
프론트엔드, 백엔드 개발 모두 진행하였는데
본업이 백엔드 개발자다 보니 UI, UX의 부족함은 감안해주시면 감사드리겠습니다..
지극히 개인적 사용 목적으로 개발한 개인 프로젝트이며
Kafka와 Debezium을 사용해 데이터 동기화를 한 것이 특징인 프로젝트입니다.
분산 시스템에서 데이터 동기화를 어떻게 구현했는 지를 중심으로 설명드리려 합니다!
프로젝트 개요
매주 웨이트 트레이닝을 하는데 중량이나 횟수, 진행한 세트 수 등을 기록하지 않아서 매주 할 때마다 헷갈리고 중량이 잘 늘지 않는 것 같다...
좀 더 체계적으로 운동할 수 있도록 내 운동 페이스에 맞춘 트레이너 앱을 제작해 관리하자!

사용 시나리오
-
오늘도 웨이트 트레이닝을 하러 헬스장에 간다!
-
헬스 시작 전 운동 시작하기 버튼을 누른다!
-
진행할 운동을 선택한다!
-
열심히 운동한다!
-
수행한 중량, 횟수를 기록한다!
-
이제 뭐할 건지 선택한다!
6-1. 한 세트 더를 선택한 경우
6-2. 다른 운동하기를 선택한 경우
6-3. 운동 그만하기를 선택한 경우
프로젝트 구조
백엔드 구조
백엔드는 MSA 구조로 구현하였으며 웨이트 트레이닝 기록을 관리하는 Log API Server와 웨이트 트레이닝 기록을 기반으로 대시보드 데이터를 만들어 제공하는 Dashboard Server로 나누어집니다.
따라서 Log API Server에 웨이트 수행 기록이 저장되면 실시간으로 Dashboard API에 해당 데이터를 동기화 시켜 보여줘야 합니다.
이를 구현하기 위해 Kafka와 Debezium을 사용하였습니다.
아래는 전체 백엔드 구조를 도식화한 것입니다.
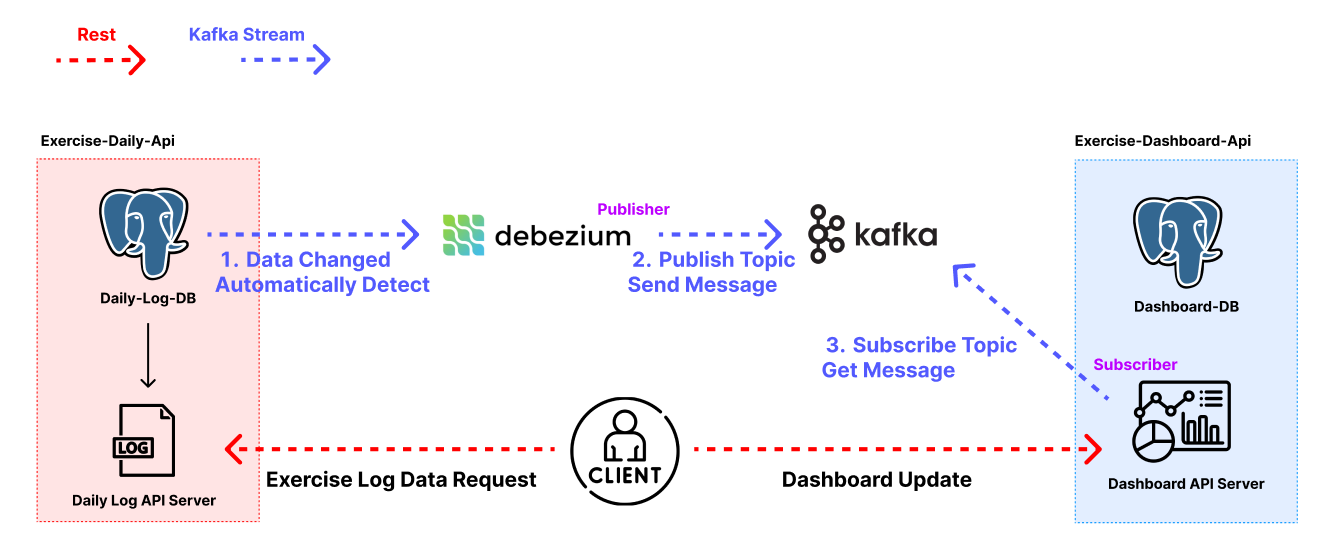
데이터가 동기화되는 플로우를 설명드리면 아래와 같습니다.
( 사진에서 파란색 부분에 해당합니다. )
- Debezium이 Log API Server의 DB를 바라보고 있다가 데이터 변경이 일어나면 자동적으로 Capture하고 저장합니다.
- Debezium이 캡쳐한 데이터 변경 내역을 Kafka에 Message로 전달하면 Kafka Topic에 해당 Message가 저장됩니다.
- Dashboard API Server는 데이터 동기화가 필요한 Kafka Topic들을 Subscribe 하고 있다가 Message들을 Consume하고 DB에 알맞게 변형해 저장합니다.
요약하면 Debezium이 데이터 변경을 감지하고 Kafka에 보내면 Dashboard API Server가 이를 Consume 하는 구조입니다.
그럼 위 구조를 구현한 과정을 좀 더 상세히 설명드리겠습니다.
구현 과정
먼저 저는 로컬 환경 구축이 더 쉽도록 Kafka와 Debezium을 모두 도커라이징하여 구동하였습니다.
먼저 Kafka를 올리기 위해 docker-compose 파일에 아래와 같이 kafka 설정을 추가하였습니다.
kafka:
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_LISTENERS: ${KAFKA_ADVERTISED_LISTENERS}
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: ${KAFKA_LISTENER_SECURITY_PROTOCOL_MAP}
KAFKA_LISTENERS: ${KAFKA_LISTENERS}
KAFKA_INTER_BROKER_LISTENER_NAME: ${KAFKA_INTER_BROKER_LISTENER_NAME}
KAFKA_ZOOKEEPER_CONNECT: ${KAFKA_ZOOKEEPER_CONNECT}
volumes:
- /var/run/docker.sock:/var/run/docker.sock
depends_on:
- zookeeper
- KAFKA_ADVERTISED_LISTENERS : Kafka 브로커가 클라이언트에게 알리는 리스너의 엔드포인트입니다. 즉, 클라이언트가 브로커에 연결할 때 사용하는 값
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP : Kafka 브로커가 리스너 간에 사용하는 보안 프로토콜
- KAFKA_LISTENERS : Kafka 브로커가 클라이언트로부터 연결을 수락하는 데 사용할 리스너
- KAFKA_INTER_BROKER_LISTENER_NAME : Kafka 브로커 간 통신에 사용할 리스터의 이름
- KAFKA_ZOOKEEPER_CONNECT : Zookeeper 연결 정보
KAFKA_ADVERTISED_LISTENERS와 KAFKA_LISTENERS의 의미가 비슷해보이는데
간단히 말해 KAFKA_ADVERTISED_LISTENERS와는 외부 클라이언트에게 노출되는 주소를 의미하고
KAFKA_LISTENERS의는 브로커가 클라이언트로 연결을 받아들이는 데 사용하는 내부 주소와 포트입니다.
제 설정의 경우 API 서버는 KAFKA_ADVERTISED_LISTENERS를 사용해 kafka와 연결을 하며 docker container 내부적으로는 KAFKA_LISTENERS 값으로 통신합니다.
kafka는 zookeeper에 의존성을 가지며 zookeeper 컨테이너가 올라간 후 올라가게 됩니다.
zookeeper 또한 docker로 구동하였으며 아래와 같이 작성하였습니다.
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"zookeeper의 역할만 간단히 설명드리면 kafka의 클러스터를 조절하고 관리해주는 역할을 수행합니다.
즉, kafka는 들어온 데이터를 처리하는데 집중한다면 zookeeper는 어떤 브로커들이 있는지 파악하고 효율적인 처리를 위해 브로커들을 관리하는 역할을 수행합니다.
특별한 옵션은 없기에 부가적인 설명은 생략하겠습니다.
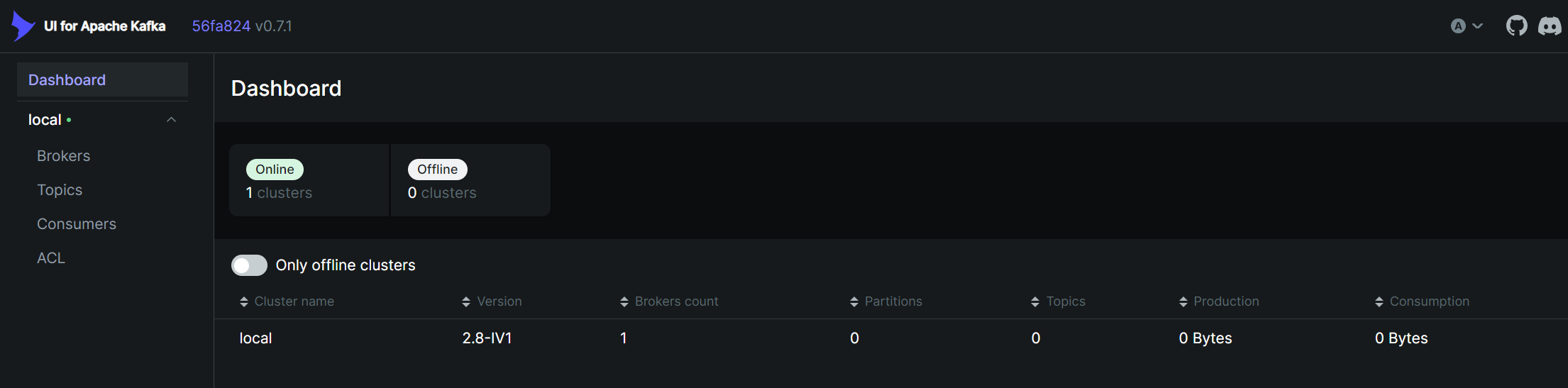
다음은 kafka의 변화를 좀 더 쉽게 관찰하기 위해 kafka-ui라는 것을 추가했는데요
kafka 상태를 보기위한 여러 툴이 있었지만 kafka-ui가 가장 괜찮아보여서 선택하였습니다.
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
ports:
- "9000:8080"
restart: always
environment:
- KAFKA_CLUSTERS_0_NAME=${KAFKA_CLUSTERS_0_NAME}
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=${KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS}
- KAFKA_CLUSTERS_0_ZOOKEEPER=${KAFKA_CLUSTERS_0_ZOOKEEPER}환경 변수는 kafka에 대한 설정을 주면 되는데요
kafka 클러스터의 이름과 주소, 주키퍼 주소등을 주면 됩니다.
정상적으로 구동시킨 후 localhost:9000으로 접속하면 아래와 같이 kafka 관리 GUI를 볼 수 있어 관리가 쉽습니다.
다음은 debezium인데요.
debezium은 변경 데이터 캡처가 가능한 플랫폼으로 데이터베이스의 변경 사항을 실시간으로 감지하고 이를 캡처하여 다른 시스템에 전달하는 기능을 제공합니다.
debezium:
image: debezium/example-postgres:1.6
ports:
- "5432:5432"
environment:
POSTGRES_DB: ${POSTGRES_DB}
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
depends_on:
- kafkadebezium 설정으로는 데이터 변경을 감지할 데이터베이스의 정보를 주면 됩니다.
다만 debezium에서 캡쳐한 데이터를 kafka에 전달하기 위해서는 debezium connector라는 것이 추가적으로 필요합니다.
connect:
image: debezium/connect:1.7
ports:
- "8083:8083"
links:
- kafka
- zookeeper
environment:
- BOOTSTRAP_SERVERS=${BOOTSTRAP_SERVERS}
- GROUP_ID=${GROUP_ID}
- CONFIG_STORAGE_TOPIC=${CONFIG_STORAGE_TOPIC}
- OFFSET_STORAGE_TOPIC=${OFFSET_STORAGE_TOPIC}
- STATUS_STORAGE_TOPIC=${STATUS_STORAGE_TOPIC}
- KEY_CONVERTER=${KEY_CONVERTER}
- VALUE_CONVERTER=${VALUE_CONVERTER}
- INTERNAL_KEY_CONVERTER=${INTERNAL_KEY_CONVERTER}
- INTERNAL_VALUE_CONVERTER=${INTERNAL_VALUE_CONVERTER}
- INTERNAL_KEY_CONVERTER_SCHEMAS_ENABLE=${INTERNAL_KEY_CONVERTER_SCHEMAS_ENABLE}
- INTERNAL_VALUE_CONVERTER_SCHEMAS_ENABLE=${INTERNAL_VALUE_CONVERTER_SCHEMAS_ENABLE}
- STATUS_STORAGE_REPLICATION_FACTOR=${STATUS_STORAGE_REPLICATION_FACTOR}
- OFFSET_STORAGE_REPLICATION_FACTOR=${OFFSET_STORAGE_REPLICATION_FACTOR}
- CONFIG_STORAGE_REPLICATION_FACTOR=${CONFIG_STORAGE_REPLICATION_FACTOR}
- CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE=${CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE}
- CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE=${CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE}Debezium-Connector가 실질적으로 Kafka의 Publisher가 되기 때문에 이에 필요한 많은 설정이 필요합니다.
다 설명하기엔 무리가 있고 저도 공식 문서를 참고해서 값을 설정했기 때문에
정확한 값은 공식문서를 확인하시면 되겠습니다.
여기까지 구성하시고 도커 컴포즈를 올리시면 정상적으로 모든 서버가 구동되게 됩니다.
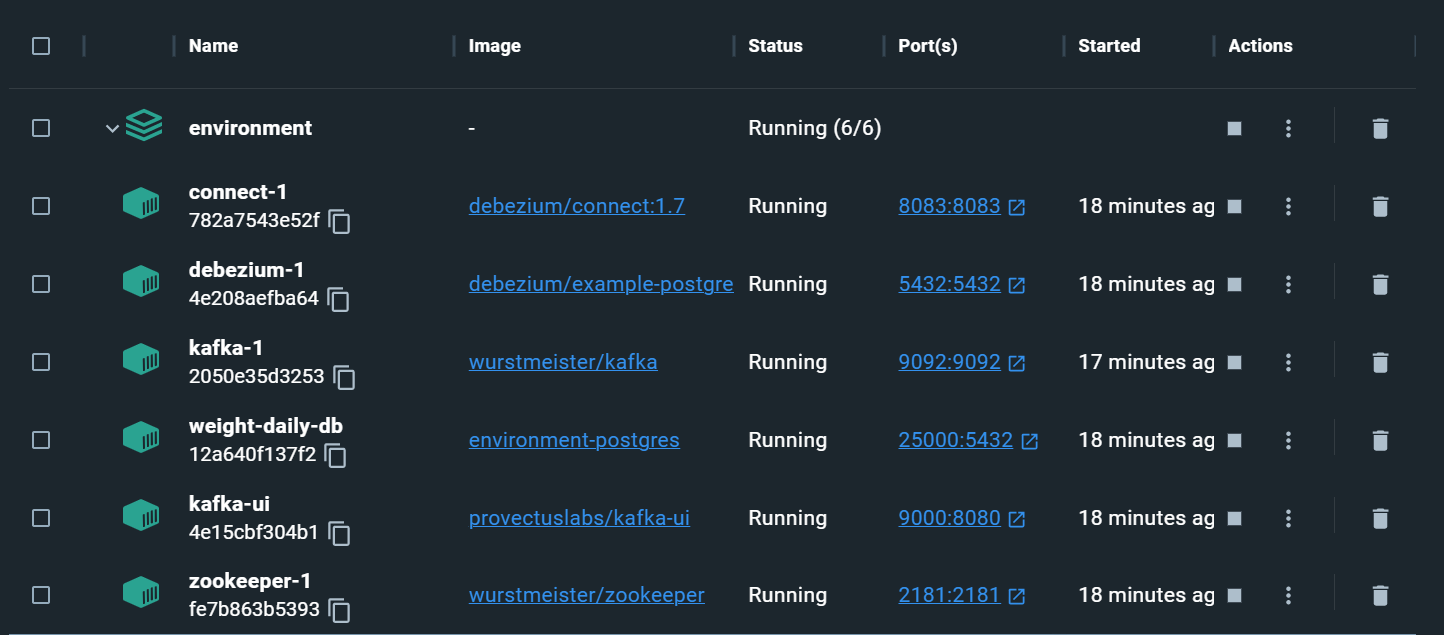
추가적으로 저는 PostgreSQL 또한 도커에 올렸는데
만약 로컬 컴퓨터에 DB를 구성하면 Docker Container와 연결되는 부분이 많아 네트워킹이 헷갈리는 부분들이 있었습니다.
그래서 가능하다면 시간 절약과 필요없는 공수를 들이지 않기 위해 도커화하시는 걸 추천드립니다.
환경 설정에 대한 것들은 제 깃헙에 있습니다. (env 제외)
https://github.com/Mactto/weight-daily-environment
위 구성을 마쳤다면 DB 변경을 감지하고 Kafka에 Publish 하는 것까지는 Debezium과 Kafka가 자동적으로 해주게 됩니다.
Consumer는 따로 Kafka Connector를 두어 구현하거나 애플리케이션 단에서 직접 수행할 수도 있습니다.
저는 Dashboard 서버가 Consumer 역할을 해야하기에 Nest.js 환경에 Consumer를 구성하였습니다.
Nest.js 공식문서에 해당 내용이 나오는데 정말 설명할 것도 없이 쉽게 구성할 수 있습니다.
Kafka + Debezium 사용 후기
회사에서 프로젝트를 구현할 때는 정말 Kafka와 Debezium이 해주는 부분들을 전부 구현해야 했어서
개발 난이도도 너무 높고 아무리 직관적인 구조를 짜더라도 관리가 힘든 이슈가 있었습니다.
이번에 이 조합을 사용해보니 자동적으로 해주는 것도 너무 많았고 전부 오픈 소스라는 장점이 있어 커스터마이징이 정말 용이했습니다.
다만 제공하는 옵션이 많아서 실제 운영 단계에서는 하나하나 잘 파악해서 상황에 맞게 잘 적용해야 할 것 같다는 느낌을 받았습니다.
