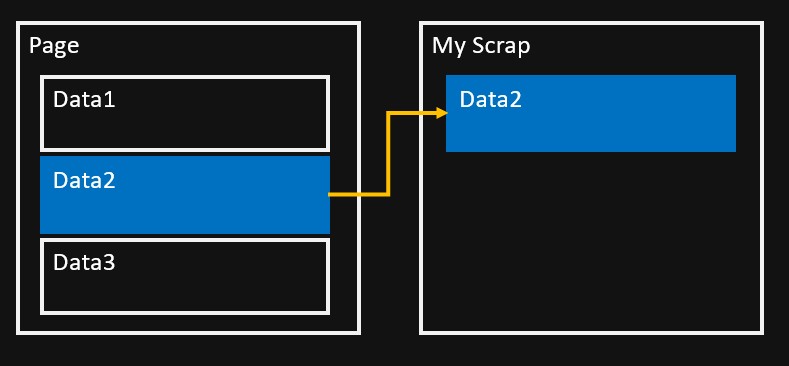
스크랩핑이란?
- 어렸을 적 신문지에서 우리가 좋아하던 아이돌 또는 뉴스 기사를 오려다가 공책에 붙이는 행위를 스크랩하는 것이라고 들어봤을 것이다. 학교 숙제로도 많이 했었던 기억이 난다.
- 인터넷 상에서 우리가 필요한 정보를 어떠한 웹페이지에서 가져오는 것, 그것을 스크랩핑이라고 한다.
크롤링
- 스크랩은 한 페이지에서 특정 정보를 가져오는 것이라고 하면 크롤링은 그 페이지 자체를 가져오는 것이다.
어원은 모르겠다.
준비 과정
- 우리가 필요한 정보를 가진 웹 페이지
- 소스 코드 편집기(Visual Studio Code)
- python
- pip
https://bootstrap.pypa.io/get-pip.py
위 URL에서 다운받은 get-pip.py 가 있는 경로에서 cmd 명령어 입력
py get-pip.py - BeautifulSoup4
pip install beautifulsoup4
기초 학습
1. 웹 페이지 정보 가져오기
- python의 requests 모듈을 이용하여 html 정보를 가져오자
requests 문법
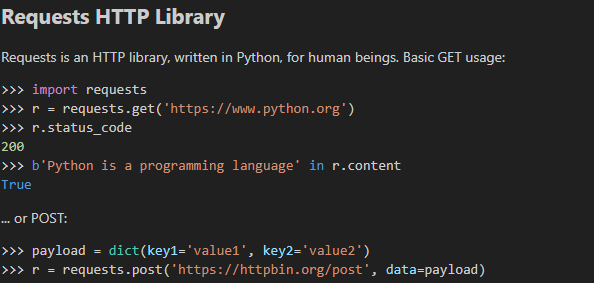
requests.<HTTP Method>('URL')
Content
- requests 모듈을 사용하여 원하는 정보를 추출하고자 할 때 그 정보가 어디에 있는지 아는게 중요하다.
- 보통 스크랩핑은 웹페이지 안의 내용을 가져오고자 하니 content를 사용하지만 단순 HTTP Response Code가 필요한거라면 status_code를 요청할 수도 있다.
Source Code Sample
import requests
req = requests.get('https://www.krcert.or.kr/kr/bbs/list.do?bbsId=B0000302&menuNo=205023')
print(req.content)2. html 소스를 시각화
- html 소스를 위 requests를 가져온다고 해도 text형태이기 때문에 가시성도 떨어질 뿐더러 그 안의 정보를 쉽게 추출하기란 어렵다.
어렵다기 보단 눈이 아프다 - 이를 쉽게 해주는 모듈이 스크랩핑의 꽃 BeautifulSoup4 이다.
3. BeautifulSoup
-
사용법은 간단하다. 모듈을 import 한 상태에서 위에서 가져온 정보를 정해진 문법에 따라 우리가 보기 쉬운 html 형태로 바꾸는 것이다.
import requests from bs4 import BeautifulSoup req = requests.get('https://URL') scrap = BeautifulSoup(req.content, 'html.parser') -
모듈을 사용하기 전
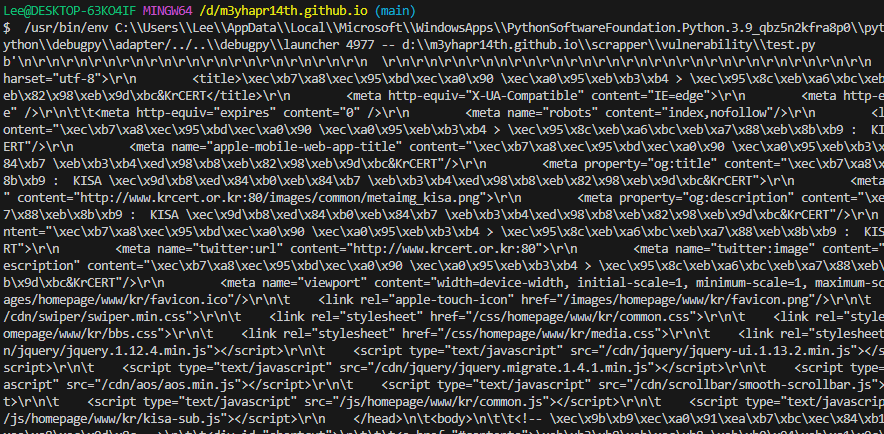
-
모듈 사용 후
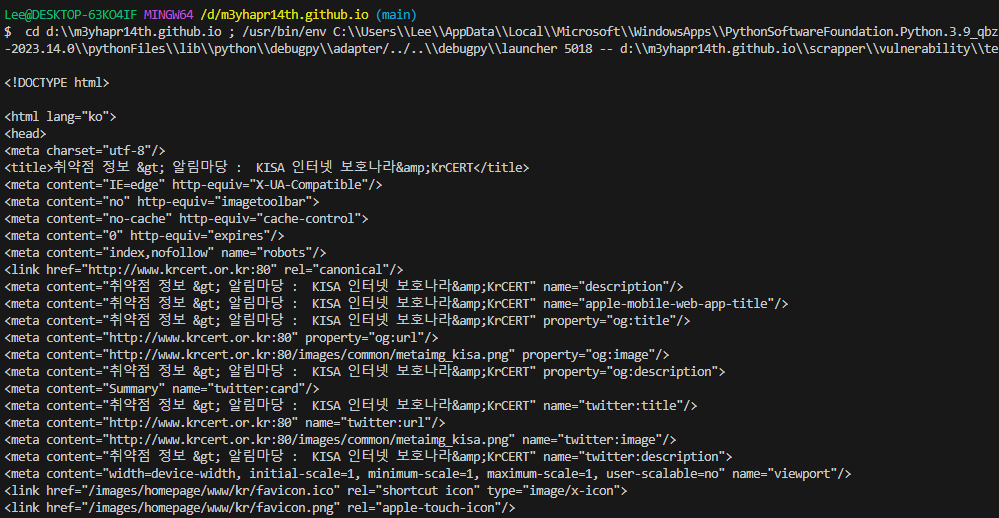
find vs find_all
- 보기 좋게 만들었다고 해서 끝난 게 아니다. 내용 중에 우리가 필요한 정보를 찾아서 그 부분만 추출해야하는 작업을 해주어야 한다.
- 필요한 특정 정보를 찾기 위해 find 와 find_all을 사용할 수 있다.
- 이 둘의 차이점은 명확하다. 정해진 키워드를 1개를 찾으면 멈추던가, 키워드가 있는 모든 걸 찾거나이다. 아래의 이미지를 참고하길 바란다.
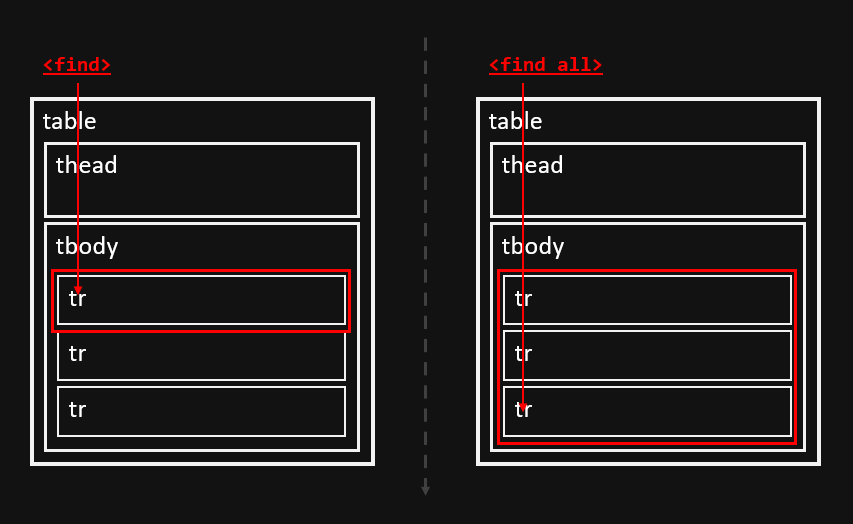
- tr이라는 키워드를 find로 찾았을 때와 find_all로 찾았을 때의 차이를 그려낸 그림이다.
결론
- 파이썬에서 스크랩핑은 사실 여기까지만 알고 있어도 거의 다 한거라고 볼 수 있다.
- 이를 어떻게 활용하고 어떤 방식으로 가져올 것인지는 역량에 있다고 생각한다.
- 다음은 실습으로 넘어가보자.
그랬다

잃기전에 기억하기