
Python 기초 문법 정리
1. 실수 연산 주의
파이썬을 비롯한 대부분의 프로그래밍 언어는 내부적으로 숫자를 2진수(바이너리) 형태로 변환하여 계산합니다.
이 때문에 부동소수점(floating-point) 계산 시 오차가 발생할 수 있으므로, 정밀도가 중요한 경우는 decimal 모듈을 사용하는 것이 좋습니다.

2. import 문
import는 외부 모듈이나 함수를 현재 작업 중인 스크립트의 메모리에 로드해주는 역할을 합니다.
예를 들어 다음과 같이 작성하면 math 모듈의 모든 함수를 가져올 수 있습니다:
from math import *
import 뒤에 오는 모듈 또는 함수 이름이 name table에 등록됩니다.
함수를 사용할 때는 name table에 등록된 이름을 통해 접근해야 합니다.
3. 연산자 우선순위와 괄호 사용
코드를 작성할 때 연산자 우선순위를 정확히 기억하기보다는 괄호를 적절히 사용하는 편이 가독성 측면에서 바람직합니다.
4. 삼중 따옴표(""") 문자열
파이썬의 삼중 따옴표(""")는 여러 줄 문자열을 쉽게 표현할 수 있어 주석처럼도 자주 사용됩니다.
"""
342342 432432423432 23432432432
""" 이렇게 작성하면 문자열 안에 줄바꿈과 공백을 그대로 유지할 수 있습니다.
5. 문자열 인덱스
파이썬에서 문자열은 각각의 문자를 인덱스로 접근할 수 있습니다. 인덱스는 0부터 시작하며, 음수 인덱스도 지원합니다.
s = "Python"
print(s[0]) # 'P'
print(s[-1]) # 'n' (마지막 문자)

s[-1]은 문자열 s의 마지막 문자를 의미합니다.
s[len(s) - 1]과 동일하지만, -1을 더 자주 사용합니다.
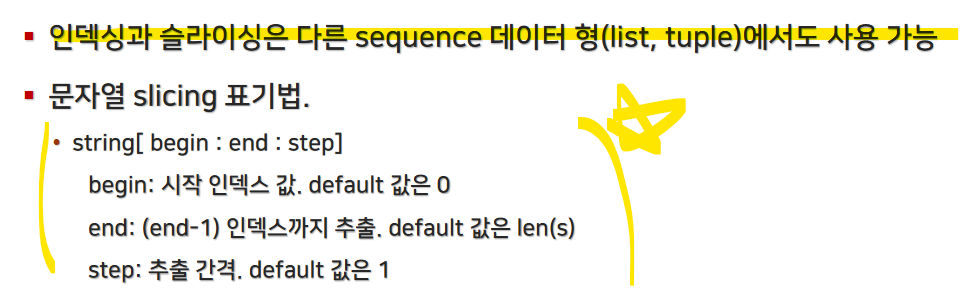
6. 문자열 슬라이싱
문자열에서 특정 범위를 추출할 때는 [start:end:step] 슬라이싱 문법을 사용합니다.
s = "Hello"
print(s[1:4]) # 'ell'
print(s[:3]) # 'Hel'
print(s[2:]) # 'llo'start(시작) 인덱스를 생략하면 문자열의 처음부터 시작합니다.
end(끝) 인덱스를 생략하면 문자열의 끝까지 추출합니다.
step을 생략하면 기본값은 1입니다.
또한 '.' 같은 문장 부호도 문자열의 일부로 취급하므로, 문자열 길이 계산 시 주의해야 합니다.
예를 들어 "Python."은 '.'을 포함하므로 길이가 7입니다.

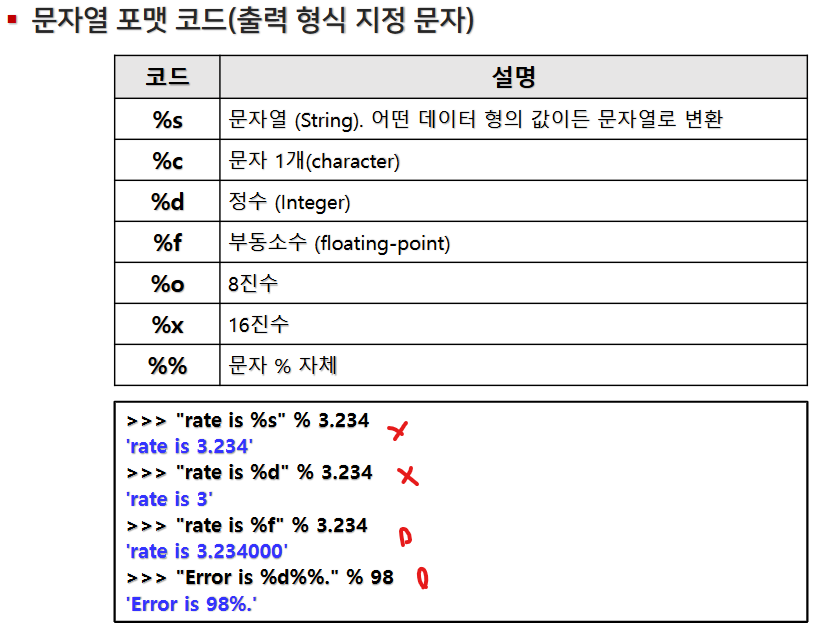
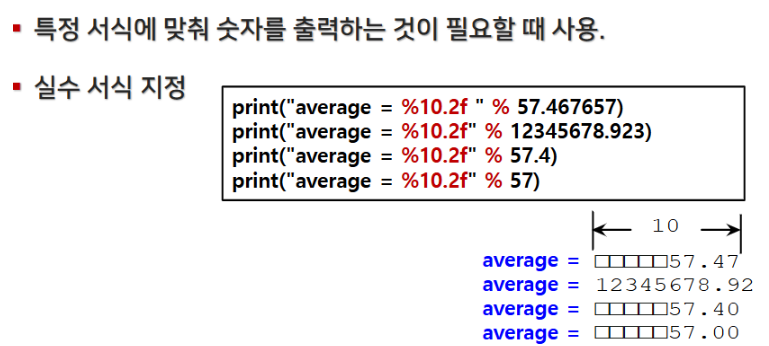
7. 문자열 포매팅(str.format())
문자열 포매팅은 원하는 위치에 변수를 삽입해 출력하는 방법입니다.
예를 들어:
name = "Alice"
score = 90
print("Hello, {}. Your score is {}.".format(name, score))중괄호 {} 위치에 format()의 인자가 순서대로 대입됩니다.
위치 인덱스를 사용해 명시적으로 순서를 지정할 수도 있습니다:
print("Hello, {1}. Your score is {0}.".format(score, name))
.format() 함수 사용법들

8. 문자열 메서드 – split()
문자열을 일정 기준으로 나눌 때는 split()을 사용합니다.
text = "Hello World"
words = text.split() # 기본적으로 공백 기준으로 분할
print(words) # ['Hello', 'World']매개변수를 지정하지 않으면 공백을 기준으로 문자열을 분할합니다.
예: text.split(',') → 콤마(,)를 기준으로 나눔
split()의 리턴 타입은 list 타입입니다.

split() 처럼 아무것도 없이 쓰면 space기준으로 쪼깨고, ()에 인수로 받은 문자로 split합니다.
9. 표준 입출력
9.1. 입력받기 (input())
user_input = input("문자를 입력하세요: ")
print("입력하신 값:", user_input)- input()은 사용자 입력을 받고, 엔터 입력 전까지 대기합니다.
- 반환값은 항상 문자열입니다.
또한 다음과 같이 연쇄 호출을 사용해 공백 구분 입력을 리스트로 받을 수 있습니다:
numbers = input("숫자들을 공백으로 구분하여 입력하세요: ").split()
print(numbers) # 리스트 타입- input()의 반환값(문자열)이 split()의 입력 타입(문자열)과 일치하기 때문에 가능합니다.
- split()의 반환값은 리스트이므로, 이후에 또 다른 함수를 연결할 경우 해당 타입을 고려해야 합니다.
예를 들어, input의 반환값은 문자열이고, split의 입력타입도 문자열임. 그리고 split의 반환 타입은 리스트


9.2. 출력하기 (print())
print("Hello World!")- 여러 인자를 쉼표로 구분하면, 자동으로 공백을 삽입해 출력합니다.
- sep와 end 파라미터로 구분자와 줄바꿈 문자를 설정할 수 있습니다.
예: print("Hello", "World", sep="|") → Hello|World

붉은색 언더바는 실제 언더바가 아니고 SPACE임을 강조하기 위해 표시된 것..




