오늘 공유드릴 논문은
https://arxiv.org/abs/2304.08485
Visual Instruction Tuning
으로, LLAVA : Large Language And Visual Assistant 로 잘알려진 논문이고, NeurIPS 2023에서 Oral paper로 선정된 논문입니다.
논문의 저자는 AI의 핵심 기능 중 하나인 general-purpose assistant를 multi-modal로 확장하기 위해 다음과 같은 방법을 사용했습니다. (여기서 general-purpose assistant란, GPT처럼 일상 생활에서 보조역할을 해주는 기능을 해주는 model)
- Multimodal instruction-following data
a. GPT-4/ChatGPT를 사용해서 이미지-텍스트 데이터 쌍을 적절한 instruction-following 형태로 변환
COCO dataset을 이용해서 instruction-following data를 만들었음. 이 때, 이미지를 입력으로 사용하지 않고, 이미지와 관련된 캡션과 Bounding box만 사용해서 질문과 대화셋을 만들어냄
b. 이를 통해 세가지 타입에 대한 instruction-following data를 생성
- Conversation : 사진과 질문, 답변의 형태로 디자인
- Detailed description : 이미지에 대한 구체적인 설명의 형태로 디자인
- Complex reasoning : 심층 추론 질문을 추가로 생성.
c. 총 158K data를 생성했고, 공개함.


- Large multimodal model
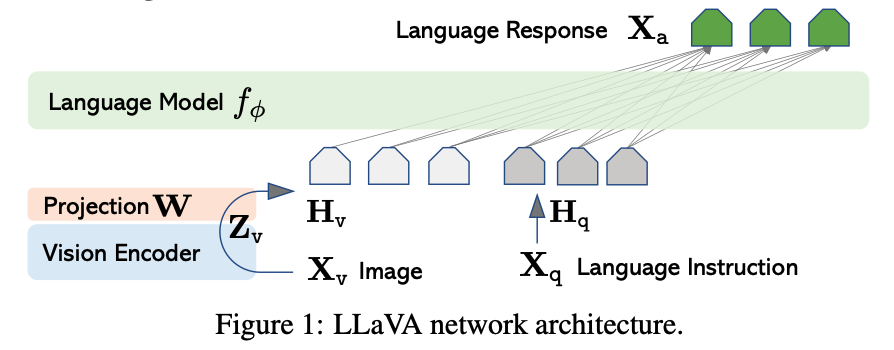
a. CLIP의 visual Encoder와 Vicuna의 language decoder를 연결해서, 1번에서 생성한 데이터를 end-to-end로 fine-tuning하는 LMM(Large Multimodal Model)을 만듦
b. general-purpose instruction-following visual agent를 만들 수 있는 실용적인 팁들을 제공
- Pre-training for Feature Alignment
- projection layer만 학습
- 여기서, imgae feature H_v가 pre-trained LLM word embedding에 align됨.
- Fine-tuning End-to-End
- Visual encoder만 froze, LLM, projection layer 학습
- Multi-modal Instruction-following benchmark
a. 두가지 챌린징한 벤치마크인 LLaVA-Bench를 제공함
b. 위를 통해 future research에 도움을 줌
- Open-source 제공
- generated multimodal instruction data
codebase
- model checkpoint
- visual chat demo