오늘 공유드릴 논문은
Does CLIP’s generalization performance mainly stem from high train test similarity ?
라는 논문으로 NeurIPS 2023 Workshop에서 poster로 발표된 논문입니다.
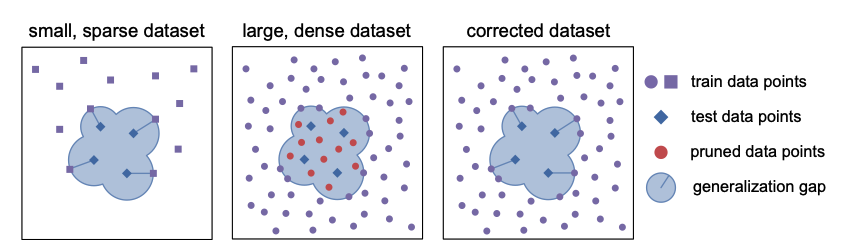
해당 논문은 CLIP과 같은 Foundation model이 지니고 있는 zero-shot and few-shot Out-of-distribution performance가 large-scale dataset와 VLM의 특징에 의한 것이 아니라, LAION이라는 web-scale dataset이 OOD benchmark들과 비슷한 샘플들을 많이 포함했기 때문이 아닐까? 라는 의문을 제기하는 논문입니다.
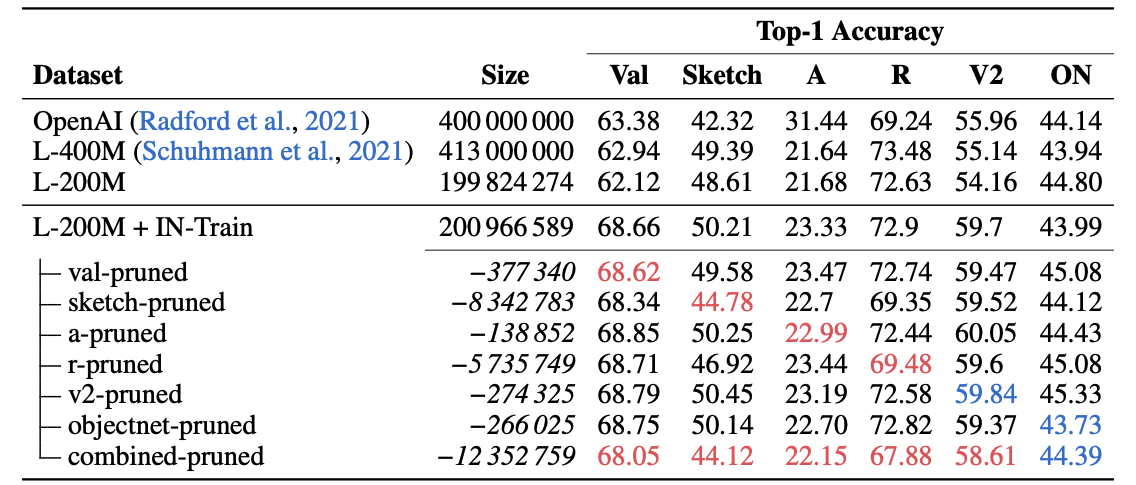
이러한 가설을 검증하기 위해, 논문에서 similarity gap을 사용하여 LAION에서 OOD Benchmark (ImageNet-Sketch, ImageNet-R, 등등)와 비슷한 similarity를 가지는 데이터들을 제거한 뒤 재훈련을 진행해보았습니다. 결과적으로, overall 성능은 여전히 높지만 몇몇 벤치마크 데이터들에서 성능이 감소했습니다. 이를 통해 high train-test similarity를 지닌 Training datatset으로 CLIP의 성능을 설명하기에는 충분치 못하다라는 주장을 합니다.
논문의 주장을 위해 ImageNet-Train 과 LAION-200M을 훈련 데이터로, test로는 ImageNet의 OOD Benchmark를 사용하여 실험을 진행.
- LAION에서 OOD Benchmark와 비슷한 이미지를 제거
a. similarity gap이라는 nearest neighbor distance를 사용하여 데이터를 평가하여 제거
b. ImageNet-Train과 OOD Benchmark 사이의 similarity gap보다 작은 distance를 가지는 모든 LAION 내의 데이터를 제거함 - LAION에서 testset과 비슷한 이미지를 제거한뒤 retrain을 진행
a. val-pruned
b. sketch-pruned
c. a-pruned
d. r-pruned
e. v2-pruned
f. objectnet-pruned
g. combined-pruned
놀랍게도, similarity gap을 사용하여 제거한 데이터셋에 대해 성능이 감소하는 것을 확인할 수 있었습니다. 특히, Sketch와 R과의 관계에서 재밌는 점은, 두 벤치마크가 몇몇 스타일에 대해 비슷한 데이터들을 포함하고 있기 때문에 Sketch와 R pruned dataset으로 각각 훈련했을 때 성능이 두 경우 모두 하락하는 것을 확인할 수 있습니다. 따라서, train-test similartiy로 인해 OOD benchmark성능이 좋은 것이 아닌가 ? 라는 의문에 어느정도는 그럴 수 있음을 보여주는 것으로 보입니다.
그럼에도, pruned sketch만을 중점적으로 보았을 때, ImageNet만 가지고 훈련했을 때 기대할 수 있는 ImageNet-Sketch의 성능(14%)보다 30퍼센트가량(44.78%) 증가하는 것으로 보아, CLIP의 성능이 high train-test similarity에만 존재한다고는 말할 수 없고 dataset scale과 다양성으로 인해 generalization feature를 획득한다는 것을 알 수 있다고 말합니다.