Transformer
1.Transformer - Self attention 개념
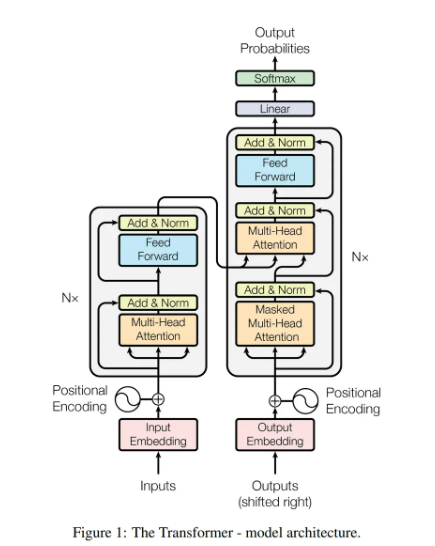
Transformer 🔍 Self-Attention Mechanism Self-Attention Mechanism은 트랜스포머(Transformer) 모델의 핵심 요소. 문장 내 단어들 간의 의존 관계를 거리와 상관없이 학습할 수 있도록 도움. 전통적인 RNN은
2.Transformer와 LSTM의 작동 방식 차이

Transformer는 일반적으로 encoder-decoder 아키텍처를 사용하며, 예측 시에는 한 개의 초기 시퀀스를 바탕으로 autoregressive하게 한 스텝씩 미래 값을 생성한다. 이 rollout 방식은 Transformer의 구조상 디코더에 이전 예측 결
3.Transformer 순차데이터 처리
Transformer 학습 및 평가 시 training data와 test data를 다르게 처리 하는 이유평가 시에 rollout 방식을 사용하는 것은 미래 예측을 위해 이전 예측값을 기반으로 순차적으로 진행하는 반면, 학습 단계에서는 그런 방식을 사용하지 않습니다.
4.Transformer를 이용한 시계열 데이터 예측 - 코드 분석
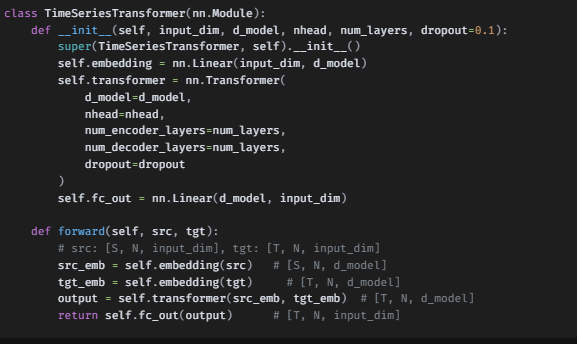
Pytorch에서 제공하는 nn.Module Transformer 모델을 이용하여 주가예측을 해보는 프로젝트입니다. 이번엔 코드 분석 위주로 작성하였고, 추후 성능 개선을 통해 그럴듯한 예측을 할 수 있을지 확인 해보려고 합니다.
5.Transformer를 이용한 시계열 데이터 예측 - 결과 분석 (1)
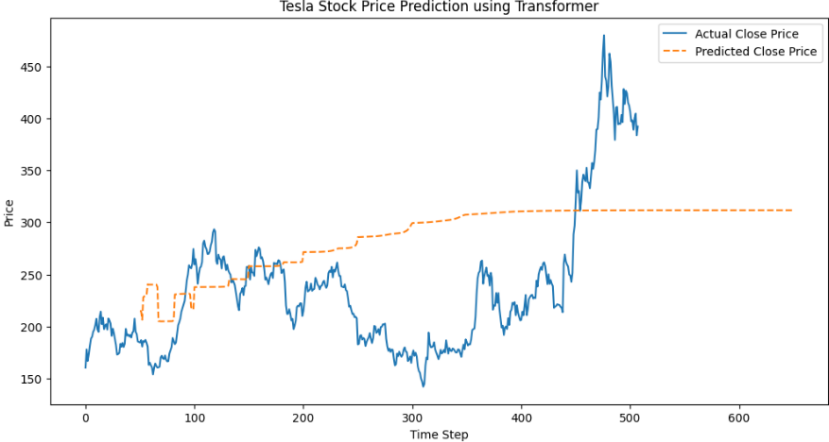
이전 포스팅 : https://velog.io/@machu8/Transformer%EB%A5%BC-%EC%9D%B4%EC%9A%A9%ED%95%9C-%EC%8B%9C%EA%B3%84%EC%97%B4-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%98
6.Transformer를 이용한 시계열 데이터 예측 - 코드 분석 (2)
코드 변경 사항 1) Teacher Forcing 기법 도입 2)
7.[Transformer] 토큰화 (Tokenization) / 임베딩 (Embedding)
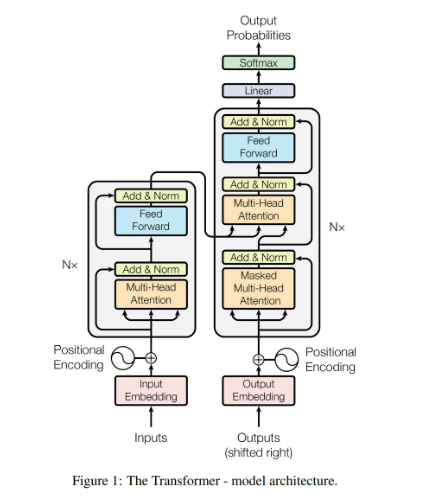
1\. 컴퓨터가 언어를 이해하도록 변환컴퓨터는 텍스트를 직접 처리할 수 없다. 때문에 "단어" 또는 "문장"과 같은 자연 언어를 컴퓨터가 이해할 수 있는 숫자의 배열/벡터로 변환해야한다. 이 과정 중의 첫번째가 토큰화이다. 토큰화는 텍스트를 모델이 처리할 수 있는 단위