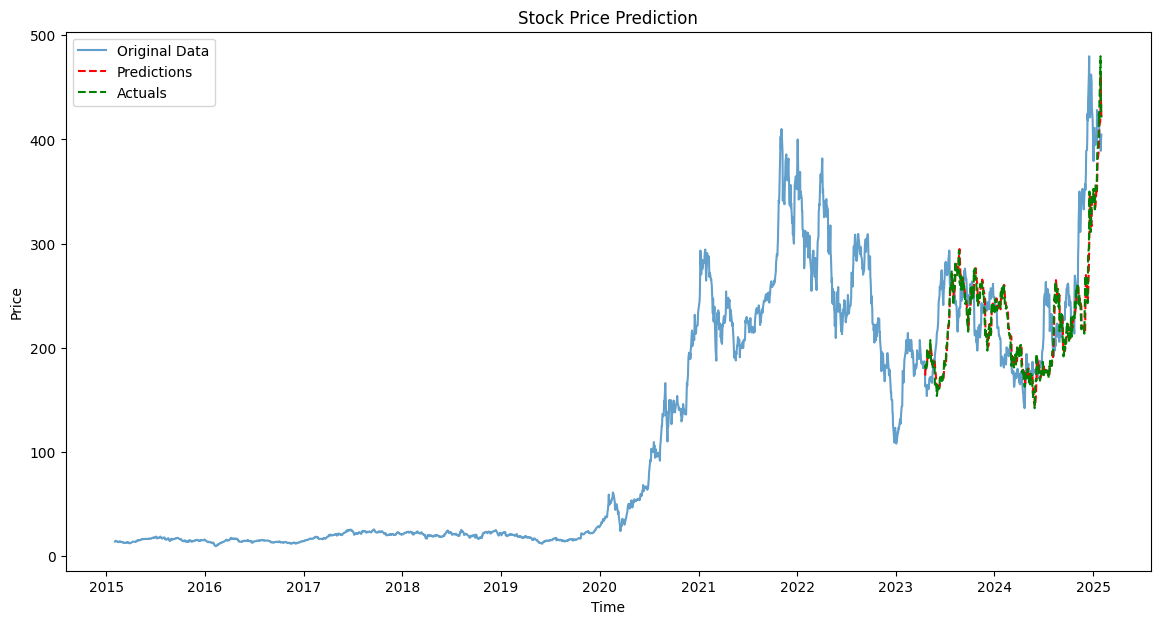
지난번에는 predictions이 제대로 예측되지 않는 문제가 있었다.
정규화된 상태에서 예측치 결과가 음수가 나오거나 역정규화 후 결과의 범위가 이상하게 나오는 문제 때문에 정규화 작업에 문제가 있는 것으로 생각했다.
하지만 수차례 검토하면서 학습 단계에서 모델 인스턴스를 초기화하는 부분 때문에 학습된 결과가 평가에 반영되지 못하고 있다는 것을 발견했다.
# lstm_model 모델 인스턴스를 생성하여 train_lstm_model()과 evaluate()에
# 매개변수로 사용하도록 main()에서 정의
def main(config):
utils.setup_logging(config["logging"]["file"])
train_loader, test_loader, close_scaler, data = dataset.dataset()
lstm_model = model.LSTMModel(
config["train"]["input_size"],
config["train"]["hidden_size"],
config["train"]["num_layers"],
config["train"]["output_size"])
train.train_lstm_model(lstm_model, train_loader, config)
predictions, actuals = eval.evaluate(lstm_model, test_loader, close_scaler)
visualization.plot_predictions(predictions, actuals, data)
if __name__ == "__main__":
config_path = "./configs/config.yaml"
config = utils.load_config(config_path)
main(config)
# 모델 초기화:
# 학습 시 모델 객체를 초기화하게 되면서 평가에 학습되지 않은 모델로 평가하는 문제가 발생됨
# (이를 방지하기 위해 모델을 트레이닝 단계에서 초기화하지 않도록 주석 처리)
import numpy as np
import torch
import torch.nn as nn
from src.model import LSTMModel
def train_lstm_model(model, train_loader, config):
# 문제되었던 코드 삭제
# model = LSTMModel(config["train"]["input_size"], config["train"]["hidden_size"], config["train"]["num_layers"], config["train"]["output_size"], 0.2)
# 장치 설정 (GPU 사용 가능 시 GPU 사용)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# MSE 대신 Huber Loss 사용
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=config["train"]["learning_rate"])
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1)
num_epochs = config["train"]["num_epochs"]
for epoch in range(num_epochs):
model.train()
epoch_loss = 0
for X_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_loss /= len(train_loader)
scheduler.step()
if (epoch+1) % 10 == 0:
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.6f}")Feature 추가
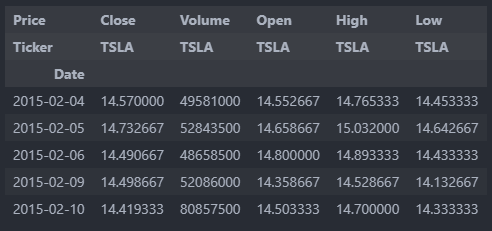
기존에는 Close price만 가져와 학습에 사용하였으나, 좀 더 다양한 데이터로 학습 시키기 위해 일일 거래량 Volume, 일일 시작가 Open price, 일일 최고가 High, 일일 최저가 Low 데이터를 추가로 학습에 사용하도록 했다.
전체 코드
- dataset()
dataset 처리 시 여러 feature를 사용하도록 바꾸면서 정규화 처리 시 각 feature 별로 각각 정규화시켰다.
각각 정규화 시키는 이유는 MinMaxScaler의 정규화 방법이 최저값을 0, 최고값을 1로 정규화하는 방법때문에 특정 feature를 기준으로 정규화 시키면 다른 feature의 정규화 시 특정 범위로 몰리는 현상이 있을 수 있기 때문이다.
예를 들면 Volume의 숫자 범위가 다른 feature들 보다 숫자 크기가 훨씬 크기 때문에 어느 한 feature를 기준으로 정규화한다면 volume이 정규화가 잘 안되거나 그 외 feature들의 정규화가 제대로 되지 않을 수 있다. 그래서 모든 feature들을 각각 정규화했다.
import numpy as np
import yfinance as yf
import torch
from torch.utils.data import DataLoader, TensorDataset
from sklearn.preprocessing import MinMaxScaler
def dataset():
# TSLA 주가 데이터 다운로드 (예: 최근 10년간의 일일 주가)
ticker = "TSLA"
data = yf.download(ticker, period="10y", interval="1d")
data = data[['Close', 'Volume', 'Open', 'High', 'Low']]
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Train-test split
train_size = int(len(data) * 0.8)
train_data = data[:train_size].copy()
test_data = data[train_size:].copy()
# 학습 데이터에 대해 스케일링
close_scaler = MinMaxScaler(feature_range=(0, 1))
volume_scaler = MinMaxScaler(feature_range=(0, 1))
open_scaler = MinMaxScaler(feature_range=(0, 1))
high_scaler = MinMaxScaler(feature_range=(0, 1))
low_scaler = MinMaxScaler(feature_range=(0, 1))
train_data["Close_scaled"] = close_scaler.fit_transform(train_data["Close"].values.reshape(-1, 1))
train_data["Volume_scaled"] = volume_scaler.fit_transform(train_data["Volume"].values.reshape(-1, 1))
train_data["Open_scaled"] = open_scaler.fit_transform(train_data["Open"].values.reshape(-1, 1))
train_data["High_scaled"] = high_scaler.fit_transform(train_data["High"].values.reshape(-1, 1))
train_data["Low_scaled"] = low_scaler.fit_transform(train_data["Low"].values.reshape(-1, 1))
# 테스트 데이터는 학습 데이터의 스케일러를 사용하여 변환
test_data["Close_scaled"] = close_scaler.transform(test_data["Close"].values.reshape(-1, 1))
test_data["Volume_scaled"] = volume_scaler.transform(test_data["Volume"].values.reshape(-1, 1))
test_data["Open_scaled"] = open_scaler.transform(test_data["Open"].values.reshape(-1, 1))
test_data["High_scaled"] = high_scaler.transform(test_data["High"].values.reshape(-1, 1))
test_data["Low_scaled"] = low_scaler.transform(test_data["Low"].values.reshape(-1, 1))
# 시퀀스 데이터 준비 함수
def create_sequences(dataset, time_step=30):
X, y = [], []
for i in range(len(dataset) - time_step - 1):
X.append(dataset[["Close_scaled", "Volume_scaled", "Open_scaled", "High_scaled", "Low_scaled"]].iloc[i:i+time_step].values)
y.append(dataset["Close_scaled"].iloc[i+time_step])
return np.array(X), np.array(y)
time_step = 30
X_train, y_train = create_sequences(train_data, time_step)
X_test, y_test = create_sequences(test_data, time_step)
# Tensor 변환 및 차원 추가
X_train = torch.tensor(X_train, dtype=torch.float32).to(device)
y_train = torch.tensor(y_train, dtype=torch.float32).unsqueeze(-1).to(device)
X_test = torch.tensor(X_test, dtype=torch.float32).to(device)
y_test = torch.tensor(y_test, dtype=torch.float32).unsqueeze(-1).to(device)
print(f"y_train min: {y_train.min()}, max: {y_train.max()}")
print(f"y_test min: {y_test.min()}, max: {y_test.max()}")
# TensorDataset 및 DataLoader 생성
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, drop_last=True)
return train_loader, test_loader, close_scaler, data- evaluate()
import numpy as np
import torch
def evaluate(model, test_loader, close_scaler):
model.eval()
predictions = []
actuals = []
with torch.no_grad():
for X_batch, y_batch in test_loader:
outputs = model(X_batch)
predictions.append(outputs.cpu().numpy())
actuals.append(y_batch.cpu().numpy())
predictions = np.concatenate(predictions, axis=0)
actuals = np.concatenate(actuals, axis=0)
# 역변환
predictions_inversed = close_scaler.inverse_transform(predictions)
actuals_inversed = close_scaler.inverse_transform(actuals)
print(f"Predictions before inverse transform: {predictions[:10]}")
print(f"Predictions range after inverse transform: {predictions_inversed.min()} to {predictions_inversed.max()}")
print(f"Actuals range after inverse transform: {actuals_inversed.min()} to {actuals_inversed.max()}")
return predictions_inversed, actuals_inversed
- LSTMModel(nn.Module)
import torch
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, dropout=0.2):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, dropout=dropout)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.lstm(x, (h0, c0))
out = out[:, -1, :] # 마지막 타임스텝의 출력만 사용
out = self.fc(out) # 출력층에 활성화 함수 없음
return out
- train_lstm_model()
import numpy as np
import torch
import torch.nn as nn
from src.model import LSTMModel
def train_lstm_model(model, train_loader, config):
# 장치 설정 (GPU 사용 가능 시 GPU 사용)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# MSE 대신 Huber Loss 사용
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=config["train"]["learning_rate"])
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1)
num_epochs = config["train"]["num_epochs"]
for epoch in range(num_epochs):
model.train()
epoch_loss = 0
for X_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_loss /= len(train_loader)
scheduler.step()
if (epoch+1) % 10 == 0:
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.6f}")- load_config(), setup_logging()
import yaml
import logging
import os
def load_config(config_path):
with open(config_path, 'r', encoding="utf-8") as f:
config = yaml.safe_load(f)
return config
def setup_logging(log_file, level=logging.INFO):
os.makedirs(os.path.dirname(log_file), exist_ok=True)
logging.basicConfig(
level=level,
format="%(asctime)s [%(levelname)s] %(message)s",
handlers=[
logging.FileHandler(log_file),
logging.StreamHandler()
]
)- plot_predictions()
import matplotlib.pyplot as plt
import numpy as np
def plot_predictions(predictions, actuals, data):
print(f"Predictions before inverse transform: {predictions[:10]}")
# 테스트 데이터가 시작하는 인덱스
test_start_idx = len(data) - len(predictions)
print(f"Original data range: {data['Close'].min()} to {data['Close'].max()}")
print(f"Predictions range after inverse transform: {predictions.min()} to {predictions.max()}")
print(f"Actuals range after inverse transform: {actuals.min()} to {actuals.max()}")
# 시각화
plt.figure(figsize=(14, 7))
plt.plot(data.index, data["Close"], label="Original Data", alpha=0.7)
plt.plot(data.index[test_start_idx:], predictions, label="Predictions", color="red", linestyle="--")
plt.plot(data.index[test_start_idx:], actuals, label="Actuals", color="green", linestyle="--")
plt.title("Stock Price Prediction")
plt.xlabel("Time")
plt.ylabel("Price")
plt.legend()
plt.show()
- main()
import src.utils as utils
import src.dataset as dataset
import src.model as model
import src.train as train
import src.eval as eval
import src.visualization as visualization
def main(config):
utils.setup_logging(config["logging"]["file"])
train_loader, test_loader, close_scaler, data = dataset.dataset()
lstm_model = model.LSTMModel(
config["train"]["input_size"],
config["train"]["hidden_size"],
config["train"]["num_layers"],
config["train"]["output_size"])
train.train_lstm_model(lstm_model, train_loader, config)
predictions, actuals = eval.evaluate(lstm_model, test_loader, close_scaler)
visualization.plot_predictions(predictions, actuals, data)
if __name__ == "__main__":
config_path = "./configs/config.yaml"
config = utils.load_config(config_path)
main(config)
학습 및 평가 결과
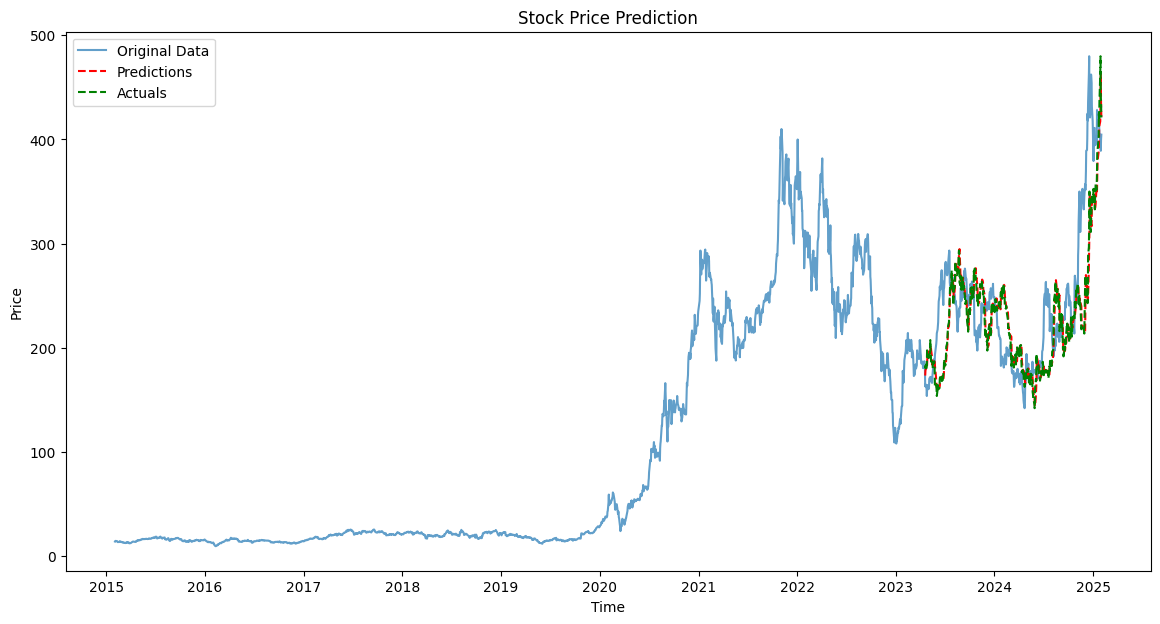
training dataset을 기준으로 정규화하였기 때문에 test dataset의 정규화 후 MinMax는 0과 1에서 살짝 벗어난 것을 볼 수 있다. 그리고 시각화 결과로 불 수 있듯이 예측값은 실제값과 큰차이를 보이지 않으며, 이전에 나왔던 결과와 같이 특정 범위에 예측값들이 몰리는 현상은 학습된 모델이 평가에 사용되지 않아 발생한 문제였음을 확인할 수 있었다.
y_train min: 0.0, max: 1.0
y_test min: 0.33085575699806213, max: 1.1745538711547852
Epoch 10/200, Loss: 0.000807
Epoch 20/200, Loss: 0.000642
Epoch 30/200, Loss: 0.000525
Epoch 40/200, Loss: 0.000421
Epoch 50/200, Loss: 0.000471
Epoch 60/200, Loss: 0.000342
Epoch 70/200, Loss: 0.000348
Epoch 80/200, Loss: 0.000311
Epoch 90/200, Loss: 0.000323
Epoch 100/200, Loss: 0.000309
Epoch 110/200, Loss: 0.000292
Epoch 120/200, Loss: 0.000305
Epoch 130/200, Loss: 0.000304
Epoch 140/200, Loss: 0.000295
Epoch 150/200, Loss: 0.000310
Epoch 160/200, Loss: 0.000310
Epoch 170/200, Loss: 0.000290
Epoch 180/200, Loss: 0.000280
Epoch 190/200, Loss: 0.000292
Epoch 200/200, Loss: 0.000293
Predictions before inverse transform: [[0.40911722]
[0.42153814]
[0.42755365]
...
TSLA 479.859985
dtype: float64
Predictions range after inverse transform: 144.0032501220703 to 462.3989562988281
Actuals range after inverse transform: 142.0500030517578 to 479.8599853515625