- 병합 정렬(Merge Sort)이란, 분할 정복 알고리즘의 하나입니다.
분할 정복(divide and conquer) 방법이란?
문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략이다. 분할 정복 방법은 대개 순환 호출을 이용하여 구현한다.
과정 설명
1. 리스트의 길이가 0 또는 1이면 이미 정렬된 것입니다. 그렇지 않은 경우에는
2. 분할 : 정렬되지 않은 리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눕니다.
3. 정복 : 각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬합니다.
4. 결합 : 두 부분 리스트를 다시 하나의 정렬된 리스트로 모읍니다.
-
위의 GIF파일을 보면서 이해해보세요.
-
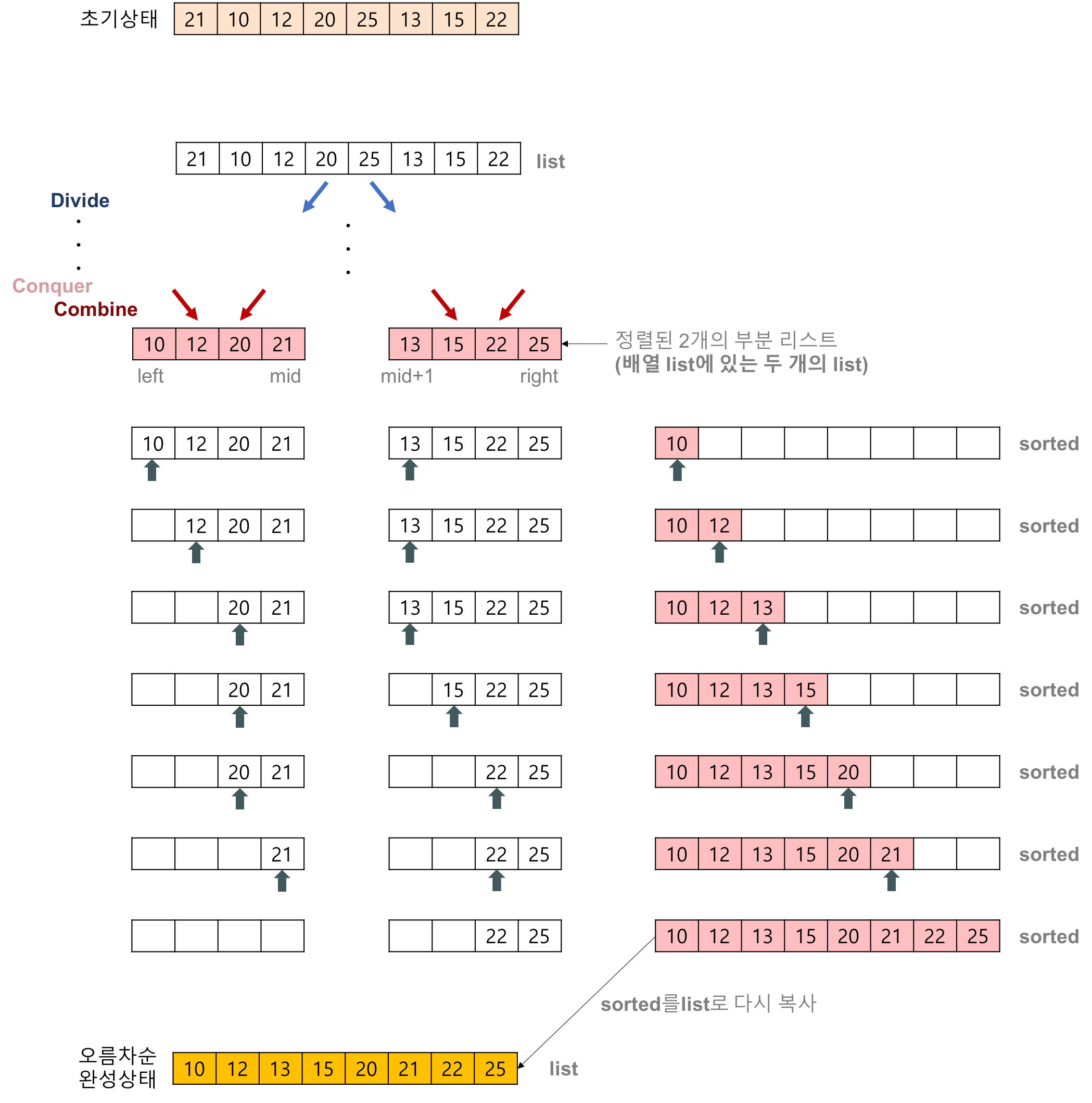
2개의 정렬된 리스트를 병합(merge)하는 과정
- 2개의 리스트의 값들을 처음부터 하나씩 비교하여 두 개의 리스트의 값 중에서 더 작은 값을 새로운 리스트(sorted)로 옮깁니다.
- 둘 중에서 하나가 끝날 때까지 이 과정을 되풀이합니다.
- 만약 둘 중에서 하나의 리스트가 먼저 끝나게 되면 나머지 리스트의 값들을 전부 새로운 리스트(sorted)로 복사합니다.
- 새로운 리스트(sorted)를 원래의 리스트(list)로 옮깁니다.
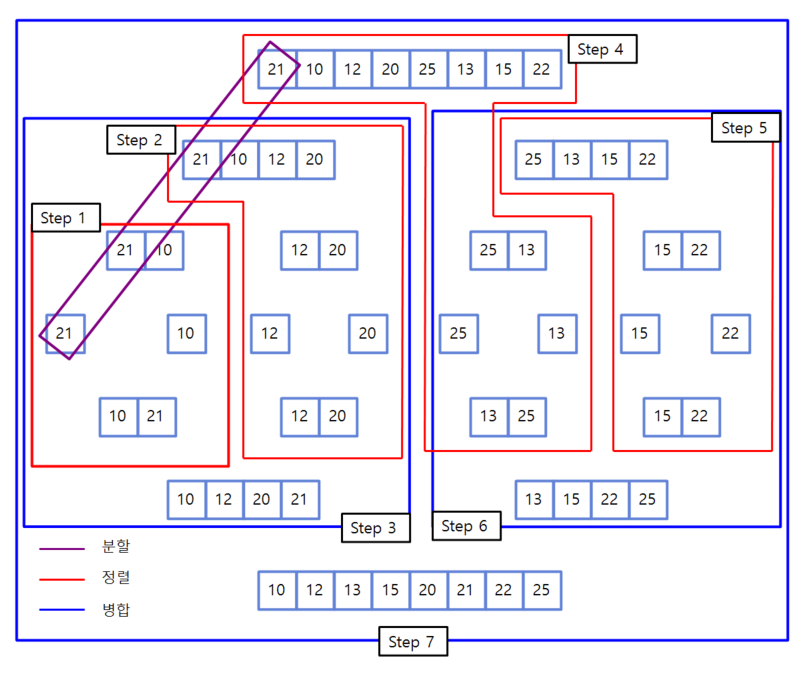
- 배열에 27, 10, 12, 20, 25, 13, 15, 22이 저장되어 있다고 가정하고 자료를 오름차순으로 정렬해 볼까요?
- 전체 과정
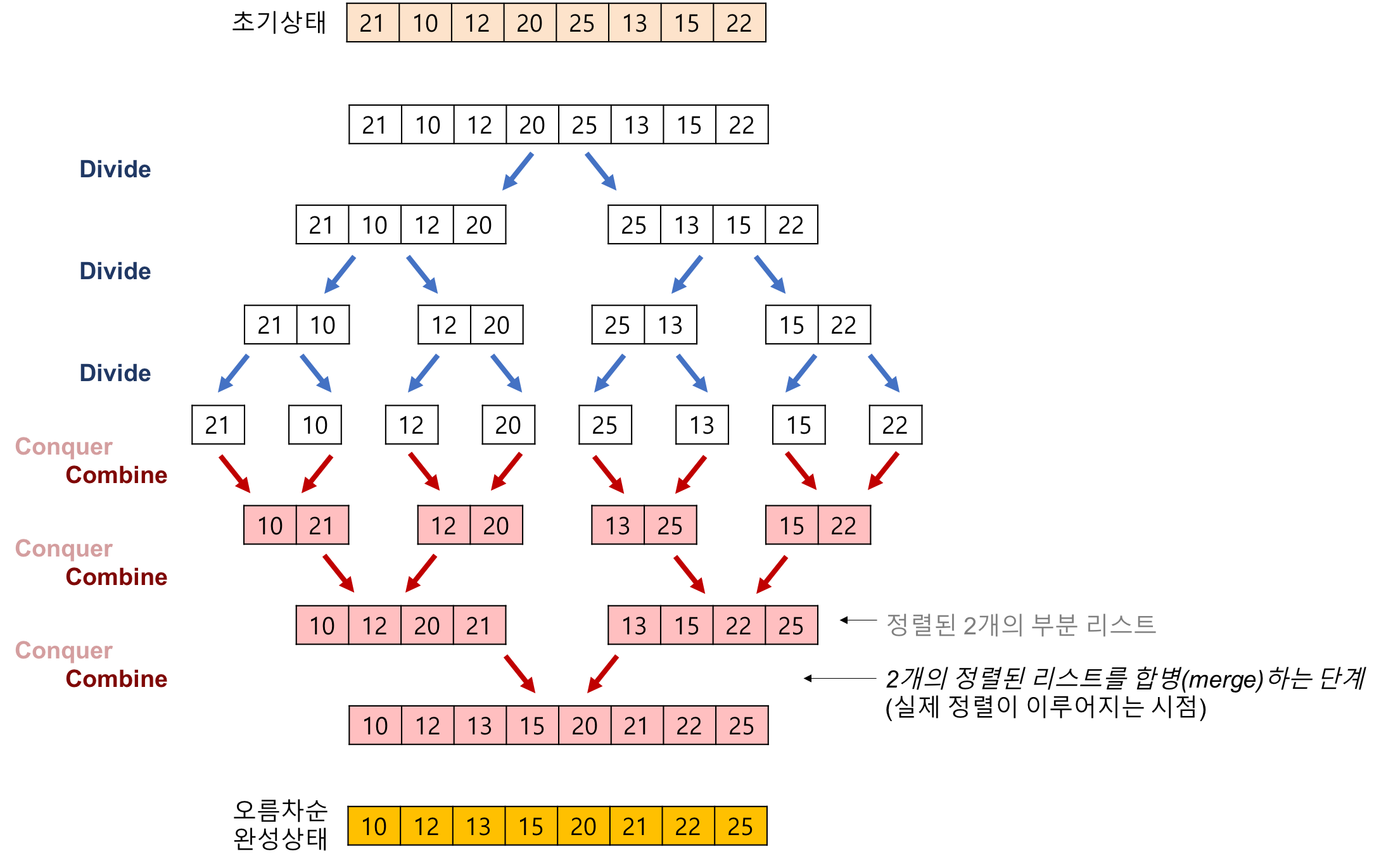
- 병합과정
병합 정렬 과정은 재귀함수에 대한 이해가 반드시 필요합니다.
재귀 함수에 대해 잘 알고 계시다면, 넘기셔도 상관없습니다.
- 재귀란? 어떠한 이벤트에서 자기 자신을 포함하고 다시 자기 자신을 사용하여 정의되는 경우
- 아래는 혼공파 유튜브에서 캡쳐한 재귀함수 코드와 구조입니다. 이해하기에 어렵지 않으니, 꼭 이해하신 뒤 아래의 병합 정렬 과정(그림도 그려놨어요!)와 비교하며 이해해보세요.
def factorial(n: int) -> int:
if n > 0:
return n * factorial(n - 1)
else:
return 1
if __name__ == '__main__':
n = int(input('출력할 팩토리얼값을 입력하세요.:'))
print(f'{n}의 팩토리얼은 {factorial(n)}입니다.')
- 위 그림을 통해 병렬 과정을 이해할테니 꼭 숙지해주세요!
factorial() 함수는 n - 1의 팩토리얼 값을 구하기 위해 다시 자신과 똑같은 factorial() 함수를 호출합니다. 이런 함수의 호출을 재귀호출(recursive call)이라고 합니다.
factorial() 함수와 같이 자신과 똑같은 함수를 호출하는 방식을 직접 재귀라고 합니다. 이와 다르게 a() 함수가 b() 함수를 호출하고 다시 b() 함수가 a() 함수를 호출하는 구조를 간접재귀 구조라고 합니다.
-
재귀 알고리즘의 분석 방법으로는 하향식 분석과 상향식 분석 방법으로 2가지가 있습니다. 재귀 알고리즘은 꼭 분석해보셔야 이해할 수 있으므로 꼭 분석해보시길 권유드립니다.
-
하향식 분석 방법
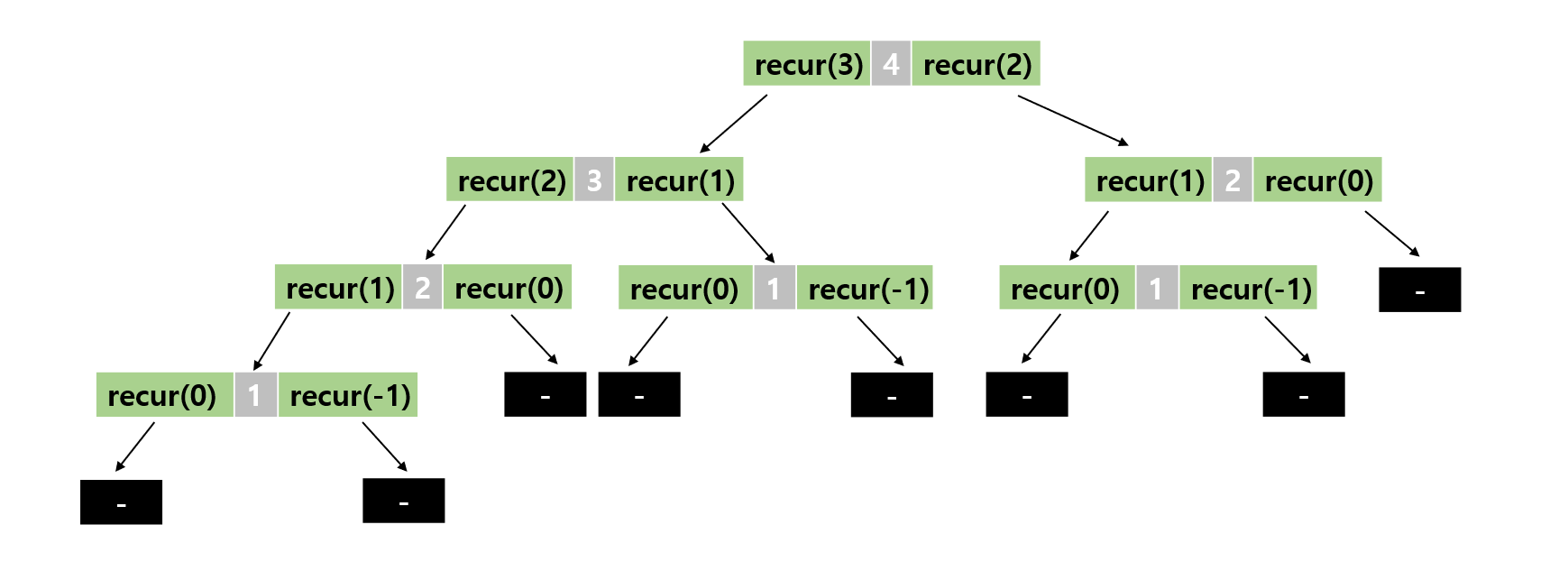
가장 위쪽에 있는 상자는 recur(4)의 실행을 나타냅니다. recur(3)을 실행하면 무엇을 하는지는 왼쪽 아래 화살표를 따라가야 알 수 있고, recur(2)를 실행하면 무엇을 하는지는 오른쪽 아래 화살표를 따라가야 알 수 있습니다.
이 내용을 정리하면 '왼쪽 화살표를 따라 1칸 아래쪽 상자로 이동하고, 다시 원래 호출한 상자로 돌아가면 [-]값을 출력합니다. 이어서 오른쪽 화살표를 따라 1칸 아래쪽 상자로 이동합니다'를 하나의 단계로 생각해야 합니다. 이 단계를 1번 끝내야 비로소 1칸 위쪽 상자로 올라갈 수 있습니다.
이처럼 가장 위쪽에 위치한 상자의 함수 호출부터 시작하여 계단식으로 자세히 조사해 나가는 분석 방법을 하향식 분석이라고 합니다.
- 상향식 분석 방법
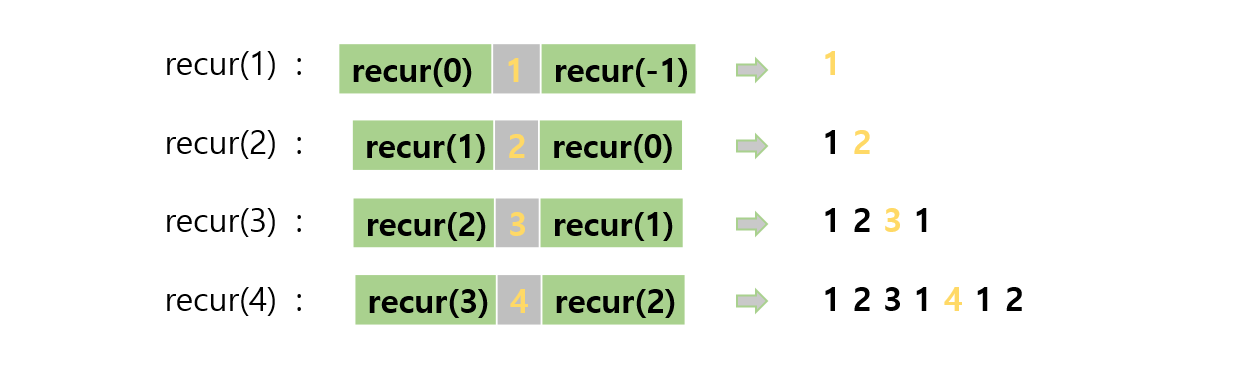
하향식 분석과는 반대로 아래쪽부터 쌓아 올리며 분석하는 방법을 상향식 분석이라고 합니다.
recur() 함수는 n이 양수일 때만 실행하므로 먼저 recur(1)이 어떻게 처리되는지 알아야합니다.
recur(1)의 실행 과정- recur(0)을 실행합니다.
- 1을 출력합니다.
- recur(-1)을 실행합니다.
이런 방식으로 recur() 함수의 실행 과정을 쫓으면 위와 같은 그림으로 표현 가능합니다.
- 이제 병합 정렬 알고리즘의 구현 코드 입력해보고 분석해봅시다.
# 내포 표기 생성으로 리스트 생성
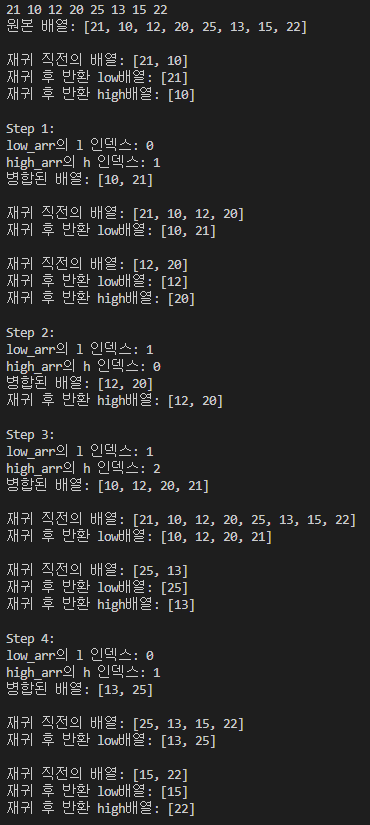
arr = [int(x) for x in input().split()] # 리스트형, [21, 10, 12, 20, 25, 13, 15, 22]
def merge_sort(arr, step_count=[0]):
if len(arr) < 2: # 배열의 길이가 1인 경우
return arr # 정렬된 상태로 판단
mid = len(arr) // 2 # 리스트의 중간 찾기
low_arr = merge_sort(arr[:mid], step_count) # 중간으로 나눈 왼쪽 배열을 재귀적으로 끝까지 분할
print(f"\n재귀 직전의 배열: {arr}")
print(f"재귀 후 반환 low배열: {low_arr}")
high_arr = merge_sort(arr[mid:], step_count) # 나머지 오른쪽 배열도 끝까지(부분 배열의 길이가 1) 분할
print(f"재귀 후 반환 high배열: {high_arr}")
# --- 분할 과정 종료 ---
step_count[0] += 1
current_step = step_count[0]
merged_arr = [] # 정렬한(정복한) 배열을 최종적으로 담는 배열 생성
l = h = 0 # merged 배열에 low와 high의 요소를 추가할 때 참고할 인덱스, 배열의 요소가 1개일 때는 0으로 초기화
print(f"\nStep {current_step}:")
# Step 3부터 h의 요소가 2개이므로 [21, 10] 뒤인 [2]에 추가 가능하다.
while l < len(low_arr) and h < len(high_arr):
if low_arr[l] < high_arr[h]: # 배열의 맨 앞 요소의 대소 비교
merged_arr.append(low_arr[l])
l += 1
else:
merged_arr.append(high_arr[h])
h += 1
print(f"low_arr의 l 인덱스: {l}")
print(f"high_arr의 h 인덱스: {h}")
merged_arr += low_arr[l:]
merged_arr += high_arr[h:]
print(f"병합된 배열: {merged_arr}")
return merged_arr
print(f"원본 배열: {arr}")
result = merge_sort(arr)
print(f"\n최종 정렬 결과: {result}")
-
실행 결과

-
출력 과정 및 결과 도식화(하향식 분석)
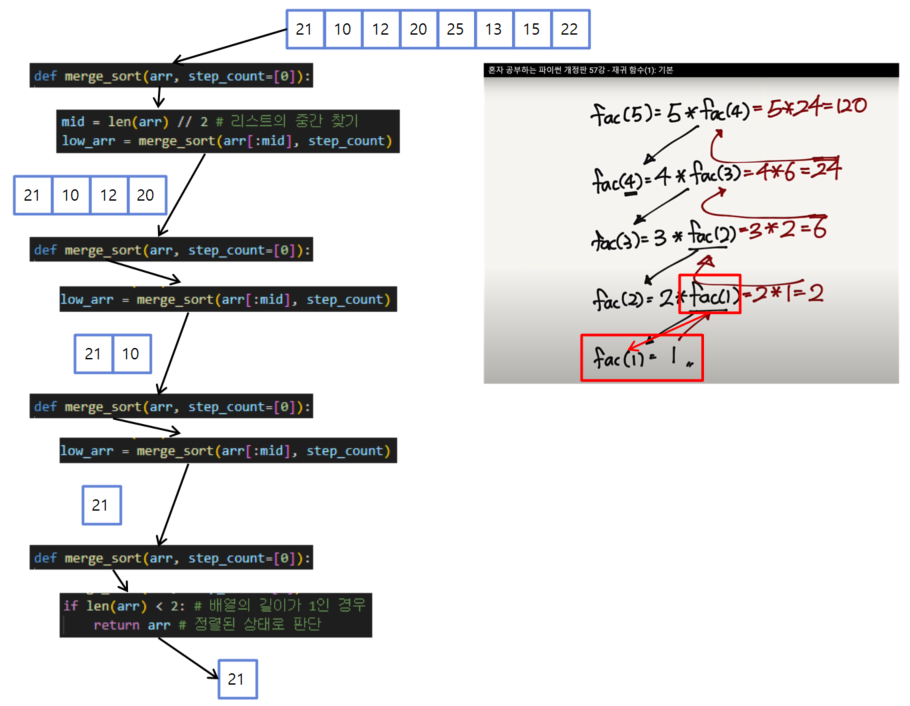
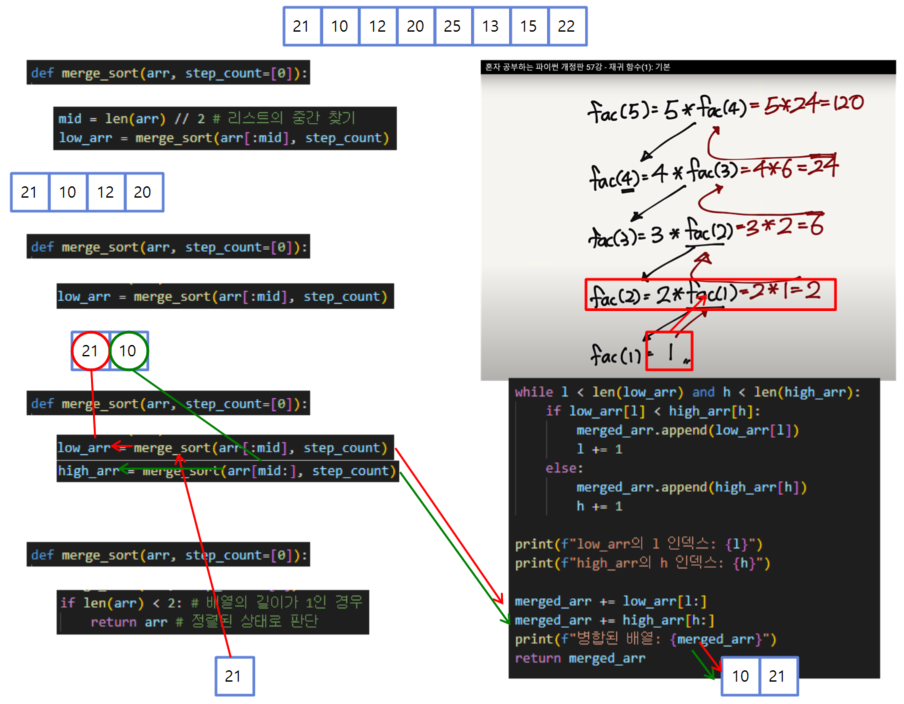
-
위 그림에서 마지막에 merged_arr가 반환되기 전 while문을 통해 정렬됩니다. 4번째 그림에 표시되어 있어요!
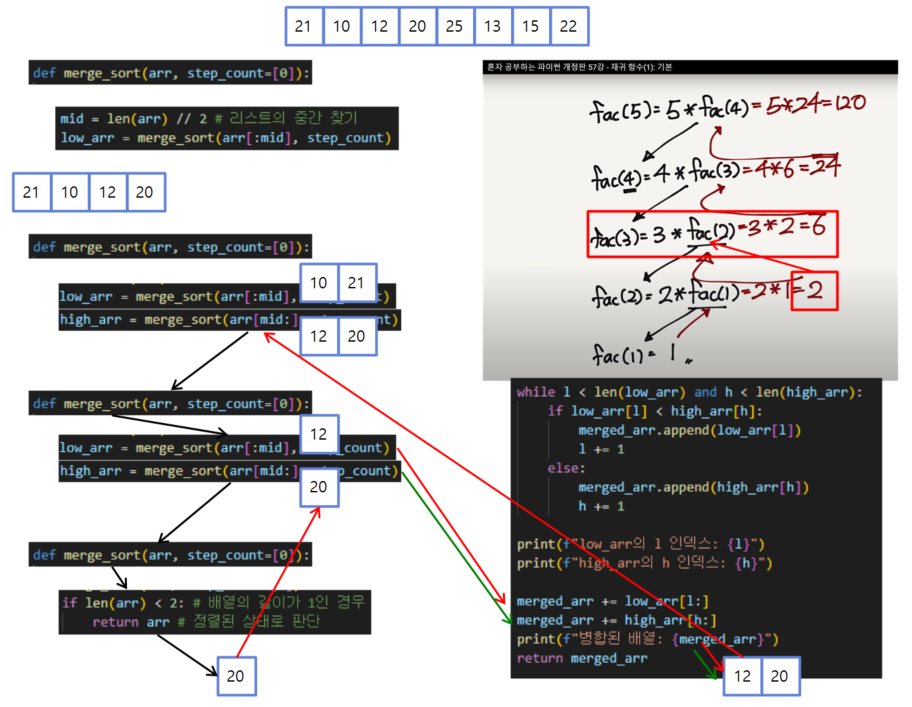
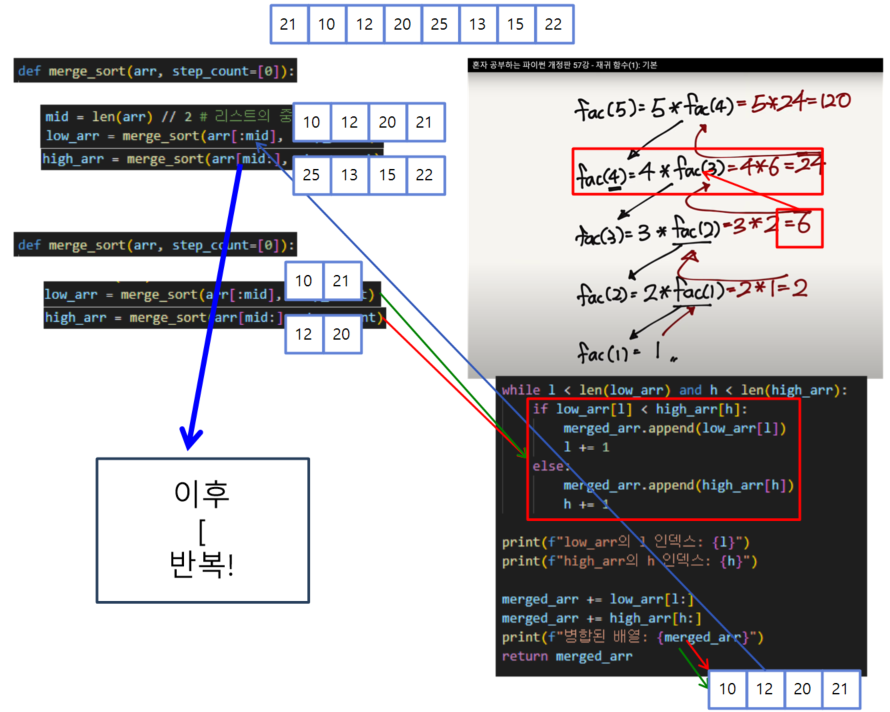
-
정리 도식
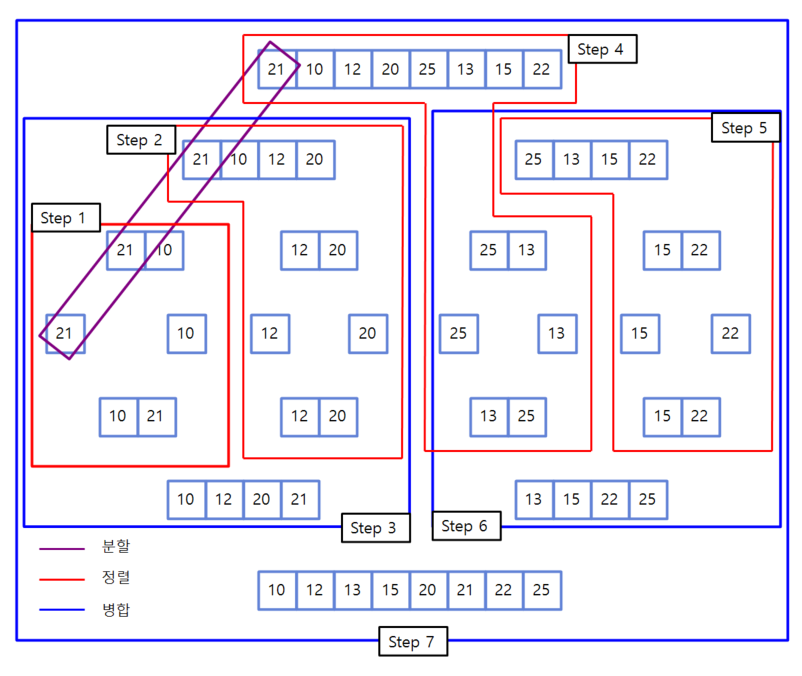
-
위 출력 결과에 Step1~7과 동일합니다! 비교하며 읽어보세요
더 알아볼까요?
-
시간복잡도
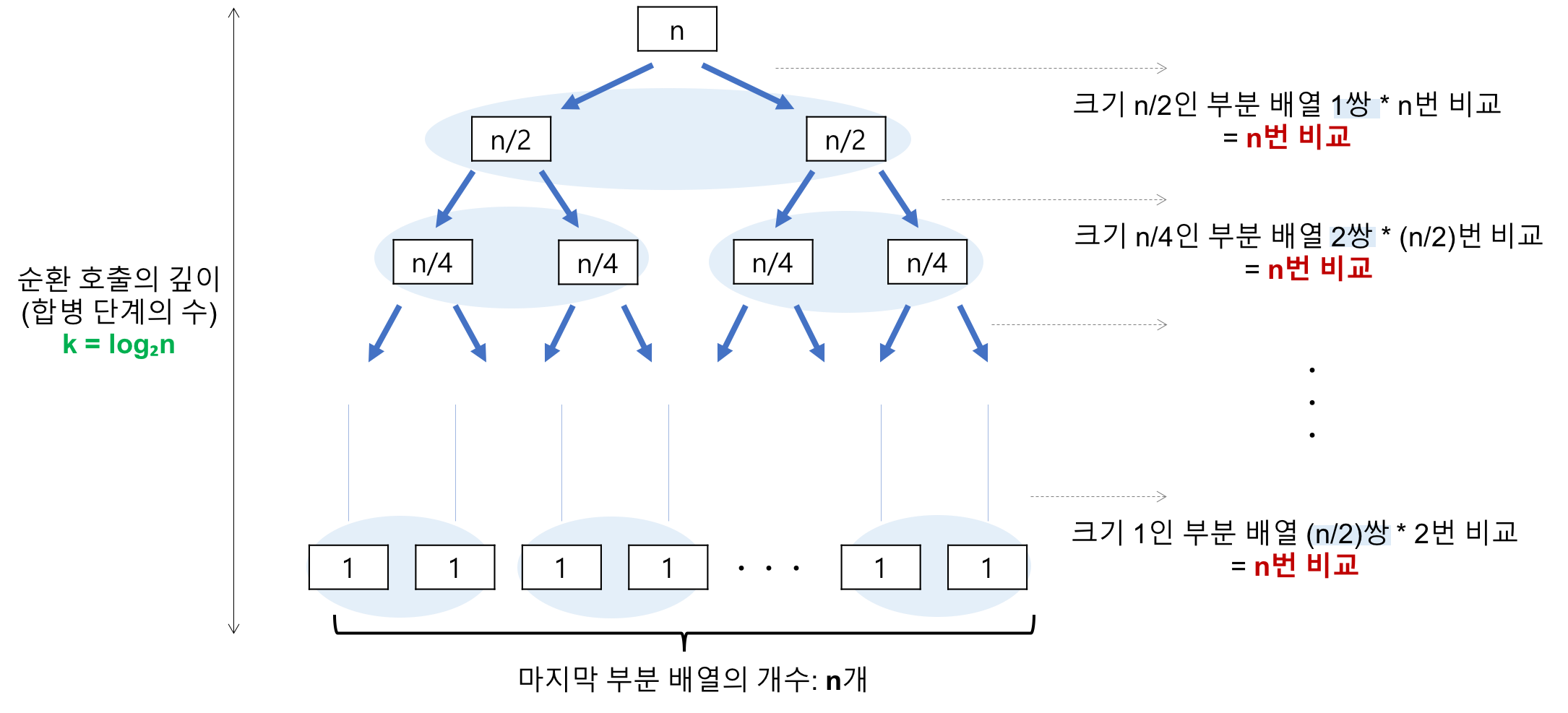
-
분할 단계 : 비교 연산과 이동 연산이 수행되지 않습니다.
-
합병 단계 : n번 비교합니다.
순환 호출의 깊이(합병 단계의 수)는 레코드의 개수 n이 2의 거듭제곱이라고 가정(n=2^k)했을 때, n=2^3의 경우, 2^3 -> 2^2 -> 2^1 -> 2^0 순으로 줄어들어 순환 호출의 깊이가 3임을 알 수 있습니다. 이것을 일반화하면 n=2^k의 경우, k(k=log₂n)임을 알 수 있습니다. k=log₂n -
각 합병 단계의 비교 연산
합병 단계에서 가장 처음의 경우, 크기 1인 부분 배열 2개를 합병하는 데는 최대 2번의 비교 연산이 필요하고 부분 배열의 쌍이 4개이므로 2x4=8번의 비교 연산이 필요합니다. 다음 단계에서는 크기 2인 부분 배열 2개를 합병하는 데 최대 4번의 비교 연산이 필요하고, 부분 배열의 쌍이 2개이므로 4x2=8번의 비교 연산이 필요합니다. 마지막 단계에서는 크기 4인 부분 배열 2개를 합병하는 데는 최대 8번의 비교 연산이 필요하고, 부분 배열의 쌍이 1개이므로 8x1=8번의 비교 연산이 필요합니다. 이것을 일반화하면 하나의 합병 단계에서는 최대 n번의 비교 연산을 수행함을 알 수 있습니다. 순환 호출의 깊이 만큼의 합병 단계 x 각 합병 단계의 비교 연산 = nlog₂n -
이동 횟수
순환 호출의 깊이는(합병 단계의 수) k=log₂n -
각 합병 단계의 이동 연산
임시 배열에 복사했다가 다시 새로운 리스트에 담아야 되므로 이동 연산은 총 부분 배열에 들어 있는 요소의 개수가 n인 경우, 레코드의 이동이 2n번 발생한다. -
순환 호출의 깊이 만큼의 합병 단계 * 각 합병 단계의 이동 연산 = 2nlog₂n
-
결론: T(n) = nlog₂n(비교) + 2nlog₂n(이동) = 3nlog₂n = O(nlog₂n)
특징
- 알고리즘을 큰 그림에서 보면 분할(split) 단계와 방합(merge) 단계로 나눌 수 있으며, 단순히 중간 인덱스를 찾아야 하는 분할 비용보다 모든 값들을 비교해야하는 병합 비용이 큽니다.
- 예제에서 보이는 것과 같이 8 -> 4 -> 2 -> 1 식으로 전반적인 반복의 수는 점점 절반으로 줄어들 기 때문에 O(logN) 시간이 필요하며, 각 패스에서 병합할 때 모든 값들을 비교해야 하므로 O(N) 시간이 소모됩니다. 따라서 총 시간 복잡도는 O(NlogN) 입니다.
- 두 개의 배열을 병합할 때 병합 결과를 담아 놓을 배열이 추가로 필요합니다. 따라서 공간 복잡도는 O(N) 입니다.
- 다른 정렬 알고리즘과 달리 인접한 값들 간에 상호 자리 교대(swap)이 일어나지 않습니다.
출처
https://www.youtube.com/watch?v=IubMUA1oz-o
https://gmlwjd9405.github.io/2018/05/08/algorithm-merge-sort.html
https://www.daleseo.com/sort-merge/
