
LSTM
Long Short Term Memory
1. RNN의 구조
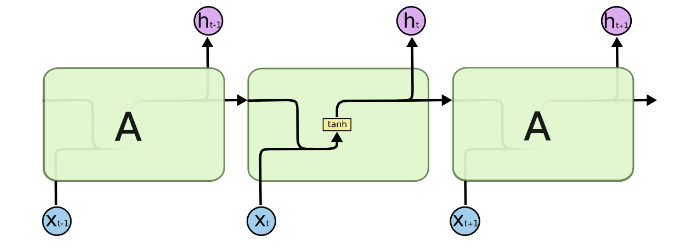
RNN은 sequence 형태의 데이터류 (음성, 언어 모델)를 다루는데에 최적화된 neural network이다.
기존 RNN의 문제는 장기 의존성(Long-Term Dependency)를 학습하지 못하는 문제가 있다.
- 기울기 소실 문제(Vanishing Gradient Problem) : 흔히 알려진 기울기 소실 문제가 있다.
- Long term memory의 부족 - 시간적으로 멀리 떨어진 정보는 기억하기 어려운 구조로 되어있다.
LSTM : 기본 RNN의 문제를 개선
LSTM은 RNN이면서도 긴 시간 이전의 정보도 기억할 수 있는 구조로 되어 있다.
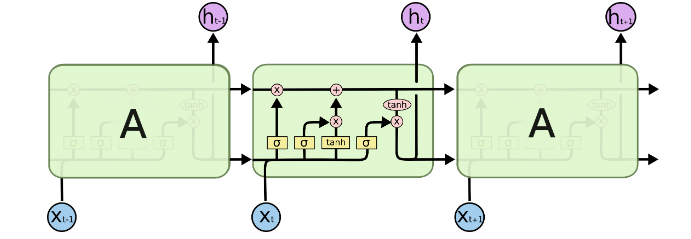
2. LSTM의 구조
하나의 모듈은 6개의 파라미터와 4개의 게이트로 표현된다.
RNN과 비교했을 때는 RNN은 모듈 내에 1개의 tanh layer만 있는 반면에 LSTM은 모듈 내부에 있는 3개의 Sigmoid layer와 1개의 tanh layer가 존재한다.
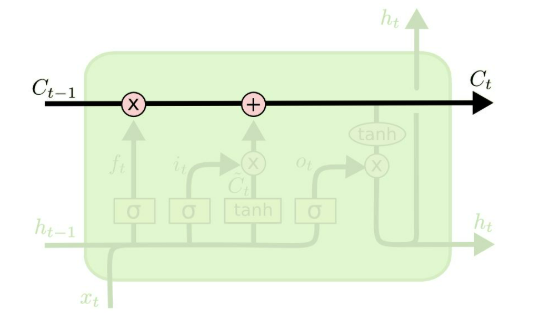
Cell State(LSTM의 핵심)
LSTM은 은닉 상태(h) 외에 셀 상태(c)라는 추가 메모리 저장 공간을 도입했다.
-> 정보의 변경 없이 이전 정보를 그대로 앞으로 전달한다.
셀 상태는 중요한 정보를 장기적으로 저장하고, 필요에 따라 정보를 읽고 삭제할 수 있다.
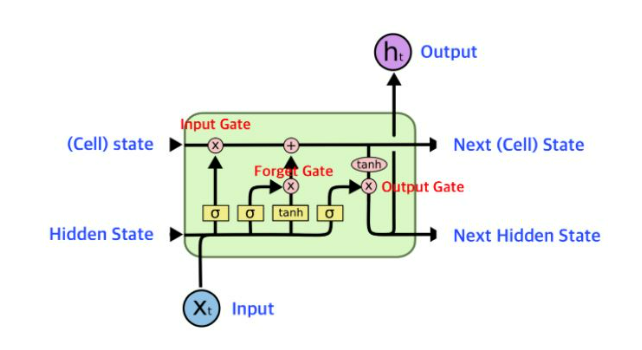
Gate Mechanism
LSTM은 정보를 선택적으로 전달하거나 삭제하는 게이트(Gate) 구조를 추가하여, 장기 의존성을 학습할 수 있도록 했다.
입력 게이트(Input Gate): 새로 들어오는 정보를 얼마나 셀 상태에 추가할지 결정한다.
- 현재 시점의 입력 정보를 얼마나 셀 상태에 추가할지 결정한다.
- 중요하다고 판단되는 정보를 셀 상태에 저장한다.
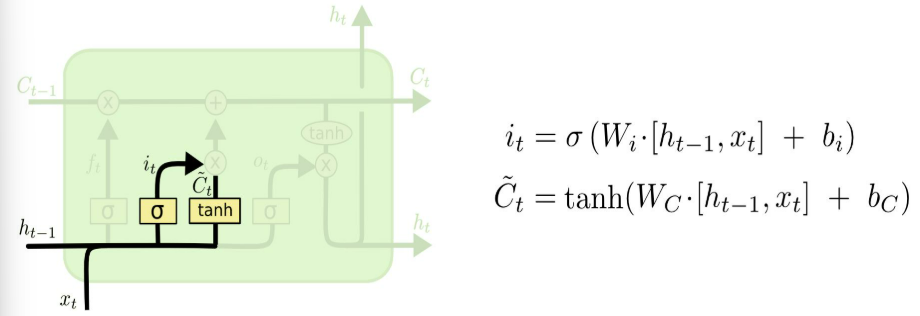
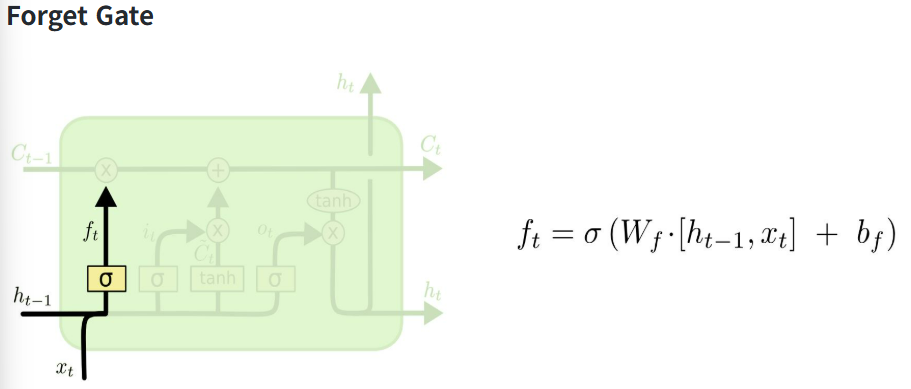
포겟 게이트(Forget Gate): 셀 상태에서 어떤 정보를 잊을지 결정한다.
- 이전 시점의 셀 상태에서 어떤 정보를 삭제할지 결정한다.
- 과거 정보 중 중요하지 않은 부분을 잊음으로써 불필요한 정보가 누적되는 것을 방지한다.
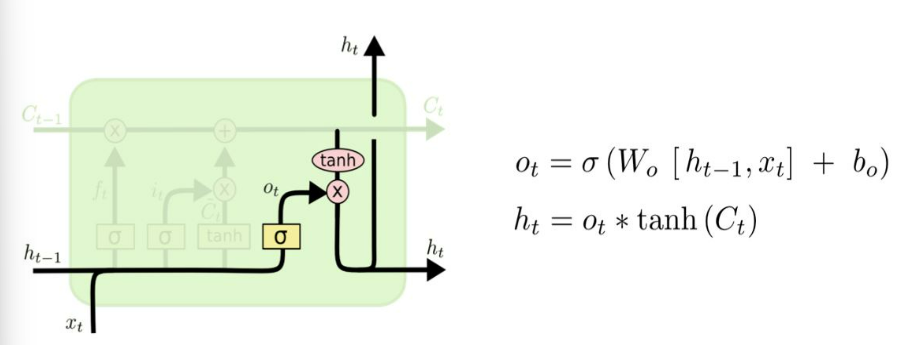
>**출력 게이트(Output Gate)**: 은닉 상태로 어떤 정보를 출력할지 결정한다. - 현재 시점의 은닉 상태(h_t)를 결정한다. - 셀 상태와 입력 데이터를 활용하여, 다음 레이어로 전달할 정보를 계산한다.
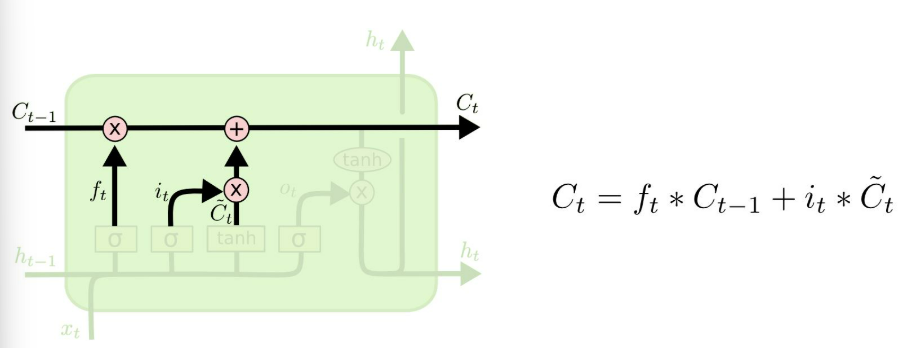
셀 상태 업데이트 (Cell State): 과거 Cell State를 새로운 State로 업데이트 하는 과정이다.
- 포겟 게이트와 입력 게이트의 결과를 결합하여 셀 상태를 업데이트한다.
- 이 과정에서 중요한 정보만 장기적으로 유지할 수 있다.
3. LSTM 활용 코드 예제
Pytorch에서는 nn.Module을 상속받은 클래스를 정의하고 nn.LSTM을 활용해서 LSTM 레이어를 쉽게 정의할 수 있다.
# nn.Module로부터 LSTM 모델 가져와 정의
import torch
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return out아래는 sin파에 랜덤 노이즈를 추가하여 data를 생성하고, 위 모델을 기반으로 학습 및 평가를 진행하는 코드이다.
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
import os
# 데이터 처리 함수
# create_sequences 함수는 시계열 데이터를 모델 학습에 적합한 입력-출력 시퀀스로 변환하는 역할
# 과거 seq_length 만큼의 데이터를 사용하여 다음 시점의 값을 예측하기 위해 사용
def create_sequences(data, seq_length):
X, y = [], []
for i in range(len(data) - seq_length):
X.append(data[i:i+seq_length]) # X: 입력 시퀀스의 배열 (모델이 학습에 사용하는 과거 데이터) -> X는 2차원 배열임
y.append(data[i+seq_length]) # y: 출력 값의 배열 (모델이 예측해야 하는 정답 데이터) -> y는 1차원 배열임
return np.array(X), np.array(y)
def prepare_data(data, seq_length, batch_size):
# 시퀀스 생성
X, y = create_sequences(data, seq_length)
# 차원 변환: (샘플수, 시퀀스길이, 특성수)
X = X.reshape(-1, seq_length, 1) # X = (샘플수 x 시퀀스길이) -> (샘플수, 시퀀스길이, 특성수)
y = y.reshape(-1, 1) # y = (샘플수) -> (샘플수 x 1)
# 텐서로 변환 및 DataLoader 준비
X_tensor = torch.from_numpy(X).float()
y_tensor = torch.from_numpy(y).float()
dataset = TensorDataset(X_tensor, y_tensor) # 입력 텐서(X_tensor)와 출력 텐서(y_tensor)를 하나의 데이터셋으로 묶는 작업
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
return loader, X_tensor, y_tensor
# 학습 함수
def train_model(model, loader, criterion, optimizer, num_epochs):
model.train()
for epoch in range(num_epochs):
epoch_loss = 0
for inputs, targets in loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {epoch_loss/len(loader):.4f}')
# 평가 함수
def evaluate_model(model, X_tensor):
model.eval()
with torch.no_grad():
predictions = model(X_tensor).squeeze().numpy()
return predictions
# 시각화 함수
def plot_results(actual_data, predictions, seq_length):
plt.figure(figsize=(12,6))
plt.plot(range(seq_length, len(actual_data)), actual_data[seq_length:], label='Actual')
plt.plot(range(seq_length, len(actual_data)), predictions, label='Predicted')
plt.legend()
plt.title('LSTM Time Series Prediction')
filepath = os.path.join("./outputs/", "plot.png")
plt.savefig(filepath)
plt.show()
# 메인
def main():
# 데이터 생성 (예시: 노이즈가 있는 사인파)
np.random.seed(0)
time_steps = np.linspace(0, 100, 1000) # 0부터 100까지 1000개의 시간 스텝
#time_steps는 0초부터 100초까지의 시간 동안 일정 간격(약 0.1초)으로 측정된 시간 스텝
data = np.sin(time_steps) + 0.1 * np.random.normal(size=len(time_steps)) # 사인파에 노이즈 추가
# 하이퍼파라미터 설정
sequence_length = 50
batch_size = 32
input_size = 1
hidden_size = 64
num_layers = 2
output_size = 1
learning_rate = 0.001
num_epochs = 20
# 데이터 준비
loader, X_tensor, y_tensor = prepare_data(data, sequence_length, batch_size)
# 모델, 손실함수, 옵티마이저 초기화
model = LSTMModel(input_size, hidden_size, num_layers, output_size)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 모델 학습
train_model(model, loader, criterion, optimizer, num_epochs)
# 평가 및 시각화
predictions = evaluate_model(model, X_tensor)
plot_results(data, predictions, sequence_length)
if __name__ == "__main__":
main()
이미지 출처 : https://wikidocs.net/152773

AI Study