사전지식
Visual Studio에서 C++ 컴파일러 및 빌드 속성 설정
빌드 구성할 때 대부분의 속성은 구성(대상 플랫폼, 실행 파일이 실행되는 디바이스 및 운영 체제의 종류) 컴파일러는 올바른 코드를 생성하기 위해 프로그램이 실행될 특정 플랫폼과 사용할 특정 컴파일러 옵션을 모두 알고 있습니다.
컴퓨터의 이해
CPU의 구조
CPU는 연산 장치, 제어 장치, 레지스터, 외부 인터페이스로 구성되어 있습니다.
연산 장치는 정수 연산과 논리 연산을 하는 ALU(Arithmetic Logic Unit)와 실수를 처리하기 위한 FPU
(Floating Point Unit)으로 구성되어 있습니다.
제어 장치(CU, Control unit)은 프로세서의 조작을 지시하는 장치입니다. 입출력 장치 간 통신 및 조율을 제어하고, 명령어들을 읽고 해석하며 데이터 처리를 위한 시퀀스를 결정합니다.
레지스터는 CPU에서 작업을 하기 위해 값이나 상태를 저장할 때 사용하는 장치(메모리)를 레지스터라고 부릅니다. CPU 외부에 있는 메모리는 주소를 사용해서 접근해야 하지만, CPU 내부 메모리인 레지스터는 번지가 아닌 고유 명칭을 사용합니다. x86 기준으로 이름과 용도는 아래와 같습니다.
- AX(Accumulator Register) : 연산에 사용되는 레지스터
- BX(Base Register) : 연산과 주소의 간접 지정에 사용되는 레지스터
- CS(Counter Register) : 연산과 반복 작업에서 반복 횟수를 계산하는데 사용되는 레지스터
- DX(Data Register): 연산에 사용되는 레지스터(AX와 함께 사용)
- SP(Stack Pointer): Stack 메모리에서 데이터가 추가될 위치를 기억하는 레지스터
- BP(Base Pointer) : Stack 메모리에서 주소를 간접 지정할 때 사용하는 레지스터 (C언어에서는 현재 수행중인 함수에 선언된 지역 변수들의 시작 주소를 저장하는 용도로 사용)
- SI(Source Index) : 주소의 간접 지정에 사용되는 레지스터
- DI(Destination Index) : 주소의 간접 지정에 사용되는 레지스터
- FL(Flag register) : CPU의 동작 상태나 처리한 작업 상태를 비트 단위로 저장하고 있는 레지스터
- IP(Instruction Pointer) : 다음에 실행할 명령의 위치를 기억하는 레지스터
CPU는 위 레지스터를 활용해서 아래와 같은 방식으로 동작합니다.
1. 제어 장치(CU)가 현재 처리할 명령어를 메모리에서 가져온다.
2. 가져온 명령을 제어 장치가 해석한다.
3. 명령이 단순 메모리 명령이면 아래의 작업을 수행한다.
4-1. 값 읽기 명령이면 메모리에서 값을 읽어 레지스터에 저장한다.
4-2. 값 저장 명령이면 레즛터의 값을 메모리에 저장한다.
4-3. 연산 명령이면 레지스터에 저장된 값을 연산 장치를 사용해서 연산하고 그 결과를 다시 레지스터에 저장한다.
100 1011 0100 0101 1111 1000예를 들어, 위와 같은 명령이 메모리에 저장되어 있으면, 제어 장치가 메모리에서 위 값을 읽어옵니다.
mov eax, DWORD PTR [ebp-8]제어 장치는 위 명령이 대입 명령(mov, 메모리 값을 레지스터에 저장)이라는 것을 해석하고 연산 장치(ALU, FLU)을 이용해서 BP 레지스터의 값에 8을 뺍니다. 그리고 연산 결과 값을 주소로 저장해서 메모리에 4바이트 크기의 값을 읽어 AX 레지스터에 저장합니다.
즉, 제어장치가 명령을 해석하고 레지스터에 저장된 값을 연산 장치로 연산을 합니다. 그리고 메모리에서 값을 읽어 레지스터에 저장합니다.
CPU 레지스터의 변천사
여기서 잠깐, 레지스터의 'X'는 무엇을 뜻하는 것일까요?
결론부터 이야기하자면 '쌍(pair)'의 뜻입니다. 그렇다면 무엇으로부터의 쌍일까요? Chapt3.1에 해당하는 'CPU의 변천사'에 대해 조금더 알아봅시다
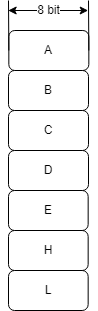
1972년에 intel은 세계 최초로 8-bit 마이크로프로세서(CPU)를 소개했습니다. 이 칩에는 7개의 8-Bit register가 있었어요.(실은 'M'까지 포함해서 8개인데, 얘는 16-bit으로 확장되면서 사라졌습니다.) 'A'라는 레지스터는 산술 및 논리 연산을 담당했기 때문에 Arithmetic의 A였습니다.
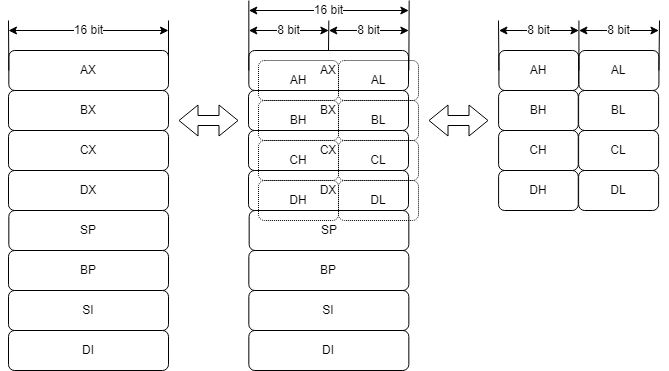
1979년에 지금 보편적으로 쓰이게 된 16-bit 마이크로프로세서인 8086을 도입했습니다. 여기서 중요한건, 기존 고객 기반을 활용하기 위해 8008까지 호환하도록 만들었어요. 이를 위해 8086 명령어 세트 아키텍쳐(ISA)가 8008에도 잘 매칭되어야 했습니다. 위와 같은 방법으로 8개의 16비트 레지스터와 8개의 8비트 레지스터를 겹치는 식으로 설계했습니다.
때문에 8086 명령어에는 비트 플래그라는 레지스터를 지정하는 기능이 있습니다.
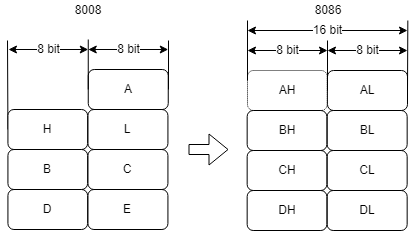
예를들어, AX는 16비트 누산기지만, AH는 8비트 레지스터로 간주되거나 상위 및 하위 바이트에 AL 액세스하는 방법으로 간주될 수 있습니다. 그래서 AX에서 X는 H와 L의 자리 표시자를 의미합니다.
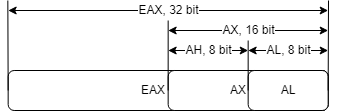
1985년에 Intel은 x86 라인의 최초 32-bit 프로세서인 80386을 출시했습니다.(386 컴퓨터 들어보셨나요?)
많은 새로운 기능이 도입되었지만, 8086까지의 바이너리 호환을 계속하기 위하여 메인 레지스터에 접두어(E, Extended)를 붙여 EAX라는 방식으로 확장했습니다.

2003년에 AMD는 아키텍처 리더십을 장악하고 x86 계보에 최초의 64-bit 프로세서를 도입합니다. 이로인해 8개의 메인 레지스터가 64비트로 확장되었죠. 그래서 확장 레지스터는 E를 대체하여 R(Register)이라는 접두사를 사용하게 됩니다.(RAX) 갑자기 왜 AMD가 레지스터의 이름을 명명하게 되었냐구요? 거기엔 더 많은 스토리가 있지만 생략하겠습니다!
제가 퍼온 블로그 주인이 x86의 설계자인 Stephen Morse 박사에게 받은 답변을 첨부하겠습니다.
블라디미르,
귀하의 질문은 확실히 40년 전에 내려진 결정에 대한 나의 기억을 자극하고 있습니다. 따라서 다음은 제가 기억하는 것 중 최고이며 반드시 100% 정확하지는 않습니다.
8086 이전에는 레지스터가 A, B, C, D와 같은 단일 문자였습니다. 각각은 8비트 레지스터였습니다. 8086에는 한 번에 8비트를 참조하거나 한 번에 16비트 모두를 참조할 수 있는 16비트 레지스터가 있습니다. 예를 들어 A 레지스터의 상위 8개 비트, A 레지스터의 하위 8개 비트 또는 A 레지스터의 전체 16비트를 참조할 수 있습니다. 처음 두 개의 명명법은 AL과 AH로 선택되었으며, 여기서 L/H는 하위 또는 상위 절반을 지정했습니다. 이제 전체 16비트를 지정하는 용어가 필요했습니다. 그래서 문자 X가 선택되었습니다. X는 단순히 L과 H를 결합한 임의의 문자였습니다. 대수학에서 미지수를 지정하기 위해 X를 사용하는 것과 비슷합니다. X가 무엇을 의미하는지에 대해서는 실제로 그렇게 많이 생각되지 않았습니다. 포인터와 인덱스가 아닌 일반 레지스터(AX, BX, CX, DX)를 식별하는 데 필요한 문자일 뿐이었습니다. 레지스터(SP, BP, SI, DI) 및 세그먼트 레지스터(CS, DS, ES, SS).
– 스티브 모스
출처 : EAX x86 Register
Meaning and History
메모리의 관리 단위와 사용 단위

위 사진과 같은 공공사물함을 많이 보셨죠? 공공사물함은 공공장소에서 물건을 보관하기 위해 일정한 크기로 어디에 넣었는지 확인이 편하도록 번호도 붙여져 있습니다.
컴퓨터도 마찬가지입니다. 메모리는 여러 프로그램들이 각자의 정해진 작업을 수행하고 처리 결과를 보관하기 위해 메모리라는 데이터 저장 장치에 담습니다. 메모리도 사물함처럼 크기가 일정하게 구분되어 있고 위치를 구분하기 위해 번호도 매겨져 있는데, 이를 주소(address)라고 부릅니다. 그렇기 때문에 메모리 공간에 접근하려면 반드시 주소를 사용해야 접근이 가능합니다.
사물함도 각자의 사용 목적에 따라 크기가 크기도 하고, 작기도 합니다. 이렇게 사물함의 크기를 역할에 따라 합리적으로 결정해도, 누군가에게는 공간이 부족하고 누군가에게는 커서 낭비될 수 있습니다. 사물함의 설계자는 적당한 크기를 정하기 위해 고민했겠죠.

메모리를 설계한 사람도 고민했을 것입니다. "주소(번호)가 부여된 메모리 한 칸의 크기를 어떤 크기로 해야 효율적일까?"
그래서 컴퓨터는 바이트(Byte)라는 크기를 메모리 사용 단위로 결정하게 됩니다. (정답은 없었겠죠) 컴퓨터는 데이터를 숫자로 표현하기 때문에 1바이트 크기에는 0 ~ 255 사이의 숫자 중에 한 개의 숫자를 저장할 수 있습니다. 그리고 메모리 주소는 바이트 단위로 부여되기 때문에 주소가 1이 증가 하면 실제로도 1바이트 크기만큼 이동하게 됩니다.
