
Python 기초 문법 정리
1. 조건문 (Conditional Statements)
- 코드 블럭의 들여쓰기: Python에서는 들여쓰기가 코드 블럭을 구분하는 중요한 역할을 합니다. 들여쓰기를 올바르게 유지해야 코드가 제대로 실행됩니다.
- 명확한 조건 표현: 조건문은 가능한 한 조건을 명확하게 작성하는 것이 좋습니다. 예를 들어, 두 번째 조건문에 90 이상의 경우는 실제로 실행되지 않더라도, 조건을 명시해 두면 가독성이 높아집니다.

- 특정 조건 활용: 아래 이미지는 2의 배수를 확인하는 조건문 예제로, 자주 사용되므로 기억해두면 유용합니다.

2. 리스트 (Lists)
리스트는 순서가 중요한 데이터를 저장할 때 사용합니다. (참고로, 집합(Set)은 순서를 보장하지 않습니다.)
2.1 리스트 생성
- 리스트는 다양한 방식으로 생성할 수 있습니다. 아래 이미지는 리스트 생성 예제를 보여줍니다.


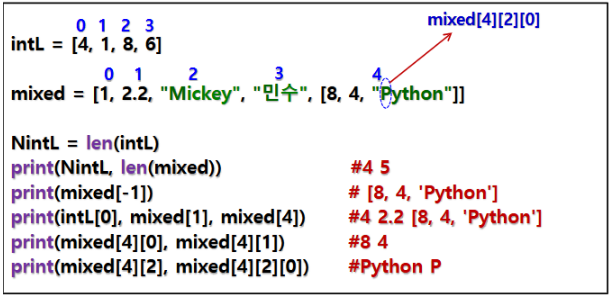
2.2 인덱싱
- 리스트의 각 요소는 인덱싱을 통해 접근할 수 있습니다.
2.3 슬라이싱
- 슬라이싱의 개념:
- b (begin): 시작 인덱스
- e (end): 종료 인덱스(해당 인덱스 바로 전까지 포함)
- s (step): 추출할 간격
- 슬라이싱을 통해 추출한 부분은 새로운 리스트로 반환됩니다.

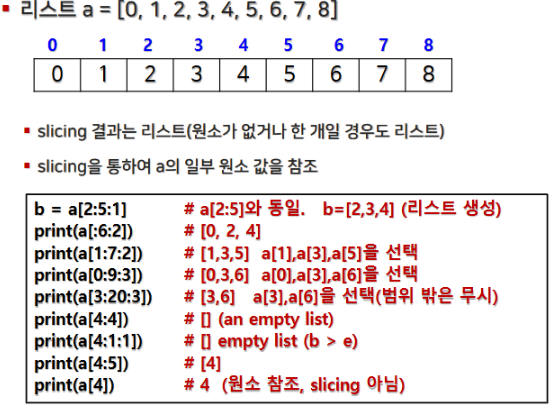
- 역순 슬라이싱: 스텝에 음수를 사용하면 리스트의 뒤쪽부터 슬라이싱을 진행합니다.

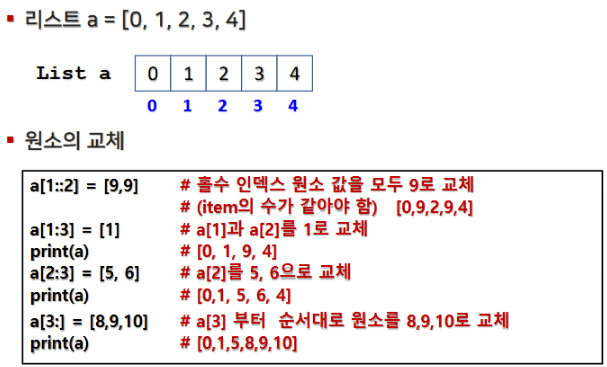
2.4 리스트 요소 수정 및 삭제
- 리스트는 mutable(변경 가능) 하므로, 원소를 삭제하거나 새로운 값으로 할당할 수 있습니다.
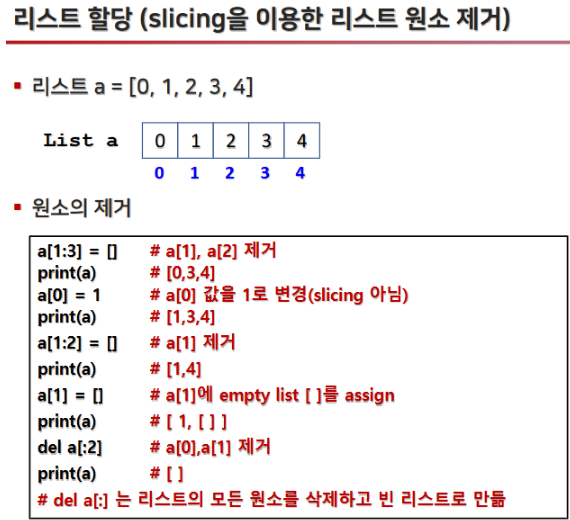
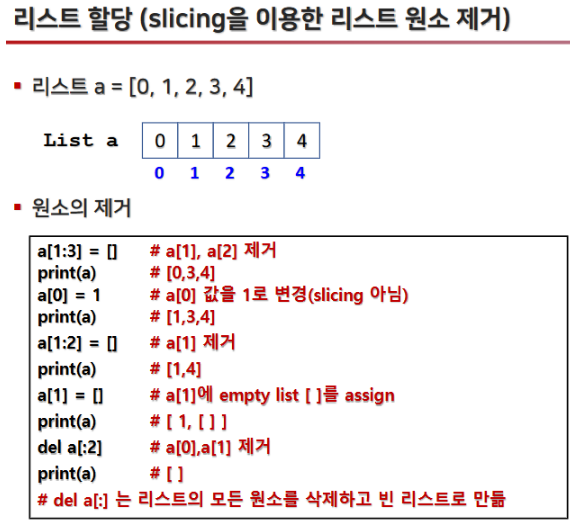
2.5 리스트에 요소 끼워넣기 (Insertion)
- 슬라이싱 기법을 이용해 리스트의 특정 위치에 새로운 요소를 삽입할 수 있습니다.
a[1:1] = ['a', 'b']
인덱스 1 위치에['a', 'b']를 삽입합니다.a[len(a):len(a)] = [10]
리스트의 마지막에 새 원소10을 추가합니다.a[5:5] = "999"
문자열"999"는 각 문자가 분리되어 삽입됩니다. 예를 들어, 결과가[0, ['A', 'B'], 'a', 'b', 1, '9', '9', '9', 5, 2, 3, 4, 10]와 같이 나타날 수 있습니다.

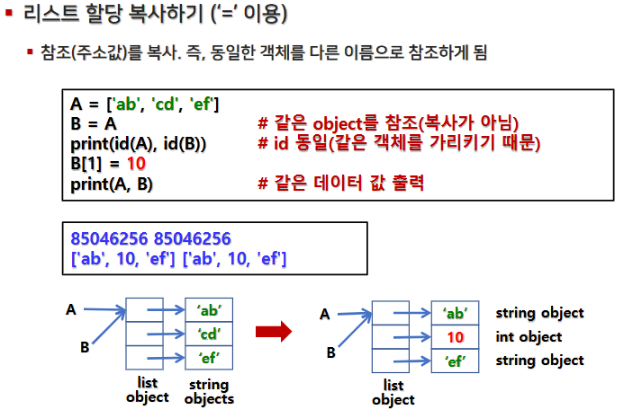

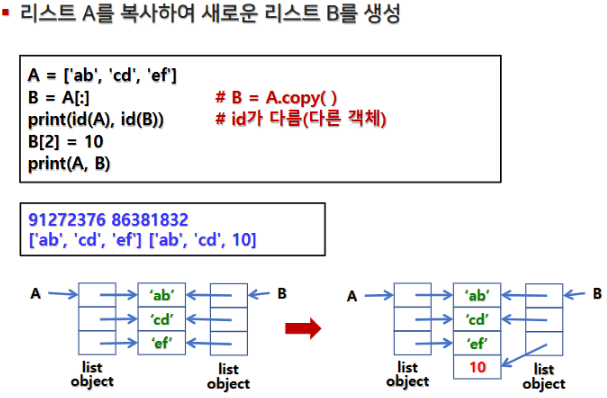
2.6 깊은 복사(Deep Copy) vs. 얕은 복사(Shallow Copy)
- 깊은 복사: 원본 객체와 완전히 독립된 복사본을 생성합니다. (우리가 아는 원본이 안바뀌는 카피)
- 얕은 복사: 객체의 최상위 레벨만 복사하며, 내부의 가변 객체는 원본과 공유될 수 있습니다.
3. 연산자 (Operators)
Python은 산술, 비교, 논리, 할당 등 다양한 연산자를 제공합니다. 아래 이미지는 대표적인 연산자들을 시각적으로 정리한 예제입니다.

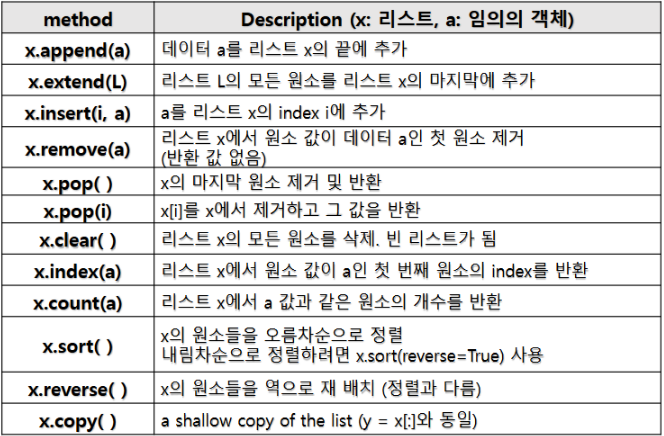
4. 메소드 (Methods)
메소드는 특정 객체가 수행할 수 있는 동작을 정의한 함수입니다. 메소드는 아래와 같이 호출합니다:
objectName.method()예를 들어, 리스트에 대한 메소드를 사용하면 아래와 같이 나타낼 수 있습니다.

L = [1, 2, 3]
E = list(enumerate(L))
print(E) # 출력: [(0, 1), (1, 2), (2, 3)]위 예제에서 enumerate() 함수는 (인덱스, 데이터) 쌍을 반환합니다.
리스트는 mutable (변경 가능), sequence (시퀀스형), iterable (반복 가능)한 자료형입니다.
----
5. 튜플, 집합, 사전 (Tuples, Sets, Dictionaries)
5.1 튜플 (Tuples)
불변 자료형: 튜플은 한 번 생성되면 수정할 수 없습니다.
시퀀스형: 정수, 문자열, 리스트 등 다양한 타입의 데이터를 담을 수 있습니다.
쉼표의 중요성: 튜플은 쉼표(,)가 있어야 튜플로 인식됩니다. 괄호는 생략 가능하지만, 쉼표는 필수입니다.


-
Packing과 Unpacking:
- Packing은 여러 값을 하나의 튜플로 묶는 과정입니다.
- Unpacking은 튜플의 각 요소를 개별 변수에 할당하는 과정입니다. -
튜플 연산:
- 두 튜플을 더하면 새로운 튜플이 생성됩니다.


- 튜플 내의 리스트:
- 튜플 내부에 포함된 리스트는 변경이 가능하다는 점을 유의해야 합니다.
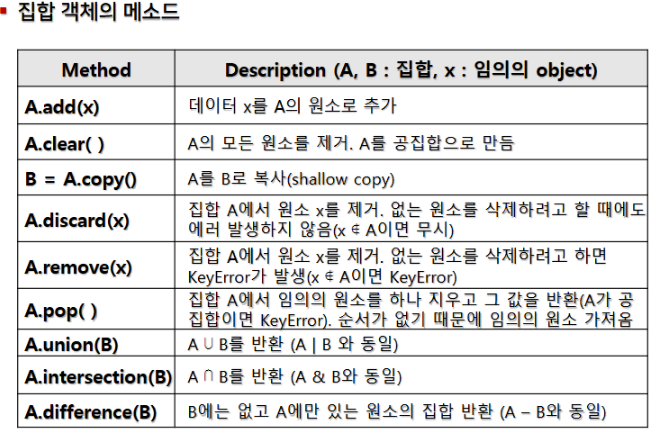
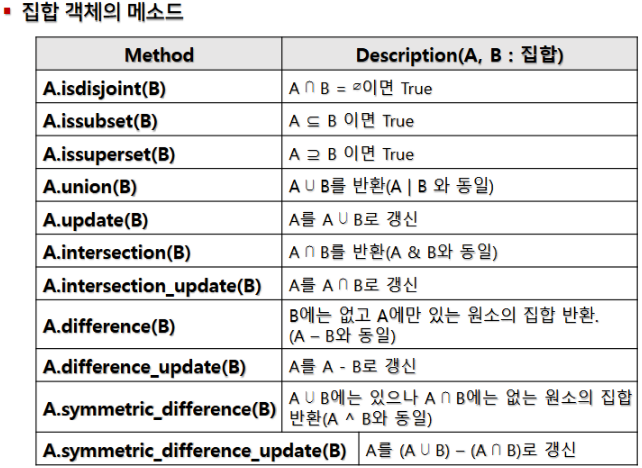
5.2 집합 (Sets)
-
특징:
- 집합은 중복을 허용하지 않으며, 순서가 없어서 인덱싱이나 슬라이싱이 불가능합니다. -
아래 이미지는 집합의 특징과 사용 예제를 보여줍니다.



5.3 사전 (Dictionaries)
- 구조:
- 사전은 키(key)와 값(value)의 쌍으로 데이터를 저장합니다.
- 집합은 값이 없는 키만으로 구성된 사전 형태로 볼 수도 있습니다.




딕셔너리는 리스트로 변환해서 가공할 수 있습니다.



AI Study