실습 목표
- KISA 보호나라의 취약점 정보를 가져와보자
준비 과정
필요한 소스 확인
-
웹사이트에서 개발자모드(F12)를 진입하여 소스(Element)를 확인하자

-
위 화면에서 우리가 필요한 정보는 "번호, 제목, CVSS, 게시일"이다.
-
소스코드를 한번 확인해보자
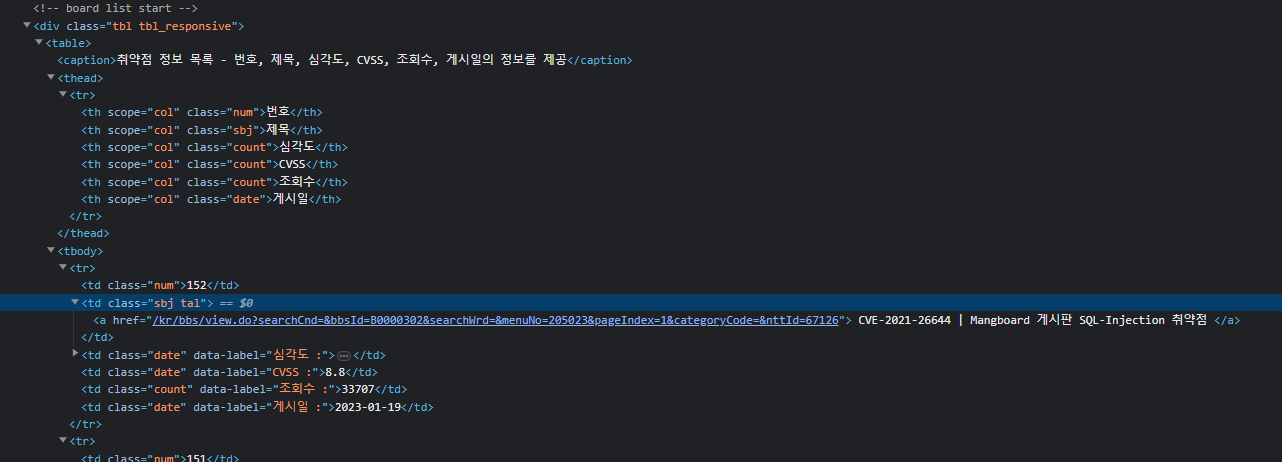
-
위 소스코드에서 보면 table 태그안에 thead, tbody 가 있고, 우리가 필요한 정보는 tbody 안의 tr에 있는 것을 확인했다.
복습(Find vs Find_all)
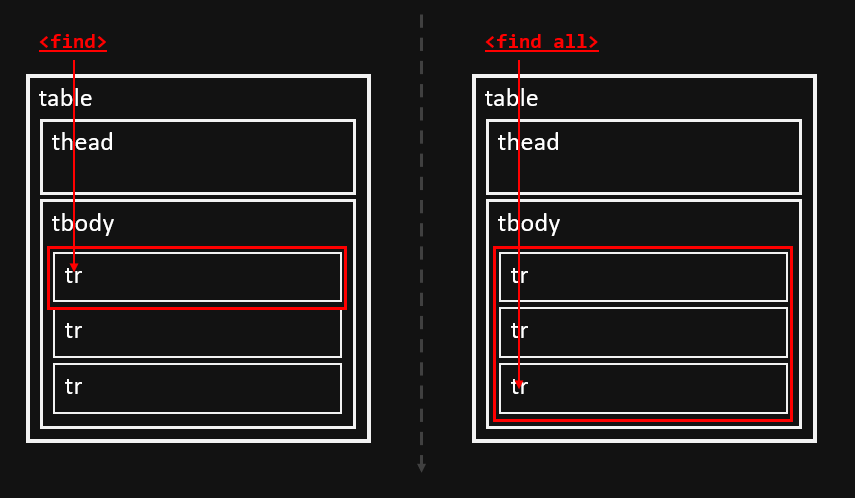
- 지난 기초 학습에서 설명했지만 BeautifulSoup 중 find와 find_all을 이용해볼 예정이다
- find는 키워드 중 첫번째 1개만 찾고, find_all은 키워드의 모든 것을 찾는다.
Find 의 동작 방식
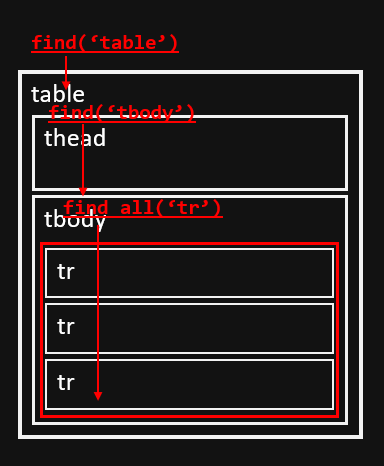
- 위 이미지와 같이 우리가 찾는 정보는 tr에 있고 tr에 도달하려면 table과 tbody를 거쳐 tr을 찾아내야 한다.
여기까지 이해했다면 바로 코드를 짜보자
실습
1. 스크랩핑할 웹 페이지 호출
- requests 모듈을 이용하여 웹페이지를 호출하자
import requests
req = requests.get('https://www.krcert.or.kr/kr/bbs/list.do?bbsId=B0000302&menuNo=205023')- 위 코드를 print해보면 아래와 같다
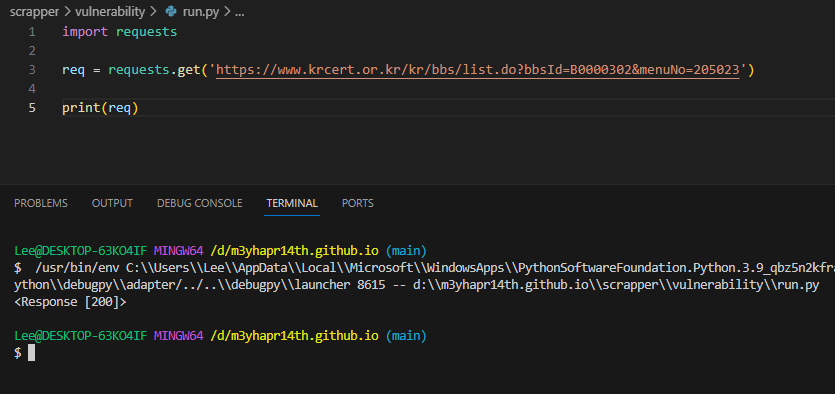
- Status code가 기본적으로 나온다
- 우리가 필요한 정보는 소스의 내용이므로 req.content를 출력해보면,,,
- 얼추 내용처럼 보이긴 한다.
2. HTML 소스를 보기 좋게
- BeautifulSoup 모듈을 이용하여 내용을 가시적으로 볼 수 있게 만들어보자
import requests
from bs4 import BeautifulSoup
req = requests.get('https://www.krcert.or.kr/kr/bbs/list.do?bbsId=B0000302&menuNo=205023')
scrap = BeautifulSoup(req.content, 'html.parser')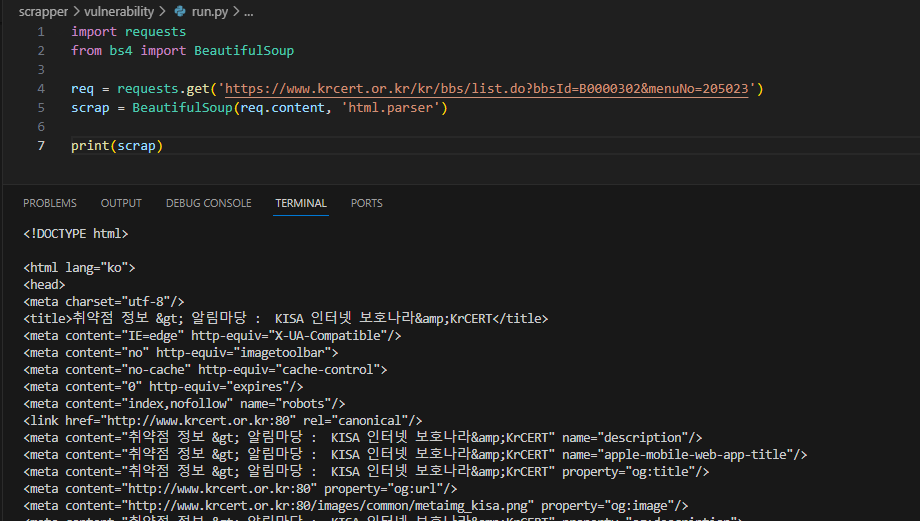
- 확실히 우리가 보기 좋은 형태로 변한 걸 확인할 수 있다
3. 정보 찾기
1) find, find_all을 이용하여 필요한 정보를 찾아보자
table = scrap.find('table')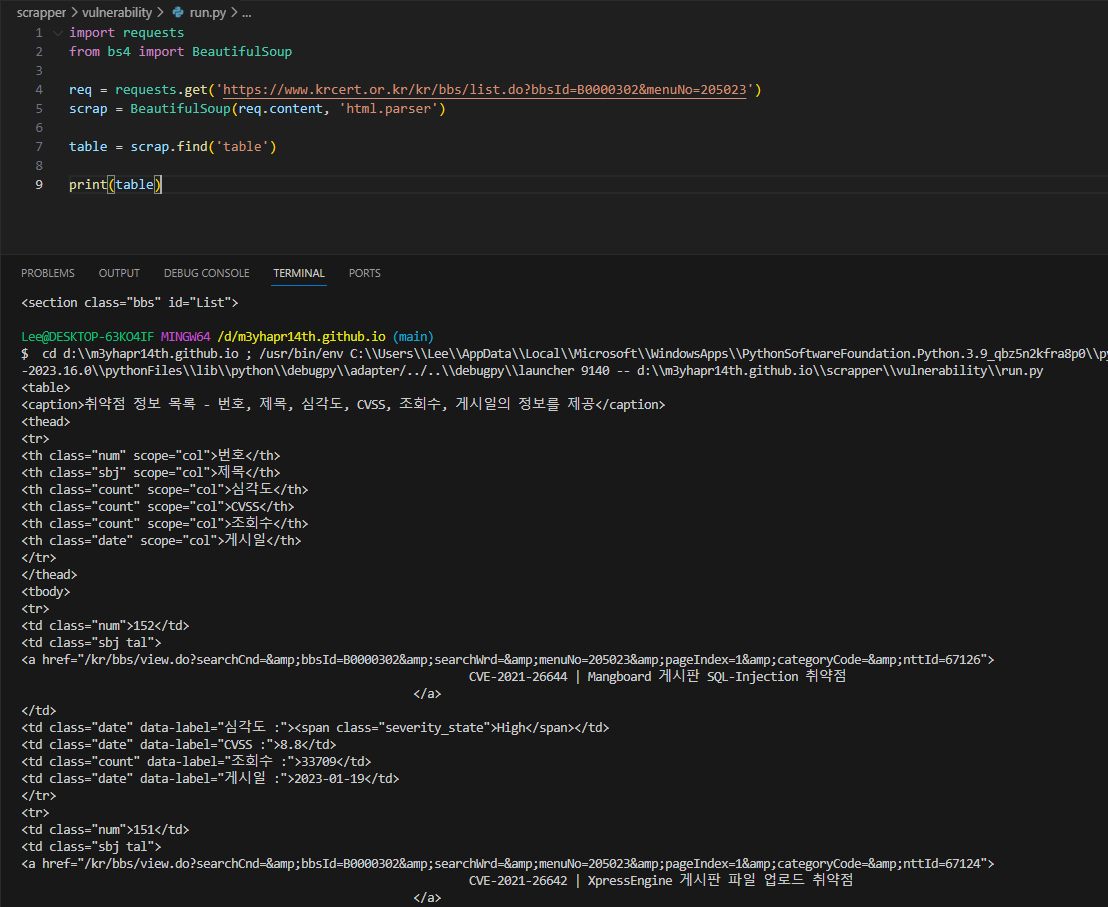
- 필요한 정보까지 가까이 온 것 같다.
만약 해당 소스에 table이 여러개고 위 이미지와 같은 정보가 2번째의 table이라면 find_all을 이용하여 찾은 다음 인덱스를 이용하여 찾아야한다.
table = scrap.find_all('table')
print(table[1])
2) thead에는 테이블의 식별? 제목같은 느낌의 내용만 있고 필요한 정보는 없다. tbody를 찾아보자
tbody = table.find('tbody')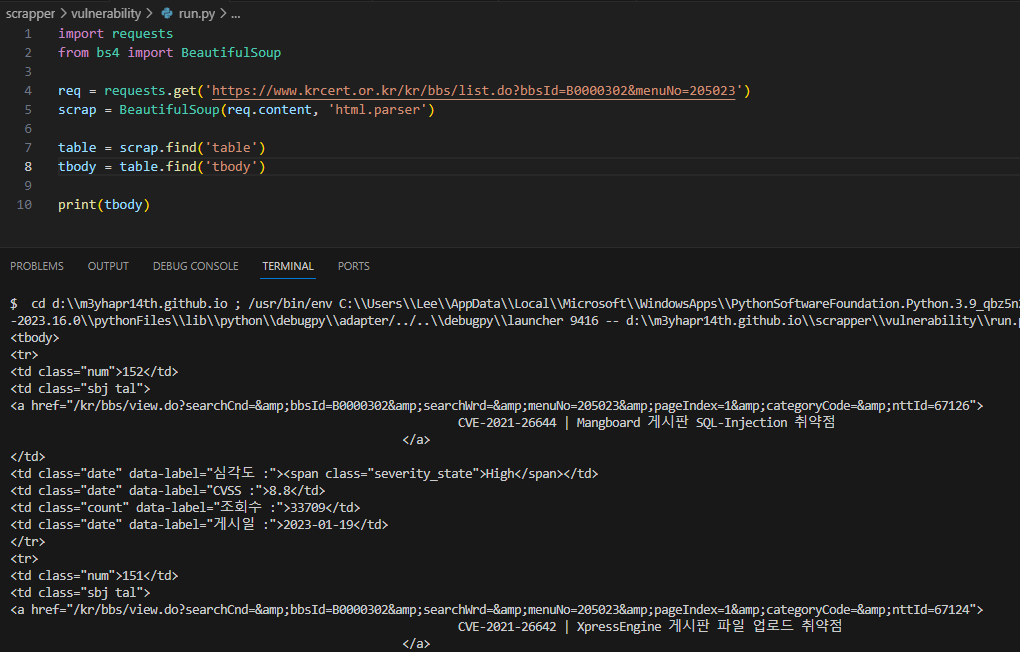
- 변수가 여러개가 되면 지저분해질 수 있기 때문에 아래와 같이 해도 된다.
table = scrap.find('table').find('tbody')3) tbody안의 tr를 find와 find_all로 비교해보면,
-
find
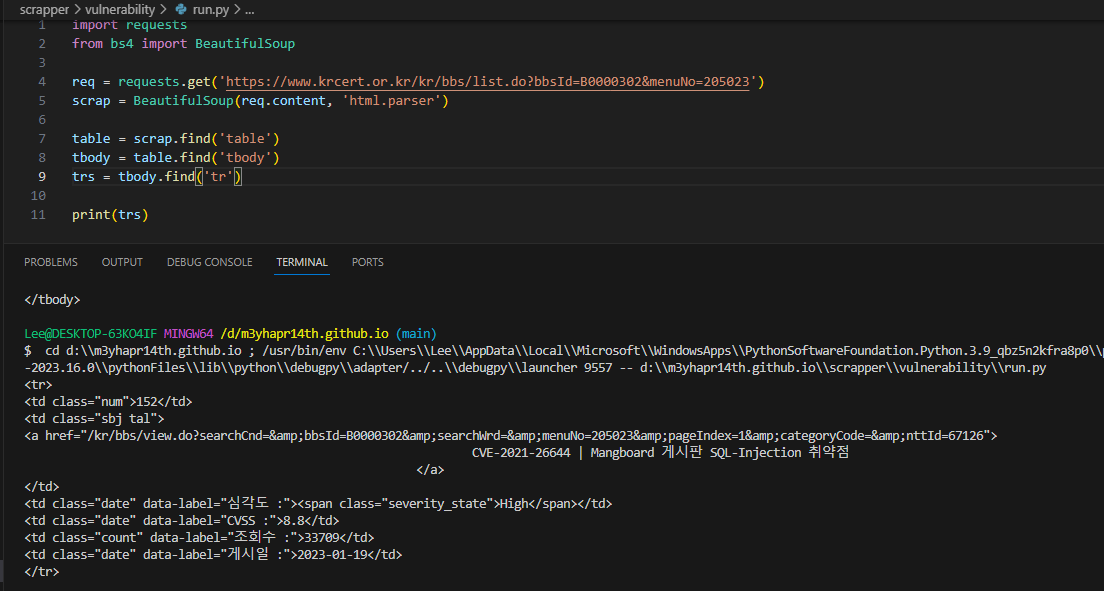
-
find_all
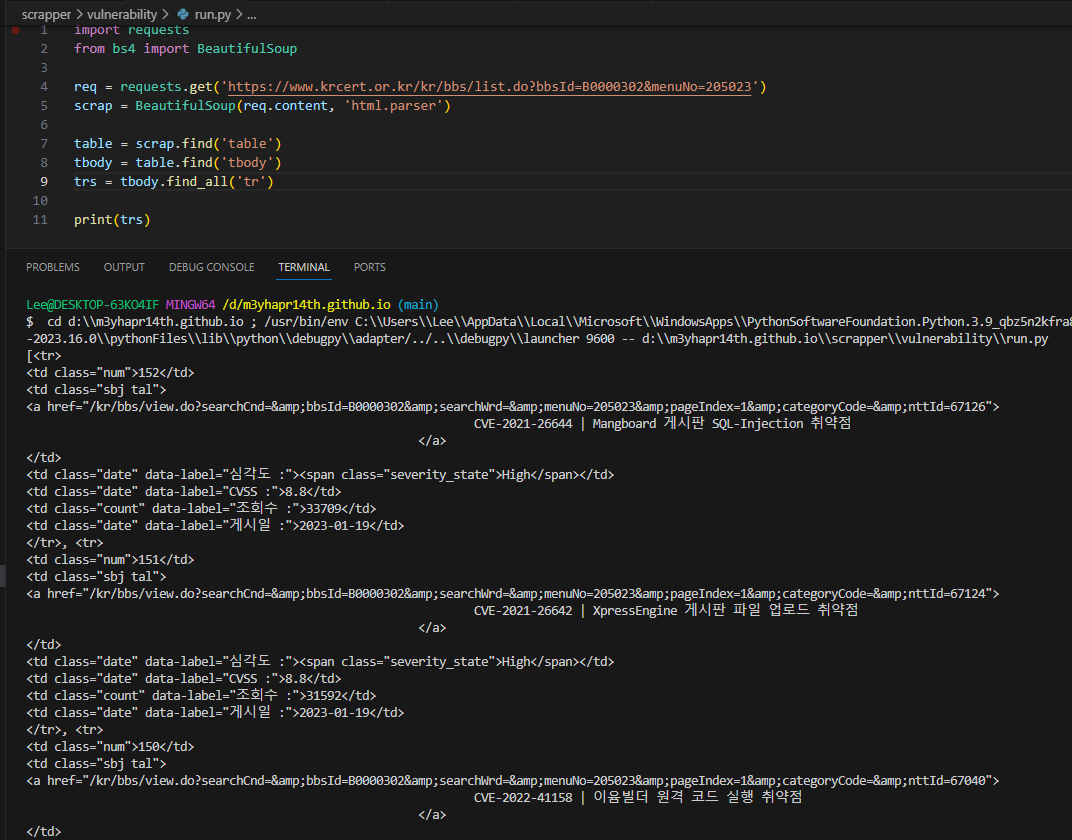
find는 tr의 첫번째 내용만 보이고, find_all은 모든 tr을 list 형태로 보여준다
4) tr 안의 내용 중 필요한 정보만 추출해보자
- td도 형태가 여러개이기 때문에 find_all을 통해 list 형태로 만들고 인덱스 형태로 바꿀 수 있다
tds = trs.find_all('td')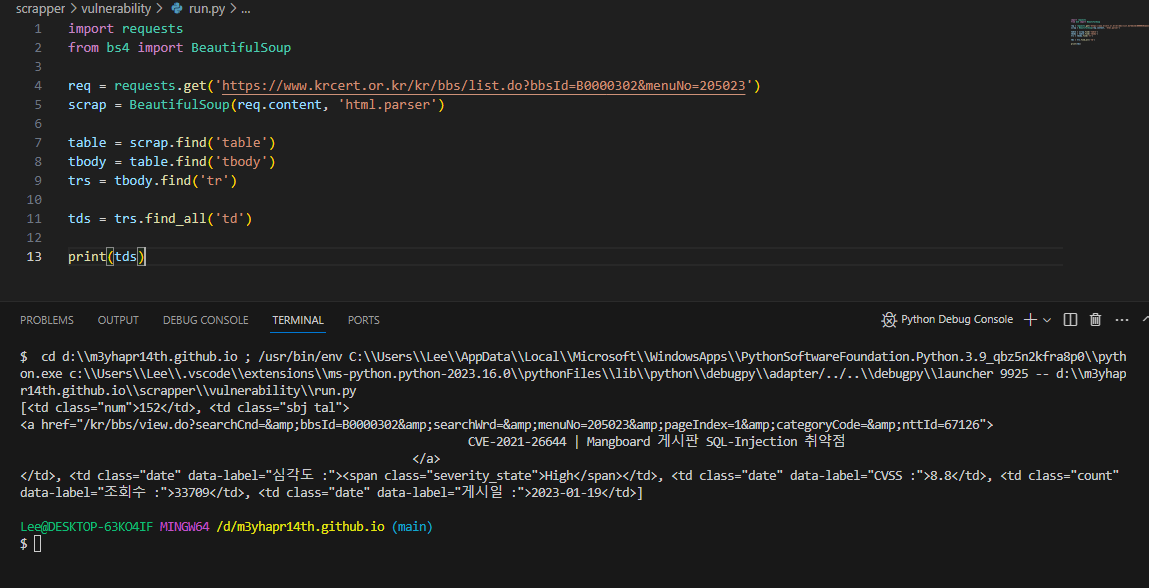
-
이제 list의 특정 내용만 보고 싶으면 index를 사용하여 필요한 부분을 추출하자
-
"번호"
num = tds[0]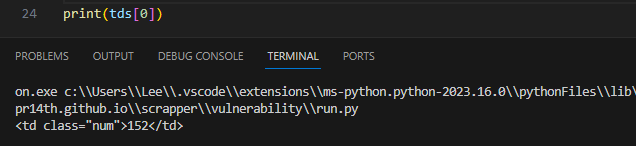
5) .text로 내용만 추출
- .text를 이용하면 html 태그를 제외한 내용(text)만 볼 수 있다.
num = tds[0].text
title = tds[1].text
severity = tds[2].text
cvss = tds[3].text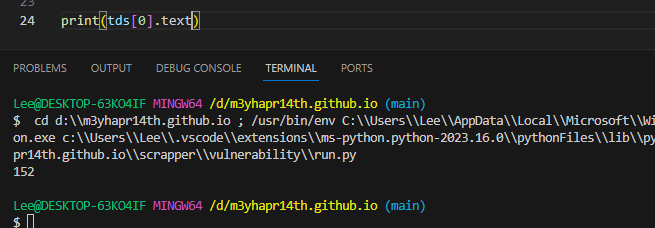
6) 필요한 정보를 사전(dictionary) 형태로 보기
vuln_dic = {'num':num, 'title':title, 'severity':severity, 'cvss': cvss}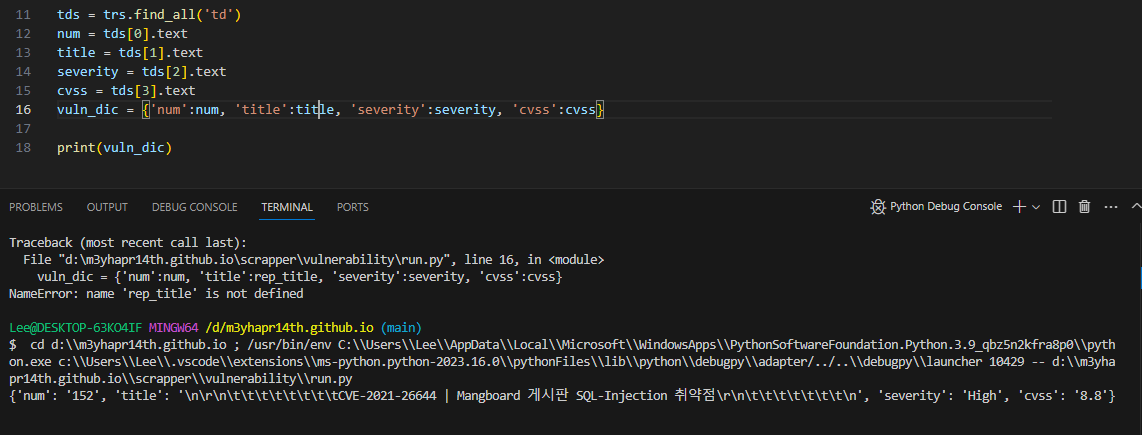
4. Source Code
import requests
from bs4 import BeautifulSoup
req = requests.get('https://www.krcert.or.kr/kr/bbs/list.do?bbsId=B0000302&menuNo=205023')
scrap = BeautifulSoup(req.content, 'html.parser')
table = scrap.find('table')
tbody = table.find('tbody')
trs = tbody.find('tr')
tds = trs.find_all('td')
num = tds[0].text
title = tds[1].text
severity = tds[2].text
cvss = tds[3].text
vuln_dic = {'num':num, 'title':title, 'severity':severity, 'cvss':cvss}
print(vuln_dic)5. 실행 결과

- 제목(title)에 '\n', '\r', '\t' 와 같은 개행문자가 들어가는데 다음 실습에서 개선해보도록 하겠다
결론
- 어떤 식으로 정보를 찾아내는지 알아보았다.
- 다음은 1개가 아닌 여러개의 정보를 모으고 json 형태로 저장하는 것까지 해보자

잃기전에 기억하기