
미안합니다 이거 보여주려고 어그로 끌었습니다
"પ નુલુંગ લસશ"나 "⎝⎛° ͜ʖ°⎞⎠પ ભય નુૂપ"와 같이 재밌는 글자를 찾아서 친구에게 메모장에 적어 보내고 싶습니다. 메모장을 받은 친구는 글자가 깨져서 아래와 같이 보인다고 합니다.

나에게는 잘 보였던 텍스트가 왜 친구에게는 안 보였을까요? 이는 문자 인코딩 방식이 다르기 때문입니다. 문자열 인코딩 방식이란 무엇일까요?
-
이를 이해하기 위해, 데이터와 문자 인코딩이 무엇인지부터 살펴봅시다.
-
컴퓨터는 컴퓨터는 주기억 장치로 램(RAM, Random Access Memory)를 사용하여 데이터(Data)를 저장합니다. 보통 메모리라고 하면 램을 의미합니다. 메모리는 1바이트(8bit) 단위로 주소가 매겨져 있습니다.(운영체제마다 주소를 관리하는 방법이 상이합니다) 예를 들어 32bit 기반의 OS라면, 0부터 2의 32제곱(0 ~ 4,294,967,295)까지의 주소를 사용할 수 있어요.
- 메모리의 최소 저장 단위는 비트(bit)입니다. 0,1 중에서 한 개를 저장할 수 있는 크기인거죠. 이는 2진수의 표현 방법과 같습니다. 2비트는 각 비트에 0, 1 중 한 개를 저장할 수 있으니 4가지의 조합을 만들 수 있답니다. 1바이트는 8비트이므로 256개의 숫자 중 하나를 저장할 수 있어요.
-
아스키 코드란?
미국 정보교환 표준부호(영어: American Standard Code for Information Interchange), 또는 줄여서 ASCII( /ˈæski/, 아스키)는 영문 알파벳을 사용하는 대표적인 문자 인코딩이다. 아스키는 컴퓨터와 통신 장비를 비롯한 문자를 사용하는 많은 장치에서 사용되며, 대부분의 문자 인코딩이 아스키에 기초를 두고 있다. - 위키백과
-
즉 통신을 위해 문자를 전송할 때, 두 통신 장치가 97을 a라고 미리 약속하여 97을 주고 받는다면 소통이 가능한 것이죠. 만약 각 통신 장치마다 a에 대한 약속이 다르면 소통이 안되기 때문에, 이를 표준으로 정한 것이 아스키(ASCII) 입니다. 이때 문자 데이터를 약속한 숫자로 변경하는 것을 이를 '문자 인코딩(Encoding, 정보의 형태나 형식을 변환)' 혹은 '부호화'라고 합니다. 모스부호도 문자 인코딩이에요!
-
아스키는 초기 7비트 방식으로 인코딩되었기 때문에 총 128개로 사용되었으나 다양한 표현을 위해 8비트(256개)로 확장되었습니다. 이를 ANSI(American National Standard Institute)라고 합니다.
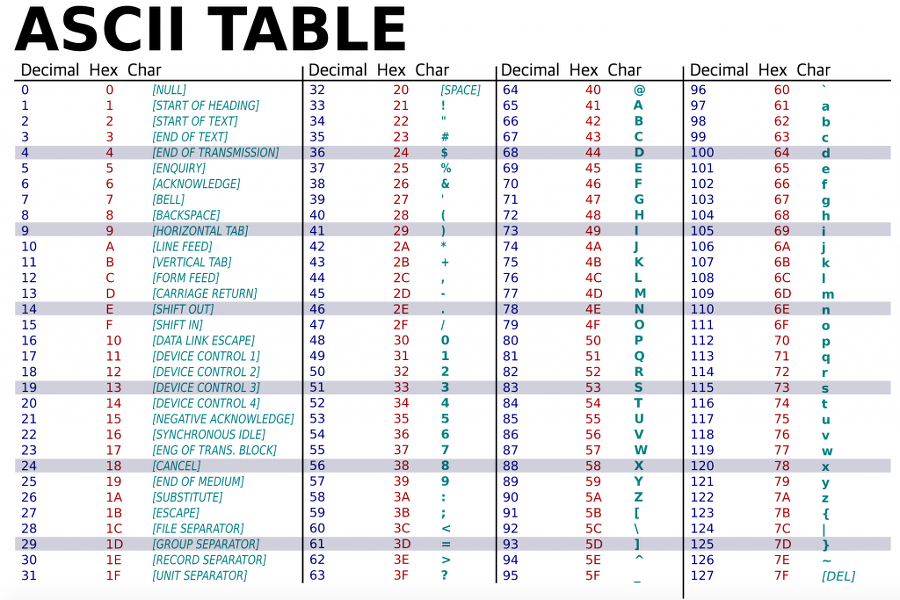
- (더 알아보기)
문자의 아스키 값은 부호없는 1바이트에 저장됩니다. 이게 무슨말일까요?
숫자는 음수도 있기 때문에 음수 데이터는 메모리에 저장할 때 가장 앞의 1개 비트에 0, 1로 음수 또는 양수인지의 상태를 저장합니다. 이를 부호비트라고 합니다. 이때의 양수와 음수를 구별하는 비트를 부호 비트라고 합니다. 8비트로 확장되면서 256개의 문자를 숫자로 표현하기 때문에 아스키 값은 부호 없는 1바이트에 메모리에 저장하게 됐습니다.
따라서 컴퓨터에서 가장 효율적인 메모리 저장인 1바이트 메모리에 맞게 저장할 수 있는 것이죠.
01111111 # 양수 최댓값인 127
10000000 # 음수 최댓값인 -128
11111111 # 음수 최댓값인 -1-
그러나 이러한 아스키 코드로 다른 나라와 통신하다보니 알파벳이 아닌 문자는 숫자로 인코딩할 수가 없었습니다. 이를 해결하기 위해 Unicode라는 전 세계 언어의 문자를 정의하기 위한 국제 표준 코드가 등장하게 된 것입니다.
-
유니코드란?
유니코드(Unicode)는 전 세계의 거의 모든 문자에 고유 숫자를 부여한 문자 집합으로, 1993년 국제 표준(ISO/IEC 10646)으로 제정되었다. 유니코드는 기본적으로 2 바이트로 한 문자를 표현하여, 기존 7 비트 또는 8 비트로 한 문자를 표현하는 아스키(ASCII) 문자 기반 시스템과 호환을 위해 UTF를 사용한다.
TTA 정보통신용어사전 -
유니코드는 기본적으로 2바이트로 한 문자를 표현합니다. 2의 16제곱인 65,536개의 문자(+기호들까지)를 숫자로 표현할 수 있게 된 것이죠. 2진법으로 0000 0000 0000 0000 ~ 1111 1111 1111 1111까지 조합이 늘어났습니다. 이것마저 다양한 언어와 기호(음표같은)를 인코딩하기에 부족해져서 평면(Plane)이라 불리는 17개의 영역까지 늘렸습니다. 모두 17x2^16개 = 백만개가 넘는 문자를 표현할 수 있게 된거죠. 참고로 한글 '가'는 유니코드로 'U+AC00(10진수로 44032)'입니다.

결국 친구는 유니코드 번호를 수동으로 입력해야 내가 보낸 언어를 볼 수 있는걸까요?
-
이렇게 문자와 숫자를 대응시켜 약속했지만, 컴퓨터가 데이터를 어떻게 저장할 것인지도 정해야 합니다. 프로그래밍이나 웹상에서 많이 쓰이는 ACII코드는 1바이트면 충분한데, 범위가 4바이트까지라고해서 모든 데이터를 4바이트에 저장하는 것은 비효율적이기 때문이죠. 이러한 문제를 해결하기 위해 데이터를 컴퓨터에 저장할 것인지, 즉 인코딩 방식도 정하게 됩니다. 이것이 UTF(Unicode Transformation Format)입니다.
유니코드 문자를 기존 문자 체계와의 상호 호환을 위해 가변 길이의 바이트열 값으로 인코딩하는 방식. 유니코드는 기본적으로 2 바이트로 한 문자를 표현하여, 기존 7 비트 또는 8 비트로 한 문자를 표현하는 아스키(ASCII) 문자 기반 시스템과 호환을 위해 UTF를 사용한다. UTF 인코딩 방식으로 UTF-8, UTF-16 및 UTF-32 등이 있다. UTF 뒤의 숫자는 한 문자를 인코딩하는 길이로, UTF-8은 유니코드 문자를 8비트(1바이트) 값으로 인코딩함을 의미한다. - TTA
-
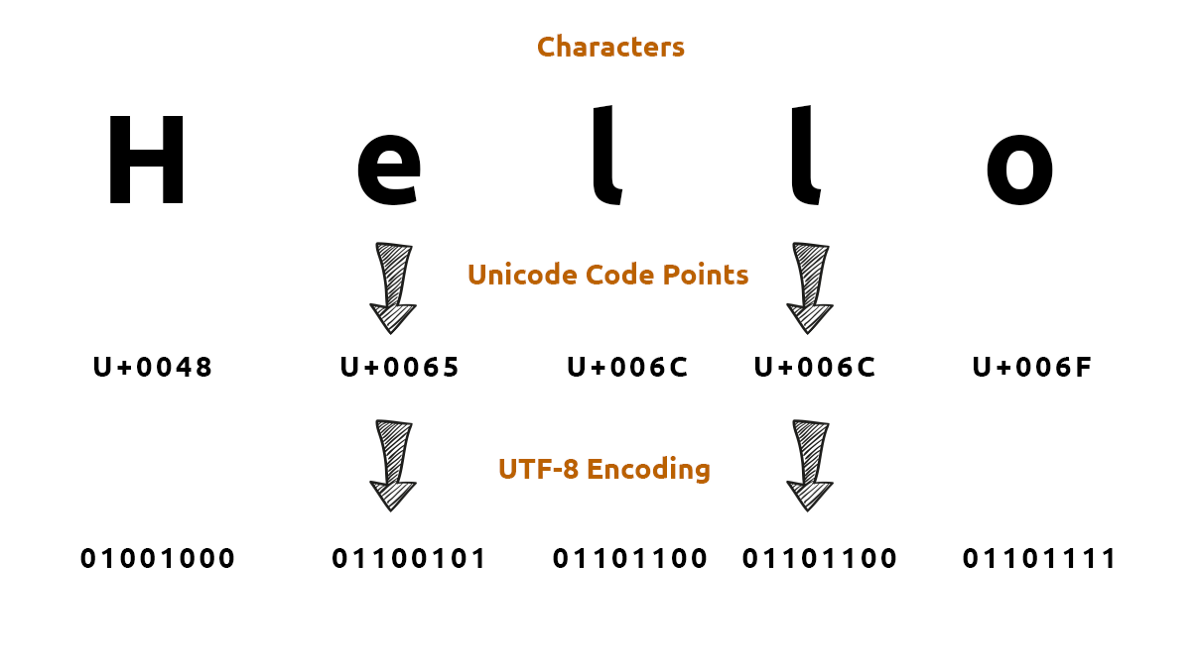
네 맞습니다! 우리가 메모장이나 텍스트 파일을 저장할 때 저장하는 그 인코딩 방식이 UTF-8 방식이 되는 것입니다. 유니코드 문자를 8비트(1바이트) 값으로 인코딩함을 의미합니다. 표준 영어 및 기호는 1바이트, 추가 라틴 및 중동 문자는 2바이트, 한글을 포함한 아시아 문자는 3바이트, 그 외는 4바이트로 저장하도록 약속되어 있습니다.
-
"A"와 "가"라는 문자를 저장하는 방식에 따라 어떻게 데이터가 달라지는지 확인해봅시다.

-
UTF-8은 A = 1byte, 가 = 3byte로 저장하여 총 4바이트입니다. UTF-16 방식은 A = 2byte, 가 = 4byte(3바이트는 2의 배수가 아니므로)로 저장해 총 6byte로 저장되네요.
-
운영체제별 사용하는 인코딩 방식도 다릅니다. 마이크로소프트(Windows)는 CP949, 맥(Mac)과 리눅스는 UTF-8의 인코딩 방식을 사용합니다.
친구에게 물어보니, Mac을 사용해서 그런 것이라네요. 인코딩 방식을 맞췄더니 글자가 보인다고 합니다.

- 저희가 작성하는 HTML파일에 항상 추가하는 위 코드 중 charset = "utf-8" 보이시나요? 이제 대강 짐작은 하시겠지만, 마지막으로 저 코드의 의미를 조금더 파헤쳐봅시다.
- 웹, 컴퓨터의 HTML 파일을 웹 브라우저에서 표시될 수 있도록 변환하는 처리작업입니다. 파일의 정보 형태가 어떤 언어로 되어있는지에 대한 지정을 해주는 코드인거죠.
- 참고로 "પ નુલુંગ લસશ"나 "⎝⎛° ͜ʖ°⎞⎠પ ભય નુૂપ" 같이 윗 글자도 뚫고 나가는 저 언어의 이름은 '구자라트어'입니다.
출처
Doit! C언어 입문
https://whatisthenext.tistory.com/103
https://it-eldorado.tistory.com/61
https://terms.tta.or.kr/dictionary/dictionaryView.do?word_seq=059151-5
https://jeongdowon.medium.com/unicode%EC%99%80-utf-8-%EA%B0%84%EB%8B%A8%ED%9E%88-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-b6aa3f7edf96
https://code-lab1.tistory.com/233
https://ko.wikipedia.org/wiki/%EC%9C%A0%EB%8B%88%EC%BD%94%EB%93%9C

와 정리 대박.. ANSI랑 UTF-8이 뭔지 이해 제대로 알았어요 !