, 두번째 인자로 파서 종류를 설정하는데 'html.parser' 외에 'lxml'등 상황에 맞는 종류로 설정해준다.
import requests
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(uri, headers=headers) 데이터 url 요청
from bs4 import BeautifulSoup
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')-
bs4 사용해보기
👉 태그 안의 텍스트를 찍고 싶을 땐 ▶️ 태그.text
👉 태그 안의 속성을 찍고 싶을 땐 ▶️ 태그['속성'] -
예제1)
import requests
from bs4 import BeautifulSoup
# URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr') // 파싱할 부분들의 가장 큰 공통된 부분
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a') // 상세 위치
if a_tag is not None:
# a의 text를 찍어본다.
print (a_tag.text)- 예제2) beautifulsoup 내 select에 미리 정의된 다른 방법
# 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')- 예제3) *항상 정확하지는 않으나, 크롬 개발자도구를 참고도 가능
- 원하는 부분에서 마우스 오른쪽 클릭 → 검사
- 원하는 태그에서 마우스 오른쪽 클릭
- Copy → Copy selector로 선택자를 복사할 수 있음
4. 후기
위와 같은 과정들을 배우면서 웹 크롤링과 웹 스크래핑의 차이가 궁금해서 찾아봤다. 웹 크롤링과 웹 스크래핑은 모두 정보를 추출해온다는 공통점은 있지만 '타깃 웹 페이지의 유무'와 '중복 제거의 실행 여부'에서 차이가 난다고 한다.
웹 크롤링은 특정 웹 페이지를 목표로 하지 않고 일단 탐색 후 정보를 가져오는 '선탐색 후추출'구조이다. 반면 웹 스크래핑을 할 때는 목표로 하는 특정 웹페이지가 있다. 우리가 원하는 정보를 어디서 가져올지 타깃이 분명하고, 그 타깃에서 정보를 가져오므로 '선결정 후추출'이다.
또한, 웹 크롤링에서는 중복 제거가 필수적이다. 중복되거나 불필요한 정보는 분류를 더 어렵게하기 때문이다. 도서관의 책이 개별적으로 구분되는 색인이 있는 것처럼 웹 크롤링도 수집한 웹 페이지가 중복되지 않도록 서로 다른 색인을 남긴다. 그래서 웹 크롤링을 웹 인덱싱(web indexing)이라고도 부른다고 한다. 반면 웹 스크래핑에서는 중복 제거가 필수는 아니다.
