
📌 분류(Classification)와 군집화(Clustering) 정리
1. 분류 vs 군집화
-
분류(Classification)
→ 소속 집단의 정보를 이미 알고 있는 상태에서 데이터를 분류하는 방법 -
군집화(Clustering)
→ 소속 집단의 정보가 없는 상태에서 비슷한 집단으로 묶는 비지도 학습
2. k-NN 알고리즘 (k-Nearest Neighbor)

- 가장 간단한 분류 알고리즘
- 새로운 데이터의 클래스를 정할 때 가장 가까운 k개의 이웃을 찾아 다수결로 결정
- 장점: 단순하고 직관적, 학습 과정이 불필요
- 단점: 메모리와 계산량이 많음, k 값에 따라 성능 차이 발생
📌 예제
- 개 품종 분류 (닥스훈트 vs 사모예드)
- 붓꽃(Iris) 데이터셋: 꽃받침/꽃잎 길이와 너비를 기준으로 종 분류
- k=3일 때 약 95.6% 정확도
✨ 붓꽃(Iris) 데이터셋 분류
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 훈련/테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# k-NN 모델 학습
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
# 예측 및 정확도
y_pred = knn.predict(X_test)
print("정확도:", accuracy_score(y_test, y_pred))3. 성능 평가 지표
머신러닝 모델은 단순히 정확도(Accuracy) 만으로 평가하면 위험.
데이터가 불균형하면 정밀도(Precision), 재현율(Recall), F1 Score 같이 봐야 함.
-
정확도 (Accuracy)
전체 중에서 맞춘 비율 -
정밀도 (Precision)
양성으로 분류된 것 중 실제 양성인 비율 -
재현율 (Recall)
실제 양성 데이터 중 양성으로 맞춘 비율 -
F1 Score
정밀도와 재현율의 조화 평균
⚠️ 표집 편향(Sampling Bias):
데이터가 특정 클래스에 치우쳐 있으면 성능 왜곡 발생
✨ 혼동행렬 + 정밀도/재현율 계산
from sklearn.metrics import confusion_matrix, classification_report
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))앙상블 학습 (Ensemble)
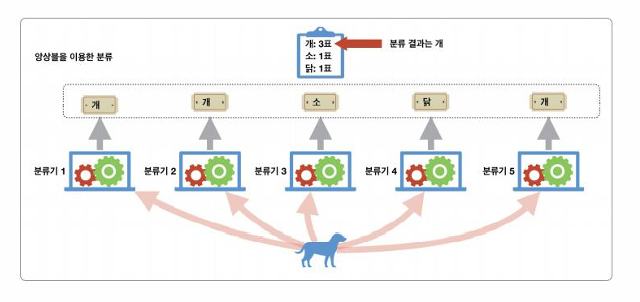
- 여러 개의 분류기를 결합해 더 나은 성능을 내는 기법
- 다양성(Diversity) 확보가 중요 (동질한 모델보다 다른 성격의 모델 조합이 효과적)
- 방법:
- 배깅(Bagging): 데이터 복원 추출
- 페이스팅(Pasting): 데이터 비복원 추출
- 부스팅(Boosting): 이전 모델이 틀린 데이터에 더 집중 (AdaBoost 등)
✨ 랜덤포레스트 예제
from sklearn.cluster import KMeans
import pandas as pd
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
kmeans = KMeans(n_clusters=3, random_state=42)
iris_df['cluster'] = kmeans.fit_predict(iris.data)
print(iris_df.head())5. 군집화 (Clustering)
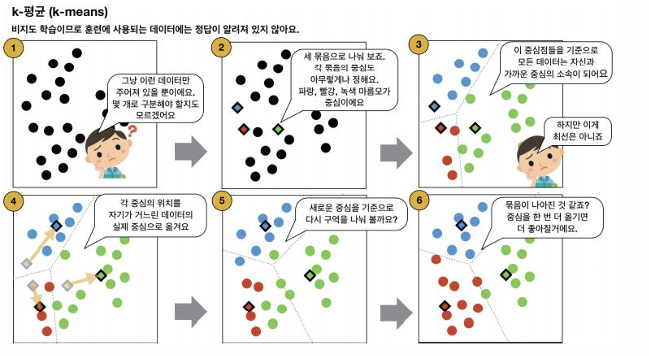
- 레이블이 없는 데이터를 그룹화하는 비지도 학습
- 대표 알고리즘: k-평균(k-means)
- 단순하고 직관적, 성능이 우수
- 단점: 클러스터 개수 k를 사전에 정해야 함
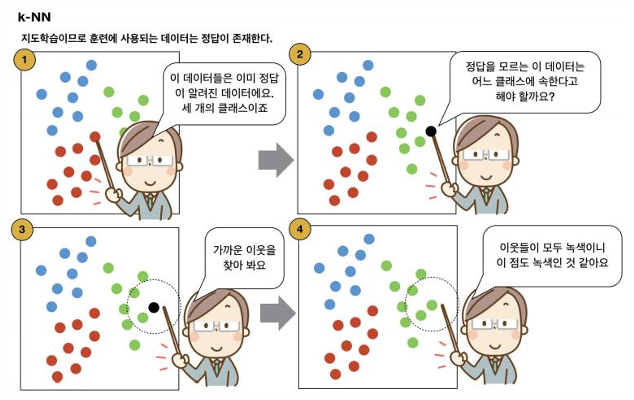
📌 k-NN vs k-means
- k-NN: 지도 학습, 레이블 있음
- k-means: 비지도 학습, 레이블 없음
📌 예시 코드 (k-means 군집화)
from sklearn.cluster import KMeans
import pandas as pd
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
kmeans = KMeans(n_clusters=3, random_state=42)
iris_df['cluster'] = kmeans.fit_predict(iris.data)
print(iris_df.head())6. 핵심 요약
- 분류: 레이블 있음 → k-NN, SVM, Decision Tree 등
- 군집화: 레이블 없음 → k-means, DBSCAN 등
- 성능 지표: Accuracy, Precision, Recall, F1 Score
- 앙상블: Bagging, Boosting으로 성능 향상
- k-NN은 단순하지만 직관적, k-means는 군집화의 대표 알고리즘
