Chapter 1 Data and Statistics
Categorical and Quantitaitve Data
- 데이터는 범주형(categorical) 또는 양적(quantitative) 데이터로 분류
- 적절한 통계 분석은 변수의 데이터가 범주형(categorical)인지 양적(quantitative)인지에 따라 달라짐
- 일반적으로 데이터가 정량적(quantitative)일 때 통계 분석을 위한 대안이 더 많음
Categorical Data
측정하는 것이 카테고리로 묶일 때 사용
- 각 요소의 속성(attribute)을 식별하는 데 사용되는 레이블 또는 이름
- 질적 데이터(qualitative data)라고도 함
- 측정의 공칭(nominal) 또는 순서(ordinal) 척도 사용
- 숫자(numeric) 또는 비숫자(nonnumeric)일 수 있음
- 적절한 통계 분석은 다소 제한적
Quantitative Data
숫자로 측정될 때 사용
- 정량적 데이터는 다음과 같은 수 또는 양을 나타냄:
- 이산형(discrete), 몇 개인지 측정하는 경우
- 연속형(continuous), 얼마나 측정하는지 측정하는 경우
- 정량적 데이터는 항상 숫자(numeric)
- 일반적인 산술 연산은 정량적 데이터에 의미
Scales of measurement
- 척도(Scale)는 데이터에 포함된 정보의 양을 결정
- 척도는 가장 적절한 데이터 요약(data summarization) 및 통계 분석(statistical analyses)을 나타냄
명목 척도(Nominal scale)
- 데이터는 요소의 속성(attribute)을 식별하기 위해 사용되는 레이블 또는 이름
- 비숫자적인 레이블(nonnumeric label) 또는 숫자 코드(numeric code)를 사용
- 예시
- 대학의 학생들은 Business, Humanities, Education 등과 같은 비숫자적인 레이블을 사용하여 등록된 학교로 분류
서열 척도(Ordinal scale)
- 데이터는 명목 데이터(nonminal data)의 특성을 가지고 있으며 데이터의 순서(order) 또는 순위(rank)가 의미가 존재
- 비숫자적 레이블(nonnumeric label) 또는 숫자 코드(numeric code)를 사용 가능
- 예시
- 대학생들은 학년에 따라 분류될 수 있으며, 이 경우 Freshman, Sophomore, Junior, Senior와 같은 비숫자적 레이블을 사용
- Excellent(3), Good(2) 및 Poor(1)와 같은 숫자 코드를 사용하여 평가 가능
등간 척도(Interval scale)
- 데이터는 순서형 데이터(ordinal data)의 속성을 가지며 관측치 간의 간격(interval between observations)이 고정된 단위(fixed unit)로 표현
- 간격 데이터는 항상 숫자로 이루어짐
- 예시
- 멜리사는 SAT 점수가 1885이고 케빈은 SAT 점수가 1780입니다.
- 멜리사는 케빈보다 105점 높은 점수를 받았습니다.
비율 척도(Ratio scale)
- 데이터는 간격 데이터(interval data)의 모든 특성을 갖고 있으며, 두 값의 비율이 의미가 있는 경우
- 거리, 높이, 무게, 시간 등의 변수는 비율 척도(ratio scale)를 사용
- 예시
- 멜리사는 대학에서 36 학점을 이수했으며, 케빈은 72 학점을 이수, 케빈은 멜리사의 학점 수의 두 배
- 자동차의 가격 비율: $30,000/$15,000=2
Types of data(variable)
-
variable types
- 범주형 변수(Categorical variable)
- 명목 척도(Nominal scale)
- 서열 척도(Ordinal scale
- 수치형 변수(Numerical variable)
- 간격 척도(Interval scale)
- 비율 척도(Ratio scale)
- 범주형 변수(Categorical variable)
-
데이터의 측정 수준에 따라 척도(scales of measurement)가 다르게 구분되는데,
측정 수준이 높아질수록(measurement level becomes more detailed)
더 많은 정보를 제공(the amount of information increases)
범주형 변수(Categorical variable)
- 양적 의미가 없으며 두 개 이상의 범주로 나누어 분류를 나타내기 위해 사용
- 예시
- 대학생: 1, 2, 3, 4 학년을 새내기, 2학년, 3학년, 4학년으로 분류
- 신용 등급: A, AA, AAA, B, BB, BBB 등
- 자동차 제조사: 현대, 기아, 대우, 삼성 등
- 연산이 적용될 수 없음
- 질적 변수
수치 변수(Numerical variable)
- 양적 의미가 있는 변수
- 대부분의 금융 및 경제 변수(환율, 이자율, 주가 등)가 이에 해당
- 종류:
이산형 변수(Discrete): 취할 수 있는 값의 개수를 세는 변수 (예: 가구 당 소지한 휴대전화 대수)
연속형 변수(Continuous): 가능한 값이 연속적(continuous)이며 무한한 범위(uncountable)를 가지는 변수 (예: 시간, 키, 체중)
대부분의 금융 및 경제 변수는 연속형 변수로 처리
- 종류:
한 눈에 보는 Data Type들
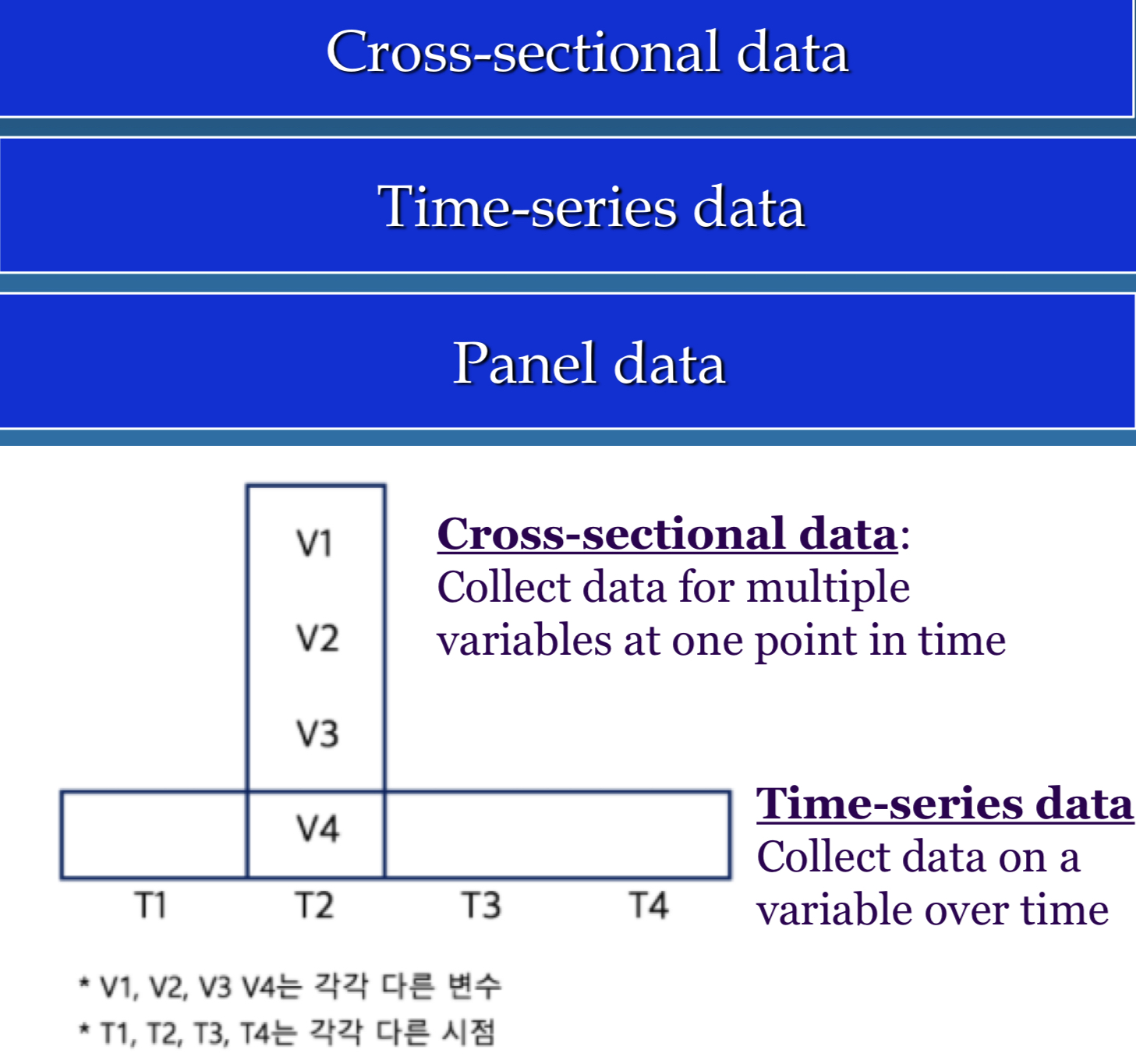
- Panel data
- 여러 개체를 시간에 따라 관찰하여 얻은 데이터
- 예시
2000-2021 기간 동안 KOSDAQ 등록 기업의 연도별 종가와 재무제표 변수 값 등
한국노동패널조사(노동연구원): 1998-2021 동안 경제 및 사회활동에 대해 1년에 한 번씩 5,000 가구 및 가구 구성원을 조사한 데이터 - 종단 자료(cross sectional data)와 차이
학생들의 성별, 나이, 학과 등의 정보를 한 시점에서 측정한 데이터는 종단 자료에 해당합니다. 반면에, 같은 학생들의 성적, 출석률 등을 여러 학기에 걸쳐 측정한 데이터는 panel data에 해당

Why not change the code?