오늘 공유드릴 논문은
Nearest Neighbor Guidance for Out-of-distribution Detection (OoDD)
이라는 논문으로, 2023 ICCV에 pulbish된 논문입니다. (혹시 틀린 내용 있다면 댓글 부탁드립니다 ㅎㅎ..)
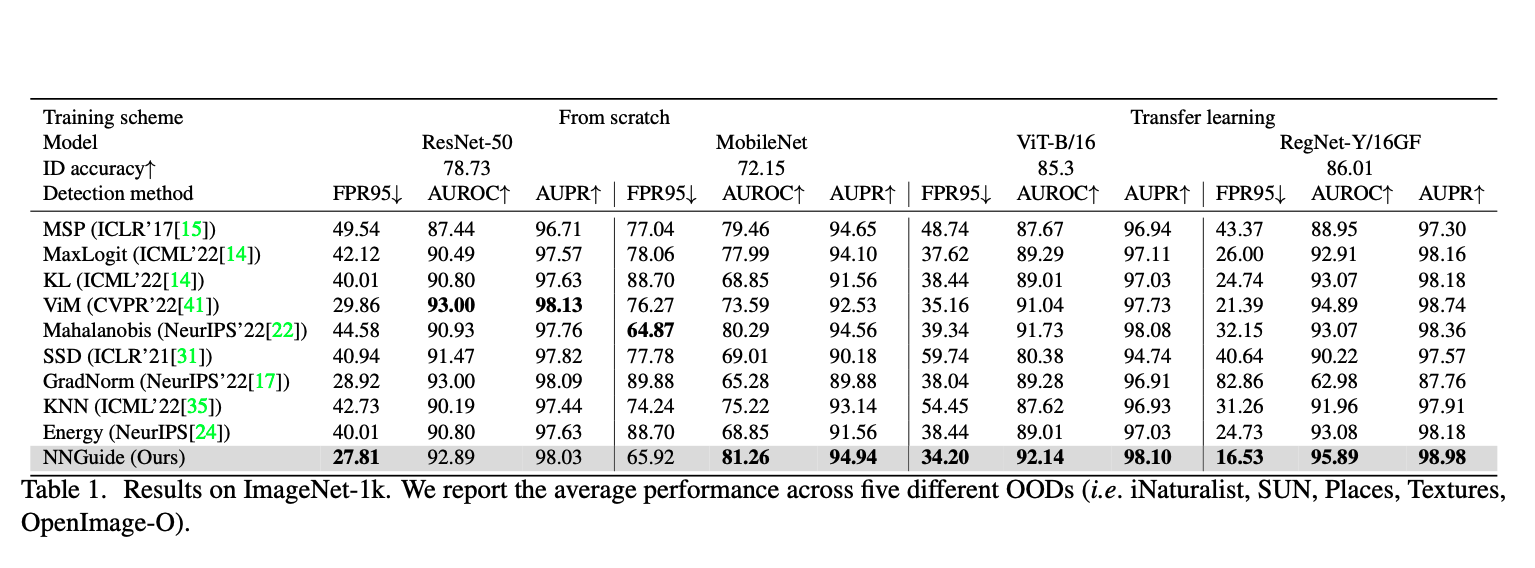
논문의 주된 내용은 Classifier-based score 방식을 사용한 OoDD 방법론의 문제점중 하나인 in-distribution에서 멀리 벗어난 데이터에 대해 overconfidence를 갖는 문제점을 해결할 수 있는 방법을 제안하는 논문입니다.
Out-of-distribution Detection은 일반적으로 Classifier-based score를 사용하여 task를 수행합니다. Classifier-based score는 예를들어, 모델을 ID sample에 대해 훈련킨다면 test단계에서 입력으로 ID가 들어왔을 때 상대적으로 OOD보다 높은 score를 가질 것임을 기대하고 수행하는 방식입니다. 이런 방법은 ID data의 class-dependent한 정보를 잘 활용하기 때문에 fine-grained한 detection capability가 뛰어납니다. 하지만 far OOD sample들에 대해 overconfidence를 가지게 되는 문제도 함께 존재하는데요.
이와 반면에 distance-based 방법론 (KNN, Mahalanobis distance)들은 ID data와의 distance를 기반으로 OODD를 진행하기 때문에, 상대적으로 fine-grained detection capability가 부족하다는 단점이 있지만, ID, OoD 사이의 거리가 멀어질수록 잘 구분할 수 있는 장점이 있습니다.
위 두 효과를 첫번째 그림(toy experimetns)을 통해 쉽게 확인해볼 수 있습니다.
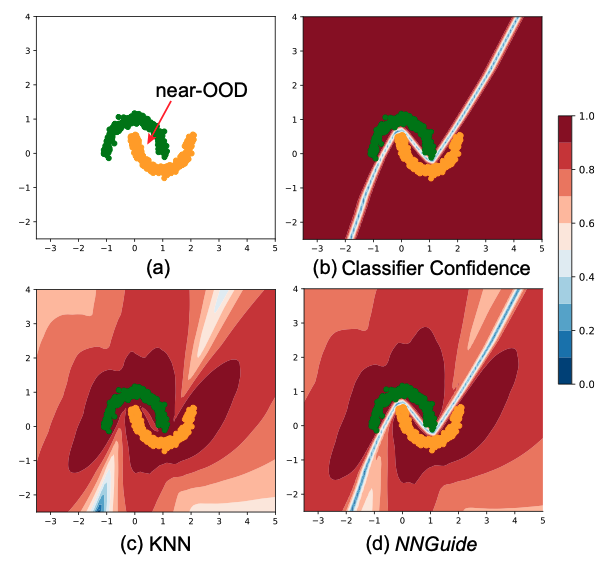
Classifier confidence같은 경우, ID들 사이의 경계에서 낮은 confidence를 가질 뿐 나머지 영역에 대해 높은 confidence를 유지하고 있는 것을 확인할 수 있습니다. 반면에 KNN의 경우 멀리 있는 데이터에 대해 낮은 confidence를 가지고 fine-grained한 영역에서 구분이 쉽지 않아보입니다.
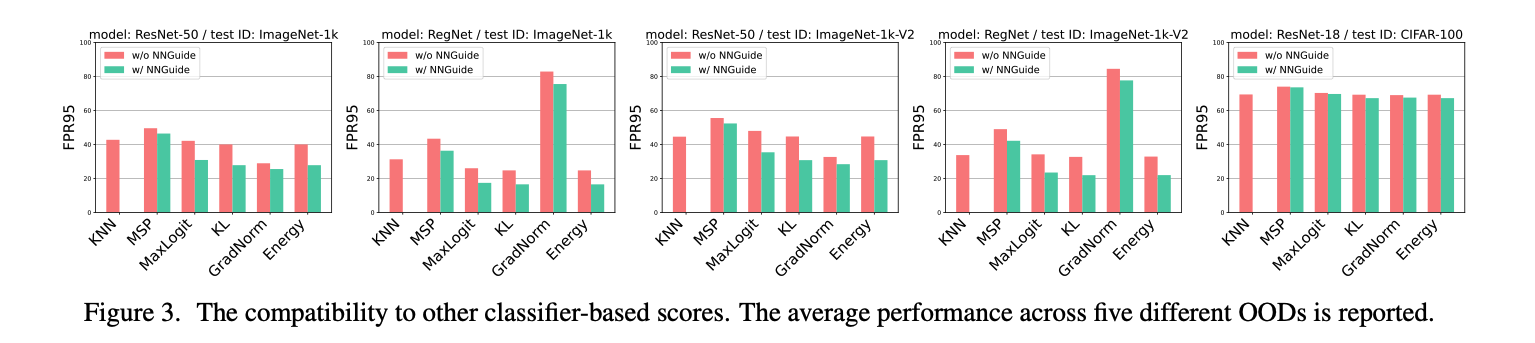
해당 논문은 fine-grained detection capability는 유지하면서 far-OOD region에 대해 잘 detection할 수 있는 Nearest Neighbor Guidance (NNGuidance) 방법론을 제안합니다.

해당 방법론은 test sample의 feature와 randomly selected된 training set (ID bank set)에서의 feature 사이의 cosine similarity에 confidence-scaling을 해준 값들을 역순(큰 -> 작은)으로 나열한 뒤에 K개를 선택하고 그것의 평균으로 Guidance를 진행합니다. 이를 통해 classifier based score방식에서 fine-grained한 영역의 detection 성능을 유지(만약 test sample이 ID에 가깝다면, guidance는 base confidence를 upscale하기 때문에 높은 base score, 상대적으로 class decision boundary같은 low-confidence 영역에 대해서는 down scaling할 것이기 때문에, fine-grained한 영역에서 OOD일 경우 구분을 잘 할 것임)하면서, ID bask set과 멀리 있는 test sample에 대해서는 guided score가 낮아지기 때문에 far-OoD region에 대해 overconfidence issue가 사라질 것입니다.